어떤 웹 프로젝트를 하든, 프론트엔드와 서버 간의 연결은 늘 고민거리인 것 같다. 요청과 응답이 오가면서 연결을 유지해야 할지, 매번 끊어야 할지, 성능이 어떻게 될지… 간단해 보이지만 막상해보면 “어? 이거 어떻게 설정해야 하지?”라는 생각이 든다.
이번 글에서는 HTTP Keep-Alive(일명 Persistent Connection)에 대해 살펴보자. 왜 존재하고, 어떤 이점이 있고, 또 개발자가 직접 설정할 때 놓칠 수 있는 부분이 있는지 알아보도록 하겠다.
HTTP Keep-Alive란?
-
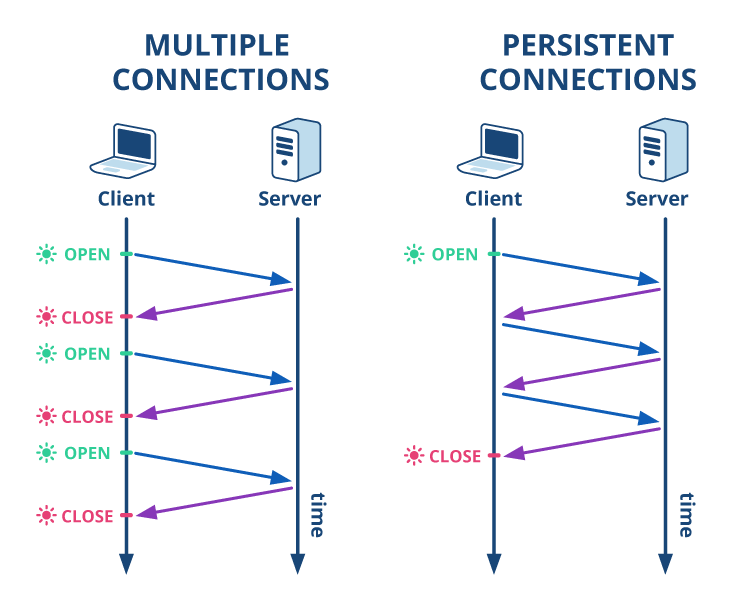
개념 : HTTP/1.1에서 기본으로 지원하는 지속 연결(Persistent Connection).
한 번 TCP 연결을 맺으면, 그 연결을 계속 유지하면서 여러 요청/응답을 처리할 수 있도록 해준다. -
배경 : HTTP/1.0 시절에는 요청-응답이 끝날 때마다 TCP 연결을 끊었다. 리소스를 여러 개 요청하려면 그만큼 3-way handshake(연결 수립 과정)를 매번 수행해야 하니, 오버헤드가 컸다.
-
원리 : 한 번 연결이 맺히면, Connection: keep-alive 헤더를 사용해 특정 시간 동안 연결을 닫지 않는다. 그동안은 추가 요청이 있으면 새로운 TCP 연결을 맺을 필요 없이 기존 연결을 재활용한다.
왜 좋을까?
-
TCP 연결 비용 절감
- 3-way handshake를 자주 할 필요가 없다.
- 여러 개의 작은 리소스(이미지, CSS, JS 등)를 다운로드할 때, 한 번 연결로 연속해서 요청/응답을 주고받을 수 있다.
-
네트워크 성능 향상
- 매번 연결-해제 과정을 반복하지 않으니, 지연(latency)이 줄어든다.
- 브라우저나 서버 측 리소스 소모도 최소화할 수 있다.
-
UX 개선
- 웹 페이지 로딩 속도가 좀 더 빨라져서 사용자 경험이 좋아진다.
- 동시 접속자가 많은 웹서비스에서도 연결 비용 부담을 줄여서 좀 더 매끄러운 통신을 제공한다.
실제로 설정하는 법?
사실 Spring Boot나 Tomcat, Nginx, Apache 같은 서버에서는 HTTP 1.1을 기본 사용하므로 별다른 설정 없이도 Keep-Alive가 기본 동작한다.
다만, 타임아웃(Keep-Alive Timeout)을 조정해야 할 경우가 생긴다.
- Tomcat 예시(tomcat/conf/server.xml)
<Connector
protocol="HTTP/1.1"
...
connectionTimeout="20000" <!-- 20초 -->
keepAliveTimeout="10000" <!-- Keep-Alive Timeout 10초 -->
maxKeepAliveRequests="100"
/>- Nginx 예시(nginx.conf)
http {
keepalive_timeout 65; # 65초
...
}주의할 점
- Timeout 너무 길면 : 사용되지 않는 연결도 서버가 오래 유지해야 하므로 자원이 낭비될 수 있음
- Timeout 너무 짧으면 : 자주 연결이 끊겨서 Keep-Alive의 장점을 활용하지 못할 수 있음
그래도 “연결 유지”가 무조건 좋은가?
동시 접속이 매우 많은 환경에서 Keep-Alive를 너무 오랫동안 유지하면, 서버 소켓이 계속 점유되어 서버 부담이 커질 수 있다.
Short-Lived API(한 번 요청 후 거의 다시 안 쓰는 API)나, 대용량 파일 업로드 시에도 적절히 고려가 필요하다.
→ 그래서 대형 사이트들은 적절한 최적화 & 로드 밸런싱으로 Keep-Alive와 서버 리소스를 함께 관리한다.
마무리
분명 단순해 보이지만, 네트워크 세팅은 처음 보면 헷갈리는 요소가 많다. Keep-Alive 역시 예전부터 들어온 방식이지만, 아직도 성능 최적화에 핵심적인 역할을 한다.
“어? 왜 갑자기 handshake가 자주 일어나지?” 같은 문제가 생기면, 브라우저나 서버의 Keep-Alive 설정이 꺼져있거나, Timeout 값이 너무 작은 경우일 수 있으니 한 번 체크해보자.
개발자는 클라이언트-서버-네트워크-인프라 전반에 관심을 가져야 한다지만 일이 늘어나버린 느낌.. 😅
