일반화를 잘되게 하기 위해서 필요한 기법이다.
즉 모델이 학습에서만 잘 되게 하는게 아니라 테스트에서도 잘 되게 하기 위한 방법이다.
종류
-
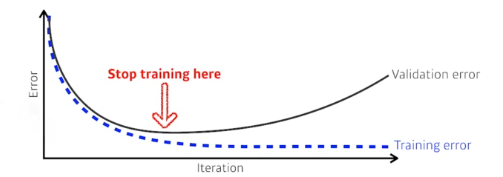
Early stopping
말 그대로 학습을 멈추는 건데 검증 계속하다보면 어느 순간 loss가 올라가는 형태가 보일텐데 그때 멈추는 거다.
-
parameter norm penalty
뉴럴네트워크 파라미터가 너무 커지지 않았으면 좋겠다는 것이다.
크기가 작으면 작을 수록 좋다!!
total cost에 제곱항을 추가하기
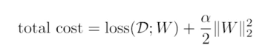
-
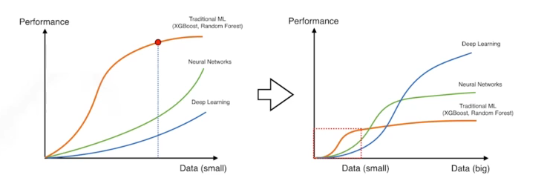
data augmentation
딥러닝에서는 데이터가 많으면 많을수록 잘 된다.
데이터가 적으면 사실 딥러닝보다 머신러닝이 잘 될때가 많다.
근데 데이터가 많아지면 머신러닝을 데이터를 다 표현해 내지 못한다.
그래서 데이터를 늘리기 위해 데이터를 증강하는 것이다!!
갖고 잇는 데이터를 조금씩 변형시켜서 증강하는 것이다(레이블이 변환되지 않는다는 조건 하에서)
-
noise robustness
이미지에 노이즈에 넣는것이다. 노이즈를 섞어서 학습하면 성능이 더 잘 나온다는 것이다. -
label smoothing
data augmentation과 유사한데 클래스가 다른 두 데이터를 섞어주는 것이다. 우리가 이미지 분류하고 싶어 할때 이 방법을 쓰면 바운더리를 부드럽게 만들어준다. 라벨도 섞어 버리는 것
(mixup - 섞는것 , cutout- 사진 잘라내기, cutmix- 영역을 나눠서 섞기 -
drop out
뉴럴네트워크 뉴런을 무작위로 0으로 주는 것. 편향되지 않게 -
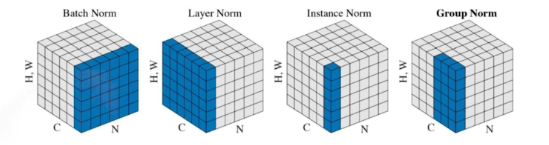
batch nomalization
각각의 파라미터를 평균과 분산을 이용해 정규화를 시켜주는 것이다.
배치 정규화를 사용하면 딥러닝에서 층을 깊게 쌓을때마다 성능이 올라가는 효과를 준다.
배치 정규화도 다양한 방법으로 사용될 수 있다.