언어모델은 더 자연스러운 문장에 더 높은 확률을 부여한다.
또한 더 자연스러운것의 정의는 "일반적으로 더 많이 사용되는 것"이다.
일반적인 언어모델 프로세스
1) 언어모델로 언어에 대한 이해를 높인다.
2) 미세조정학습(지도학습) 수행
3) 모델이 분류성능을 갖게 됨
1. BERT의 구조
BERT(Bidirectional Encoder Representations from Transformers)는 모델기반의 학습으로 언어에 대한 이해룰 높인 후에 다양한 작업을 수행할 수 있다.
BERT는 트랜스포머의 인코더 부분만 사용한 모델로, 이 인코더는 양방향 셀프어텐션을 구현하고 있다.
2. Pre-training과 Fine-Tuning
Pre-training은 언어에 대한 이해를 높이기 위한 비지도학습이고, Fine-Tuning은 실제 수행하고 있는 작업에 대한 지도학습이다.
1) BERT의 사전학습
보통의 언어 모델들은 앞에 주어진 단어들 다음에 나올 단어의 확률을 예측하는 방식으로 학습한다.(트랜스포머의 디코더 구조)
트랜스포머의 디코더에서도 현재까지 단어 시퀸스를 이용해서 다음 단어를 예측하는 작업도 그 이후 단어들로부터 오는 어텐션을 활용할 수 없다.(그 단어들은 아직 생성도 안됨)
- Q: 그렇다면 어떻게 BERT는 양방향이 가능할까?
1> Masking
A: BERT는 문장안에서 랜덤한 위치의 단어를 지우고, 이 단어를 예측한다. -> masked language model
즉 가려진 단어는 문장의 중간에 위치하며, 양쪽에 단어들이 있어 양방향 셀프 어텐션을 모두 이용해 예측한다.
2> 두개의 문장을 다룰 수 있게함
ex> 두 문장이 같은 의미인지, 앞문장의 내용으로 뒤 문장의 질문에 대한 답이 가능한지 등
BERT는 두 문장을 구분하는 토큰을 정의한다. 그 후 두 문장사이에 넣어서 하나의 시퀸스로 만든 후에 인코더에서 한번에 처리할 수 있게 하였다.
또한 BERT는 두 문장에 대한 학습목표를 "순서를 맞히는 것으로 했다"
이렇게 Pre-training을 거쳐 언어에 대한 이해를 높인 후에는 Fine-Tuning작업에 들어간다.
2) BERT의 미세조정
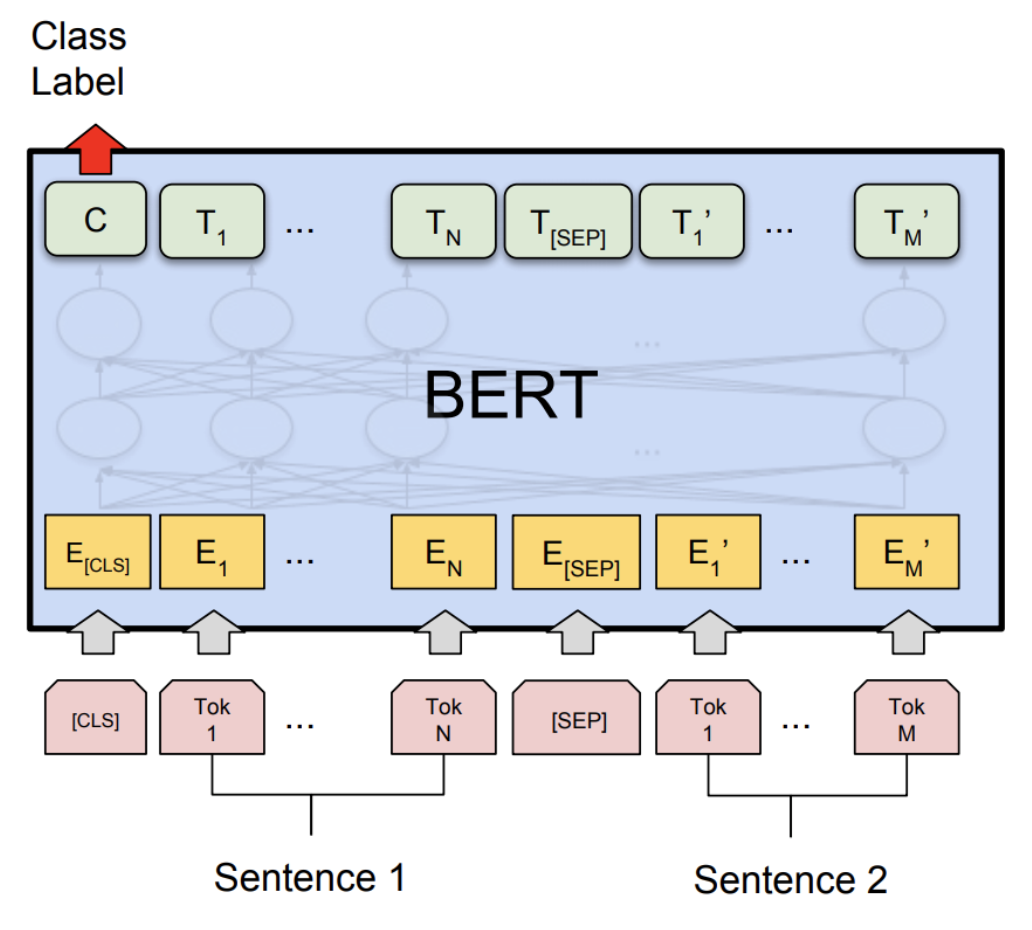
문장의 각 단어는 "Tok"로 표기된 입력에 매칭되어 T1. T2 ...로 이어진다.(BERT는 자체적인 토크나이저가 있다.)
첫째 토큰인 [CLS]를 주목하자!
CLS는 분류기 토큰으로 다른 단어들과 마찬가지로 모형의 끝까지 이어진다.
또 필요한 어텐션을 학습하게 된다.
결국 문장의 분류는 이 [CLS]토큰의 최종 출력을 이용한다.
즉 학습이 된 다른단어들(T1, T2...)은 임베딩용도로 사용하고, 문장의 분류에서는 분류기 토큰만 이용하여 Label을 예측한다.
추가로 응용을 하고 싶다면 T1, T2, T3의 단어 임베딩값을 다시 LSTM, CNN등에 넣어서 그 결과를 이용하여 예측을 할 수도 있다.(BERT + CNN)
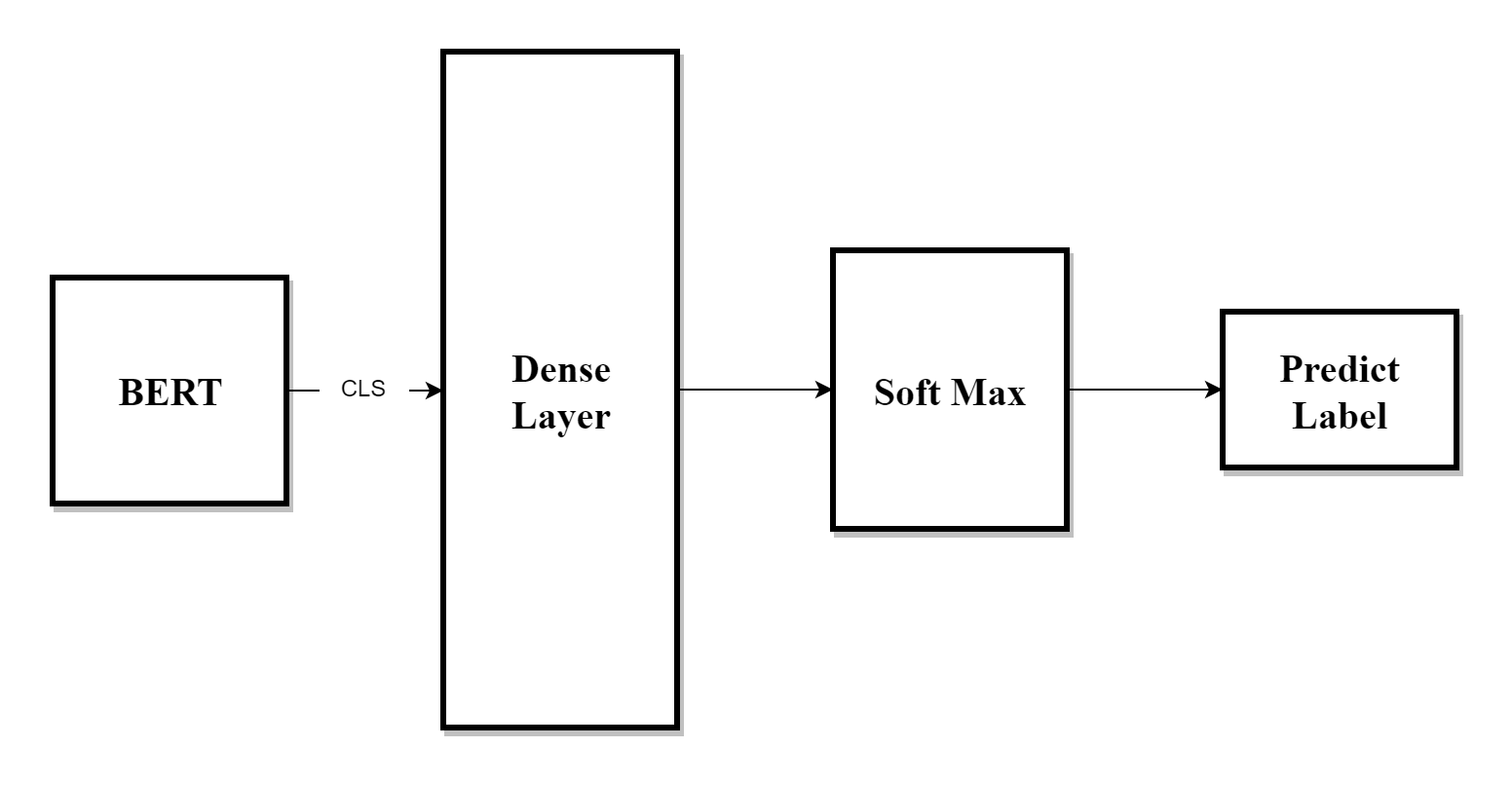
Fine-Tuning을 하게 되면 사전학습으로 만들어진 BERT의 분류기 토큰(CLS)가 분류 목적에 맞게 다시 학습된다. 또한 단어들의 어텐션도 조정이 된다. -> 분류에 있어서 CLS토큰은 그 문장 혹은 문단의 전체적인 표현임
또한 BERT모델과 추가된 분류Layer(Demse, Softmax등)을 같이 Fine-Tuning 한다. 이러면 BERT의 모든 파라미터와 분류 레이어의 파라미터가 동시에 업데이트 된다.(물론 Fine-Tuning은 분류에 쓸 데이터를 이용해서 훈련한다.)
결국 CLS토큰이 분류 작업의 입력으로 사용된다.(한 문장의 임베딩된 단어들을 대표하는 값)
3. 결론
- 사전학습된 해당 BERT의 임베딩된 벡터값은 다 똑같다. 그러나 우리의 학습데이터로 Fine-Tuning할 경우에 그 벡터값도 변하고 CLS토큰값도 변한다!
- BERT의 결과물은
1) CLS토큰(한 문장의 단어들이 임베딩된 값)과
2) 각 단어들이 임베딩된 벡터값이다.
