인덱스(Index)
인덱스는 데이터베이스 테이블의 검색 속도를 향상시켜주는 자료구조이다. 특정 컬럼에 인덱스를 생성하면, 해당 컬럼의 데이터들을 정렬하여 별도의 공간에 데이터의 물리적 주소와 함께 저장한다.
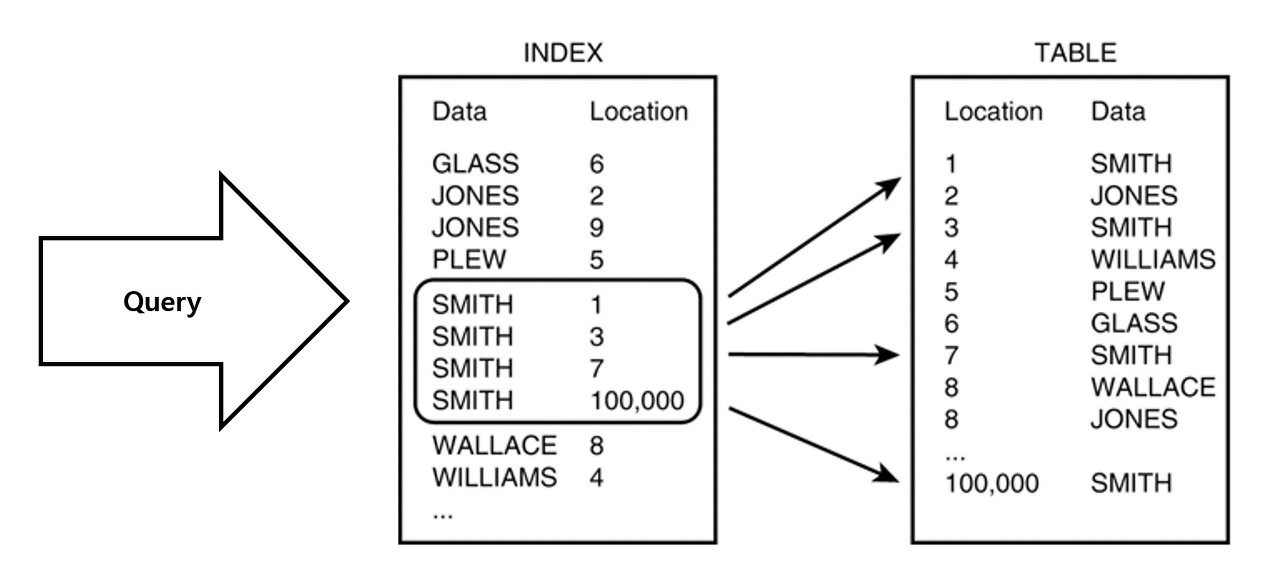
이렇게 인덱스를 생성했다면 쿼리문에 인덱스 생성 컬럼을 WHERE 조건으로 걸 때 옵티마이저에서 판단하여 생성된 인덱스를 탈 수 있다. 인덱스를 타게 되면 인덱스에 저장된 데이터의 물리적 주소로 가서 데이터를 가져오는 등의 동작을 통해 검색 속도를 향상시킬 수 있다.
또한 인덱스 생성 시 데이터를 정렬하여 저장한다.
인덱스의 장점
조건 검색(WHERE) 성능 증가
테이블에 데이터가 쌓이면 테이블의 레코드는 내부적으로 특정한 순서가 없이 저장이 된다. 이렇게 되면 WHERE 절에 특정 조건에 맞는 데이터를 찾을 때도 테이블을 풀 테이블 스캔(Full Table Scan)하며 조건과 일치하는지 비교해야 한다.
하지만 인덱스 테이블 스캔(Index Table Scan)시 인덱스 테이블은 데이터들이 정렬되어 저장되어 있기 때문에 조건에 맞는 데이터들을 더 빠르게 찾아낼 수 있다는 장점이 있다. 이게 인덱스를 사용하는 가장 큰 장점이다.
정렬(ORDER BY) 성능 증가
인덱스를 사용하면 ORDER BY에 의한 정렬 과정이 필요 없어진다. ORDER BY는 굉장히 많은 부담이 가해지는 작업인데 이미 인덱스는 정렬이 되어있는 상태이므로 그냥 가져오기만 하면 된다.
MIN, MAX 효율적인 처리
역시나 데이터가 정렬되어 있기에 테이블 전체를 뒤지는 것보다 인덱스를 활용하면 훨씬 효율적이다.
인덱스의 단점
INSERT, UPDATE, DELETE 성능 하락
UPDATE나 DELETE는 보통 WHERE 절이 필수적이기 때문에 인덱스로 인해 이득을 보는 점도 있지만, 데이터를 삽입하거나 수정 혹은 삭제를 한다는 것은 인덱스 테이블을 다시 정렬을 해야 한다는 의미이다. 그렇기 때문에 데이터의 변경이 자주 일어나는 테이블보다 검색 위주의 테이블에 인덱스를 사용하는 것이 효율적이다.
무조건 인덱스 스캔이 유리하지 않음
검색 위주의 테이블이라 하더라도 반드시 인덱스를 사용하는 것이 유리한 것은 아니다. 인덱스 테이블은 전체 데이터 중 10 ~ 15% 이하의 데이터를 처리하는 경우에만 효율적이고 그 이상에서는 인덱스를 사용하지 않는 것이 더 낫다고 한다.
간단한 예시로 데이터가 100만개 있는 테이블에 100개 있는 테이블이 있다면, 100만개 있는 테이블은 풀 스캔보다 인덱스 스캔이 빠르겠지만 100개 있는 테이블은 풀 스캔이 더 빠르다.
추가 저장 공간 사용
인덱스는 별도의 저장 공간이 필요하다. 즉, 인덱스를 많이 많들면 만들수록 그만큼 추가적인 저장 공간이 필요하다는 것이다. 검색 속도 향상과 저장 공간 절약 사이에 무엇이 더 이득인지 고려하여 인덱스를 사용하는 것이 좋다.
인덱스 생성 전략
앞서 살펴본 장단점으로 어떤 컬럼에 인덱스를 걸어야 할지 그 전략을 구상해볼 수 있다.
- 조건절에 자주 등장하는 컬럼
- 항상 = 으로 비교되는 컬럼
- 중복되는 데이터가 최소한인 컬럼(분포도가 좋은 컬럼)
- ORDER BY에 자주 사용되는 컬럼
- JOIN 조건으로 자주 사용되는 컬럼
