High-ConfidenceComputing(2024)
Yifan Yao, Jinhao Duan, Kaidi Xu, Yuanfang Cai, Zhibo Sun, Yue Zhang∗,1
Department of Computer Science, Drexel University, Philadelphia, PA 19104, USA
요약
LLM이 Security 분야에서 견인력(traction)을 얻고 있다.
이 페이퍼는 LLM + Security를 주제로 한 논문들을 종합하여
1) The Good : 이로운 LLM 어플리케이션
2) The Bad: Offensive LLM 어플리케이션
3) The Ugly: LLM과 LLM 어플리케이션의 취약점
이렇게 3가지 카테고리로 분류하였다.
1. Intro
1) Capable LLM의 요건
capable LLM은 4가지 요건을 갖춘다.
1) 자연어에 대한 깊은 이해(profound comprehenstion)
2) 인간과 유사하게 텍스트를 생성하는 능력
3) 복잡하고 정보가 많은 분야에서의 문맥 인식 능력
4) 문제 해결과 의사 결정에 기여하는 강력한 명령을 따르는 능력
2) Security 분야에서의 LLM
LLM은 보안 커뮤니티내에서 인기를 끌고 있다.
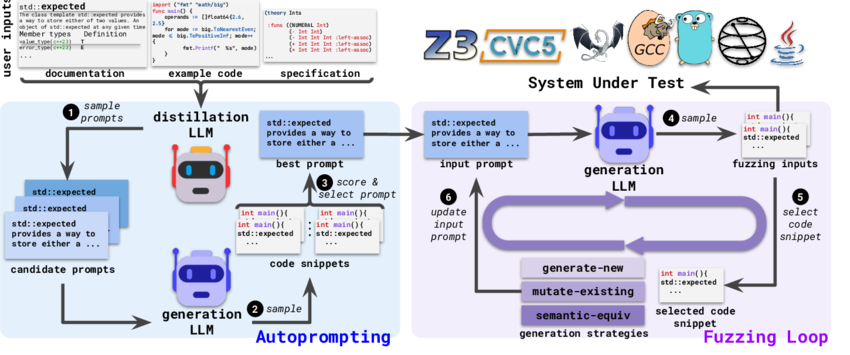
특히 LLM을 활용한 퍼저인 Fuzz4All이 등장하기도 하였다.
이는 여러 언어와 시스템을 대상으로 하는 보편적 퍼징 솔루션으로, 기존의 언어별 퍼저가 가진 한계를 극복하고 더 많은 버그를 식별할 수 있는 강력한 도구이다.
3) 본 연구에서의 Contribution
본 연구는 2가지의 공헌을 하였다.
1) Security와 Privacy에서 LLM의 Role을 요약한 선구자적 역할을 하였다.(Good, Bad, Ugly 측면을 한꺼번에)
2) 몇가지 흥미로운 발견을 하였다.
ex> 보안분야에서 LLM은 부정적인 부분보다 긍정적인 부분에 더 공헌을 많이 한다.
ex> 많은 연구자들이 동의하기를, 대형 언어 모델(LLM)은 코드나 데이터를 보호하는 데 있어서 최첨단 방법들을 능가한다,
ex> 사용자 수준(user-level)의 공격이 가장 흔하다. 이는 LLM이 인간과 유사한 추론 능력을 가지고 있기 때문이다. 이러한 능력 때문에 공격자들은 LLM을 이용하여 더 효과적으로 사용자 수준의 공격을 실행한다.
2. Background
3. Overview
1) Good: LLM이 어떻게 긍정적으로 보안과 프라이버시에 공헌하는지
그리고 보안 커뮤니티에 어떤 잠재적인 이득을 불러오는지
2) Bad: LLM이 Malicious한 목적에 어떻게 쓰이는가
3) Ugly: LLM에 존재하는 취약점
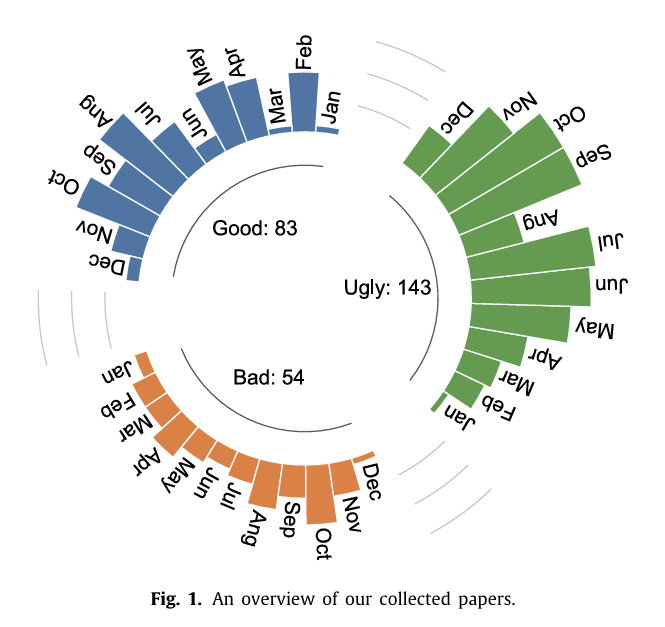
Fig1은 LLM+Security 관련 논문들을 위의 잣대를 기준으로 Google Scholar와 Compiled 페이퍼에서 조사한 결과이다.
확실히 Good 페이퍼가 Bad 페이퍼보다 많다.
4. Positive impacts of security and privacy
1) 코드 시큐리티를 위한 LLM
1> Secure coding
가. Sandoval et al.의 연구
LLMs의 도움을 받은 그룹은 새로운 보안 문제를 일으키지 않았다.
나. He et al.의 연구
LLMs를 이용한 코드 생성의 보안을 크게 향상시키는 방법을 제안했다.
다. Mohammed et al.의 연구
보안 코드를 평가하기 위한 새로운 프레임워크를 소개했으며, Madhav et al.은 ChatGPT를 사용하여 보안 하드웨어 코드를 생성하는 방법을 탐구했다.
2> Test case generating
가. Zhang et al.의 연구: ChatGPT-4.0을 사용하여 보안 테스트 생성
취약한 라이브러리 종속성이 소프트웨어에 미치는 영향을 평가하기 위해 보안 테스트를 생성하였다.
LLMs가 기존의 보안 테스트 생성기보다 뛰어난 성능을 보였으며, 55개 애플리케이션에서 24건의 성공적인 공격을 시연함.
나. Libro 프레임워크:
LLMs를 사용한 자동화된 테스트 케이스 생성:
소프트웨어 보안 버그를 재현하는 테스트 케이스를 자동으로 생성하는 프레임워크.
다. 퍼징
Fuzz4All :
목적: LLMs를 입력 생성기와 변이 엔진으로 사용하여 다양한 언어(C, C++)에 대한 현실적인 입력 생성.
성과: 기존 커버리지보다 평균 36.8% 향상.
CHATAFL:
목적: LLM을 이용한 프로토콜 퍼저로, 메시지 유형의 문법을 구성하고 메시지를 변형하거나 다음 메시지를 예측.
성과: AFLNET, NSFUZZ 등 기존 퍼저보다 더 나은 상태와 코드 커버리지 달성.
이 연구들은 LLMs가 보안 테스트 케이스를 생성하는 데 효과적이며, 특히 보안 취약점을 탐지하는 데 있어서 기존 방법들보다 더 나은 성과를 거둘 수 있음을 보여준다.
3> Vulnerable code detecting
가. Noever의 연구
주제: OpenAI의 GPT-4를 사용한 소프트웨어 취약점 탐지.
결과: GPT-4가 전통적인 정적 코드 분석 도구(예: Snyk, Fortify)보다 약 네 배 더 많은 취약점을 발견함.
나. Moumita et al.의 연구
주제: LLM을 이용한 소프트웨어 취약점 탐지.
결과: 기존 정적 분석 도구와 비교할 때 성능 격차가 존재하며, 이는 LLM이 생성하는 오탐(false alerts)의 높은 발생률에서 기인함.
다. Cheshkov et al.의 연구
주제: ChatGPT 모델을 이용한 코드 취약점 탐지.
결과: ChatGPT는 이진 및 다중 레이블 분류 작업에서 더미 분류기(dummy classifier)보다 나은 성과를 보이지 않음.
라. Wang et al.의 DefectHunter
주제: LLM 기반 기법을 사용한 코드 취약점 탐지 모델.
결과: Conformer 등의 고급 메커니즘과 LLMs의 결합으로 Pongo-70B와 비교할 때 14.64%에서 20.62%로 효과성 향상.
라. LATTE
주제: LLMs를 활용한 정적 바이너리 타인트 분석 방법.
결과: Emtaint, Arbiter, Karonte 등의 기존 기술을 능가하며, 실제 펌웨어에서 37개의 새로운 버그를 탐지.
마. 특정 도메인에서의 LLM 활용
블록체인: Chen et al. [50]과 Hu et al. [51]은 LLM을 사용하여 블록체인 스마트 계약의 취약점을 탐지.
웹 애플리케이션: Sakaoglu의 KARTAL [52]은 웹 애플리케이션 취약점 탐지에서 최대 87.19%의 정확도를 달성하고 초당 539개의 예측을 수행.
취약한 라이브러리 탐지: Chen et al. [53]의 VulLibGen은 LLMs를 활용하여 취약한 라이브러리를 식별하는 방법을 제시.
하드웨어 보안: Ahmad et al. [54]은 OpenAI Codex를 사용하여 하드웨어 설계에서 보안 관련 버그를 자동으로 식별하고 수정.
침투 테스트: PentestGPT [81]는 LLM의 도메인 지식을 사용하여 침투 테스트의 각 하위 작업을 수행, 작업 완료율을 크게 향상
4> Malicious code detecting
가. Henrik Plate의 연구
주제: GPT-3.5를 사용한 악성 코드 탐지 실험.
결과: LLM 기반 악성 코드 탐지는 인간의 리뷰를 보완할 수 있지만, 완전히 대체할 수는 없다. 1800개의 이진 분류 실험에서, false positives와 false negatives가 모두 발생했다. 또한, 간단한 트릭으로 LLM의 평가를 속일 수 있었다.
나. Apiiro
주제: LLM을 사용하는 악성 코드 분석 도구.
전략: LLM 코드 패턴(LCPs)을 생성하여 코드를 벡터 형식으로 표현함으로써, 유사성을 식별하고 패키지를 효율적으로 클러스터링.
기술: LCP 탐지기는 LLM, 독점 코드 분석, 확률적 샘플링, LCP 인덱싱, 차원 축소를 포함하여 잠재적으로 악성 코드를 식별.
이 연구들은 LLM이 악성 코드 탐지에서 유용할 수 있음을 보여준다. GPT-3.5와 같은 LLM은 인간의 리뷰를 보완할 수 있으며, Apiiro와 같은 도구는 LLM을 활용하여 더욱 효율적인 악성 코드 분석을 가능하게 한다. 그러나, 아직 LLM의 평가를 속일 수 있는 트릭도 존재하므로, 인간의 감독과 함께 사용되는 것이 바람직하다.
5> Vulnerable/buggy code fixing
가. Jin et al.의 연구: InferFix
주제: Transformer 기반의 프로그램 수리 프레임워크인 InferFix를 제안.
방법: 최신 정적 분석기와 Transformer 기반 모델을 결합하여 중요한 보안 및 성능 문제를 해결.
성과: 65%에서 75% 사이의 정확도로 문제를 해결.
나. Pearce et al.의 연구
주제: LLMs가 명시적으로 취약점 수리에 대한 훈련을 받지 않아도 다양한 문맥에서 취약 코드를 수리할 수 있음을 관찰.
이 연구들은 LLMs가 프로그램 수리 작업에서 효과적임을 보여준다. 특히, Jin et al.의 InferFix는 최신 정적 분석기와 결합된 Transformer 기반의 모델을 사용하여 보안 및 성능 문제를 해결하는 데 높은 정확도를 보인다. 또한, Pearce et al.의 연구는 LLMs가 취약점 수리에 대한 특정 훈련 없이도 다양한 문맥에서 효과적으로 취약 코드를 수리할 수 있음을 시사한다.
다. Fu et al.의 연구
주제: ChatGPT의 취약점 관련 작업 수행 능력 평가.
작업: 취약점 예측, 분류, 심각도 추정 등.
데이터: 190,000개 이상의 C/C++ 함수 분석.
결과: ChatGPT의 성능이 취약점 탐지에 특화된 다른 LLM들보다 뒤처짐.
라. Sobania et al.의 연구
주제: ChatGPT의 버그 수정 능력 평가.
결과: 표준 프로그램 수리 방법과 경쟁력을 보이며, 40개의 버그 중 31개를 수정하는 데 성공.
마. Xia et al.의 연구: ChatRepair
주제: 사전 훈련된 언어 모델(PLMs)을 활용한 패치 생성, 버그 수정 데이터셋에 의존하지 않음.
목적: ChatGPT의 코드 수정 능력 향상.
결과: 337개의 버그 중 162개를 수정, 버그 하나당 $0.42의 비용 소요.
이 연구들은 ChatGPT가 코드 버그 탐지 및 수정에서 유용할 수 있음을 보여준다. Fu et al.의 연구는 ChatGPT가 다른 취약점 탐지 LLM들보다 성능이 낮음을 발견했지만, Sobania et al.의 연구는 ChatGPT가 버그 수정에서 경쟁력을 보인다고 평가했다. Xia et al.의 ChatRepair는 ChatGPT의 코드 수정 능력을 향상시키기 위해 사전 훈련된 언어 모델을 활용하여 상당한 성과를 거두었다.
연구 결과 요약
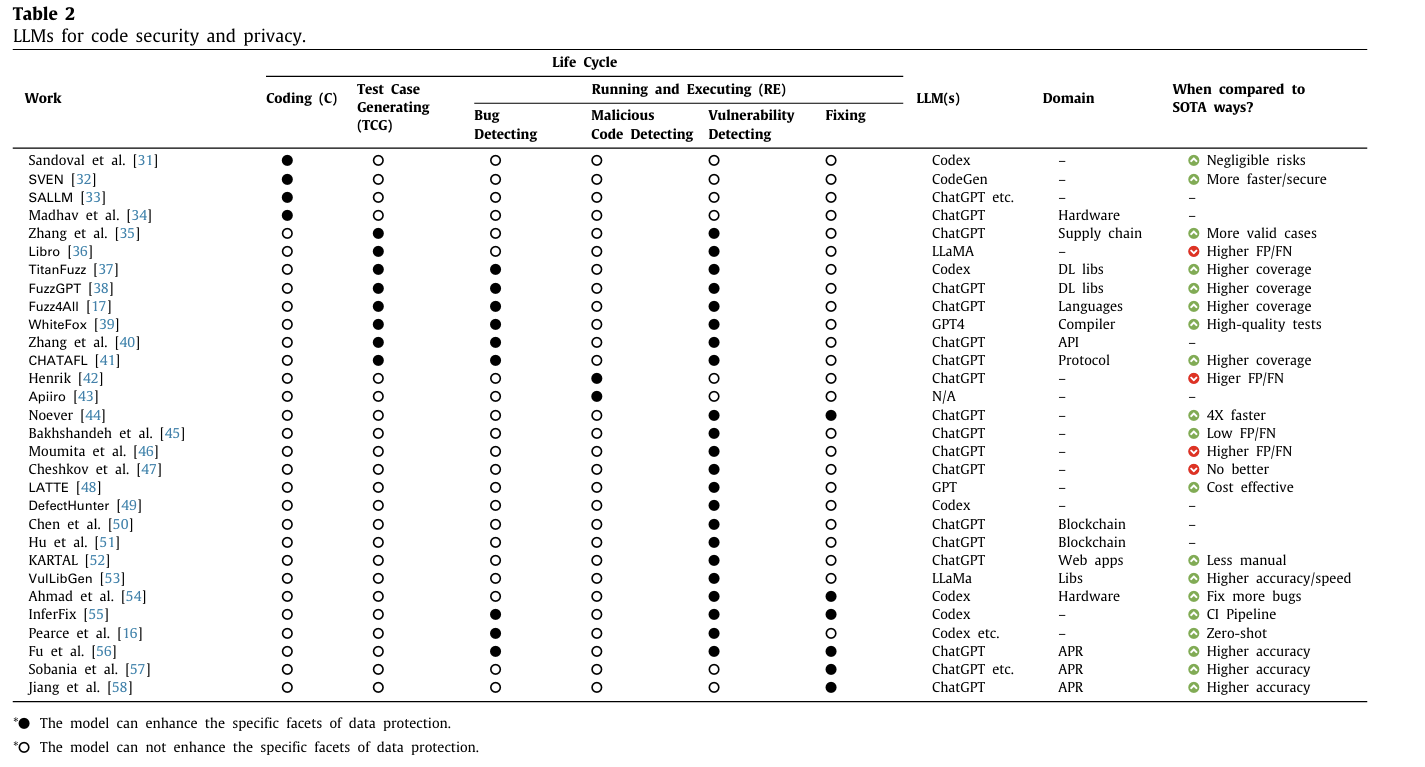
LLM 기반 방법의 우수성: Table 2에 따르면, 25개의 연구 중 17개 연구에서 LLM 기반 방법이 전통적인 접근법보다 우수하다고 결론지었다.
장점: LLM 기반 방법의 장점으로는 더 높은 코드 커버리지, 더 높은 탐지 정확도, 더 낮은 비용 등이 있다.
반대 의견
소수 의견: 4개의 연구에서는 LLM 기반 방법이 최신 방법(state-of-the-art)보다 우수하지 않다고 주장했다.
LLM 기반 방법의 한계
주요 문제점: LLM 기반 방법의 가장 자주 언급되는 문제는 취약점이나 버그를 탐지할 때 높은 비율의 false negatives(거짓 음성)와 false positives(거짓 양성)를 생성하는 경향이다.
2) 데이터 시큐리티와 프라이버시를 위한 LLMs
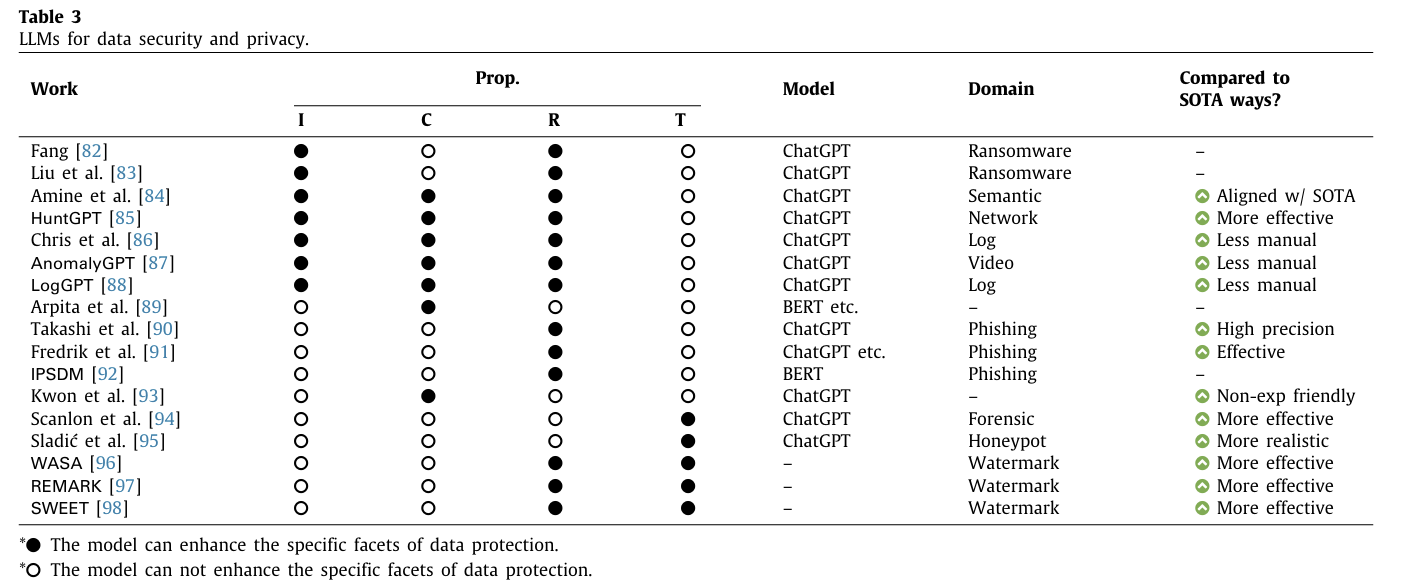
1> Data integrity
가. Wang Fang의 연구
주제: LLMs를 이용한 랜섬웨어 사이버 보안 전략.
내용: 실시간 분석, 자동 정책 생성, 예측 분석 및 지식 전이를 이론적으로 제안.
한계: 이러한 전략은 아직 경험적 검증이 부족하다.
나. Liu et al.의 연구:
주제: LLMs를 이용한 사이버 보안 정책 생성 가능성 탐구.
내용: 데이터 유출을 포함한 랜섬웨어 공격을 완화하기 위한 사이버 보안 정책을 생성.
비교: GPT가 생성한 GRC(거버넌스, 리스크 및 컴플라이언스) 정책을 기존 보안 벤더 및 정부 사이버 보안 기관의 정책과 비교.
결론: 기업들은 GPT를 GRC 정책 개발에 통합할 것을 권장.
LLMs를 이용한 실시간 분석, 자동 정책 생성 및 예측 분석은 이론적으로 유망하지만, 실제 적용을 위해서는 추가적인 경험적 검증이 필요하다.
Liu et al.의 연구는 LLMs가 생성한 사이버 보안 정책이 기존 정책과 비교하여 실질적인 가능성을 보여주며, 기업들에게 이러한 기술을 정책 개발에 통합할 것을 권장한다.
2> Anomaly detection
가. Amine et al.의 연구
주제: 시각 기반 정책에서 의미적 이상을 탐지하기 위한 LLM 기반 모니터링 프레임워크를 소개.
적용 분야: 자율 주행을 위한 유한 상태 기계 정책과 객체 조작을 위한 학습된 정책.
결과: 인간의 추론과 일치하는 의미적 이상을 효과적으로 식별.
나. HuntGPT
주제: 네트워크 이상 탐지를 위한 LLM 기반 침입 탐지 시스템.
결과: 사용자 이해와 상호작용을 개선하는 데 효과적.
다.Chris et al.와 LogGPT의 연구
주제: 평행 파일 시스템에서 로그 기반 이상 탐지를 위해 ChatGPT의 잠재력 탐구.
결과: 전통적인 수동 라벨링 및 해석 문제 해결.
라. AnomalyGPT
주제: 산업 이상을 탐지하기 위한 대형 비전 언어 모델 사용.
결과: 수동 임계값 설정을 제거하고 다중 턴 대화를 지원.
이 연구들은 LLM이 이상 탐지에서 매우 유용할 수 있음을 보여준다. LLM을 활용한 접근법은 자율 주행, 네트워크 보안, 파일 시스템 관리 및 산업 환경 등 다양한 분야에서 효과적으로 비정상적인 행동을 식별하고 대응할 수 있다. 이는 데이터의 무결성, 기밀성 및 신뢰성을 보호하는 데 중요한 역할을 한다.
3> Data confidentiality
가. LLM 기반 프라이버시 향상 기술
최신 프라이버시 향상 기술: 영지식 증명(zero-knowledge proofs), 차등 프라이버시(differential privacy), 연합 학습(federated learning) 등을 포함.
연구 사례: LLM을 사용하여 사용자 프라이버시를 향상시키는 시도가 소수 존재한다.
나. Arpita et al.의 연구
주제: LLM을 사용하여 텍스트 데이터의 식별 정보를 일반적인 마커로 대체함으로써 프라이버시 보호.
방법: 이름, 주소, 신용카드 번호 등의 민감한 정보를 저장하는 대신, 마스킹된 토큰에 대한 대체 값을 제안하여 데이터 유출을 방지.
효과: LLM을 사용하여 마스킹된 토큰의 대체 값을 생성함으로써, 모델을 원본 정보의 프라이버시와 보안을 손상시키지 않고 학습시킬 수 있다.
유사 연구: 다른 연구들에서도 유사한 아이디어가 탐구됨
다. Hyeokdong et al.의 연구
주제: ChatGPT를 사용한 암호화 구현.
방법: 광범위한 코딩 기술이나 프로그래밍 지식 없이도 ChatGPT를 통해 암호화 알고리즘을 성공적으로 구현.
효과: ChatGPT가 암호화 작업을 수행할 수 있는 잠재력을 강조.
이 연구들은 LLM이 데이터 기밀성을 보호하는 데 유용할 수 있음을 보여준다. 특히, 텍스트 데이터에서 민감한 정보를 마스킹하고 대체 값을 생성함으로써 프라이버시를 보호하는 방법이나, ChatGPT를 통해 암호화 알고리즘을 구현하는 방법이 연구되었다. 이러한 접근법들은 LLM을 활용하여 데이터 기밀성을 유지하면서도 효율적으로 데이터를 처리할 수 있는 가능성을 제시한다.
4> Data reliability
가. Takashi et al.의 연구
주제: ChatGPT를 사용한 피싱 콘텐츠 탐지.
결과: GPT-4를 사용한 실험 결과, 높은 정밀도와 재현율을 보여줌.
나. Fredrik et al.의 연구
주제: 네 가지 대형 언어 모델(GPT, Claude, PaLM, LLaMA)을 사용한 피싱 이메일 내 악의적 의도 탐지 능력 평가.
결과: 대체로 효과적이며, 인간 탐지 능력을 능가하기도 함. 그러나 가끔씩 정확도가 조금 떨어지기도 함.
다. IPSDM
주제: BERT 계열에서 미세 조정된 모델로 피싱 및 스팸 이메일을 효과적으로 식별.
결과: 불균형 및 균형 데이터 세트 모두에서 우수한 성능을 보임.
이 연구들은 LLM이 데이터 신뢰성을 보장하는 데 매우 유용할 수 있음을 보여준다. 특히, GPT-4와 같은 모델은 피싱 콘텐츠와 이메일을 효과적으로 탐지하여 높은 정밀도와 재현율을 보이며, 다른 대형 언어 모델들도 유사한 성과를 보인다. BERT 계열 모델의 미세 조정된 버전은 피싱 및 스팸 이메일 탐지에서 뛰어난 성능을 발휘한다. 이러한 연구들은 LLM이 데이터의 정확성과 신뢰성을 높이는 데 중요한 도구가 될 수 있음을 시사한다.
5> Data traceability
가. Scanlon et al.의 연구:
주제: ChatGPT가 로그, 파일, 클라우드 상호작용, 실행 가능한 바이너리, 메모리 덤프 등의 OS 아티팩트를 분석하는 데 어떻게 도움이 되는지 탐구.
목적: 의심스러운 활동이나 공격 패턴을 탐지하기 위해 디지털 증거를 분석.
나. Sladić et al.의 연구:
주제: ChatGPT와 같은 생성 모델을 사용하여 현실적인 허니팟을 만들어 인간 공격자를 속이는 방법 제안.
이 연구들은 LLM이 데이터 추적 가능성을 높이는 데 매우 유용할 수 있음을 보여준다. 특히, ChatGPT와 같은 모델은 로그, 파일, 클라우드 상호작용 등 다양한 디지털 증거를 분석하여 의심스러운 활동이나 공격 패턴을 탐지하는 데 효과적이다. 또한, 생성 모델을 사용하여 현실적인 허니팟을 만들어 공격자를 속이는 방법도 탐구되었다. 이러한 접근법들은 데이터 추적 가능성을 높이고, 포렌식 조사와 사이버 보안에서 중요한 역할을 할 수 있음을 시사한다.
연구 결과 요약
대형 언어 모델(LLMs)이 데이터 보호에 탁월하며, 현재의 솔루션을 능가하고 적은 수작업 개입을 요구한다.
특히 ChatGPT가 다양한 보안 응용 프로그램에서 널리 사용되고 있다.
5. Negative impacts on security and privacy
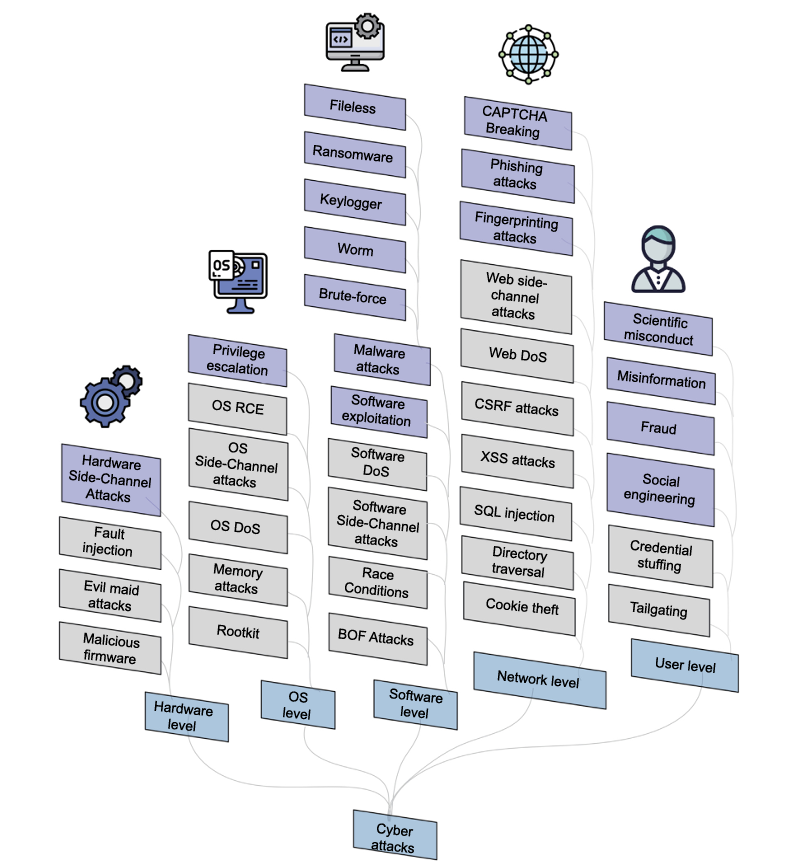
1) Hardware-level attacks
가. 사이드 채널 공격(Side-Channel Attack)
사이드 채널 공격은 물리적 시스템이나 구현에서 의도치 않은 정보 유출을 분석하여 비밀 정보를 유추하는 공격 방법이다.
예를 들어, 암호화 장치나 소프트웨어에서 키를 유추하는 것이 포함된다.
LLM이 이러한 사이드 채널 공격을 강화할 수 있다.
나. Yaman의 연구
연구 주제: LLM 기술을 사용하여 사이드 채널 분석 방법을 개발.
연구 시나리오: AES 사이드 채널 분석과 딥러닝 가속기 사이드 채널 분석의 두 가지 하드웨어 관련 시나리오에서 LLM 기반 접근법의 효과 평가.
실험 결과: 두 상황에서 이러한 방법의 성공률을 결정하기 위한 실험이 수행되었다.
LLM은 물리적 장치에 직접 접근할 수 없지만, 관련된 부수적인 정보를 분석하여 비밀 정보를 유추하는 데 유용할 수 있다. Yaman의 연구는 LLM 기반 사이드 채널 분석 방법이 두 가지 하드웨어 관련 시나리오에서 어떻게 적용될 수 있는지 평가했다.
2) OS-level attacks
가. LLMs의 제한
LLMs는 높은 수준의 추상화에서 작동하며, 텍스트 기반 입력과 출력을 주로 다룬다.
운영 체제 수준의 공격을 실행하는 데 필요한 저수준 시스템 접근 권한이 부족하다. 따라서 정보분석의 용도로 사용될 가능성이 있다.
나. Andreas et al.의 연구
주제: LLM과 취약한 가상 머신을 SSH를 통해 연결하는 피드백 루프를 설정.
목적: LLM이 가상 머신의 상태를 분석하고, 취약점을 식별하며, 구체적인 공격 전략을 제안하고 자동으로 실행.
다. 후속 연구
주제: 자동화된 Linux 권한 상승 벤치마크 도구를 소개.
방법: 로컬 가상 머신과 LLM이 안내하는 권한 상승 도구를 사용하여 다양한 LLM과 프롬프트 전략을 평가.
3) SW-level attacks
가. Mika et al.의 연구
주제: ChatGPT를 이용해 악성 소프트웨어를 배포하는 개념 증명.
결과: 탐지를 피하면서 악성 소프트웨어를 배포할 수 있음을 보여줌.
나. Yin et al.의 연구
주제: LLM을 악용해 여러 종류의 악성 소프트웨어(랜섬웨어, 웜, 키로거, 브루트포스 악성 코드, 파일리스 악성 코드)를 생성.
결과: LLM의 악용 가능성을 조사.
다. Antonio Monje et al.의 연구
주제: ChatGPT를 속여 빠르게 랜섬웨어를 생성하는 방법.
결과: ChatGPT를 속여 악성 소프트웨어를 생성할 수 있음을 시연.
라. Marcus Botacin의 연구
주제: 다양한 코딩 전략(전체 악성 소프트웨어 생성, 악성 소프트웨어 기능 생성)을 탐구하고, LLM의 악성 코드 재작성 능력을 조사.
결과: LLM은 블록 설명을 사용하여 악성 소프트웨어를 효과적으로 구성할 수 있으며, 동일한 의미의 다양한 버전(악성 소프트웨어 변종)을 생성할 수 있음. 이러한 변종의 탐지율은 4%에서 55% 사이에서 다양하게 나타남.
4) Network-level attacks
가. Fredrik et al.의 연구
주제: GPT-4를 사용해 생성한 AI 기반 피싱 이메일과 V-Triad로 수작업으로 설계된 피싱 이메일을 비교.
결과: 개인화된 피싱 이메일(AI 생성 또는 수작업 설계)이 일반적인 피싱 이메일보다 클릭률이 높았음.
나. Tyson et al.의 연구
주제: ChatGPT의 입력을 수정하여 생성된 이메일의 설득력을 높이는 방법을 조사.
결과: 입력 수정으로 더 설득력 있는 피싱 이메일 생성 가능.
다. Julian Hazell의 연구
주제: ChatGPT를 사용해 현실적이고 비용 효율적인 피싱 메시지를 생성하여 영국의 600명 이상의 국회의원 대상으로 스피어 피싱 캠페인의 확장성을 시연.
결과: ChatGPT를 활용한 피싱 메시지 생성의 확장성과 비용 효율성을 입증.
라.Wang et al.의 연구
주제: 전통적인 방어 메커니즘이 LLM 시대에 어떻게 실패할 수 있는지를 논의.
결과: CAPTCHA 도전 과제가 텍스트와 음성을 사용하는 챗봇을 탐지하는 데 어려움을 겪으며, LLM은 고품질의 인간과 같은 텍스트를 생성하고 인간 행동을 모방할 수 있음.
마.Armin et al.의 연구
주제: LLM을 활용한 지문 공격 배포.
방법: HTTP 배너를 밀도 기반 클러스터링으로 클러스터링하고 스캔 데이터를 주석 처리하기 위한 텍스트 기반 지문 생성.
결과: 기존 데이터베이스와 비교하여 새로운 IoT 장치와 서버 제품 식별 가능.
5) User-level attacks
1> Misinformation (잘못된 정보)
문제점: LLM이 생성한 콘텐츠에 과도하게 의존하면 온라인 콘텐츠의 안전성에 심각한 우려가 제기된다.
연구: 여러 연구는 LLM이 생성한 콘텐츠가 탐지하기 더 어렵고, 더 기만적인 스타일을 사용하여 더 큰 피해를 초래할 수 있다고 밝힘.
대응: Canyu Chen et al.는 LLM이 생성한 잘못된 정보에 대한 분류 체계를 제안하고 이를 검증하는 방법을 개발했다. 다양한 대응책과 탐지 방법도 개발되었다.
2> Social Engineering (사회 공학)
문제점: LLM은 훈련 데이터에서 콘텐츠를 생성할 뿐만 아니라 공격자에게 사회 공학적 공격의 새로운 관점을 제공한다.
연구: Stabb et al.의 연구는 LLM이 텍스트에서 위치, 소득, 성별 등 개인 속성을 유추할 수 있음을 강조한다. 또한, 무해해 보이는 질문에서 개인 정보를 추출할 수 있다.
추가 연구: Tong et al.은 LLM이 생성한 콘텐츠에 사용자 정보가 포함될 수 있음을 조사했다. Polra Victor Falade는 심리적 조작, 표적 피싱 및 진위 위기 등의 전술을 이용한 LLM 주도의 사회 공학 공격을 설명한다.
3> Scientific Misconduct (과학적 부정행위)
문제점: LLM의 책임 없는 사용은 원본이고 일관된 텍스트를 생성할 수 있는 능력으로 인해 과학적 부정행위와 관련된 문제를 초래할 수 있다.
연구: 학계에서는 LLM 시대에 과학적 부정행위를 탐지하는 것이 점점 더 어려워지고 있다고 우려하고 있다. LLM은 불확실한 출처에서 논문을 완전히 생성할 수 있다.
대응: 연구자들은 이러한 부정행위를 탐지하기 위해 노력하고 있다. 예를 들어, Kavita Kumari et al.은 DEMASQ라는 정확한 ChatGPT 생성 콘텐츠 탐지기를 제안했다. DEMASQ는 텍스트 구성의 편향과 회피 기술을 고려하여 다양한 도메인에서 높은 정확도로 ChatGPT 생성 콘텐츠를 식별한다.
4> Fraud (사기)
문제점: 사이버 범죄자들은 FraudGPT라는 새로운 도구를 개발했다. 이 도구는 ChatGPT처럼 작동하지만, 사이버 공격을 촉진한다.
특징: FraudGPT는 ChatGPT의 안전 제어가 없으며 다크 웹과 텔레그램에서 월 $200 또는 연간 $1,700에 판매된다. FraudGPT는 은행 관련 사기 이메일을 작성하고, 악성 링크 삽입을 제안하며, 자주 표적이 되는 사이트나 서비스를 나열하여 해커가 미래의 공격을 계획하는 데 도움을 준다.
추가 도구: WormGPT는 무제한 문자 지원 및 채팅 메모리 유지 기능을 제공하는 사이버 범죄 도구이다. 이 도구는 악성 코드 및 사기 관련 데이터에 중점을 둔 기밀 데이터 세트로 훈련되어 사이버 범죄자가 비즈니스 이메일 침해(BEC) 공격을 수행하는 데 도움을 준다.
연구 결과 요약
사용자 수준의 공격이 가장 흔한 이유는 LLMs가 인간과 유사한 추론 능력을 가지면서 인간과 유사한 콘텐츠를 생성할 수 있기 때문이다.
현재 LLMs는 운영 체제나 하드웨어 수준의 접근 권한이 제한되어 있지만, 네트워크 수준에서는 피싱 웹사이트 생성 및 CAPTCHA 우회와 같은 공격을 수행할 수 있다.
이는 사용자 수준의 공격이 가장 빈번하게 발생하는 이유를 잘 설명해 준다.
6) Vulnerabilities and defenses in LLMs
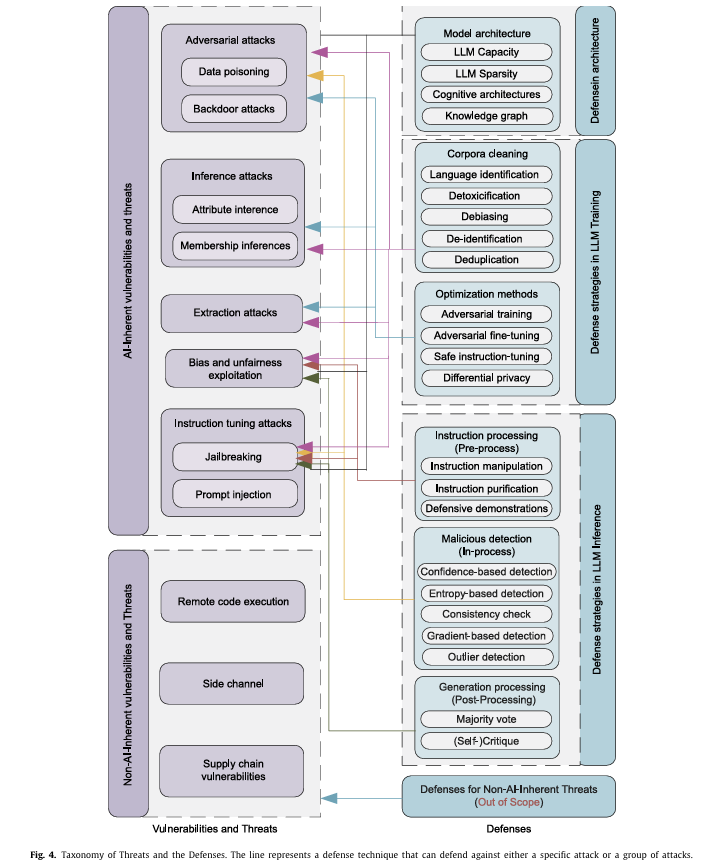
6.1.1. AI Inherent vulnerabilities and threats
LLM은 본질적으로 AI 모델이므로 그 구조와 학습 방식에서 기인하는 고유한 취약성과 위협이 존재한다.
특히, 공격자가 입력 데이터를 조작하여 LLM이 잘못된 출력을 생성하게 만드는 경우가 이러한 위협의 한 예이다.
이러한 문제를 해결하기 위해서는 LLM의 보안 강화와 더불어 입력 데이터의 무결성을 보장하기 위한 추가적인 조치가 필요하다.
1> Adversarial attacks
적대적 공격은 머신러닝 모델의 취약성을 악용하는 다양한 기술과 전략을 포함한다.
데이터 중독과 백도어 공격은 가장 많이 논의되는 두 가지 주요 공격 유형이다.
이러한 공격을 방지하기 위해서는 모델 훈련 데이터의 무결성을 보장하고, 모델의 보안성을 강화하는 추가적인 조치가 필요하다.
가. Data Poisoning
데이터 중독:
데이터 중독은 공격자가 악의적인 데이터를 훈련 데이터셋에 주입하여 훈련 과정을 조작하는 것을 의미한다.
이는 모델의 보안, 효과성 또는 윤리적 행동을 손상시킬 수 있는 취약성이나 편향을 도입할 수 있다.
여러 연구는 사전 훈련된 모델이 신뢰할 수 없는 가중치나 콘텐츠를 사용하거나, 데이터셋에 중독된 예시를 삽입하는 등의 방법으로 손상될 수 있음을 보여준다.
사전 훈련된 모델의 특성상, LLMs는 데이터 중독 공격에 취약하다.
Alexander et al.의 연구는 100개의 중독된 예시만으로도 LLMs가 다양한 작업에서 일관되게 부정적인 결과나 결함이 있는 출력을 생성할 수 있음을 보여주었다.
더 큰 언어 모델일수록 중독에 더 취약하며, 데이터 필터링이나 모델 용량 감소와 같은 기존 방어책은 테스트 정확도를 해치면서도 중간 정도의 보호만 제공한다.
나. Backdoor Attacks
백도어 공격:
백도어 공격은 훈련 데이터와 모델 처리 과정을 악의적으로 조작하여, 모델에 숨겨진 백도어를 심는 것을 의미한다.
공격자가 특정 트리거를 통해 모델의 특정 행동이나 응답을 조작할 수 있도록 한다.
백도어 공격과 데이터 중독 공격의 차이:
두 공격 모두 머신러닝 모델을 조작하지만, 백도어 공격은 숨겨진 트리거를 도입하여 특정 행동을 조작하는 데 중점을 둔다.
데이터 중독은 모델의 전반적인 성능을 저하시킬 수 있지만, 백도어 공격은 특정 상황에서만 발동된다.
LLMs에 대한 백도어 공격:
LLMs는 백도어 공격에 취약하다.
예를 들어, Yao et al.의 연구는 트리거 메커니즘과 프롬프트 튜닝을 결합한 양방향 백도어를 제안했다.
2> Inference attacks
추론 공격은 적대자가 특정 쿼리나 모델에 대한 관찰을 통해 머신러닝 모델이나 그 훈련 데이터에 대한 민감한 정보나 통찰을 얻으려는 공격 유형을 의미한다.
이러한 공격은 모델의 응답에서 의도하지 않은 정보 유출을 악용하여 수행된다.
가. Attribute Inference Attacks
속성 추론 공격은 머신러닝 모델의 응답을 분석하여 개인이나 엔티티의 민감한 속성을 추론하는 공격 방법이다.
LLM도 이러한 공격에 취약하며, Robin et al.의 연구는 LLM이 텍스트를 통해 다양한 개인 정보를 높은 정확도로 추론할 수 있음을 보여준다.
이를 방지하기 위해서는 모델의 응답에서 민감한 정보가 유출되지 않도록 설계하고, 데이터 프라이버시 보호를 위한 추가적인 보안 조치가 필요하다.
나. Membership Inferences
특정 데이터 레코드가 머신러닝 모델의 훈련 데이터셋에 포함되었는지 여부를 확인하려는 공격 유형이다.
공격자는 모델에 대한 white-box 또는 black-box 접근 권한을 이용해 특정 데이터 레코드의 멤버십을 확인한다.
white-box 접근: 모델의 내부 구조와 가중치에 접근할 수 있는 경우, 공격자는 특정 데이터 레코드가 훈련 데이터셋에 포함되었는지를 추론할 수 있다.
black-box 접근: 모델의 출력만을 관찰할 수 있는 경우, 공격자는 출력 패턴을 분석하여 특정 데이터 레코드의 멤버십을 추론할 수 있다.
-
연구 사례:
1) 레이블 분석: 레이블 정보를 분석하여 멤버십을 추론하는 방법이다.
2) 임계값 결정: 모델 출력의 확률 값이나 손실 값을 분석하여 특정 임계값을 설정하고, 이를 통해 멤버십을 추론하는 방법이다.
3) 일반화된 공식 개발: 멤버십 추론을 위한 일반화된 공식을 개발하여 다양한 상황에 적용할 수 있도록 하는 방법이다. -
Mireshghallah et al.의 연구:
헤드 미세 조정의 취약성: 모델의 헤드를 미세 조정하는 경우, 작은 어댑터를 미세 조정하는 것보다 멤버십 추론 공격에 더 취약하다는 것을 발견했다.
의의: 모델 구조와 훈련 방법에 따라 멤버십 추론 공격에 대한 취약성이 달라질 수 있음을 시사한다.
3> Extraction attacks
추출 공격은 공격자가 머신러닝 모델이나 그와 관련된 데이터에서 민감한 정보나 통찰을 추출하려는 시도를 의미한다.
이 공격은 특정 자원(예: 모델의 그래디언트, 훈련 데이터)이나 기밀 정보를 직접 얻는 것을 목표로 한다.
- 추출 공격과 추론 공격의 차이:
1) 추출 공격: 특정 자원이나 기밀 정보를 직접 얻는 것을 목표로 한다.
2) 추론 공격: 모델의 응답이나 행동을 관찰하여 모델이나 데이터의 특성에 대한 지식을 얻으려는 것이다.
훈련 데이터 추출 공격은 LLMs에 대해 효과적일 수 있다.
훈련 데이터 추출은 공격자가 머신러닝 모델에 전략적으로 쿼리를 보내 모델의 훈련 데이터에서 특정 예시를 추출하려는 방법을 의미한다.
여러 연구는 LLMs에서 훈련 데이터를 추출할 수 있음을 보여주며, 이는 개인 정보와 기밀 정보를 포함할 수 있다.
Truong et al.의 연구:
Truong et al.의 연구는 원래 모델 데이터에 접근하지 않고도 모델을 복제할 수 있는 능력으로 주목받고 있다.
4> Bias and unfairness exploitation
-
편향과 불공정성의 메커니즘:
1) 훈련 데이터의 편향: LLMs는 훈련 데이터에 포함된 편향을 학습하여 이를 그대로 재현할 수 있다.
2) 쿼리 언어의 편향: 사용자가 모델에 입력하는 쿼리 언어 자체가 편향적일 수 있으며, 이는 모델의 출력에 영향을 미친다. -
사회적 및 윤리적 영향:
1) 윤리적 책임: LLMs를 개발하고 배포하는 조직과 연구자는 모델의 편향과 공정성 문제를 해결할 윤리적 책임이 있다.
2) 연구와 감시: 편향과 공정성에 대한 연구가 활발히 이루어지고 있으며, 이는 LLMs의 신뢰성을 높이는 데 기여한다. -
다양한 분야에서의 편향:
1) 성별 및 소수 민족 그룹: 특정 그룹에 대한 차별적 결과를 생성할 수 있다.
2) 허위 정보와 정치적 측면: LLMs가 생성하는 정보가 허위 정보일 수 있으며, 정치적 편향을 포함할 수 있다.
3) 정부 검열: 모델이 정부 검열 가이드라인을 따르는 과정에서 편향이 발생할 수 있다. -
전문적 글쓰기와 코드에서의 편향:
1) 전문적 글쓰기: LLMs를 사용한 전문적 글쓰기에서의 편향은 신뢰성을 크게 훼손할 수 있다.
2) 코드 생성: LLMs가 생성한 코드에서도 편향이 나타날 수 있으며, 이는 기술적 응용에서도 중요한 문제이다.
5> Instruction tuning attacks
명령 튜닝 공격은 특정 작업을 수행하도록 명령 기반으로 미세 조정된 LLMs의 취약점을 악용하는 공격이다.
이러한 공격은 특정 작업이나 예시로 모델을 튜닝하는 과정에서 발생할 수 있는 취약점을 노린다.
가. Jailbreaking
정의: LLMs의 보안 기능을 우회하여 제한되거나 안전하지 않은 질문에 응답하도록 하는 것.
연구 사례:
여러 연구는 다양한 방법으로 LLMs를 성공적으로 jailbreaking하는 방법을 보여주었다.
1) Wei et al.는 컨텍스트 내 시연을 통해 LLMs의 정렬 기능이 조작될 수 있음을 강조했다.
2) MASTERKEY 는 시간 기반 방법을 사용하여 방어를 해체하고, 개념 증명 공격을 시연했다.
3) 기타 방법으로는 퍼징(fuzzing), 최적화된 검색 전략, LLMs를 훈련하여 다른 LLMs를 jailbreaking하는 방법 등이 있다.
4) Cao et al.는 재훈련이나 모델 매개변수에 접근하지 않고도 적대적 및 jailbreaking 프롬프트의 성공률을 낮추는 RA-LLM 방법을 개발했다.
나. Prompt Injection
정의: LLMs의 행동을 조작하여 예상치 못한 잠재적으로 해로운 응답을 유도하는 방법.
연구 사례:
많은 연구는 프롬프트 주입 공격을 자동화하고, 다양한 초점을 통해 의미 보존 페이로드를 식별하는 과정을 다루었다.
1) Greshake et al.는 LLMs가 외부 자원을 호출할 때 발생할 수 있는 새로운 취약성에 대해 우려를 표명했다.
다른 연구들은 가이드 프롬프트 공개, 프롬프트 주입의 가상화, 응용 프로그램 통합 등의 프롬프트 주입 공격을 이용하는 능력을 시연했다.
2) He et al.는 광범위한 데이터셋으로 훈련된 LLMs를 활용하여 이러한 공격을 완화하는 방향으로 전환하는 것을 탐구했다.
다. Denial of Service, DoS
정의: 자원을 고갈시켜 지연을 발생시키거나 자원을 사용할 수 없게 만드는 사이버 공격.
연구 사례:
LLMs가 상당한 양의 자원을 필요로 하기 때문에, 공격자는 의도적으로 구성된 프롬프트를 사용하여 모델의 가용성을 줄인다.
Shumailov et al.는 LLMs 분야에서 스펀지 공격(sponge attacks)을 수행할 수 있음을 증명했다. 이 공격은 에너지 소비와 지연을 최대화하는 것을 목표로 하며, 자율 주행 차량 및 신속한 의사결정이 필요한 시나리오에서 잠재적 영향을 강조한다.
연구 결과 요약
모델 추출 공격, 파라미터 추출 공격, 기타 중간 결과 추출에 대한 연구는 현재 이론적이며 실질적인 구현은 거의 이루어지지 않았다.
LLMs의 방대한 파라미터 수와 기밀 유지로 인해 전통적인 공격 방식이 어렵거나 비효율적이 될 수 있다.
또한, LLMs의 출력에 대한 엄격한 검열은 블랙박스 공격조차도 어렵게 만든다. 이러한 이유로 LLMs는 기존의 공격 전략으로부터 더 잘 보호되고 있다.
6.1.2. Non-AI Inherent vulnerabilities and threats
비 AI 고유 취약성과 위협은 LLM이 직면할 수 있는 외부 위협과 새로운 취약성을 포함한다.
이러한 공격은 AI 모델의 내부 메커니즘과 직접적으로 관련되어 있지는 않지만, 시스템 전체의 보안을 위협할 수 있다.
따라서 LLM을 안전하게 운영하기 위해서는 시스템 수준의 보안도 철저히 관리해야 한다.
1> Remote code execution(RCE)
RCE 공격은 소프트웨어 애플리케이션, 웹 서비스, 서버의 취약점을 이용하여 원격에서 임의의 코드를 실행하는 공격이다.
LLM 통합 서비스의 위험:
LLM이 웹 서비스에 통합된 경우, 해당 서비스의 인프라나 코드에서 RCE 취약점이 발견되면, 이를 통해 LLM의 환경이 손상될 수 있다.
예를 들어, https://chat.openai.com/와 같은 서비스가 RCE 공격에 취약할 경우, LLM이 포함된 서버의 보안이 위협받을 수 있다.
Tong et al.의 연구 결과:
6개의 프레임워크에서 13개의 취약점이 발견되었으며, 이 중 12개는 RCE 취약점이다.
51개의 애플리케이션 중 17개가 취약점을 가지고 있으며, 이 중 16개는 RCE 취약점, 1개는 SQL 삽입 취약점이다.
이러한 취약점은 공격자가 프롬프트 주입을 통해 애플리케이션 서버에서 임의의 코드를 실행할 수 있게 한다.
2> Side channel
사이드 채널 공격은 전력 소비나 전자기 방사와 같은 전통적인 채널을 통해 정보를 누출하지는 않지만, 시스템 수준의 구성 요소를 악용하여 민감한 정보를 추출하는 공격을 의미한다.
Edoardo et al.의 연구:
개요: 시스템 수준의 구성 요소(예: 데이터 필터링, 출력 모니터링)를 악용하여 개인 정보를 더 높은 비율로 추출할 수 있는 프라이버시 사이드 채널 공격을 소개했다.
사이드 채널의 네 가지 범주: ML 수명 주기 전체를 다루는 네 가지 사이드 채널을 제안했다.
향상된 멤버십 추론 공격: 사용자의 테스트 쿼리를 추출하는 등의 새로운 위협을 가능하게 한다.
예시: 차등 프라이버시 훈련을 적용하기 전에 훈련 데이터를 중복 제거하는 과정에서 프라이버시 보장이 손상될 수 있음을 시연했다.
3> Supply chain vulnerabilities
공급망 취약성은 LLM 애플리케이션의 라이프사이클 동안 취약한 구성 요소나 서비스를 사용함으로써 발생하는 위험을 의미한다.
여기에는 1) 서드파티 데이터셋, 2) 사전 훈련된 모델, 3) 플러그인이 포함된다.
-
공급망 취약성
1) 서드파티 데이터셋: 신뢰할 수 없는 출처에서 가져온 데이터셋은 모델의 무결성을 손상시킬 수 있다.
2) 사전 훈련된 모델: 외부에서 제공된 사전 훈련된 모델이 악성 코드나 백도어를 포함할 수 있다.
3) 플러그인: LLM의 기능을 확장하는 플러그인이 잠재적인 보안 취약성을 가질 수 있다. -
플러그인 보안 문제
1) 위험 요소: 플러그인이 채팅 기록을 훔치거나, 개인 정보에 접근하거나, 사용자 기계에서 임의의 코드를 실행할 수 있는 가능성이 있다.
2) OAuth: 플러그인이 OAuth를 통해 데이터에 접근하는 과정에서 발생할 수 있는 보안 취약성. -
Umar et al.의 연구
1) 프레임워크: 공격 유형을 분류하고 잠재적인 위험을 식별하기 위한 프레임워크를 제안했다.
2) 공격 분류: 플러그인, 사용자 및 플랫폼 자체의 기능을 기반으로 다양한 공격 유형을 분류.
6.2.1. Defense in model architecture
모델 아키텍처는 지식과 개념이 저장, 조직, 상호작용하는 방식을 결정하며, 이는 LLMs의 안전성에 중요하다.
-
모델 아키텍처와 강건성
1) 차등 프라이버시: Li et al.는 더 큰 모델이 적절한 하이퍼파라미터를 사용하면 차등 프라이버시 방식으로 더 효과적으로 훈련될 수 있음을 보여주었다.
2) 적대적 공격: Zhu et al.와 Li et al.는 더 큰 용량의 모델이 적대적 공격에 대해 더 높은 강건성을 보인다고 밝혔다.
3) OOD 시나리오: Yuan et al.는 대형 모델이 분포 외 시나리오에서도 강건성을 유지한다고 밝혔다. -
외부 모듈 결합의 이점:
1) 지식 그래프: Zafar et al.는 지식 그래프를 통해 LLMs의 추론 능력을 향상시켜 AI의 신뢰성을 높이는 방법을 제안했다.
2) 인지 아키텍처: Romero et al.는 다양한 인지 아키텍처를 LLMs에 통합하여 모델의 강건성을 개선하는 방법을 제안했다.
6.2.2 Defense in LLM training and inference
가. LLM 훈련에서의 방어 전략
모델 아키텍처:
신뢰할 수 있는 설계를 통해 악의적인 사용에 대한 강건성을 높인다.
- 훈련 데이터:
1) 데이터 정제(Corpora Cleaning):
LLM은 훈련 데이터로부터 학습하므로, 데이터의 품질이 모델의 안전성에 큰 영향을 미친다.
웹에서 수집된 원시 데이터는 공정성, 유해성, 프라이버시, 진실성 문제를 포함하고 있을 수 있다.
정제 파이프라인에는 언어 식별, 디톡스, 디바이싱, 개인 식별 정보 제거, 중복 제거가 포함된다.
예: 언어 식별, 디톡스, 디바이싱, 개인 식별 정보 제거, 중복 제거.
2) 최적화 방법:
안전하고 보안된 최적화 프레임워크:
적대적 훈련(adversarial training) 및 강건한 미세 조정(robust fine-tuning) 같은 방법들이 효과적이다.
적대적 훈련은 이미지 분야에서 영감을 받아, LLM에 적용되었다.
예: Ivgi et al., Yoo et al., Wang et al..
안전 정렬(Safety alignments):
LLM의 행동을 잘 정렬된 추가 모델이나 인간 주석을 사용하여 안내한다.
예: Zhou et al., Shi et al., Bianchi et al..
나. LLM 추론에서의 방어 전략
명령 처리(Instruction Processing):
1) 사전 처리(Pre-Processing):
사용자가 보낸 명령을 변형하여 잠재적인 악의적인 맥락이나 의도를 제거한다.
예: 명령 조작, 정화, 방어적 시연.
예: Li et al., Wei et al., Mo et al..
2) 악의적 탐지(In-Processing):
LLM의 중간 결과를 심층적으로 검토하여 악의적인 사용을 탐지한다.
예: Sun et al., Xi et al., Shao et al., Wang et al..
3) 생성 후 처리(Post-Processing):
생성된 응답 검토: 생성된 응답의 속성을 검토하고 필요시 수정하여 안전하고 적절한 출력을 보장한다.
예: Chen et al., Helbling et al., Xiong et al., Kadavath et al..
연구 결과 요약
LLM 훈련에서 모델 아키텍처의 영향을 연구한 논문의 부족은 대형 모델 훈련의 높은 비용 때문일 가능성이 크다.
또한, 안전한 명령 튜닝은 LLM의 안전성을 향상시키는 중요한 방법으로, 추가적인 연구와 주의가 필요하다.
이러한 연구는 LLM의 안전성과 신뢰성을 높이는 데 중요한 역할을 할 수 있다.
7. Discussion
1) LLM in other security related topics
1) 교육 활용:
소프트웨어 보안 과정:
학생들이 웹 애플리케이션의 취약점을 식별하고 해결하는 과제에서 LLM을 사용할 수 있다.
Jingyue et al.는 ChatGPT를 학생들이 이러한 과제에서 어떻게 사용할 수 있는지 조사했다.
2) 사이버 보안 캡처-더-플래그(CTF) 연습:
Wesley Tann et al.는 CTF 연습에서 LLM의 성능을 평가했다. 이 연습에서는 참가자들이 시스템 취약점을 이용해 "플래그"를 찾는다.
연구는 Cisco 인증 시험의 질문 답변 성능을 평가한 후, CTF 챌린지를 해결하는 능력을 조사했다.
3) 이진 코드 의미 이해:
Jin et al.는 다양한 아키텍처와 최적화 수준에서 LLM의 이진 코드 의미 이해를 종합적으로 연구했다. 이 연구는 향후 연구에 중요한 통찰을 제공한다.
4) LLM의 사이버 보안 법률, 정책 및 규정 준수에서의 활용
법률 및 정책:
LLM은 보안 정책, 지침 및 규정 준수 문서를 작성하는 데 도움을 줄 수 있으며, 조직이 규제 요구사항과 산업 표준을 충족하도록 도울 수 있다.
그러나 LLM의 도입은 현재의 사이버 보안 관련 법률과 정책에 변화를 요구할 수 있다.
Ekenobi et al.는 LLM의 도입으로 발생하는 법적 영향을 조사했으며, 특히 데이터 보호 및 프라이버시 문제에 중점을 두었다.
이 논문은 ChatGPT의 프라이버시 정책이 사용자 데이터를 잠재적인 위협으로부터 보호하는 데 탁월한 조항을 포함하고 있음을 인정한다.
2) Future directions
1) LLM을 ML-특정 작업에 사용:
LLM은 전통적인 머신 러닝 방법을 효과적으로 대체할 수 있으며, 보안 응용 분야에서도 마찬가지이다.
예를 들어, 전통적인 머신 러닝 방법이 악성 소프트웨어 탐지에 사용되는 경우, LLM도 이 목적에 사용될 수 있다.
보안 연구자들은 LLM 기반 접근 방식을 설계하여 최신 방법들과 비교하여 한계를 넘어서도록 할 수 있다.
2) 인간의 노력을 대체:
LLM은 공격 및 방어 보안 응용에서 인간의 노력을 대체할 수 있는 잠재력을 가지고 있다.
예를 들어, 전통적으로 인간의 개입이 필요한 사회 공학 작업을 LLM 기술을 사용하여 효과적으로 수행할 수 있다.
보안 연구자들은 인간의 참여가 중요한 전통적인 보안 작업에서 LLM 기능으로 대체할 수 있는 기회를 탐색해야 한다.
3) 전통적인 ML 공격을 LLM에 맞게 수정:
LLM의 많은 보안 취약점은 전통적인 머신 러닝 시나리오에서 발견된 취약점의 확장이다.
LLM은 딥 뉴럴 네트워크의 특수한 사례로, 적대적 공격 및 명령 튜닝 공격과 같은 일반적인 취약점을 상속한다.
적절한 조정(예: 위협 모델)으로 전통적인 ML 공격은 여전히 LLM에 대해 효과적일 수 있다.
예를 들어, jailbreaking 공격은 제한된 텍스트를 생성하기 위한 명령 튜닝 공격의 특정 형태이다.
4) 전통적인 ML 방어를 LLM에 맞게 조정:
전통적으로 사용되는 취약점 완화 대책은 LLM의 보안 문제를 해결하는 데도 사용할 수 있다.
예를 들어, 기존의 프라이버시 강화 기술(예: 영지식 증명, 차등 프라이버시, 연합 학습)을 사용하여 LLM의 프라이버시 문제를 해결할 수 있다.
이러한 도전 과제를 해결하기 위해 기존 방법 또는 혁신적인 접근 방식을 탐구하는 것은 유망한 연구 방향을 나타낸다.
5) LLM 특정 공격의 문제 해결:
모델 추출 또는 파라미터 추출 공격을 구현하는 데 여러 어려움이 있다
(예: LLM 파라미터의 방대한 규모, 강력한 LLM의 사유 소유 및 기밀성).
LLM이 도입한 이러한 새로운 특성은 중요한 변화를 나타내며, 전통적인 ML 공격 방법론의 진화를 필요로 할 수 있다.
