코드 달달 볶기.
효율성 너가 먼데..😒
+) 시간 복잡도 관련 강사님의 명쾌한 답🫢
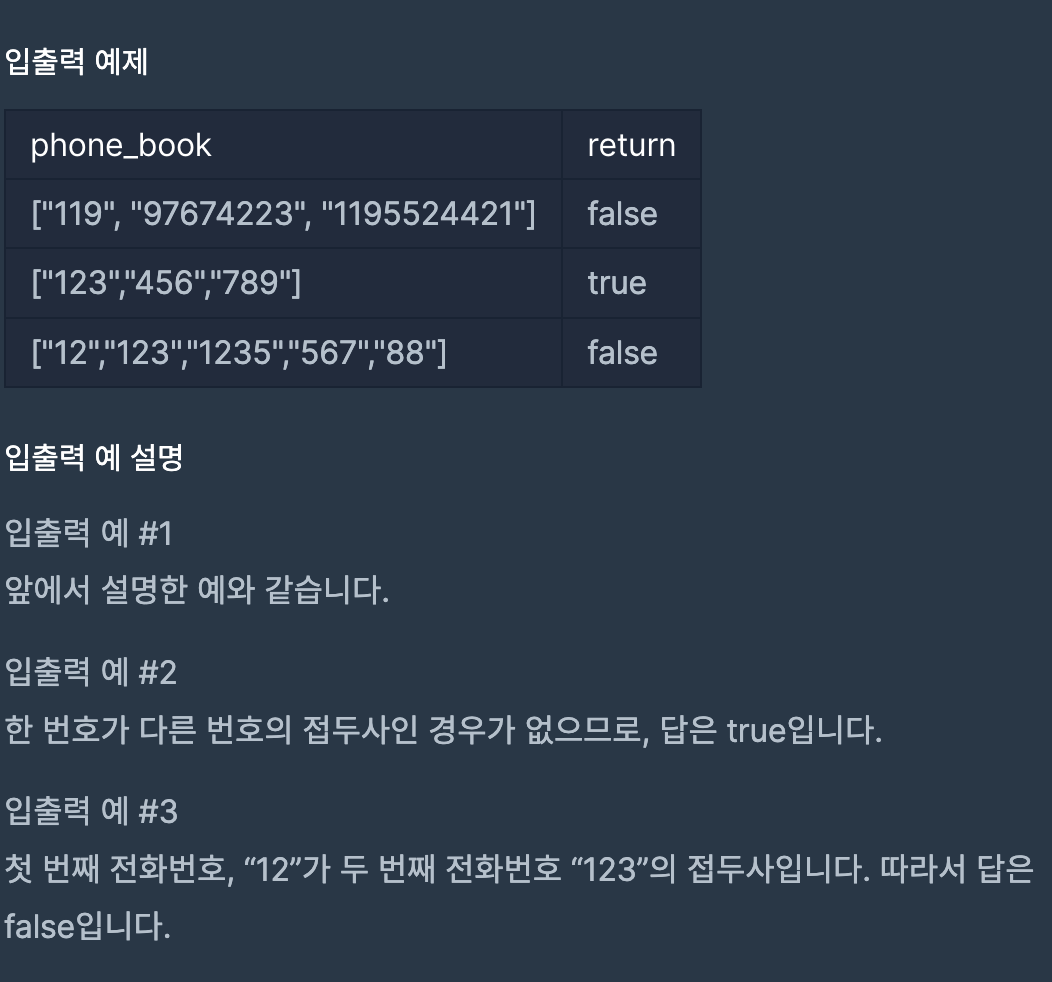
Q) 전화번호 목록
전화번호부에 적힌 전화번호 중, 한 번호가 다른 번호의 접두어인 경우가 있는지 확인하려 합니다.
전화번호가 다음과 같을 경우, 구조대 전화번호는 영석이의 전화번호의 접두사입니다.
구조대 : 119
박준영 : 97 674 223
지영석 : 11 9552 4421
전화번호부에 적힌 전화번호를 담은 배열 phone_book 이 solution 함수의 매개변수로 주어질 때, 어떤 번호가 다른 번호의 접두어인 경우가 있으면 false를 그렇지 않으면 true를 return 하도록 solution 함수를 작성해주세요.
출처 : https://school.programmers.co.kr/learn/courses/30/lessons/42577
정확성은 통과했지만 효율성에서 빠꾸당한 문제..
요건 다른 풀이들 참고했다
난 효율성 80점 인간^0^
1st Try:
import java.util.*;
class Solution {
public boolean solution(String[] phone_book) {
boolean answer = true;
Set<String> chkSet = new HashSet<>();
Set<String> numSet = new HashSet<>();
for (int i = 0; i < phone_book.length; i++) {
chkSet = new HashSet<>();
chkSet.add(phone_book[i]);
int len = phone_book[i].length();
numSet = new HashSet<>();
for (int j = 0; j < phone_book.length; j++) {
if (j != i) {
if (phone_book[j].length() >= len) {
numSet.add(phone_book[j].substring(0, len));
}
}
}
Set<String> retain = new HashSet<>(chkSet);
retain.retainAll(numSet);
if (retain.size() != 0) {
answer = false;
break;
}
}
System.out.println(answer);
return answer;
}
}1) 비교할 대상을 chkSet에 넣고, 나머지 것들을 numSet이라는 세트에 chkSet에 들어가있는 숫자의 길이만큼 substring으로 잘라서 넣었다.
2) 그리고 두 set의 교집합을 구해서 size가 0이 아니면 answer를 false로 설정했다.

막이래 ~
for loop 두 개를 쓴 게 너무 문제였다.
하지만 한 개만 쓰고는 불가하지 않나..
2nd Try:
import java.util.*;
class Solution {
public boolean solution(String[] phone_book) {
boolean answer = true;
Set<String> chkSet = new HashSet<>();
Set<String> numSet = new HashSet<>();
loop1:
for (int i = 0; i < phone_book.length; i++) {
chkSet = new HashSet<>();
chkSet.add(phone_book[i]);
int len = phone_book[i].length();
numSet = new HashSet<>();
for (int j = 0; j < phone_book.length; j++) {
if (j != i) {
if (phone_book[j].length() >= len) {
numSet.add(phone_book[j].substring(0, len));
}
}
Set<String> retain = new HashSet<>(chkSet);
retain.retainAll(numSet);
if (retain.size() != 0) {
answer = false;
break loop1;
}
}
}
return answer;
}
}1) 1번이랑 같은 알고리즘이지만
2) 교집합이 생기자마자 바로 answer에 false를 리턴할 수 있게 했다.
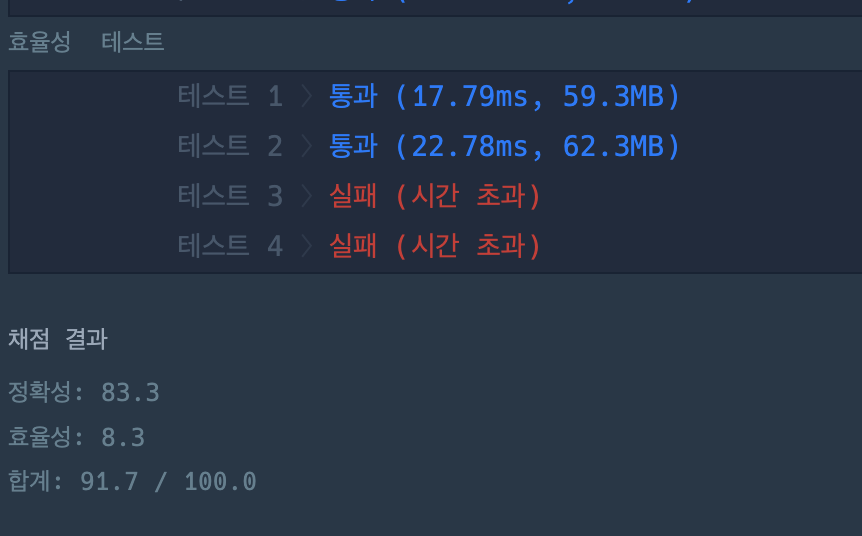
진짜 어쩔티비 ..
그래서 다른 풀이들을 참조했다!
contains()를 쓰는 게 O(1)의 complexity를 가지고 있다고 한다..!
왜 나는 교집합만 쓸 생각을 했을까..?
3rd Try (HashSet):
import java.util.*;
class Solution {
public boolean solution(String[] phone_book) {
boolean answer = true;
Set<String> chkSet = new HashSet<>();
for (int i = 0; i < phone_book.length; i++) {
chkSet.add(phone_book[i]);
}
for (String s : chkSet) {
for (int i = 0; i < s.length(); i++) {
if (chkSet.contains(s.substring(0, i))) {
answer = false;
}
}
}
return answer;
}
}1) chkSet에 모든 값을 넣어준다.
2) 결국엔 for loop 두 개를 쓴다..!
chkSet의 요소를 한 개씩 봐가면서 해당 string의 길이만큼 다른 string들을 substring으로 잘라서 chkSet가 contain하고 있는지 확인한다.
*본인을 제외한 요소를 확인해준다
ex) {"119", "97674223", "1195524421"}가 chkSet에 들어있을 때, s가 "119"일 경우, s.length() = 3이고, for(int i = 0..)문에서는 s.substring(0,0), s.substring(0,1), s.substring(0,2)까지만 비교를 하게 된다.
즉 "", "1", 그리고 "11"까지만 chkSet에 있는지 확인하게 되는 셈..
이 생각을 어떻게 하는거ㅈㅣ
다른 풀이를 참조하게 되어서 자존심이 살짝쿵 상했다🙃
그래서 해시맵으로 도전
4rd Try (HashMap):
import java.util.*;
class Solution {
public boolean solution(String[] phone_book) {
boolean answer = true;
Map<String, Integer> myMap = new HashMap<>();
for (String s : phone_book) {
myMap.put(s, 1);
}
for (String m : myMap.keySet()) {
for (int i = 0; i < m.length(); i++) {
if (myMap.containsKey(m.substring(0, i))) {
answer = false;
}
}
}
return answer;
}
}하지만 알고리즘 자체는 똑같았죠 .. ?🥲
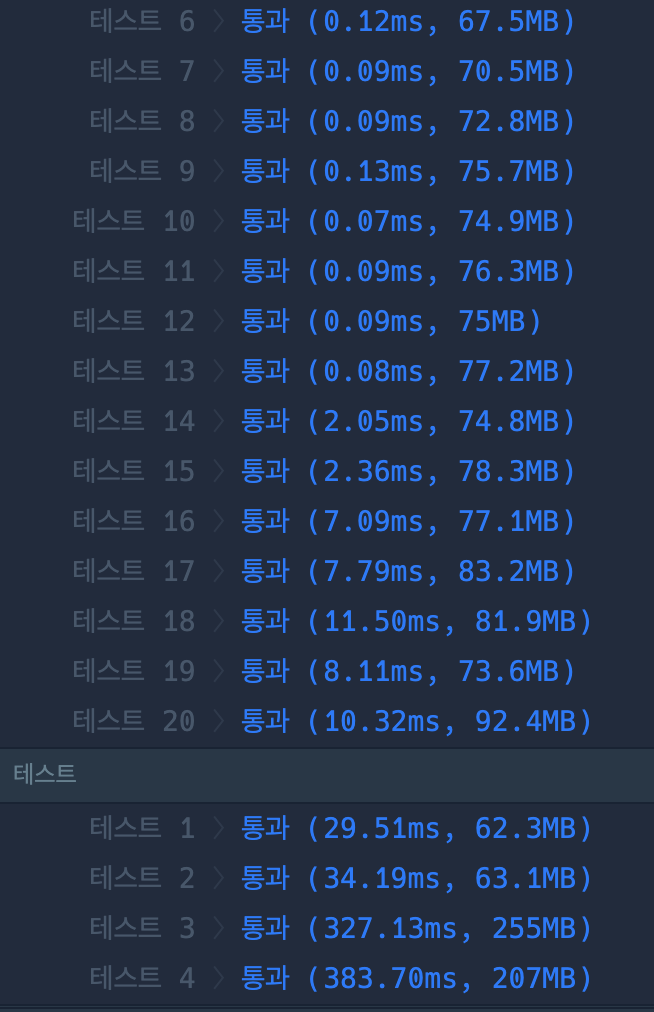
HashSet이랑 HashMap 중에 뭐가 더 좋을까..?
- HashSet
- HashSet
- HashMap
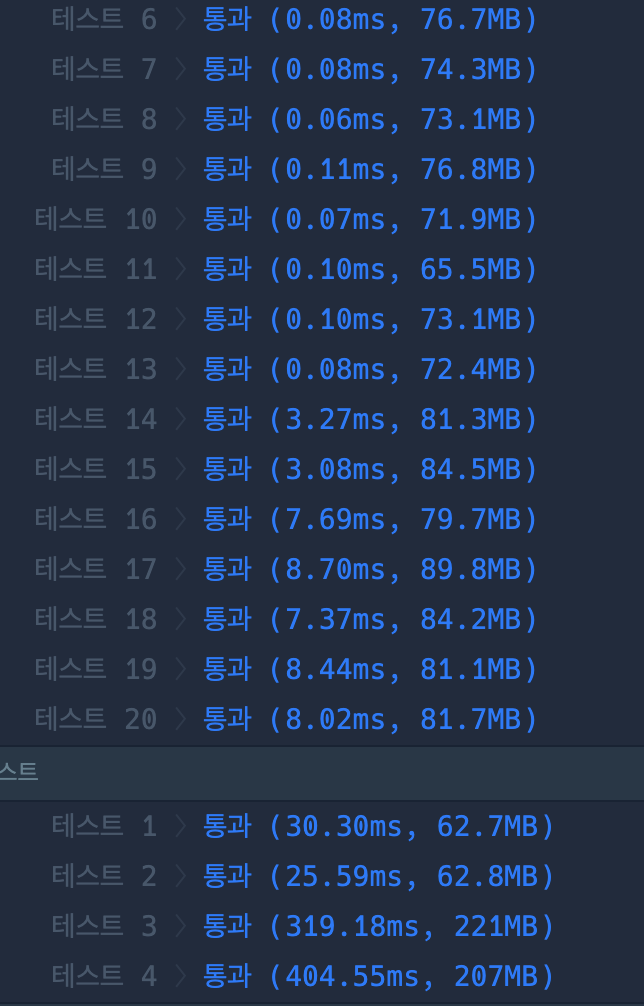
- HashMap
+) 강사님께 여쭤본 결과 !!!
retainAll()이랑 contains()에서의 시간 복잡도는 별 차이가 나지 않는데 내 풀이에서는 phone_book안에 있는 모든 요소들, 즉 최대 1,000,000개일 수 있는 요소들을 다 loop하려고 했다. 반면에 내가 참조한 풀이에서는 한 String당 최대 20번 반복하면서 substring을 자르는 loop을 사용했다.
여기서 완전히 시간 복잡도 차이가 나버린 것!! 🫢🫢🫢🫢
강사님 최고...