
Java 11 설치 및 SSH 연결을 마쳤으니 Spark Clustering을 위해 8개 노드에 Apache Spark를 설치해보겠습니다.
※ Ubuntu 22.04 버전에서 다운로드 설치했습니다.
※ 잘못된 내용이 있으면 피드백 주시면 감사하겠습니다.
[ Spark 설치 및 환경 변수 설정 ]
1. Spark 다운로드
Spark 공식 홈페이지에서 원하시는 Spark 버전 선택 후 다운로드 링크를 통해 tgz 파일을 받아온 후 압축을 풀어줍니다.

#tgz 파일 다운
sudo wget https://dlcdn.apache.org/spark/spark-3.4.0/spark-3.4.0-bin-hadoop3.tgz
#/usr/local 경로에 tgz 파일 압축해제
sudo tar -zxvf spark-3.4.0-bin-hadoop3.tgz -C /usr/local/
# 디렉토리 이름을 spark로 변경했습니다
sudo mv spark-3.4.0-bin-hadoop3 /usr/local/spark
#권한을 root로 바꾸어줍니다.
sudo chown -R root:root /usr/local/spark
2. Spark 환경 변수 등록
이제 Spark 환경 변수를 등록해줍니다.
#다음 경로로 들어가 맨 밑에 코드를 넣어줍니다.
sudo vim /etc/profile
export SPARK_HOME=/usr/local/spark
#같은 방법으로 사용자 환경 변수 등록
sudo vim ~/.bashrc
export SPARK_HOME=/usr/local/spark
#활성화
sudo source ~/.bashrc
#환경 변수 등록이 되었는지 확인해줍니다.
env | grep SPARK
- 8개 노드에 같은 작업을 반복했습니다.
[ Spark Clustering / 애플리케이션 ]
1. 호스트 이름 변경 및 SSH 통신
보기 편하게 하기 위해 호스트 이름을 변경하였으며, 내부끼리 SSH 통신이 가능하도록 하기 위해 호스트를 등록하였습니다.
#각 노드에서 다음과 같은 작업을 시행
#호스트 이름(노드 이름) 변경
sudo hostnamectl set-hostname <원하는 이름>
#마스터 노드
sudo hostnamectl set-hostname master
#워커노드 1번
sudo hostnamectl set-hostname worker01
#워커노드 2번
sudo hostnamectl set-hostname worker02
#워커노드 3번
sudo hostnamectl set-hostname worker03
#워커노드 4번
sudo hostnamectl set-hostname worker04
#워커노드 5번
sudo hostnamectl set-hostname worker05
#워커노드 6번
sudo hostnamectl set-hostname worker06
#워커노드 7번
sudo hostnamectl set-hostname worker07
호스트 이름을 변경했다면 각 노드에 호스트를 등록 해줍니다. (8대 노드에 같은 작업 반복)
sudo vim /etc/hosts
#다음과 같이 삽입해줍니다.
#ip주소 호스트이름
00.000.00.000 master
00.000.00.000 worker01
00.000.00.000 worker02
00.000.00.000 worker03
00.000.00.000 worker04
00.000.00.000 worker05
00.000.00.000 worker06
00.000.00.000 worker07모든 노드를 root 로그인하여 PermitRootLogin과 PasswordAuthentication을 모두 yes로 변경해줍니다.
#root 계정 로그인
sudo su
#해당 경로 들어가기
vim /etc/ssh/sshd_config
#no가 되어있다면
PermitRootLogin no
...
PasswordAuthentication no
#yes로 변경해줍니다.
PermitRootLogin yes
...
PasswordAuthentication yes
#SSH를 재실행합니다
systemctl restart sshdpublic 키를 교환하는 작업을 합니다 (모든 노드에 같은 작업을 반복합니다.)
cd ~/.ssh
ssh-copy-id root@master
ssh-copy-id root@worker01
ssh-copy-id root@worker02
ssh-copy-id root@worker03
ssh-copy-id root@worker04
ssh-copy-id root@worker05
ssh-copy-id root@worker06
ssh-copy-id root@worker07
#비밀번호 없이 연결되는지 확인
ssh master
ssh worker012. 스파크 클러스터 실행
/spark/conf/workers.template을 복사하여 실행하고자하는 노드들의 정보를 입력합니다
※마스터 노드에만 작업합니다.
#템플릿을 복사하여 생성합니다.
cp /usr/local/spark/conf/workers.template /usr/local/spark/conf/workers
#워커 노드를 편집합니다.
vim /usr/local/spark/conf/workers
#localhost를 주석처리한 후 노드의 이름을 넣어줍니다.
master
worker01
worker02
worker03
worker04
worker05
worker06
worker07이제 모든 준비를 마쳤습니다.
/sbin/start-all.sh를 통해 실행합니다.
8개 노드가 정상적으로 작동하는 것을 알 수 있습니다.
/usr/local/spark/sbin/start-all.ship_adress:8080 들어가면 클러스터링 상태를 확인할 수 있습니다.
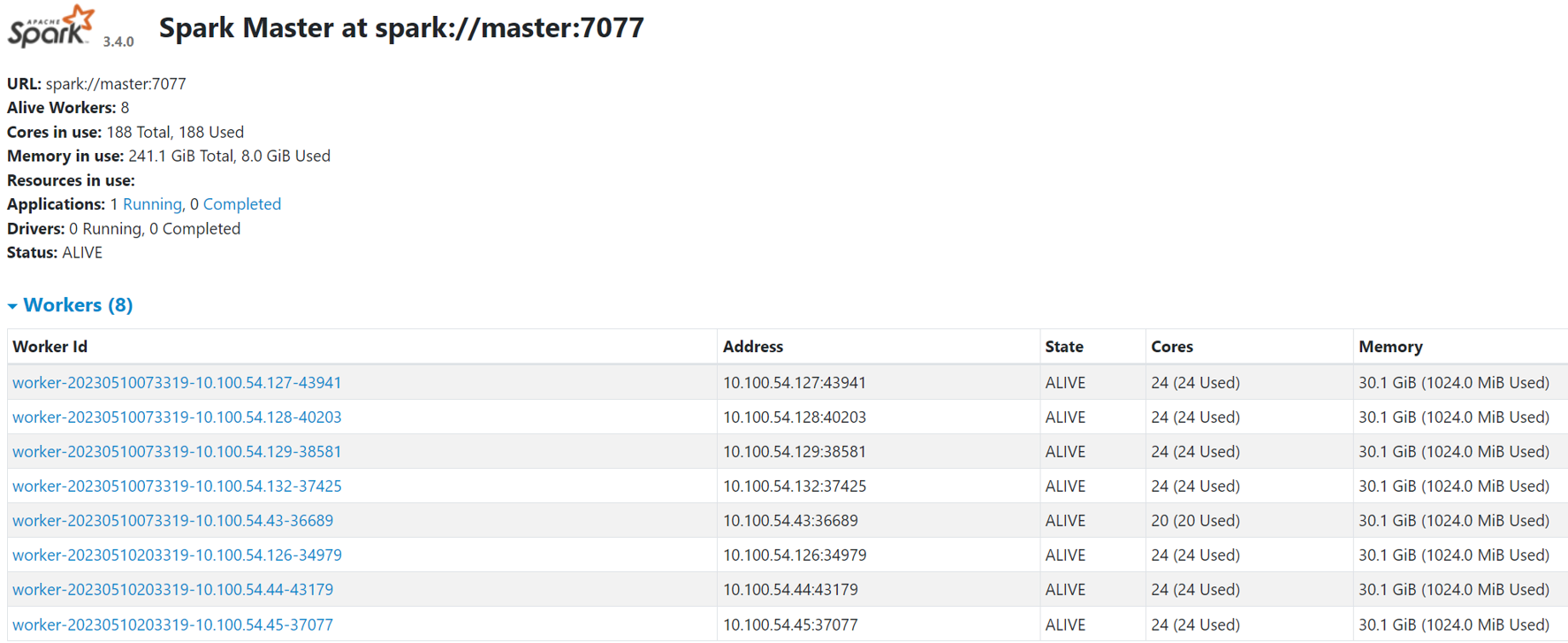
3. 스파크 애플리케이션 실행
클러스터링을 성공했으니 Spark 애플리케이션을 실행해보겠습니다.
정상적으로 되었습니다.
#URL 확인
pyspark --master spark://master:7077
4. 스파크 종료
애플리케이션을 종료하고 싶을 땐 URL에서 (kill) 버튼을 통해 쉽게 종료할 수 있습니다.
클러스터링을 종료하고 싶을 땐 /sbin/stop-all.sh를 통해 종료할 수 있습니다.
/usr/local/spark/sbin/stop-all.sh참고
빅공잼님의 영상을 참고하였습니다.
https://www.youtube.com/watch?v=qiEQ7gnYRfk
