- 지도학습
- 비지도학습
- 강화학습
군집
비슷한 데이터끼리 하나의 클러스터로 묶고 다른 데이터끼리는 다른 클러스터로 분류
군집 종류
- k-means
- 계층적 클러스터링
- DBSCAN
1. K-means 군집
- 가장 일반적으로 사용되는 알고리즘
- Centroid (군집 중심점) 이라는 특정한 임의으이 지점을 선택해 해당 중심에 가장 가까운 포인트들을 선택하는 군집화 기법
- 특징
- 일반적인 군집화에서 많이 활용되는 알고리즘
- 알고리즘이 쉽고 간결함
- 거리기반 알고리즘으로 속성의 개수가 많은 경우 군집화 정확도가 떨어짐 (차원축소를 적용해야할 수도 있음)
- 반복 횟수가 많아질 경우 경우 수행 시간이 매우 느려짐
- 몇 개의 군집을 선택해야 할지 가이드하기가 어려움
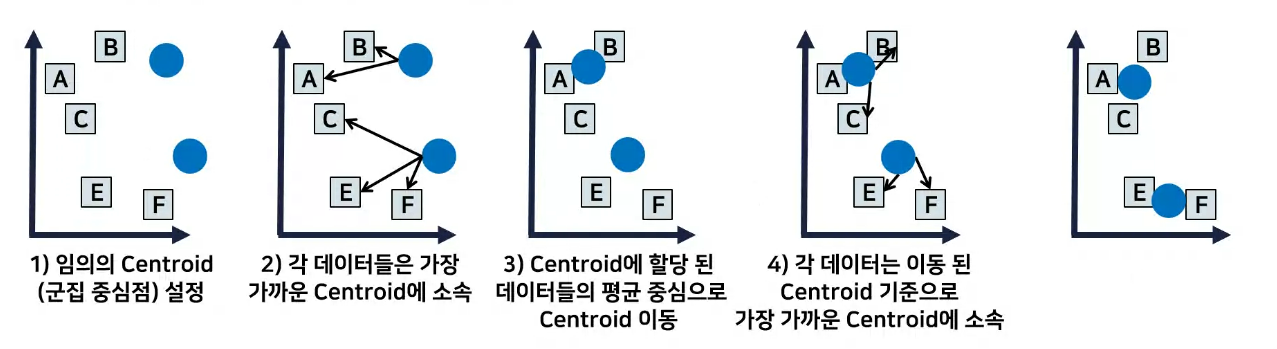
여러 centroid 의 중심으로 이동후 다시 평균으로 이동을 반복 이후 더이상 평균이 안바뀌면 종료
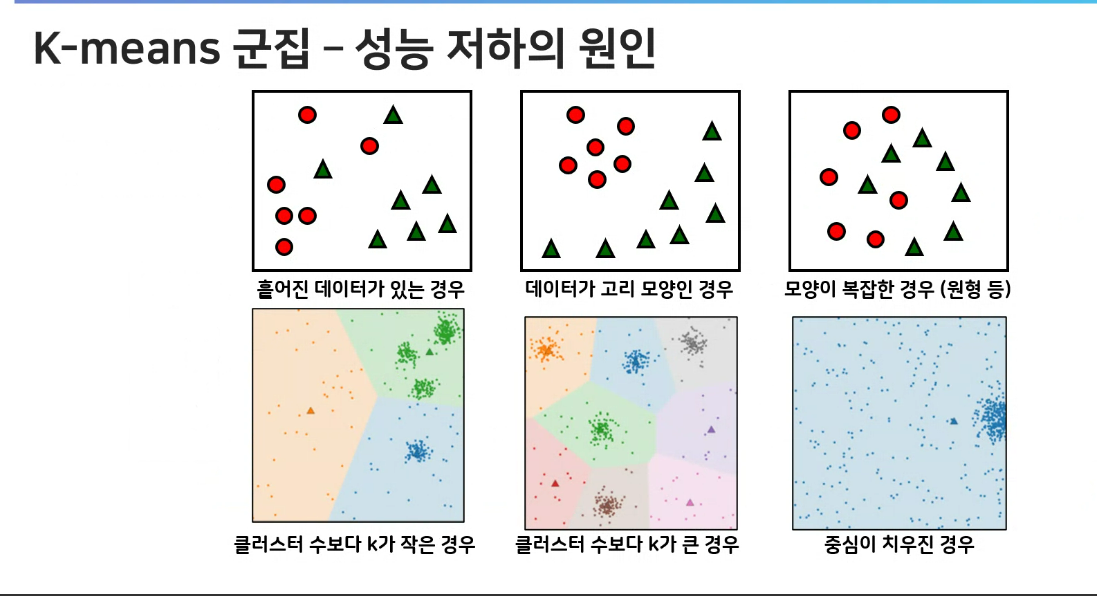
군집 성능 저하의 원인
군집 평가
- 비지도 학습의 특성상 어떠한 지표라도 정확하게 성능을 평가하기는 어려움
- 그러나 군집화의 성능을 평가하는 지표들은 존재함
여러 지표들을 활용하여 어느 정도 군집화에 대한 성능 평가 가능


엘보우 기법
-
클러스터링 알고리즘에서 최적의 클러스터 수를 결정하기 위해 사용되는 시각화 기법
-
군집간 분산과 전체 분산의 비율을 확인
-
기울기가 완만해지는 지점 선택
-
__SSE (sum of
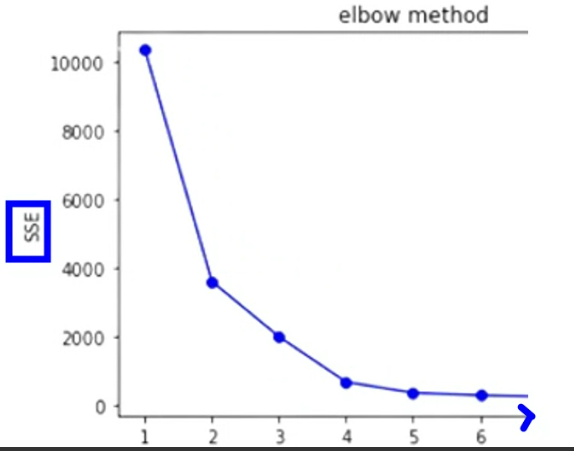
4가 완만해지는 지점
실루엣 분석

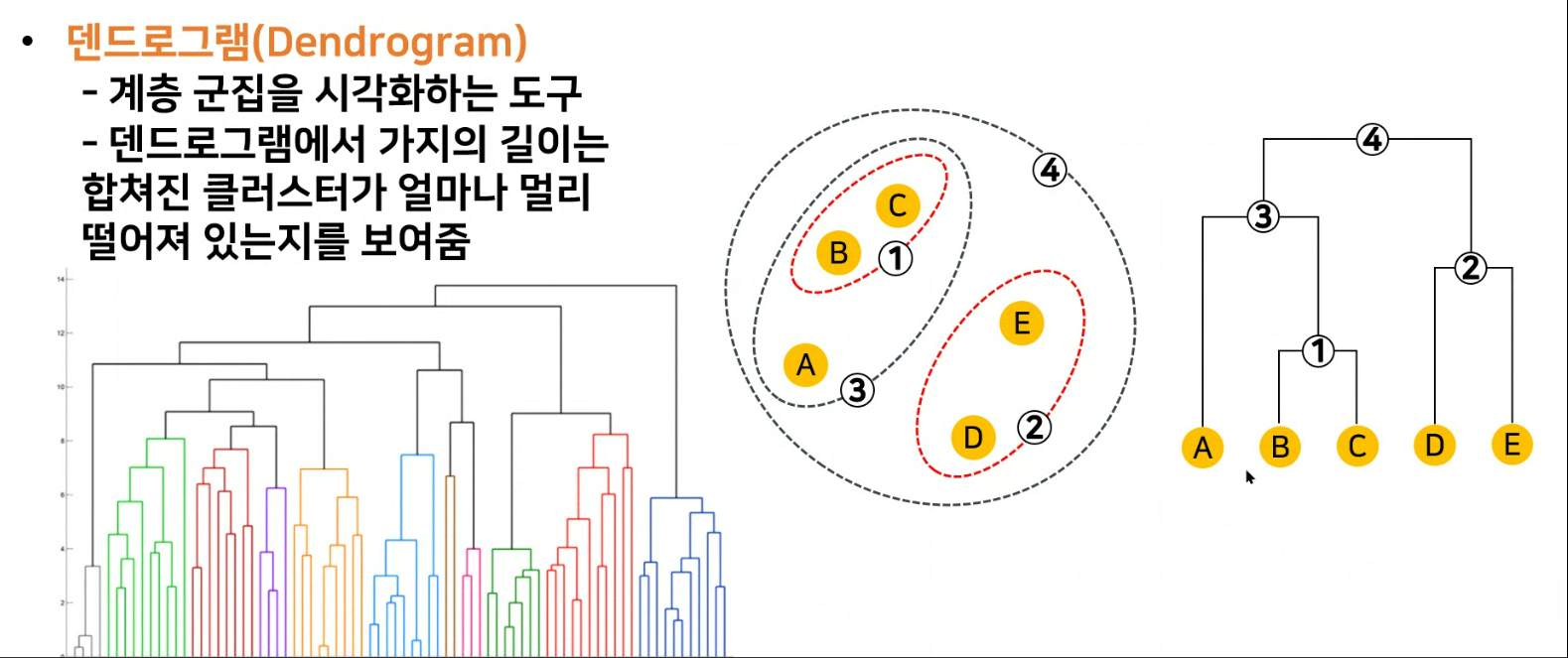
2. 계층적 클러스터링
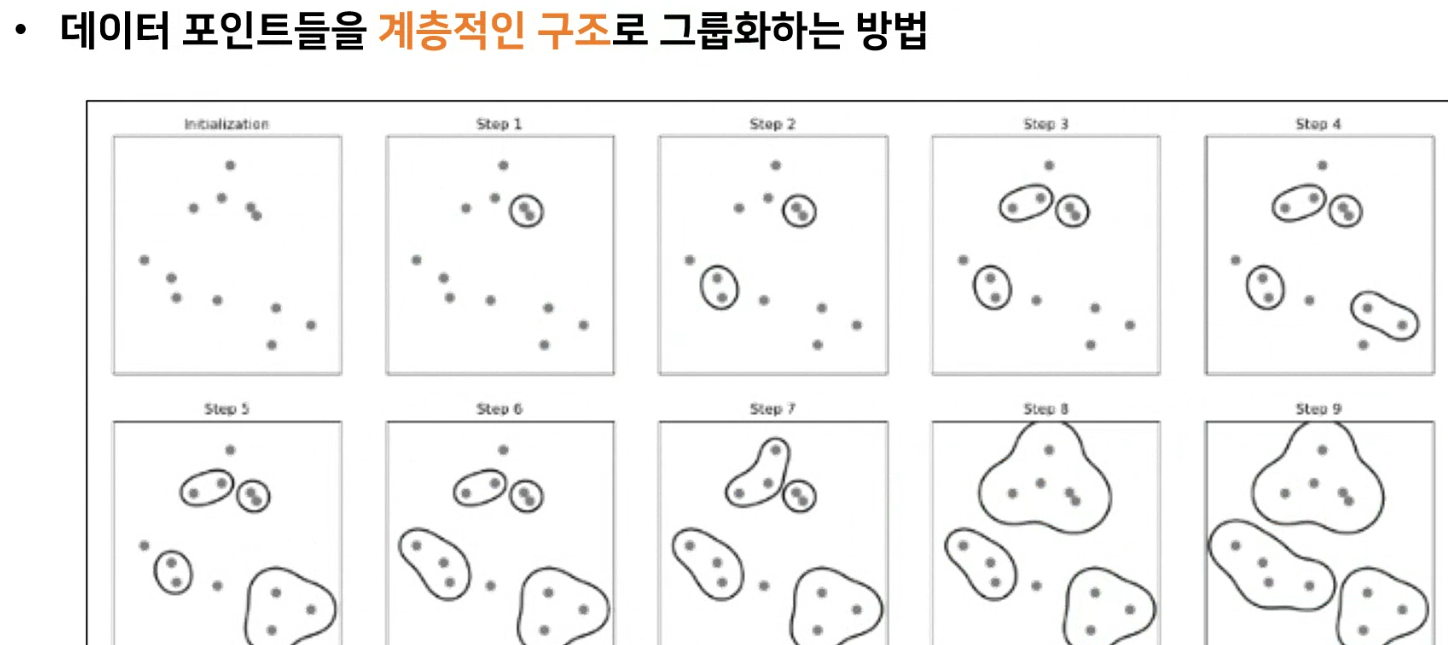
- 데이터 포인트들을 계층적인 구조로 그룹화하는 방법
- 계층적 트리 모형을 이용하여 개별 데이터 포인트들을 순차적 계층적으로 유사한 클러스터로 통합하여 군집화를 수행하는 알고리즘
- K-means 군집 알고리즘과는 달리 클러스터의 개수를 사전에 정하지 않아도 학습을 수행
3. DBSCAN
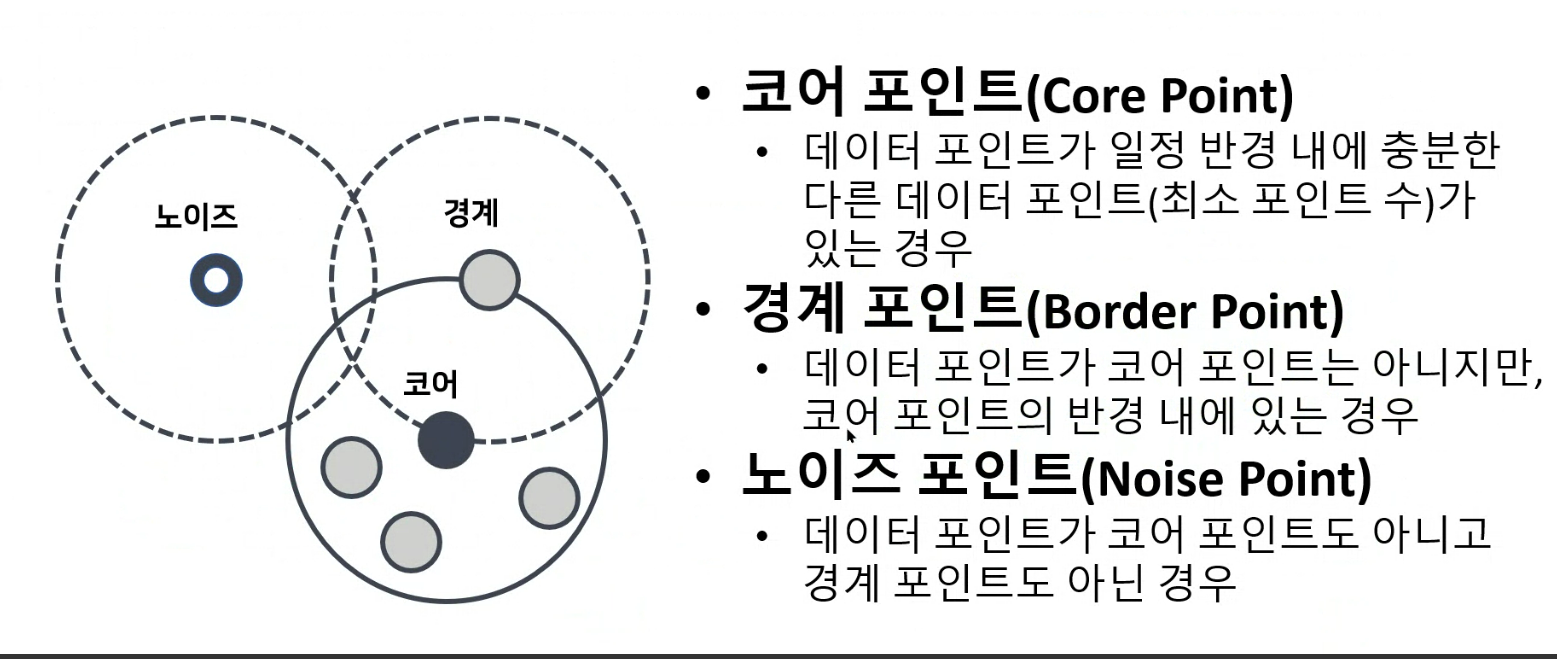
(Density-based spatial clustering of applications with noise)
- 밀도 있게 연결되어 있는 데이터 집합은 동일한 클러스터라고 판단
- 일정한 밀도를 가지는 데이터의 무리가 마치 체인처럼 연결되어 있으면 거리의 개념과는 관계 없이 같은 클러스터로 판단
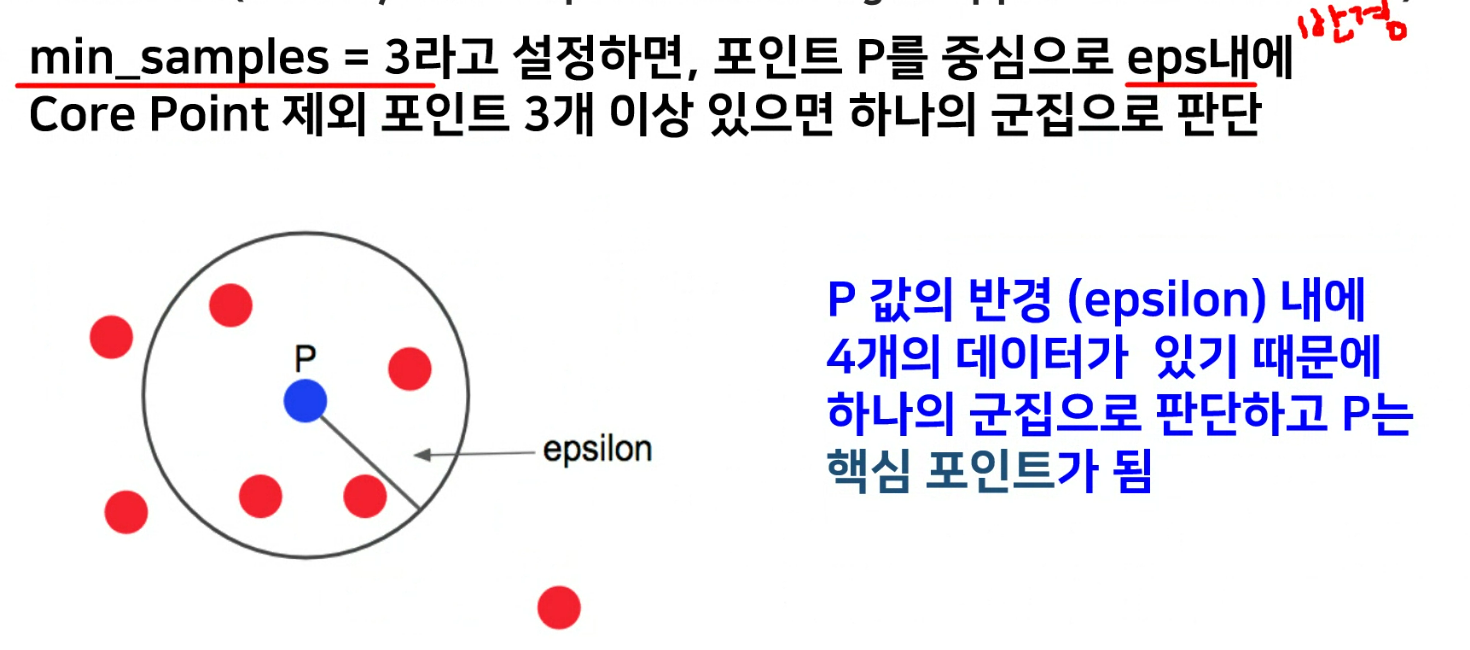
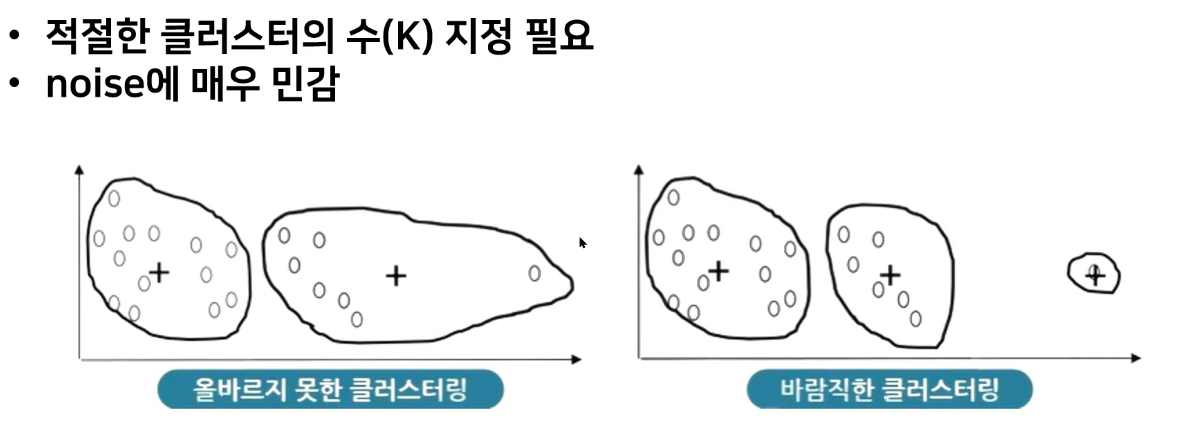
자기 제외하고 3개가 있어야함
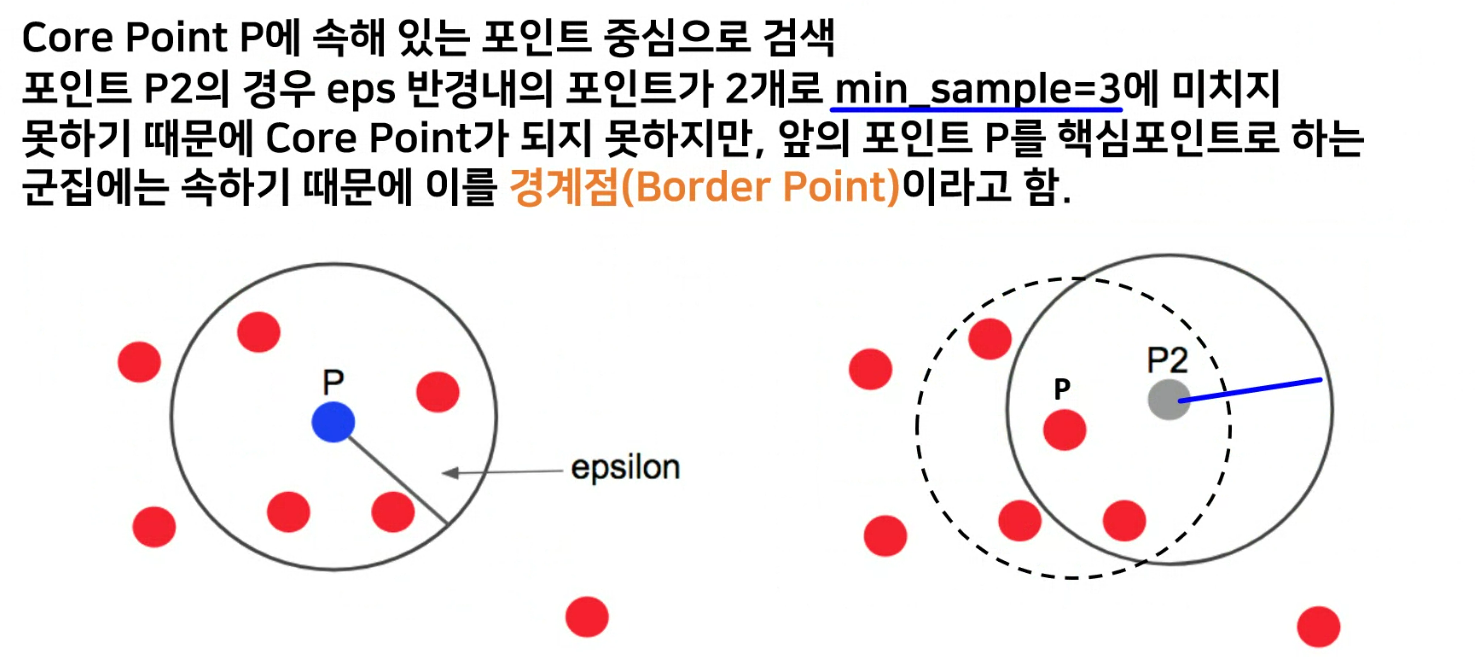
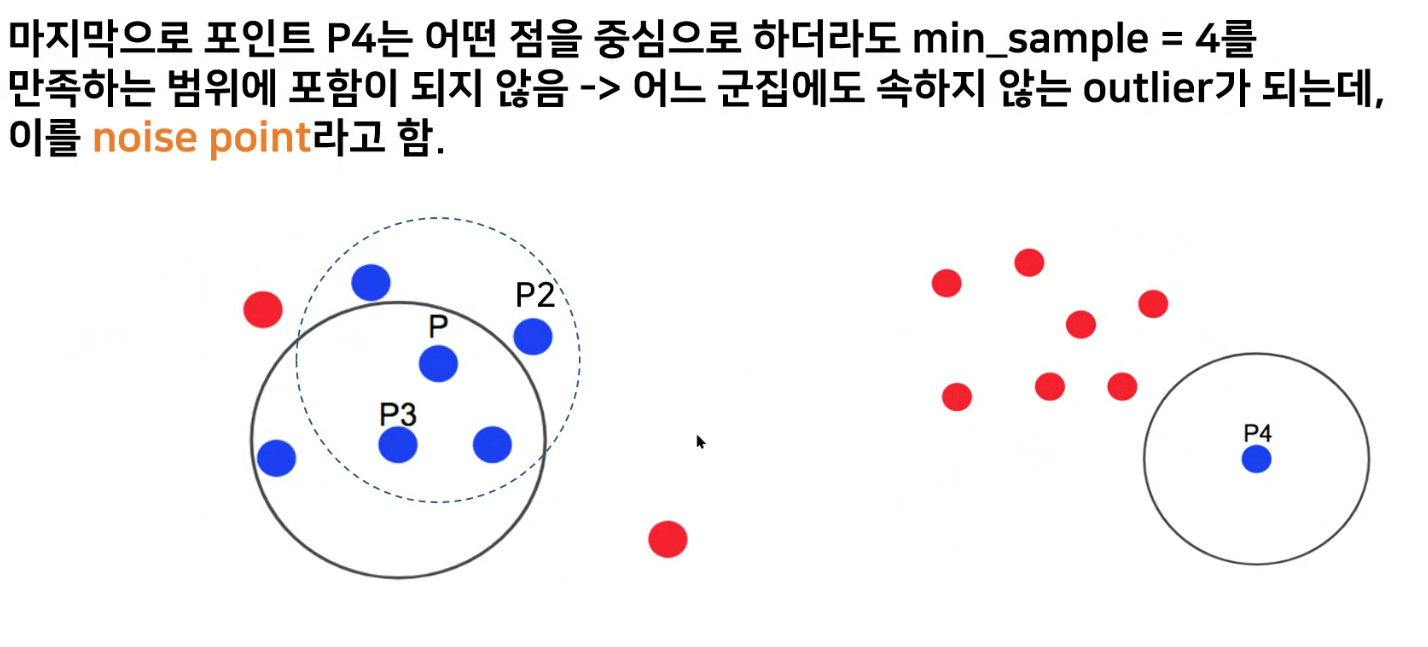
- p와 p3가 같은 공간으로 군집을 형성함

