1일차
데이터 모델링
데이터 모델링 프로세스
요구사항 분석 > 개념적 모델링 > 논리적 모델링 > 물리적 모델링 > 데이터 베이스
- 개논물
개념적 모델링
현실 세계의 복잡한 대상들을 추상화, 단순화 하여 데이터로 표현하는 과정
어떤 데이터를 저장할 것인지 결정하는 단계
- 어떻게 데이터로 저장하는가?
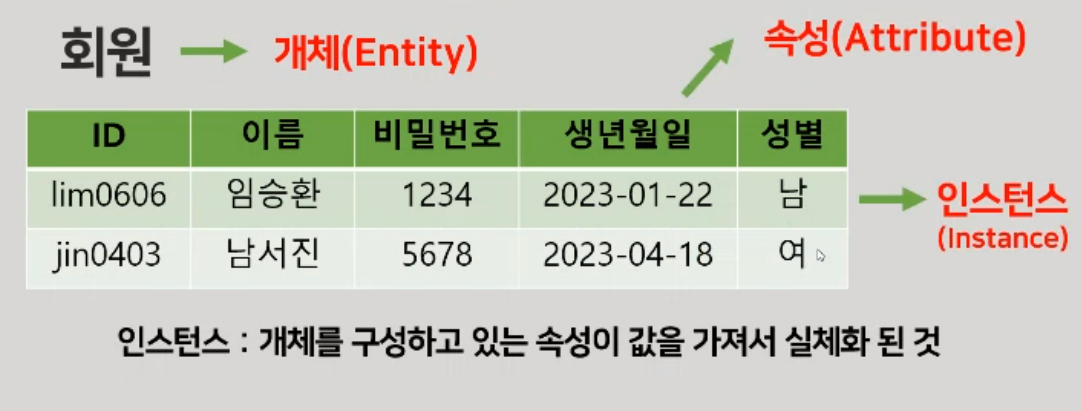
개체 : 현실세계에서 저장할 가치가있는 중요한 데이터의 집합
속성 : 개체가 가지고 있는 특징
인스턴스 : 개체 안의 실체화 된 개별적인 것들
관계 개체와 개체가 맺고 있는 의미 있는 연관성
** 두 개체 사이에는 의존적 관계가 존재한다.
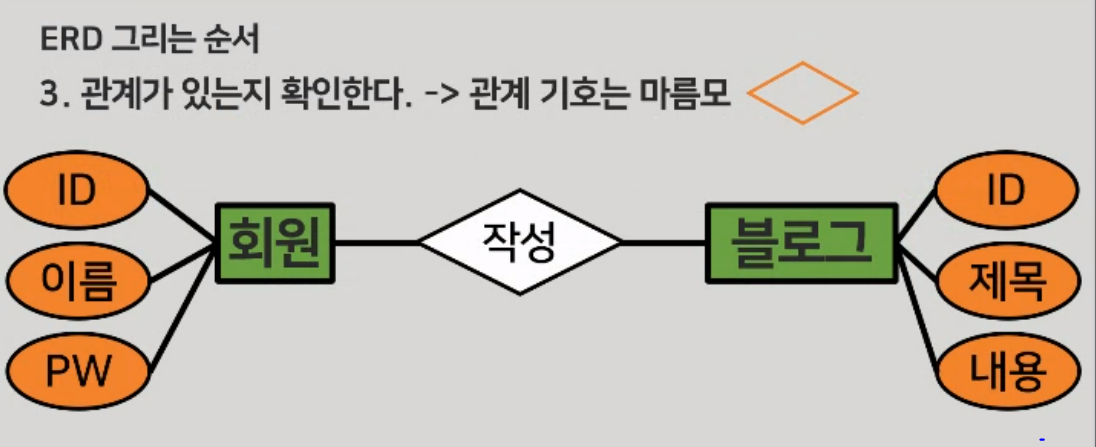
ERD
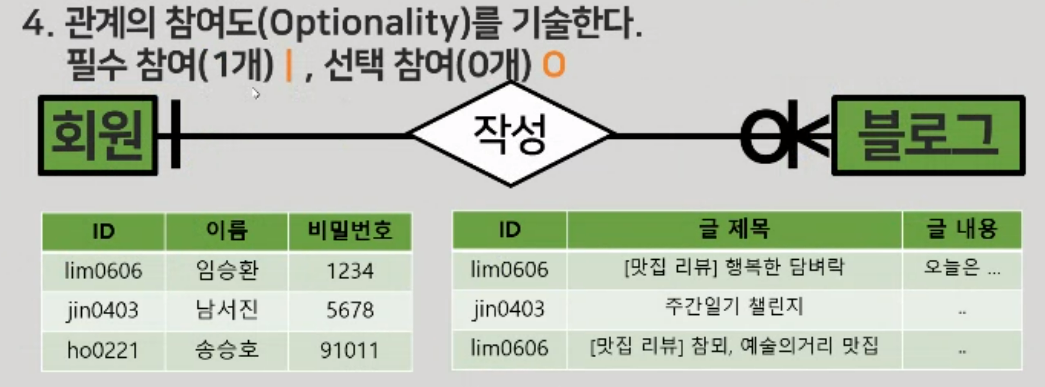
관계에 대한 참여도
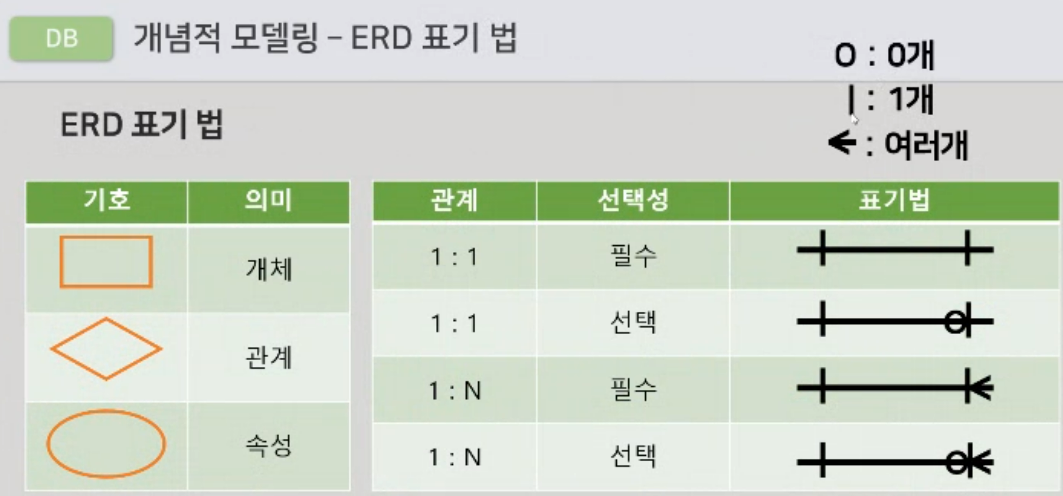
ERD 표기법
논리적 모델링
ERD를 기준으로 개체들을 DBMS가 지원하는 데이터로 변환시키는 과정 즉 데이터들을 구조적으로 설계하는 과정
식별자 선택, 정규화, 관계설정 등을 진행
- 데이터 설계하는 과정
키
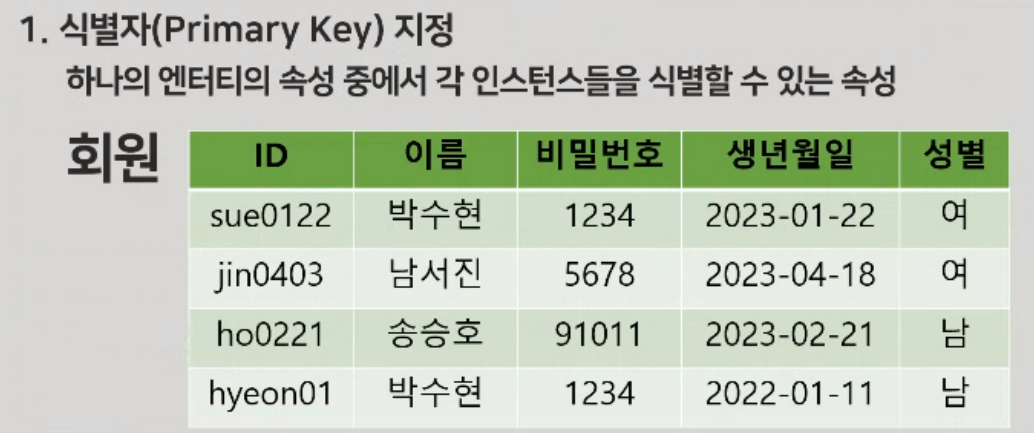
정규화
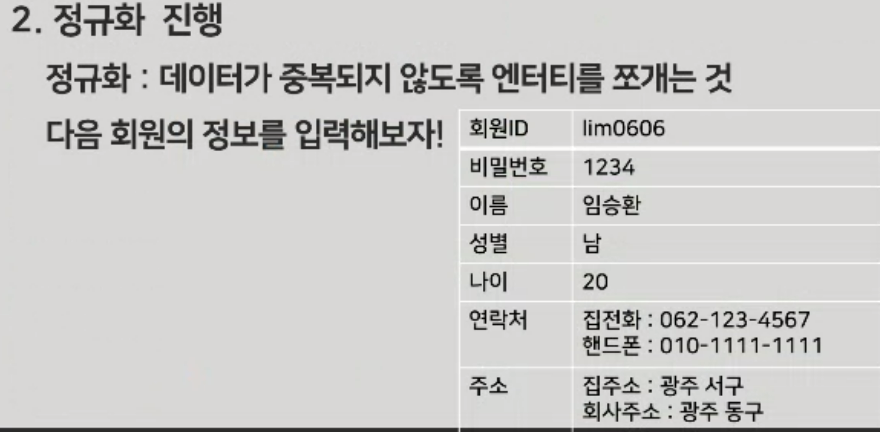


정규화로 쪼갠이후 적절한 속성을 넣어 다듬는것이 중요
ERD ER모델로 변환
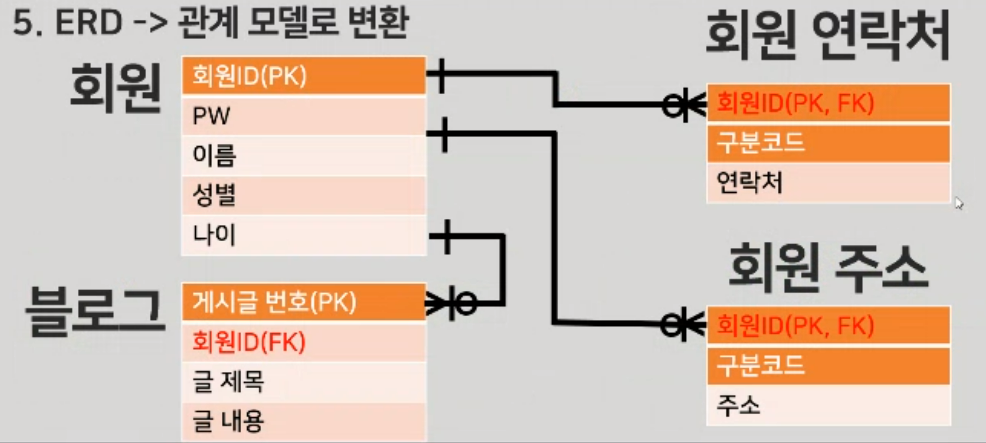
ER 모델로 전환시 개체에서 원자값이 아닌경우 개체를 새로 만들어 정규화 전체 진행
물리적 모델링
논리적 모델링 결과를 가지고 실제 DataBase로 구축하는 것
하드웨어나 운영체제의특성을 고려하여 필요한 인덱스의 구조나 내부 저장구조, 접근 경로 등에 대한 물리적인 구조를 설계하고 SQL문을 작성하고 실행시켜 실제 데이터 베이스 생성
- 데이터를 DB로 구축
용어 정리
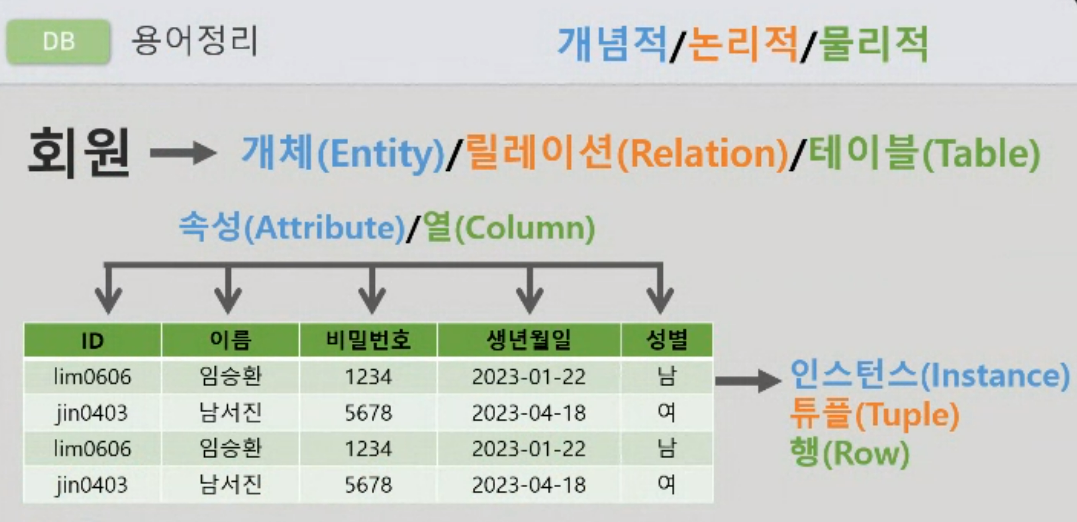
- 카디널리티 : 속성의 수
- 디그리 : 튜플의 수
2일차
SQL
SQL 문법

-
/* */ 으로 주석 사용가능
-
별칭 짓기 (알리야스) : 1. 컬럼명 별칭명 2. 컬럼명 "별칭명" 3. 컬럼명 as "별칭명"

-
where문에서 날짜 데이터를 비교 확인할 때
- 날짜 형식 확인 ( / or - or . ) 2. 문자열 ''로 인식
SQL 실행 순서

연산자
비교 연산자
<, >, <=, >=, =,!=
복합 조건 연산자
-
AND
모든 조건이 True로 나올때만 True
-
OR
하나의 조건이라도 True라면 True
-
NOT
True 나 False를 반대로 돌린다
- AND 우선 순위가 OR 우선순위 보다 높다
( ) 사용으로 우선순위 변경 가능
기타 조건 연산자
-
IN
조건식 안에 OR 조건을 대체 사용한다WHERE 컬렴명 IN (@,@);
-
NOT IN
조건식 안에 AND 조건을 대체해서 사용 -
Between a AND b
(일정범위) A와 B 사이의 값을 구할 때 사용WHERE 컬럼명 BETWEEN A AND B
-
IS (NOT) NULL
NULL 값이 있는 데이터를 찾을때 사용WHERE 컬럼명 IS (NOT) NULL
- NULL은 대입연산자인 = 기호를 사용할 수 없다
- LIKE
일부 문자열이 포함된 데이터를 조회할때 사용% >WHERE 컬럼명 LIKE '@@%' 길이와 상관 없이 모든 문자 데이터를 의미 _ >WHERE 컬럼명 LIKE '@_' 어떤 값이든 상관없이 한개의 문자 데이터를 의미
3일차
DUAL 테이블
오라클 최고관리자(SYS) 소유의 테이블
임시 연산이나 함수의 결과 값 확인 용도로 사용하는 테스트용 테이블
FROM DUAL
함수
입력 값을 넣어 특정한 기능을 통해 결과 값을 출력
함수이름()
함수를 실행할 때 사용하는 입력값 : 인자 값, 매개변수
오라클 함수의 종류
-
내장 함수
오라클에서 기본적으로 제공하고 있는 함수
SQL에서 값을 간편하게 조작하는데 사용
미리 만들어 놓은 함수,,필요 할 때마다 호출하여 쓰면 됨 -
사용자 정의 함수
사용자가 필요에 의해 직접 정의한 함수
내장 함수
- 단일 행 함수 : 입력된 하나의 행당 결과가 하나씩 나오는 함수
- 다중행 함수 : 여러 행을 입력받아 하나의 결과 값으로 출력이 되는 함수
문자형 함수
UPPER
괄호 안 문자 데이터를 대문자로 변환하여 출력
SELECT UPPER('데이터')
LOWER
괄호 안 문자 데이터를 소문자로 변환하여 출력
SELECT LOWER('데이터')
LENGTH
괄호 안 문자 데이터의 길이를 구하는 함수
SELECT LENGTH('데이터')
SUBSTR
문자열을 추출하는 함수
- SELECT문에서 보통 사용
- 문자열 데이터의 시작위치부터 추출 길이만큼 출력
SUBSTR('입력값', 시작위치, 추출길이)
- 추출길이를 생략 시 문자열 데이터의 시작위치부터 끝까지 출력
SUBSTR('입력값', 시작위치)
REPLACE
특정 문자를 다른 문자로 바구어 주는 함수
- 데이터 바꾸기
REPLACE('데이터', '바꾸고 싶은 문자', '바꿔야 할 문자')
- 데이터 삭제
REPLACE('데이터', '바꾸고 싶은 문자')
// 바꿀 문자가 없으면 삭제)
CONCAT
두 문자열 데이터를 합치는 함수
- CONCAT('데이터', '데이터')
- CONCAT('데이터', '데이터') || '데이터' || '데이터' ~......
- 함수에 들어가는 인자 값이 2개만 들어갈 수 있다
합성연산자 ||(하이푼)을 사용하면 무한대로 문자열 연결이 가능하다.
TRIM
입력 받은 문자형 데이터의 양 끝의 공백을 제거하는 함수
TRIM('데이터')
숫자형 함수
ROUND
특정 위치에서 반올림 하는 함수
- 기본형
ROUND(반올림 할 숫자, 소수점 n+1에서 반올림 )
// n까지 살림
- 반올림 소수점 첫째에서 강제 반올림
ROUND(반올림할 숫자)
TRUNC
특정 위치에서 버리는 함수
- TRUNC(버림할 숫자, 소수점 n+1 부터 버림)
// n까지 살림
MOD
숫자를 나눈 나머지 값을 구하는 함수
- 홀수와 짝수를 구분할대 유용하게 사용
10%3 == MOD(10, 3)MOD (나눗셈 될 숫자, 나눌 숫자)
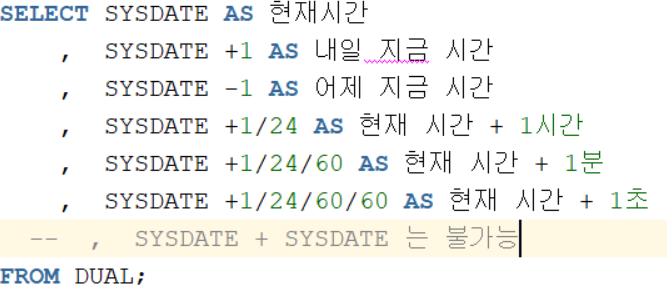
SYSDATE
현재 날짜와 시간을 출력해주는 함수
입력시 바로 출력이 되며 현재 시간을 초 단위까지 출력이 가능

- 날짜형 데이터는 연산이 가능 (SYSDATE + SYSDATE 연산은 불가능)
ADD_MONTH
몇 개월 이후 날짜를 구하는 함수
ADD_MONTH(날짜데이터, 더하거나 뺄 개월 수)

4일차
변환형 함수
암시적 형변환
데이터베이스가 자동으로 형변환을 해주는것

-> 정수형 * 문자형을 했지만 DBMS가 자동으로 문자12를 숫자로 변환해줌
명시적 형변환
데이터 변환 형 함수를 사용해서 사용자가 직접 자료형을 지정 해주는 것
TO_CHAR( )
날짜, 숫자 데이터를 문자 데이터로 변환해주는 함수
TO_CHAR(변환 할 데이터, 출력 형태)

TO_NUMBER( )
문자 데이터를 숫자 데이터로 변환 하는 함수
TO_NUMBER(문자열 데이터, 인식 될 숫자 형태)
TO_DATE( )
문자 데이터를 날짜 데이터로 변환 하는 함수
TO_DATE(문자열 데이터, 인식 될 날짜 형태)

--> 2024-05-31 00:00:00 이 나옴
NULL 처리 함수
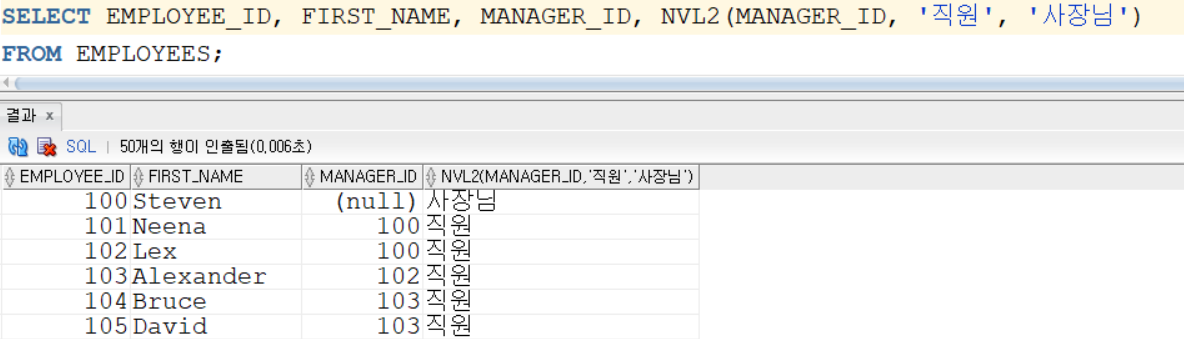
NVL /NVL2
NULL 값을 대체 할 수 있는 함수
- NVL
NVL(NULL인지 여부를 검사할 데이터1 또는 열, 데이터1 값이 NULL인 경우 반환할 데이터)

- 부서ID 컬럼에 NULL 값이 있을경우 00으로 대체
- NVL2
NVL2(NULL인지 여부를 검사할 데이터 또는 열, 데이터가 NULL이 아닐 경우 반환할 데이터, 앞 데이터가 NULL인 경우 반환할 데이터)
조건 함수
DECODE( )
상황에 따라서 다른 데이터를 변환하는 함수
검사 대상과 비교해서 지정한 값은 반환
DECODE(검사대상이 될 컬럼 OR 데이터, 비교값, 일치시 반환할 값, 일치하지 않을 시 반환 값)

- 데이터 NULL 값을 비교할 경우 NVL과 같은 용도로 사용할 수 있음

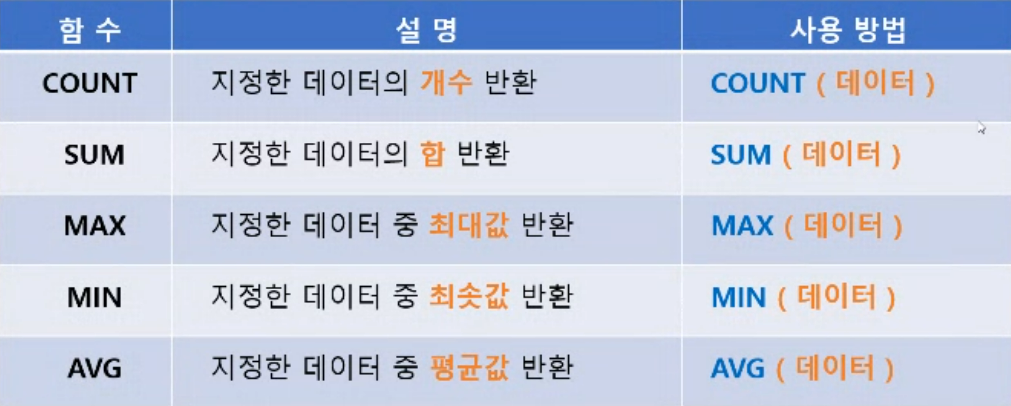
집계함수 (다중 행 함수)
- 집계 함수 특징
- NULL 값을 제외하는 특성을 가지고 있다
- 집계함수는 그룹화(GROUP BY)가 되어 있는 상태에서만 사용이 가능하다 (평소에는 테이블을 그룹화하여 생략 가능하고 사용할 수 있음
- 출력하고자 하는 행의 갯수가 맞지 않으면 에러가 난다 -> 해당 컬럼을 그룹화하면 실행 가능
- 행 갯수 파악
SELECT COUNT(*)
그룹화
끼리끼리 모아놓은 것을 집계 > 중복 데이터들을 묶어서 하나의 결과로 출력
GROUP BY
특정 컬럼을 기준으로 그룹화
SELECT
FROM
GROUP BY
-
GROUP BY 문을 사용함으로써 중복 값을 제거 가능
이후 COUNT 문을 사용해서 컬럼 내에 있는 각각의 값의 개수를 출력할 수 있음 -
GROUP BY 문을 사용하면 SELECT문 보다 먼저 실행되어서 중복 값을 제거 하였기 때문에 SELECT문 사용 시 그룹핑이 되어 있지 않은 컬럼 조회가 있을 경우 에러가 뜸
BUT 집계함수의 경우 이미 그룹핑이 되어 있어 에러 X
-> 집계함수를 제외하고 GROUP BY 문 안에 조회하는 컬럼이 전부 들어가야함

HAVING
-
GROUP BY 절을 사용할 때만 사용 가능
집계가 완료된 대상을 조건을 통해 필터링하는 문법
그룹화된(집계함수 OR GROUP BY 안에 들어간 컬럼) 대상에서만 조건이 참인 경우 출력 -
그룹화된 함수는 WHERE로 표현 불가 -> SQL 실행문이 WHERE이 먼저 되고 그룹핑이 되기 때문
ORDER BY
특정 컬럼을 정렬해주는 문법
ASC 오름차순 (1,2,3,... 가,나,다,... A,B,C,....)
DESC 내림차순
- NULL 값이 가장 큰값으로 출력 됨
