
숫자형
print(round(3.14151926535, 2))
print(8.0 // 3)
print(8 // 3)
print(2.0 ** 3)
print(2 / 4)
print(4 / 2) // 나눗셈은 정수 끼리 나누어도 소수형이 나온다.
</> 실행 결과
3.14
2.0
2
8.0
0.5
2.0형변환(Type conversion)
print(int(3.5))
print(int("2") + int("5"))
print(float(3))
print(str(2) + str(5))
</> 실행 결과
3
7
3.0
25format 다루기
year = 2022
month = 8
day = 7
print("오늘은 {}년 {}월 {}일입니다.".format(year, month, day))
date_string = "내일은 {}년 {}월 {}입니다."
print(date_string.format(year, month, day + 1))
print("저는 {1}, {0}, {2}를 좋아합니다!".format("박지성", "유재석", "빌게이츠"))
// 순서 바뀜
print("저는 {}, {}, {}를 좋아합니다!".format("박지성", "유재석", "빌게이츠"))
num1 = 1
num2 = 3
print("{0} 나누기 {1}은 {2:.2f}입니다.".format(num1, num2, num1 / num2))- 가장 오래된 방식 (% 기호)
name = "조원준"
age = 23
print("제 이름은 %s이고 %d살입니다." % (name, age))
제 이름은 조원준이고 23살입니다.- 현재 가장 많이 쓰는 방식 (format 메소드)
name = "조원준"
age = 23
print("제 이름은 {}이고 {}살입니다.".format(name, age))
제 이름은 조원준이고 23살입니다.- 새로운 방식 (f-string)
name = "조원준"
age = 23
print(f"제 이름은 {name}이고 {age}살입니다.")
제 이름은 조원준이고 23살입니다.불린형(boolean)
print(2 > 1 and "Hello" == "Hello")
print(not not True)
print(7 == 7 or (4 < 3 and 12 > 10))
x = 3
print(x > 4 or not (x < 3 or x == 3))
</> 실행 결과
True
True
True
Falsetype 함수
print(type(3))
print(type("3"))
print(type(3.0))
print(type(True))
def hello():
print("Hello World!")
print(type(hello))
print(type(print))
</> 실행 결과
<class 'int'>
<class 'str'>
<class 'float'>
<class 'bool'>
<class 'function'>
<class 'builtin_function_or_method'>
함수
-
return문이 없으면 None을 return


-
parameter
파라미터에게 '기본값(default value)'을 설정할 수 있다. 기본값을 설정해 두면, 함수를 호출할 때 꼭 파라미터에 값을 안 넘겨 줘도 된다. 이런 파라미터를 '옵셔널 파라미터(optional parameter)'라고 한다.
def myself(name, age, nationality="한국"):
print("내 이름은 {}".format(name))
print("나이는 {}살".format(age))
print("국적은 {}".format(nationality))
myself("코드잇", 1, "미국") # 옵셔널 파라미터를 제공하는 경우
print()
myself("코드잇", 1) # 옵셔널 파라미터를 제공하지 않는 경우
내 이름은 코드잇
나이는 1살
국적은 미국
내 이름은 코드잇
나이는 1살
국적은 한국
-----------------------------------------------------------------------------------------
옵셔널 파라미터는 꼭 마지막에!
참고로 옵셔널 파라미터는 모두 마지막에 있어야 한다. 아래처럼 옵셔널 파라미터를 중간에 넣으면 오류가 뜬다.
-----------------------------------------------------------------------------------------
def myself(name, nationality="한국", age):
print("내 이름은 {}".format(name))
print("나이는 {}살".format(age))
print("국적은 {}".format(nationality))
myself("코드잇", 1) # 기본값이 설정된 파라미터를 바꾸지 않을 때
print()
myself("코드잇", "미국", 1) # 기본값이 설정된 파라미터를 바꾸었을 때
File "myself.py", line 1
def myself(name, nationality = "한국", age):
^
SyntaxError: non-default argument follows default argumentscope


파이썬 스타일 가이드
이름
- 이름 규칙
모든 변수와 함수 이름은 소문자로 써 주시고, 여러 단어일 경우 _로 나눠 주세요.(스네이크 케이스)
# bad
someVariableName = 1
SomeVariableName = 1
def someFunctionName():
print("Hello")
# good
some_variable_name = 1
def some_function_name():
print("Hello")- 모든 상수 이름은 대문자로 써주시고, 여러 단어일 경우 _로 나눠주세요.
# bad
someConstant = 3.14
SomeConstant = 3.14
some_constant = 3.14
# good
SOME_CONSTANT = 3.14- 의미 있는 이름
# bad (의미 없는 이름)
a = 2
b = 3.14
print(b * a * a)
# good (의미 있는 이름)
radius = 2
pi = 3.14
print(pi * radius * radius)
# bad (의미 없는 이름)
def do_something():
print("Hello, world!")
# good (의미 있는 이름)
def say_hello():
print("Hello, world!")화이트 스페이스
- 들여쓰기
들여쓰기는 무조건 스페이스 4개를 사용하세요.
# bad (스페이스 2개)
def do_something():
print("Hello, world!")
# bad (스페이스 8개)
i = 0
while i < 10:
print(i)
# good (스페이스 4개)
def say_hello():
print("Hello, world!")- 함수 정의
함수 정의 위아래로 빈 줄이 두 개씩 있어야 합니다. 하지만 파일의 첫 줄이 함수 정의인 경우 해당 함수 위에는 빈 줄이 없어도 됩니다.
# bad
def a():
print('a')
def b():
print('b')
def c():
print('c')
# good
def a():
print('a')
def b():
print('b')
def c():
print('c')- 괄호 안
괄호 바로 안에는 띄어쓰기를 하지 마세요.
# bad
spam( ham[ 1 ], { eggs: 2 } )
# good
spam(ham[1], {eggs: 2})- 함수 괄호
함수를 정의하거나 호출할 때, 함수 이름과 괄호 사이에 띄어쓰기를 하지 마세요.
# bad
def spam (x):
print (x + 2)
spam (1)
# good
def spam(x):
print(x + 2)
spam(1)- 쉼표
쉼표 앞에는 띄어쓰기를 하지 마세요.
# bad
print(x , y)
# good
print(x, y)- 지정 연산자
지정 연산자 앞뒤로 띄어쓰기를 하나씩만 해 주세요.
# bad
x=1
x = 1
# good
x = 1- 연산자
기본적으로는 연산자 앞뒤로 띄어쓰기를 하나씩 합니다.
# bad
i=i+1
submitted +=1
# good
i = i + 1
submitted += 1- 하지만 연산의 "우선 순위"를 강조하기 위해서는, 연산자 앞뒤로 띄어쓰기를 붙이는 것을 권장합니다.
# bad
x = x * 2 - 1
hypot2 = x * x + y * y
c = (a + b) * (a - b)
# good
x = x*2 - 1
hypot2 = x*x + y*y
c = (a+b) * (a-b)- 코멘트
일반 코드와 같은 줄에 코멘트를 쓸 경우, 코멘트 앞에 띄어쓰기 최소 두 개를 해 주세요.
# bad
x = x + 1# 코멘트
# good
x = x + 1 # 코멘트피보나치 수열 구현
previous = 0
current = 1
i = 1
while i <= 50:
print(current)
previous, current = current, current + previous
i += 1간단한 구구단
i = 1
while i <= 9:
j = 1
while j <= 9:
print("{} * {} = {}".format(i, j, i * j))
j += 1
i += 1리스트
numbers = [2, 3, 5, 7, 11, 13]
names = ["윤수", "혜린", "태호", "영훈"]
print(numbers[-1])
print(numbers[-6])
#리스트 슬라이싱(list slicing)
print(numbers[0:4]) # 인덱스 0부터 3까지
print(numbers[2:]) # 인덱스 2부터 끝까지
numbers[0] = 7
print(numbers[:5]) # 인덱스 0부터 4까지
numbers[0] = numbers[0] + numbers[1]
print(numbers)
</> 실행 결과
13
2
[2, 3, 5, 7]
[5, 7, 11, 13]
[7, 3, 5, 7, 11]
[10, 3, 5, 7, 11, 13]- 리스트 함수
numbers = []
# 오른쪽 끝에 값 추가 연산
numbers.append(5)
numbers.append(8)
print(numbers)
print(len(numbers))
numbers2 = [2,3,5,7,11,13,17,19]
# 삭제 연산
del numbers2[3]
print(numbers2)
# 삽입 연산
numbers2.insert(4, 37)
print(numbers2)
</> 실행 결과
[5, 8]
2
[2, 3, 5, 11, 13, 17, 19]
[2, 3, 5, 11, 37, 13, 17, 19]- 리스트 정렬
numbers = [19, 13, 2, 5, 3, 11, 7, 17]
new_list = sorted(numbers) # 오름차순 정렬
print(new_list)
print(numbers) # 변하지 않음
new_list = sorted(numbers, reverse = True) # 내림차순 정렬
print(new_list)
print(numbers) # 변하지 않음
numbers.sort()
print(numbers) # 변함
numbers.sort(reverse = True)
print(numbers) # 변함
</> 실행 결과
[2, 3, 5, 7, 11, 13, 17, 19]
[19, 13, 2, 5, 3, 11, 7, 17]
[19, 17, 13, 11, 7, 5, 3, 2]
[19, 13, 2, 5, 3, 11, 7, 17]
[2, 3, 5, 7, 11, 13, 17, 19]

- 리스트 화씨, 섭씨 변환
# 화씨 온도에서 섭씨 온도로 바꿔 주는 함수
def fahrenheit_to_celsius(fahrenheit):
return (fahrenheit - 32) * 5 / 9
temperature_list = [40, 15, 32, 64, -4, 11]
print("화씨 온도 리스트: {}".format(temperature_list)) # 화씨 온도 출력
# 리스트의 값들을 화씨에서 섭씨로 변환하는 코드
i = 0
while i < len(temperature_list):
temperature_list[i] = round(fahrenheit_to_celsius(temperature_list[i]), 1)
i += 1
print("섭씨 온도 리스트: {}".format(temperature_list)) # 섭씨 온도 출력- 환전 서비스
# 원화(₩)에서 달러($)로 변환하는 함수
def krw_to_usd(krw):
return krw / 1000 # 1,000원 당 1달러
# 달러($)에서 엔화(¥)로 변환하는 함수
def usd_to_jpy(usd):
return usd / 8 * 1000
# 원화(₩)로 각각 얼마인가요?
prices = [34000, 13000, 5000, 21000, 1000, 2000, 8000, 3000]
print("한국 화폐: " + str(prices))
# prices를 원화(₩)에서 달러($)로 변환하기
i = 0
while i < len(prices):
prices[i] = krw_to_usd(prices[i])
i += 1
# 달러($)로 각각 얼마인가요?
print("미국 화폐: " + str(prices))
# prices를 달러($)에서 엔화(¥)로 변환하기
i = 0
while i < len(prices):
prices[i] = usd_to_jpy(prices[i])
i += 1
# 엔화(¥)로 각각 얼마인가요?
print("일본 화폐: " + str(prices))- 리스트 함수 활용
# 빈 리스트 만들기
numbers = []
print(numbers)
# numbers에 값들 추가
numbers.append(1)
numbers.append(7)
numbers.append(3)
numbers.append(6)
numbers.append(5)
numbers.append(2)
numbers.append(13)
numbers.append(14)
print(numbers)
************************************
# numbers에서 홀수 제거
i = 0
while i < len(numbers):
if numbers[i] % 2 == 1:
del numbers[i]
else:
i += 1
print(numbers)
************************************
# numbers의 인덱스 0 자리에 20이라는 값 삽입
numbers.insert(0, 20)
print(numbers)
# numbers를 정렬해서 출력
numbers.sort()
print(numbers)
리스트에서 값의 존재 확인하기
# value가 some_list의 요소인지 확인
def in_list(some_list, value):
i = 0
while i < len(some_list):
# some_list에서 value를 찾으면 True를 리턴
if some_list[i] == value:
return True
i = i + 1
# 만약 some_list에서 value를 발견하지 못했으면 False를 리턴
return False
# 테스트
primes = [2, 3, 5, 7, 11, 13, 17, 19, 23]
print(in_list(primes, 7))
print(in_list(primes, 12))
True
False쓰는데 아주 어렵지는 않습니다. 하지만 리스트에 값의 존재를 확인하는 것은 너무 자주 있는 일이라서 파이썬에 이미 이 기능이 내장되어 있습니다. in이라는 키워드를 쓰면 됩니다.
primes = [2, 3, 5, 7, 11, 13, 17, 19, 23]
print(7 in primes)
print(12 in primes)
True
False거꾸로 값이 없는지 확인하려면 in 앞에 not을 붙이면 됩니다.
primes = [2, 3, 5, 7, 11, 13, 17, 19, 23]
print(7 not in primes)
print(12 not in primes)
False
True- 리스트 안의 리스트 (Nested List)
리스트 안에는 또 다른 리스트가 있을 수 있다.
# 세 번의 시험을 보는 수업
grades = [[62, 75, 77], [78, 81, 86], [85, 91, 89]]
# 첫 번째 학생의 성적
print(grades[0])
# 세 번째 학생의 성적
print(grades[2])
# 첫 번째 학생의 첫 번째 시험 성적
print(grades[0][0])
# 세 번째 학생의 두 번째 시험 성적
print(grades[2][1])
# 첫 번째 시험의 평균
print((grades[0][0] + grades[1][0] + grades[2][0]) / 3)
[62, 75, 77]
[85, 91, 89]
62
91
75.0
sort 메소드저번에 정렬된 새로운 리스트를 리턴시켜주는 sorted 함수를 보여드렸습니다. some_list.sort()는 새로운 리스트를 생성하지 않고 some_list를 정렬된 상태로 바꿔줍니다.
numbers = [5, 3, 7, 1]
numbers.sort()
print(numbers)
[1, 3, 5, 7]- reverse 메소드
some_list.reverse()는 some_list의 원소들을 뒤집어진 순서로 배치합니다.
numbers = [5, 3, 7, 1]
numbers.reverse()
print(numbers)
[1, 7, 3, 5]- index 메소드
some_list.index(x)는some_list에서 x의 값을 갖고 있는 원소의 인덱스를 리턴해줍니다.
members = ["영훈", "윤수", "태호", "혜린"]
print(members.index("윤수"))
print(members.index("태호"))
1
2- remove 메소드
some_list.remove(x)는some_list에서 첫 번째로 x의 값을 갖고 있는 원소를 삭제해줍니다.
fruits = ["딸기", "당근", "파인애플", "수박", "참외", "메론"]
fruits.remove("파인애플")
print(fruits)
['딸기', '당근', '수박', '참외', '메론']range 함수



- 장점
깔끔하고 간편하고 메모리 효율성이 좋다.
# 인덱스와 원소 출력
for i in range(len(numbers)):
print(i, numbers[i])- 피타고라스 삼조
for a in range(1, 400):
for b in range(1, 400):
c = 400 - a - b
if a * a + b * b == c * c and a < b < c:
print(a * b * c)- 리스트 뒤집기1
numbers = [2, 3, 5, 7, 11, 13, 17, 19]
# 리스트 뒤집기
for left in range(len(numbers) // 2):
# 인덱스 left와 대칭인 인덱스 right 계산
right = len(numbers) - left - 1
# 위치 바꾸기
temp = numbers[left]
numbers[left] = numbers[right]
numbers[right] = temp
print("뒤집어진 리스트: " + str(numbers))- 리스트 뒤집기2 (튜플사용)
numbers = [2, 3, 5, 7, 11, 13, 17, 19]
# 리스트 뒤집기
for left in range(len(numbers) // 2):
# 인덱스 left와 대칭인 인덱스 right 계산
right = len(numbers) - left - 1
# 위치 바꾸기
numbers[right], numbers[left] = numbers[left], numbers[right]
print("뒤집어진 리스트: " + str(numbers))딕셔너리
# 사전 dictionary
# key-value pair (키- 값 쌍)
# 순서 없다, 해시
my_dictionary = {
5: 25,
2: 4,
3: 9
}
print(type(my_dictionary))
print(my_dictionary[3])
my_dictionary[9] = 81 # 값추가
print(my_dictionary)- 딕셔너리 활용
my_famaily = {
'엄마': '이주빈',
'아빠': '로니콜먼',
'아들': '강경원',
'딸': '츄'
}
print(my_famaily.values())
print('츄' in my_famaily.values())
for key in my_famaily.keys():
value = my_famaily[key]
print(key, value)
for key, value in my_famaily.items():
print(key, value)- 사전 뒤집기
# 언어 사전의 단어와 뜻을 서로 바꿔주는 함수
def reverse_dict(dict):
new_dict = {} # 새로운 사전
# dict의 key와 value를 뒤집어서 new_dict에 저장
for key, value in dict.items():
new_dict[value] = key
return new_dict # 변환한 새로운 사전 리턴
# 영-한 단어장
vocab = {
'sanitizer': '살균제',
'ambition': '야망',
'conscience': '양심',
'civilization': '문명',
'privilege': '특권',
'principles': '원칙'
}
# 기존 단어장 출력
print("영-한 단어장\n{}\n".format(vocab))
# 변환된 단어장 출력
reversed_vocab = reverse_dict(vocab)
print("한-영 단어장\n{}".format(reversed_vocab))- 투표 집계하기
# 투표 결과 리스트
votes = ['김영자', '강승기', '최만수', '김영자', '강승기', '강승기', '최만수', '김영자', \
'최만수', '김영자', '최만수', '김영자', '김영자', '최만수', '최만수', '최만수', '강승기', \
'강승기', '김영자', '김영자', '최만수', '김영자', '김영자', '강승기', '김영자']
# 후보별 득표수 사전
vote_counter = {}
# 리스트 votes를 이용해서 사전 vote_counter를 정리하기
for name in votes:
if name not in vote_counter:
vote_counter[name] = 1
else:
vote_counter[name] += 1
# 후보별 득표수 출력
print(vote_counter)Aliasing
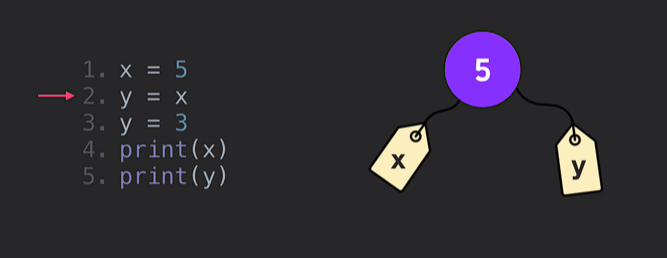
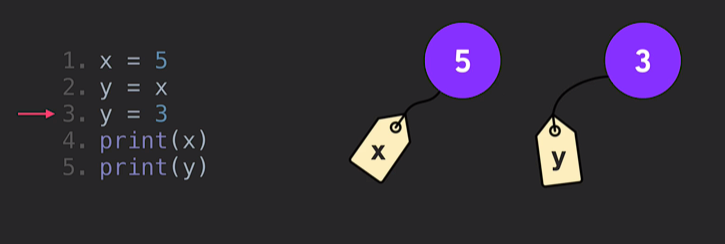

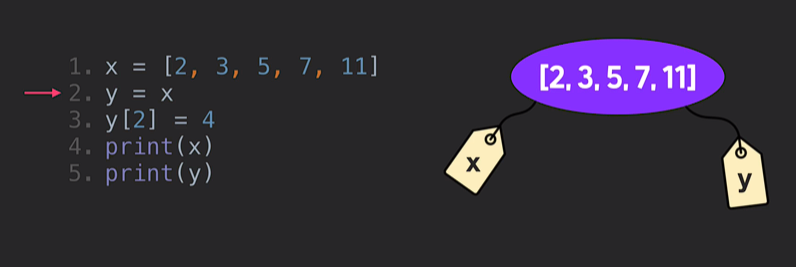
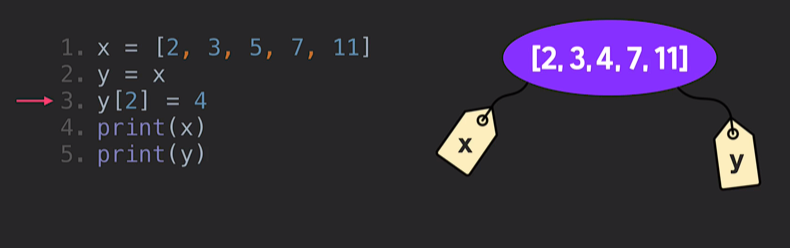
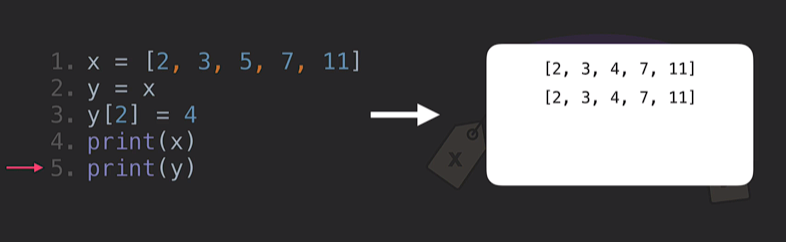
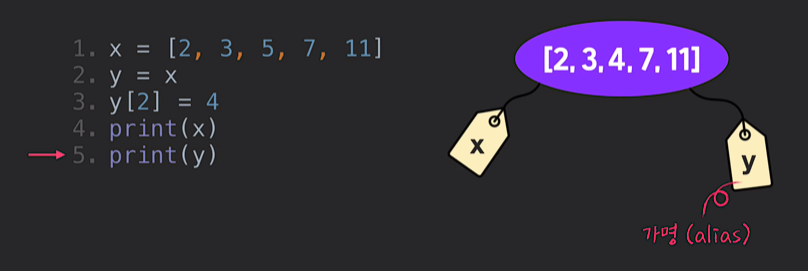
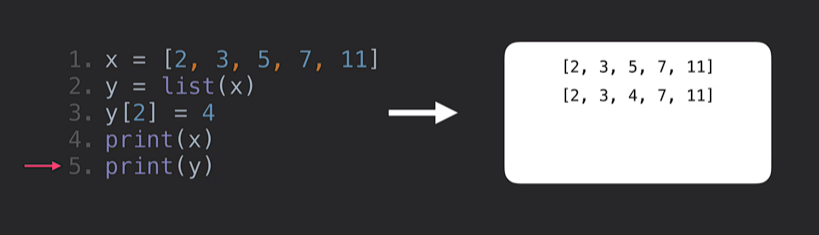
- 그럼 어떻게? 이렇게!


리스트와 문자열 정리
- 리스트와 문자열이 구조적으로 비슷하기 때문에 리스트 다루듯이 문자열 다루면 된다. 그리고 문자열 다루듯이 리스트를 다루면 편하다.
- 다만 리스트는 가변 객체라서 수정이 가능한데 문자열은 불변객체이므로 수정이 불가능하다.
- 인덱싱 (Indexing)
두 자료형은 공통적으로 인덱싱이 가능합니다.
# 알파벳 리스트의 인덱싱
alphabets_list = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J']
print(alphabets_list[0])
print(alphabets_list[1])
print(alphabets_list[4])
print(alphabets_list[-1])
# 알파벳 문자열의 인덱싱
alphabets_string = 'ABCDEFGHIJ'
print(alphabets_string[0])
print(alphabets_string[1])
print(alphabets_string[4])
print(alphabets_string[-1])
A
B
E
J
A
B
E
J- for 반복문
두 자료형은 공통적으로 인덱싱이 가능합니다. 따라서 for 반복문에도 활용할 수 있습니다.
# 알파벳 리스트의 반복문
alphabets_list = ['C', 'O', 'D', 'E', 'I', 'T']
for alphabet in alphabets_list:
print(alphabet)
# 알파벳 문자열의 반복문
alphabets_string = 'CODEIT'
for alphabet in alphabets_string:
print(alphabet)
C
O
D
E
I
T
C
O
D
E
I
T- 슬라이싱 (Slicing)
두 자료형은 공통적으로 슬라이싱이 가능합니다.
# 알파벳 리스트의 슬라이싱
alphabets_list = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J']
print(alphabets_list[0:5])
print(alphabets_list[4:])
print(alphabets_list[:4])
# 알파벳 문자열의 슬라이싱
alphabets_string = 'ABCDEFGHIJ'
print(alphabets_string[0:5])
print(alphabets_string[4:])
print(alphabets_string[:4])
['A', 'B', 'C', 'D', 'E']
['E', 'F', 'G', 'H', 'I', 'J']
['A', 'B', 'C', 'D']
ABCDE
EFGHIJ
ABCD- 덧셈 연산
두 자료형에게 모두 덧셈은 "연결"하는 연산입니다.
# 리스트의 덧셈 연산
list1 = [1, 2, 3, 4]
list2 = [5, 6, 7, 8]
list3 = list1 + list2
print(list3)
# 문자열의 덧셈 연산
string1 = '1234'
string2 = '5678'
string3 = string1 + string2
print(string3)
[1, 2, 3, 4, 5, 6, 7, 8]
12345678- len 함수
두 자료형은 모두 길이를 재는 len 함수를 쓸 수 있습니다.
# 리스트의 길이 재기
print(len(['H', 'E', 'L', 'L', 'O']))
# 문자열의 길이 재기
print(len("Hello, world!"))
5
13- Mutable (수정 가능) vs. Immutable (수정 불가능)
하지만 차이점이 있습니다. 리스트는 데이터를 바꿀 수 있지만, 문자열은 데이터를 바꿀 수 없다는 것입니다. 리스트와 같이 수정 가능한 자료형을 'mutable'한 자료형이라고 부르고, 문자열과 같이 수정 불가능한 자료형을 'immutable'한 자료형이라고 부릅니다. 숫자, 불린, 문자열은 모두 immutable한 자료형입니다.
# 리스트 데이터 바꾸기
numbers = [1, 2, 3, 4]
numbers[0] = 5
print(numbers)
[5, 2, 3, 4]리스트 numbers의 인덱스 0에 5를 새롭게 지정해주었습니다. [5, 2, 3, 4]가 출력되었습니다. 이처럼 리스트는 데이터의 생성, 삭제, 수정이 가능합니다.
# 문자열 데이터 바꾸기
name = "codeit"
name[0] = "C"
print(name)
Traceback (most recent call last):
File "untitled.py", line 3, in <module>
name[0] = "C"
TypeError: 'str' object does not support item assignment문자열 name의 인덱스 0 에 "C"를 새롭게 지정해주었더니 오류가 나왔습니다. TypeError: 'str' object does not support item assignment는 문자열은 변형이 불가능하다는 메시지입니다. 이처럼 문자열은 리스트와 달리 데이터의 생성, 삭제, 수정이 불가능합니다.
자릿수 합 구하기
# 자리수 합 리턴
def sum_digit(num):
total = 0
str_num = str(num)
for digit in str_num:
total += int(digit)
return total
# sum_digit(1)부터 sum_digit(1000)까지의 합 구하기
digit_total = 0
for i in range(1, 1001):
digit_total += sum_digit(i)
print(digit_total)주민등록번호 가리기
def mask_security_number(security_number):
# security_number를 리스트로 변환
num_list = list(security_number)
# 마지막 네 값을 *로 대체
for i in range(len(num_list) - 4, len(num_list)):
num_list[i] = "*"
# 리스트를 문자열로 복구
total_str = ""
for i in range(len(num_list)):
total_str += num_list[i]
return total_strdef mask_security_number(security_number):
num_list = list(security_number)
# 마지막 네 값을 *로 대체
for i in range(len(num_list) - 4, len(num_list)):
num_list[i] = '*'
# 리스트를 문자열로 복구하여 반환
return ''.join(num_list)def mask_security_number(security_number):
return security_number[:-4] + '****'팰린드롬
def is_palindrome(word):
for left in range(len(word) // 2):
# 한 쌍이라도 일치하지 않으면 바로 False를 리턴하고 함수를 끝냄
right = len(word) - left - 1
if word[left] != word[right]:
return False
# for문에서 나왔다면 모든 쌍이 일치
return Truestrip
- 문자열 양쪽의 white space를 제거해준다. 문자열 중간은 제거안함
# strip
print(" abc def ".strip())
print(" \tabc \n def\n\n\n".strip())
</> 실행 결과
abc def
abc
def
split
- separator를 기준으로 문자열을 잘라서 리스트로 출력
my_string = "1. 2. 3. 4. 5. 6"
print(my_string.split(". "))
print(my_string.split("."))
full_name = "Kim, Yuna"
print(full_name.split(", "))
print(" \n\n 2 \t 3 \n 5 7 11 \n\n".split())
numbers = " \n\n 2 \t 3 \n 5 7 11 \n\n".split()
# separator를 넘겨주지 않으면 화이트 스페이스가 자동으로 넘어감
print(int(numbers[0]) + int(numbers[1]))실습
- 파일 읽어들여서 하루 평균 매출 구하기
with open('data/chicken.txt', 'r') as f: # data 폴더에 있는 chicken.txt 파일을 읽는다
days = 0
sum = 0
for line in f:
sales = line.strip().split(": ") # 리스트 형태로 sales에 저장
days += 1
sum += int(sales[1])
print(sum / days)- data/chicken.txt
1일: 453400
2일: 388600
3일: 485300
4일: 477900
5일: 432100
6일: 665300
7일: 592500
8일: 465200
9일: 413200
10일: 523000
11일: 488600
12일: 431500
13일: 682300
14일: 633700
15일: 482300
16일: 391400
17일: 512500
18일: 488900
19일: 434500
20일: 645200
21일: 599200
22일: 472400
23일: 469100
24일: 381400
25일: 425800
26일: 512900
27일: 723000
28일: 613600
29일: 416700
30일: 385600
31일: 472300- 파일 쓰기
with open('vocabulary.txt', 'w') as f:
while True:
english_word = input('영어 단어를 입력하세요: ')
if english_word == 'q':
break
korean_word = input('한국어 뜻을 입력하세요: ')
if korean_word == 'q':
break
f.write('{}: {}\n'.format(english_word, korean_word))- 단어 퀴즈
with open('vocabulary.txt', 'r') as f:
for line in f:
data = line.strip().split(": ")
english_word, korean_word = data[0], data[1]
guess = input("{}:".format(korean_word))
if guess == english_word:
print("맞았습니다!\n")
else
print("아쉽습니다. 정답은 {}입니다.\n".format(english_word))- 고급 단어장
import random
vocab = {}
with open('vocabulary.txt', 'r') as f:
for line in f:
data = line.strip().split(": ")
english_word, korean_word = data[0], data[1]
vocab[english_word] = korean_word
keys = list(vocab.keys())
while True:
index = random.randint(0, len(keys) - 1)
english_word = keys[index]
korean_word = vocab[english_word]
guess = input("{}:".format(korean_word))
if guess == "q":
break
if guess == english_word:
print("맞았습니다!\n")
else:
print("틀렸습니다. 정답은 {}입니다.\n".format(english_word))- 프로젝트: 로또 시뮬레이션
from random import randint
def generate_numbers(n):
rand_list = []
while len(rand_list) < n:
rand_num = randint(1, 45)
if rand_num not in rand_list:
rand_list.append(rand_num)
return rand_list
def draw_winning_numbers():
numbers = generate_numbers(7)
return sorted(numbers[:6]) + numbers[6:]
def count_matching_numbers(numbers, winning_numbers):
cnt = 0
for num in numbers:
if num in winning_numbers:
cnt += 1
return cnt
def check(numbers, winning_numbers):
count = count_matching_numbers(numbers, winning_numbers[:6])
bonus_count = count_matching_numbers(numbers, winning_numbers[6:])
if count == 6:
return 1000000000
elif count == 5 and bonus_count == 1:
return 50000000
elif count == 5:
return 1000000
elif count == 4:
return 50000
elif count == 3:
return 5000
else:
return 0- 프로젝트: 숫자야구
from random import randint
def generate_numbers():
numbers = []
while len(numbers) < 3:
number = randint(0, 9)
if number not in numbers:
numbers.append(number)
print("0과 9 사이의 서로 다른 숫자 3개를 랜덤한 순서로 뽑았습니다.\n")
return numbers
def take_guess():
print("숫자 3개를 하나씩 차례대로 입력하세요.")
new_guess = []
for i in range(1, 4):
guess = int(input("f{i}번째 숫자를 입력하세요: "))
if guess < 0 or guess > 9:
print("범위를 벗어나는 숫자입니다. 다시 입력하세요.\n")
elif guess in new_guess:
print("중복되는 숫자입니다. 다시입력하세요.\n")
else:
new_guess.append(guess)
return new_guess
def get_score(guesses, solution):
strike_count = 0
ball_count = 0
for i in range(len(guesses)):
if guesses[i] == solution[i]:
strike_count += 1
elif guesses[i] != solution[i] and guesses[i] in solution:
ball_count += 1
return strike_count, ball_count
# 여기서부터 게임 시작!
ANSWER = generate_numbers()
tries = 0
generate_numbers()
while (True):
user_guess = take_guess()
s, b = get_score(user_guess, ANSWER)
print("{}S {}B\n".format(s, b))
tries += 1
if s == 3:
break
print("축하합니다. {}번 만에 숫자 3개의 값과 위치를 모두 맞추셨습니다.".format(tries))
어제의 나보다 딱 하나만 더 배우자는 작은 목표를 매일 실천하겠습니다. 그렇게 배운 것을 적용하고, 응용하고, 공유하겠습니다.