1. 먼저 프로세스+쓰레드가 뭘까?
"실행 중인 프로그램으로 디스크로부터 메모리에 적재되어 CPU 의 할당을 받을 수 있는 것"
"운영체제로부터 주소 공간, 파일, 메모리 등을 할당받으며 이것들을 총칭"
설명만 봐서는 도저히 뭔지 모르겠다. 다른 자료를 찾아보기로 했다.
1. 프로세스를 알려면 프로그램이 뭔지부터 알아야한다.
- 프로그램 : 생명이 없는 것. 보조 기억장치에 존재하며 실행되기를 기다리는 명령어(코드)와 정적 데이터의 묶음.
- 프로세스 : 프로그램의 명령어와 정적데이터가 메모리에 적재되면 프로세스.
즉 실행 안 되고 가만히 있으면 프로그램, 실행되면 프로세스
2. 프로세스가 멀티플레이를 할 수 있는 이유
코드 / 데이터 / 힙 / 스택
프로세스 구성 : 프로세스 제어블록(PCB) ; 병원 환자 기록부 생각하기
-
PID :
OS가 프로세스 식별하기 위해 부여한 식별번호 -
프로세스 상태 :
CPU가 프로세스 빠르게 교체하면서 실행하기 때문에 프로세스 상태 체크하고 저장 -
프로그램 카운터 :
CPU가 다음으로 실행할 명령어를 가리키는 값 -
스케줄링 우선순위 :
CPU에서 실행되는 순서를 결정하는 것을 스케줄링. 우선순위에 따른 실행 -
권한 :
프로세스가 접근할 수 있는 자원을 결정하는 정보 -
프로세스의 부모와 자식 프로세스 :
최초 init 프로세스 제외 모든 프로세스가 부모 자식 관계, 트리 형태 구성먼저 올려져야 하는 프로그램 + 자녀 프로그램
-
프로세스의 데이터와 명령어 있는 메모리 위치를 가리키는 포인터 : 포인터는 메모리 주소
프로세스는 실행중인 프로그램. 프로그램에 대한 정보가 있어야만 함. 프로그램 정보는 프로세스가 메모리에 가지는 자신만의 주소 공간에 저장. 이 공간에 대한 포인터 값을 가짐 -
프로세스에 할당된 자원들을 가리키는 포인터
-
실행문맥 :
프로세스 실행 상태에서는 마지막 실행한 프로세서의 레지스터 내용 담고 있음. CPU에 의해 계속 교체 되어 다시 자기 차례 되어도 마치 끊긴 적 없는 듯 하려고 레지스터 정보를 가지고 있다고 함. -
참고 : CPU에 레지스터에서는 1개의 프로세스 밖에 처리 못 한다 -> 일단 PCB에 저장해서 다른거 쓰고 다시 다른거 하고.. (1번 하다가 1번 PCB에 저장했다가 2번 하다가...) : 뒤에서 설명한 Context-Switching
3. 쓰레드..? : 프로세스의 일 목록
(이런 저런 개념들)
- 동시성 : 동시에 일어나는 것처럼 보인다.(동시에 일어나는 것이 아니다)
-> 옛날에 만화 그린거 연결하듯이
둘 다 '실행 단위'지만 CPU 메모리 위냐 프로세스 메모리 내에서 스택만 독립적으로 가지고 움직이는 것.
-
프로세스가 프로그램 단위라면 스레드는 프로그램 내의 것들 위주의 데이터를 관리하는 것.(영상, 댓글, 추천, 좋아요...)
참고 링크 -
스레드는 프로세스 내에서 각각 Stack만 따로 할당받고 Code, Data, Heap 영역은 공유
-
멀티쓰레드는 이를 여러개 사용한다는 뜻.
장점 : -
메모리 공간과 시스템 자원 소모 줄어든다.
-
context switching(원래는 실행, 준비로 CPU에 올라갔다 내려갔다..) 할 때 캐시 메모리 비율 필요없기 때문에 빠르다.
-> Q에 담아서 왔다 갔다 하니까 캐시 필요 없다.(python 예시)
단점 : -
디버깅이 까다롭다.
-
한 프로세스 스레드에 문제 생기면 다른 스레드에 영향
-
같은 데이터 공유하기 때문에 데이터 동기화 신경 써야 한다.
참고할 영상
요약 :
프로세스는 프로그램이 실행된 것.
쓰레드는 한 프로세스에서 나뉘어진 하나 이상의 실행 단위
2. 메모리 관리 전략
1. 배경
- 프로세스는 독립된 메모리 공간을 갖고 있다.(위에서 본 것처럼)
- OS 혹은 타 프로세스에도 자유롭게 접근할 수 없다.
반대로 OS는 제약이 없다.
1. Swapping : 두 값을 맞바꾼다.
- 메모리 관리를 위해 사용되는 기법
- e.g : 10개의 프로세스가 모두 올라가있는 상태라고 치면(10개가 최대) 여기에 11번째를 올리고 싶다.
-> 이 때 임의의 한 값을 잠시 보조기억 장치로 보내는 것을 swap-out, 그 자리에 11번째 값을 올려 주기억장치에 불러오는 것을 swap-in이라 한다.이 일련의 과정을 스와핑이라고 한다.
2. 단편화
-
이처럼 스와핑이 일어나다보면 메모리 사이에 작은 틈들이 생기는데 (자유공간) 이를 단편화라고 한다.
-
외부단편화 : 여러 프로세스가 차지한 전체 메모리 공간 중 사용 못 하는 부분합치면 사용 가능한데 분산되어서 발생하는 문제.
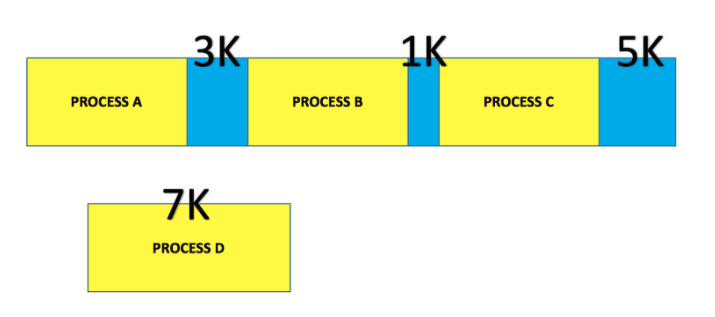 .
. -
내부단편화 : 프로세스가 사용하는 메모리 공간에 포함된 남는 부분. 10,000B 있고 Process A 가 9,998B 사용하게되면 2B 라는 차이 -> 프로레스가 쓰고 남은거.
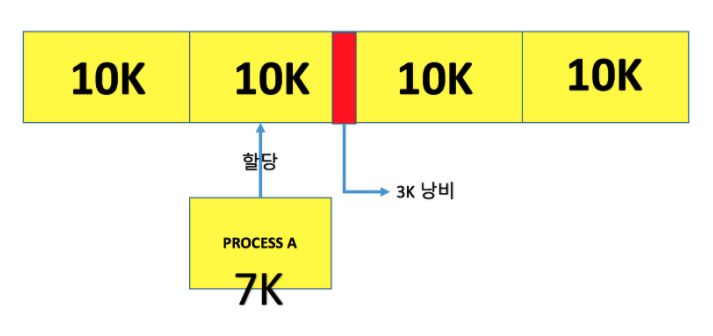
2. 그래서 해결책은?
c.f. 압축
외부 단편화 해소해보려고 남은 공간들을 한 쪽으로 몰아서 써보려고 하는 시도지만 좋지 않다.
그래서 나온 방법이 두 가지가 있는데 페이징, 세그멘테이션 기법이다.
1. 페이징 기법 : 외부 단편화와 압축을 없애보자.
-
프로세스가 저장될 때 논리메모리로 공간관리가 되어 물리메모리에 순서 상관없이 프레임에 매핑된다.(물리메모리 상자에 프로레스가 논리메모리로 포장되어 딱딱 들어간다.)
-
문제점 : 내부 단편화가 심해진다.
예 : 3100짜리 프로세스인데 1000짜리 물리 메모리 3개에 100만 넣으면 될 걸 또 1000을 써야해서 900의 내부 단편화가 생긴다...
2. 세그멘테이션 기법 : 페이징의 문제점을 극복해보자
- 페이징처럼 같은 논리 / 물리 메모리 크기로 넣는게 아니라 서로 다른 논리적 단위 세그먼트로 분할하여서 넣는다. (매핑 위해 세그먼트 테이블 형태가 필요하다) 그 때 그 때 할당해주기 때문에 내부 단편화는 안 일어난다.
약간 지점도를 페이징에서는 그릇을 맞춰서 넣는 느낌이라면 세그멘테이션은 지점토에 맞춰서 그릇이 바뀌는 것 같은 느낌. 그릇으로 그릇에 끼워 넣는건 공통점이고 어떻게든 잉여공간을 없애려는 시도는 똑같음.
- 문제점 : 중간에 프로세스가 빠지면 구멍 뚫리면서 외부 단편화가 일어남.(서로 다른 크기의 세그먼트들.. 프로세스들.. 결국 외부 단편화)
