<데이터베이스>
백엔드 개발자로서 굉장히 중요한 내용.
- 데이터베이스란?
- 컴퓨터 시스템에 저장된 정보 또는 데이터의 집합(데이터를 많이 모아서 저장해놓은 곳)
- 데이터베이스 관리 시스템(DBMS)로 제어.(Oracle)
-> 데이터가 많이 모여있는 것을 관리하는 것을 통칭하는걸 데이터베이스라고 한다. - 관계형 데이터 베이스(데이터 간의 관계에 집중)와 비관계형 데이터 베이스(관계보다는 빠르게 저장하고 불러오는데 집중)가 있음
- RDBMS란? 왜 관계형 테이블을 쓰는가?
- 관계형 데이터 베이스.
- TABLE이란? Column과 Row 그리고 Primary Key란?
- 모든 데이터의 형태. "표 안에 값은 무조건 하나만 들어가야 함."
- 컬럼은 항목(가로, 행), 로우는 실제 값(세로, 열)
prime key는 고유 키(실제 값을 가르키는 지표) ; 일종의 인덱스
- 테이블의 관계 , One to One, One to Many, Many to Many는 무엇인가? :
- 연결 방법
one-to-one(주인과 물건) : "각 테이블에 서로 맞는 고유의 키가 있다. 그 키를 참조하고 있다. 두 표에서 서로 키들이 있어서 맞추고 있는 것."
오직, 오로지, 오직 한 값만.
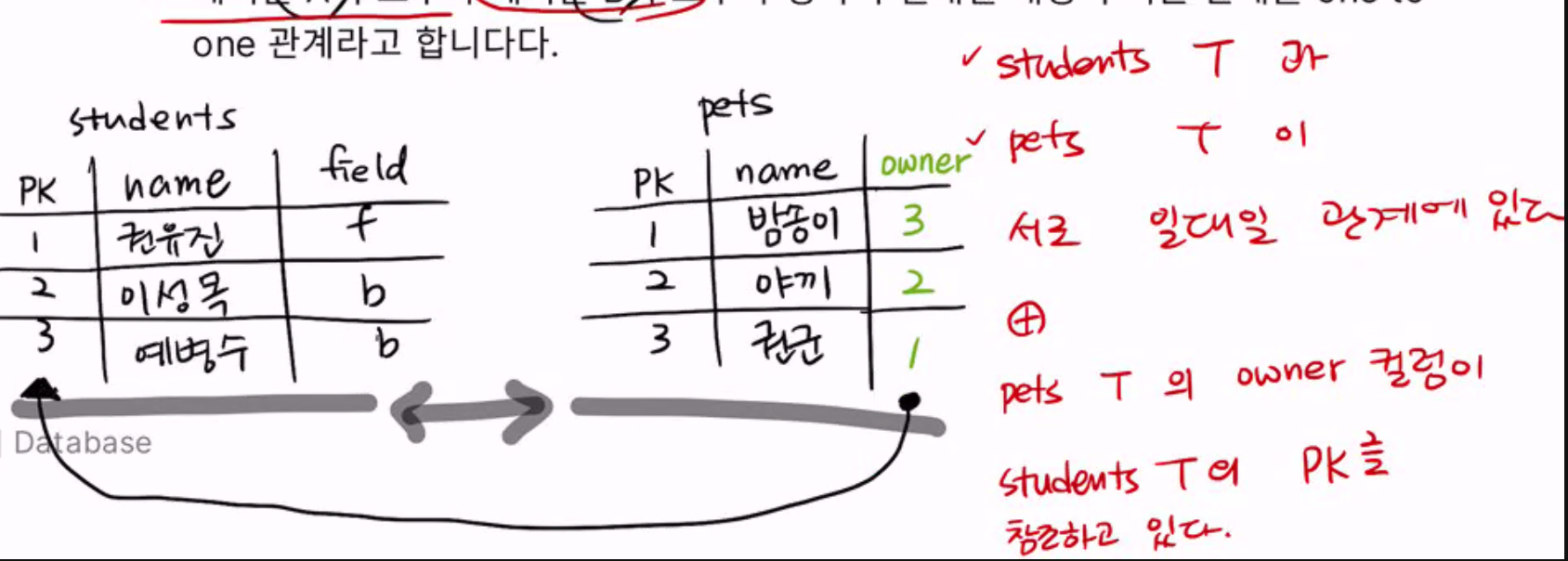
one-to-many(주인과 물건들) : 행 하나가 다른 테이블의 다수의 행에 연결, 1:N (N:1이 아님 ; 1,2 키가 1에 몰릴 때 ->방향에 따라 한 1:N이 고정이 되어 있음. 두 주인이 고양이 한 마리를 동시에 키우는 느낌, 두 사람이 같은 주문번호로 시키는 것이 아니라고 생각하기. ; 주종 관계의 예시일 뿐 그렇게 꼭 생각할 필욘 없음.)
"특히 key를 줘야할 때는 many 쪽에 줘야 데이터 중복이 생기지 않는다."
"중복을 획기적으로 줄여준다."
many-to-many(책과 작가 ; 책은 여러 작가에 의해 쓰일 수 있고 작가는 여러 책을 쓸 수 있다. ; 단편집과 작가와 책)
"N : N"
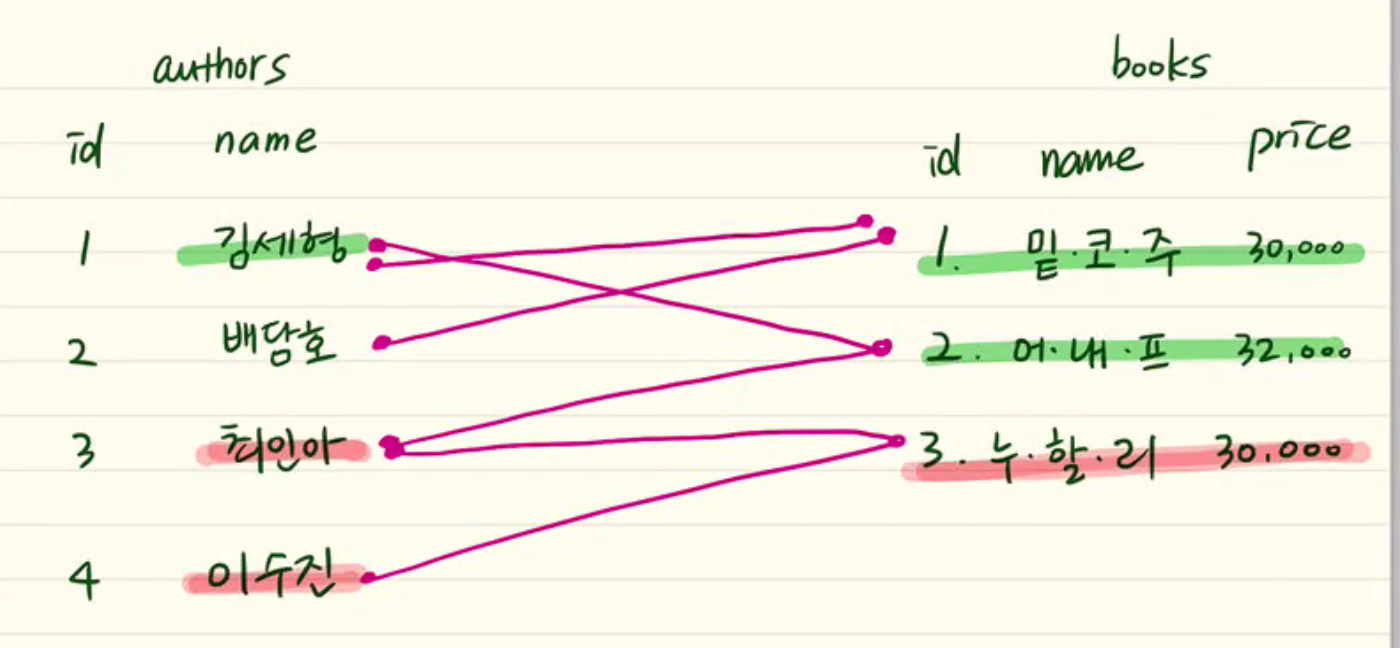
한 테이블에 한 데이터만 들어가야하므로 양쪽 모두 키를 쓸 수 없다
-> 그래서 연결 테이블을 하나 더 만든다.
-> 근데 중복이 또 된다? -> 둘 다 참조로 한다.(양 옆으로 참조)
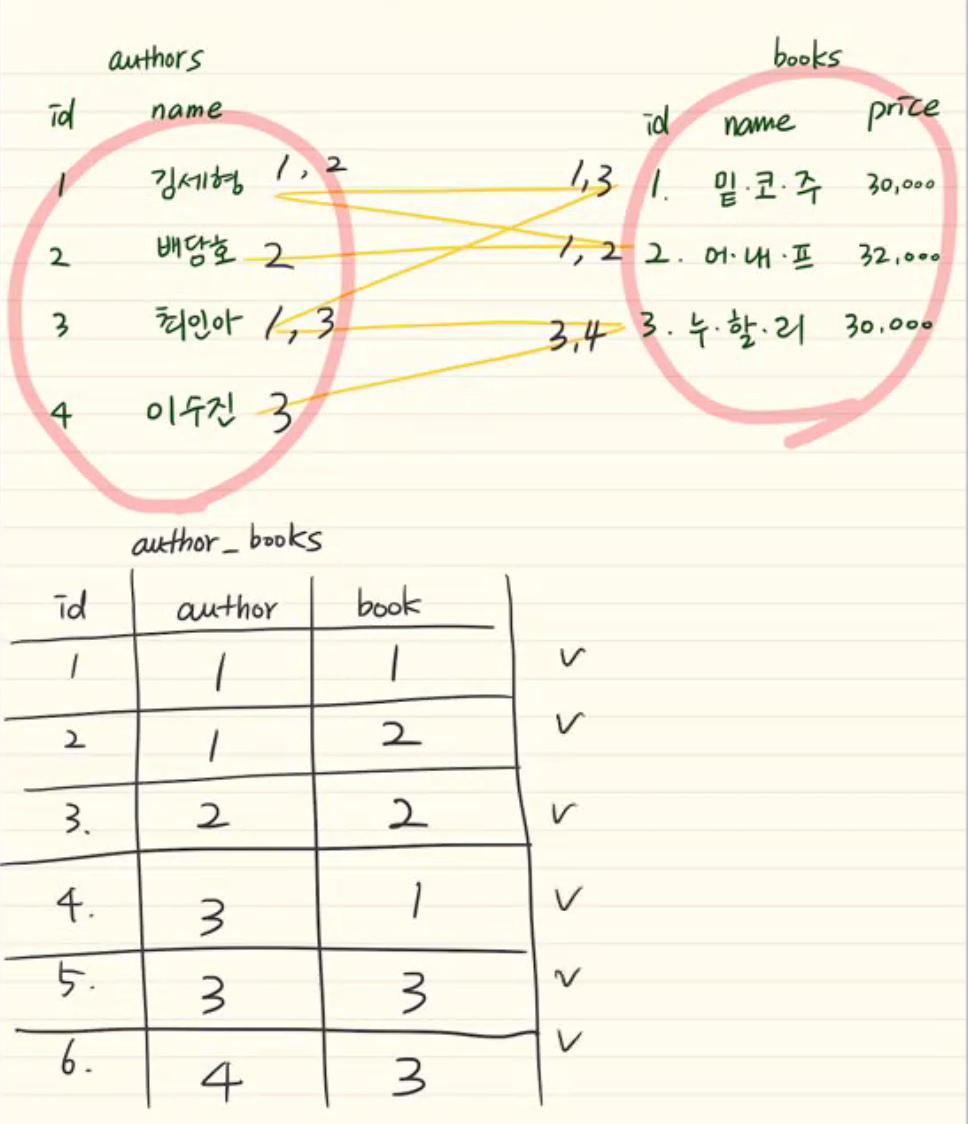
-> 데이터 양이 효과적으로 줄어든다.
-
테이블과 테이블 연결하는 방법 : foreign key 이용.
-
왜 테이블을 여러 개 써? : 중복을 방지하기. 그 중복으로 인한 잘못된 저장 피하기(회원 정보가 이름은 같은데 아이디가 다를 때), 데이터의 효율.
-> 필요할 때마다 테이블을 연결하면 디스크 자체를 효율적으로 쓸 수 있다.(정규화 : Normalization)
- ACID는 무엇인가? / 트랜잭션이란?
- 원자성 : 트랜잭션과 관련한 작업들이 부분적으로 실행되다가 중단되지 않게 하는 능력
e.g : 돈이 인출되다가 멈추는 것을 방지 - 일관성 : 트랜잭션이 성공적으로 완료하면 일관적으로 데이터베이스를 유지하는 것
e.g : 인출 및 송금이 완벽하게 완료되 상태를 유지 - 고립성 : 트랜잭션을 수행 시 다른 트랜잭션의 연산 작업이 끼어 들지 못 하게 보장하는 것.
e.g : 돈이 송금되는 과정에서 다른 연산 작업이 껴들지 못 하게 해 줌 - 지속성 : 성공적으로 수행된 트랜잭션이 영원히 반영되도록 해주는 것.
e.g : 이와 같은 과정이 영원히 반영.(어떤 점검에도)
그럼 트랜잭션이란??? :
ACID를 제공함으로 따라서 트랜잭션(일련의 작업들을 한번에 하나의 unit으로 실행하는것) 기능을 제공. 전체가 하나의 작업으로 취급되며 성공 or 실패로 나뉘는 것을 이야기 함.
은행에서 돈을 뺄 때 정전이 되었다 : 실패하지 않게 원상복구
- 관계형 데이터베이스 와 비관계형 데이터베이스의 차이는?
- SQL :
장 : 데이터를 효율적, 체계적으로 저장 및 관리 / 미리 저장하는 데이터 구조를 정의->데이터의 완전성 / 트랜잭션 가능 / 정형화된 데이터들 그리고 데이터 저장하는데 유리.
단 : 테이블 구조 변화에 유연하지 못 함(미리 지정) 이에 따라 확장성 또한 쉽지 않다.(서버 늘리는 것 만으로도 확장 쉽지 않음, 서버 분산 저장도 어려움, scale up으로 확장성이 됨)
- NoSQL : Foreign key 이런거 없고 테이블 아닌 객체로 되어 있음.
"{~~}"
장 : 데이터 구조 미리 정의하지 않아도 됨 -> 유연 / 확장성 / 방대한 양 저장하기 유리. 주로 비정형화 데이터 그리고 완전성이 상대적으로 덜 유리한 데이터를 저장하는데 유리
단 : 완전성 덜 보장 / 트랜잭션 X
- ERD 구성도로 모델링하기
- 모델링 : one to one 등 어떤 구조로 되어 있는지 결정하는 것.
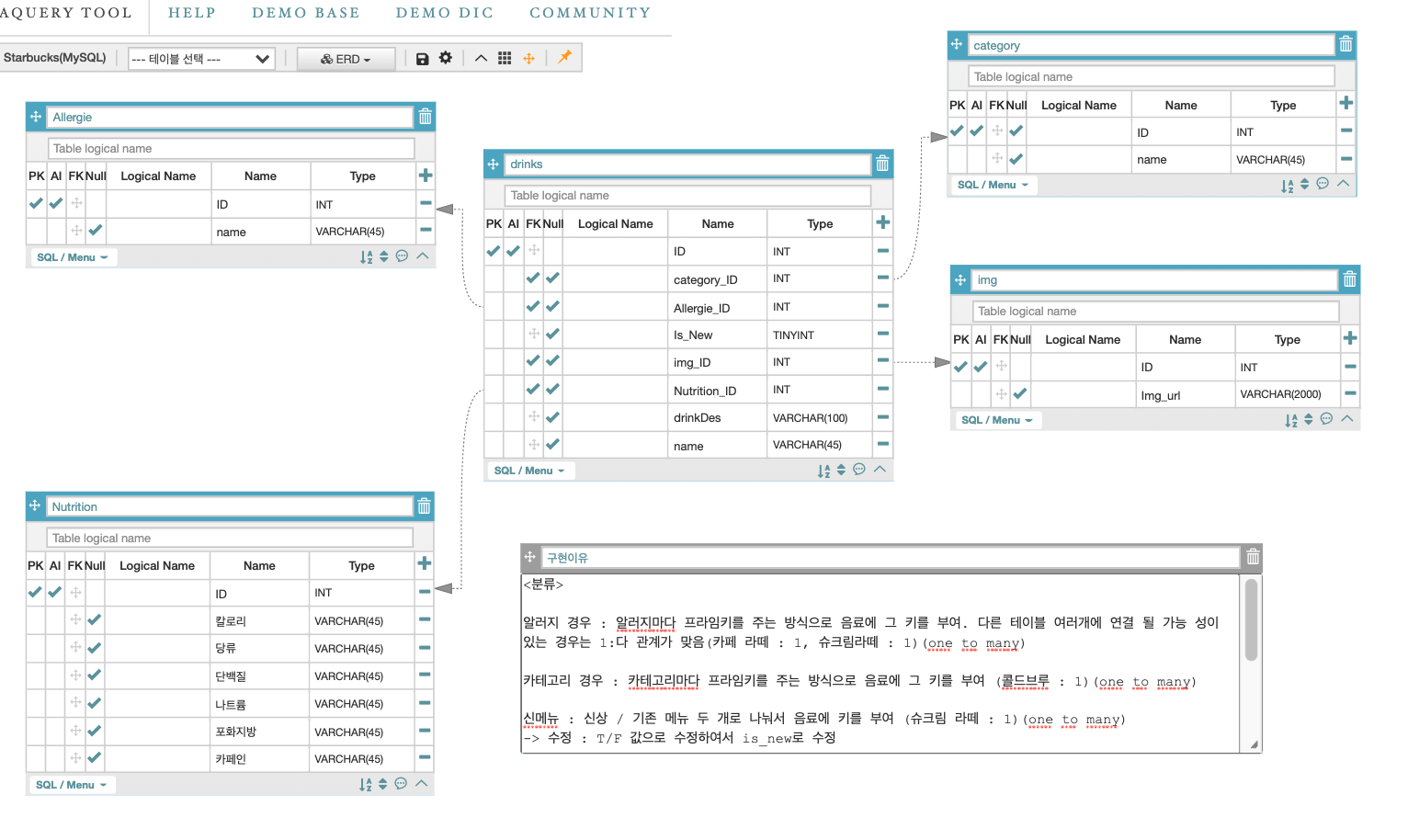
- 스타벅스 홈페이지 메뉴 보고 ERD구성도 만들기
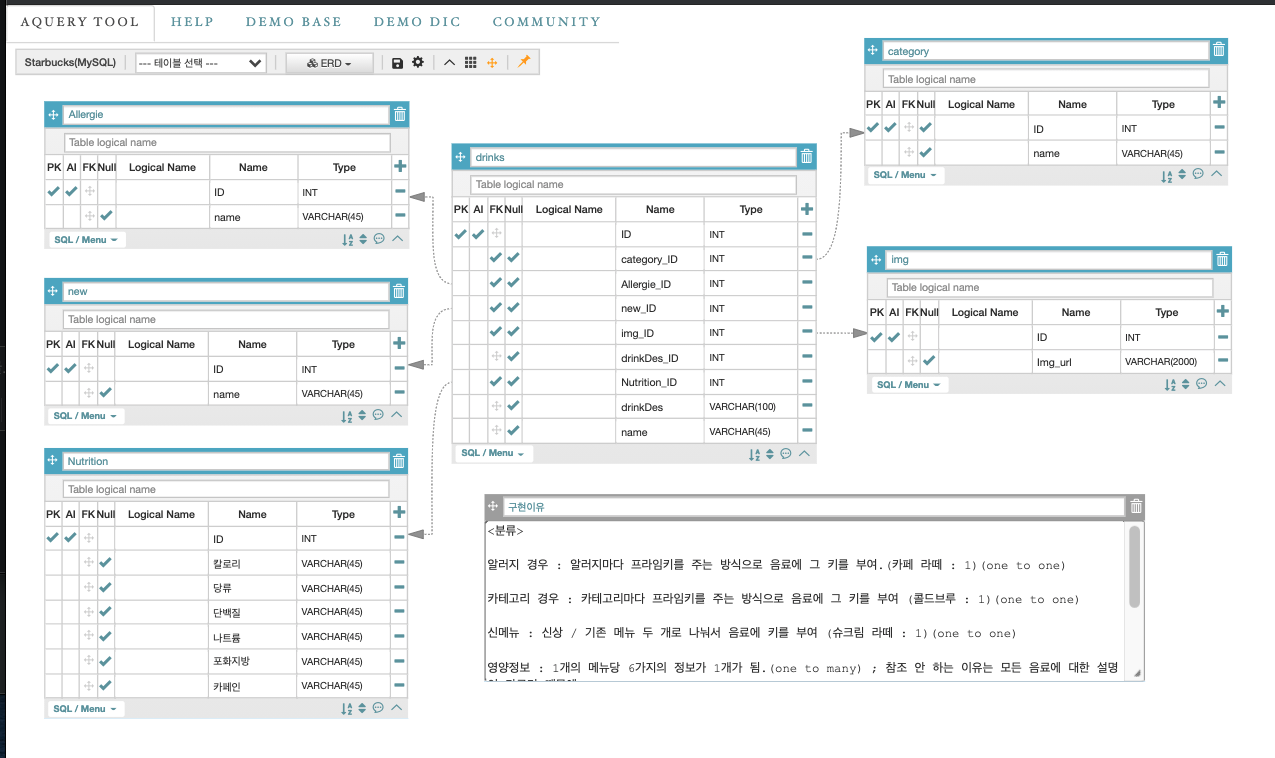
설명 : 수정함 -> 음료 하나가 갖는 값은 프라임키만. 여러 값을 갖는 경우는 영양정보에 한해서임.
<분류>
알러지 경우 : 알러지마다 프라임키를 주는 방식으로 음료에 그 키를 부여. 다른 테이블 여러개에 연결 될 가능 성이 있는 경우는 1:다 관계가 맞음(카페 라떼 : 1, 슈크림라떼 : 1)(one to many) ; 피드백 받고 수정
카테고리 경우 : 카테고리마다 프라임키를 주는 방식으로 음료에 그 키를 부여 (콜드브루 : 1)(one to many)
신메뉴 : 신상 / 기존 메뉴 두 개로 나눠서 음료에 키를 부여 (슈크림 라떼 : 1)(one to many)
영양정보 : 1개의 메뉴당 6가지의 정보가 1개가 됨.(one to many) ; 참조 안 하는 이유는 모든 음료에 대한 설명이 다르기 때문에.
이미지 : 이미지는 이미지 링크와 Id값 연동(one to one)
만일 이미지가 N개가 되면? : 1:N 관계가 된다.(one-to-many 로 테이블 분리, 테이블과 forein key 화살표 방향이 반대)
음료 설명 : one to one
음료 이름 : 모두 다른 값이므로 drinks표 자체 name 속성값으로 부여
화살표 방향은 본체에서 참조되는 방향으로 가는 것이 맞음.
만일 신상품으로 Yes or No로 판별하려면?
분리형 타입으로 is_new ~ 헤드 타입을 놓고 해도 된다.
최종수정 :