Disk 구조
1. Logical Block
- 디스크를 논리적으로 바라보는 단위이다.
- Logical Block은 디스크의 외부 컴퓨터 호스트가 디스크에 접근할 때 사용되는 단위로, 마치 1차원 배열처럼 구성되어 있다.
- 디스크는 논리적 블록 단위로 접근되며, 컴퓨터는 "몇 번째 블록을 읽어라"라는 식으로 디스크와 상호작용한다.
2. Sector
- 디스크를 물리적으로 관리하는 최소 단위이다.
- Sector는 Logical Block이 실제로 저장되는 물리적 공간에 해당한다.
- 디스크의 Sector는 일련의 동심 원으로 구성된 트랙(Track) 위에 배치되며, 각 트랙은 실린더(Cylinder)로 구성됩니다.
- Sector 0은 최외곽 실린더의 첫 트랙에 있는 첫 번째 섹터를 의미합니다.
Disk Management
1. Physical Formatting(Low-level formatting)
- Physical Formatting은 디스크를 처음 만들 때 수행하는 과정으로, 디스크를 섹터 단위로 나누는 작업이다.
- 이 과정은 공장에서 수행되며, 디스크가 물리적 섹터로 분할되어 디스크 컨트롤러가 읽고 쓸 수 있도록 준비된다.
- 각 섹터에는 논리적 블록 외에도 헤더(header)와 트레일러(trailer) 같은 부가 정보가 저장된다.
-> 헤더와 트레일러는 섹터 번호, 오류 검출 및 수정 코드(ECC) 등 디스크 컨트롤러가 직접 접근하고 운영하는 정보가 포함된다.
2. Partitioning
- Partitioning은 Physical Formatting 이후에 수행되는 단계로, 섹터 영역들을 묶어서 하나의 독립적인 디스크로 만들어주는 작업이다.
- 이를 통해 Logical Disk가 생성되며, 예를 들어 하나의 HDD를 C 드라이브와 D 드라이브로 나눌 수 있다.
- 운영 체제는 이러한 논리적 디스크에 접근하여 독립적인 디스크로 간주하고 사용한다.
- 각 파티션은 파일 시스템용으로도 사용될 수 있고, 스왑 영역(Swap Area) 용도로도 사용할 수 있다.
3. Logical Formatting
- Logical Formatting은 파티션에 파일 시스템을 설치하는 과정이다.
-> 예를 들어, FAT, NTFS, ext4와 같은 파일 시스템을 파티션에 설치한다.- 이를 통해 데이터가 저장될 수 있도록 파일 시스템의 구조가 만들어지고, 파일 및 디렉터리의 관리가 가능하다.
4. Booting
Booting은 디스크에 설치된 운영 체제가 메모리에 올라와 실행되는 과정이다.
- 부팅 과정은 다음과 같은 단계로 구성된다:
1) ROM에 저장된 "small boot strap loader"가 실행된다.
ROM: 비휘발성 메모리로, 컴퓨터가 켜질 때 가장 먼저 실행되는 프로그램이다.
2) 부트스트랩 로더는 HDD의 0번 섹터(부트 블록)를 메모리에 올리고 실행한다.
-> 부트 블록은 디스크의 첫 번째 섹터로, 운영 체제를 부팅하기 위한 초기 코드를 포함하고 있다.
3) 부트 블록의 코드가 실행되면, 운영 체제 커널의 위치를 찾고, 해당 커널을 메모리에 로드하여 실행한다.
4) 커널이 메모리에 로드되면, 운영 체제가 초기화되고 시스템이 완전히 부팅된다.
디스크 스케줄링
Access time의 구성
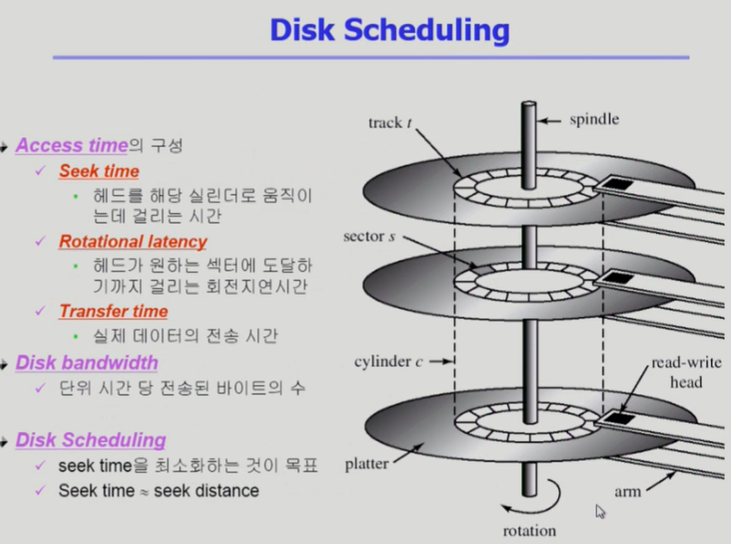
1) Seek time
디스크 헤드가 1) 해당 실린더로 움직이는데 걸리는 시간 + 2) 해당트랙까지 움직이는데 걸리는 시간
- 트랙: 통조림 파인애플
- 실린더: 통조림 파인애플 쌓인거
2) Rotational latency
원판이 회전해서 섹터 위치가 디스크 헤드한테 가는데 걸리는 시간
3) Transfer time
굉장히 적은 시간이다.
실제로 헤드가 데이터를 읽고 쓰고 하는 시간이다. (실제 데이터의 전송시간)
Disk bandwidth(디스크 성능)
단위 시간당 디스크로 전송된 바이트의 수
가능한 seek time을 줄이는게 좋다.
Disk scheduling
seek time을 최소화 하는것이 목표이다. 즉 Disk bandwidth를 높여보자!
Disk Scheduling Algorithm
1) FCFS(First Come First Service)
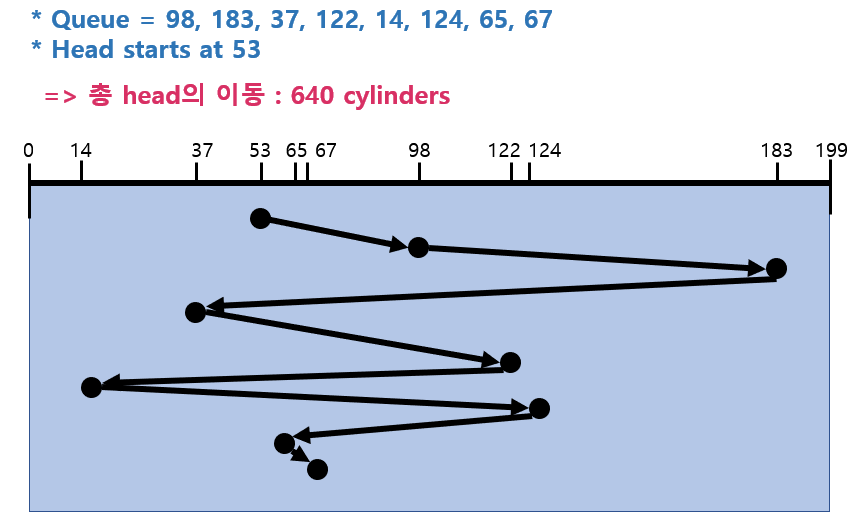
2) SSTF(Shortest Seek Time First)
현재 헤드위치에서 제일 가까운 요청을 먼저 처리한다.
Starvation 문제: 큐에 멀리 있는 애들 차례 오려고 했는데 가까운 애들이 또 왕창 들어오면 헤드가 멀리 있는 애는 처리하지 않는다.
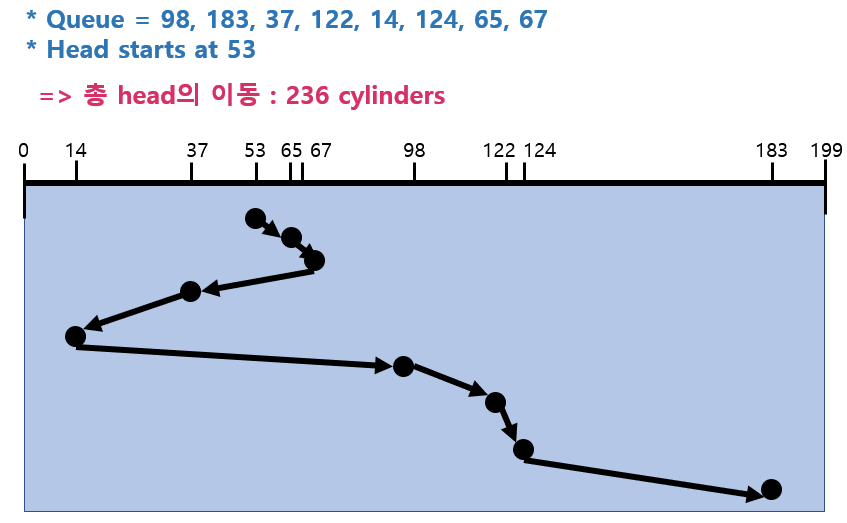
3) SCAN(엘리베이터 알고리즘)
53 -> 37 -> 14 -> 0 -> 65 -> 67 -> 98 -> 122 -> 124 -> 183
- 디스크 헤드는 항상 가장 안쪽위치에서 바깥쪾 위치로 이동하면서 가는 길목에 요청이 들어와 있으면 처리하고 지나간다.
- 제일 바깥쪽까지 나가고 방향 바꾸어서 다시 가장 바깥쪽에서 안쪽으로 들어오면서 가는 길목에 요청이 있으면 처리하고 지나간다.(반복)
-> starvation문제가 발생하지 않고 디스크의 총 이동거리도 낮다.
그러나 실린더의 위치에 따라 대기 시간이 다르다는 문제점이 있다.
1) 가운데 부분은 기다리는 시간의 예상 기대치가 짧다.
2) 가장자리 지역은 기다리는 시간의 예상 기대치가 길다.
4) C-SCAN(단 방향)
53 -> 65 -> 67 -> 98 -> 122 -> 124 -> 183 -> 199 -> 0 -> 14 -> 37
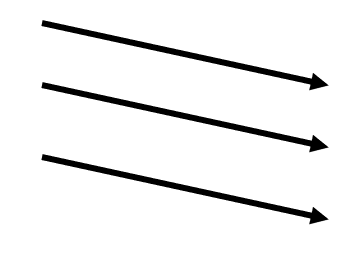
디스크 헤드가 가장 안쪽에서 바깥쪽 위치로 이동하면서 요청을 처리한다.
그러나 가장 바깥쪽에서 안쪽으로 이동할때는 큐에 들어온 요청을 처리하지 않고 헤드가 이동만 한다.
-> 이동거리는 좀 늘어나지만, SCAN보다 균일한 대기시간을 제공한다.
5) Other
가. N-SCAN
디스크 헤드가 이동하면서 현재 출발하면서 이미 큐에 들어와 있는거는 이번에 지나가면서 처리하고, 지나가는 도중에 들어오는 것들은 다음번에 처리한다.
나. Look(SCAN + a) and C-Look(C-SCAN + a)
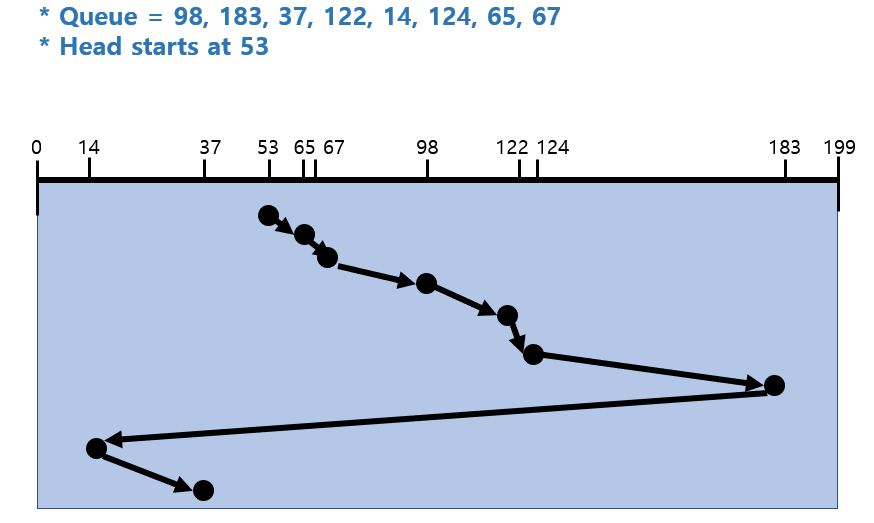
디스크헤드가 안쪽에서 바깥쪽으로 이동하다가 그 방향에 더이상의 요청이 없으면 거기서 바로 방향을 바꾼다.
디스크 스케줄링 알고리즘의 결정
현대 디스크 시스템에서는 SCAN기반 알고리즘을 많이 쓴다.
- File을 할당하는 방법도 디스크 스케줄링에 영향을 준다.
-> ex> 연속할당하면 연속된 실린더 위치에 있어서 더 이동거리 줄일 수 있다.
디스크 스케줄링 알고리즘은 OS 커널의 내부모듈과는 별도로 만들어서 필요할때 다른 알고리즘으로 교체에서 쓸 수 있게 하는 것이 바람직하다.(파일 할당에 따라 달라지기 때문이다.)
Swap-Space Management
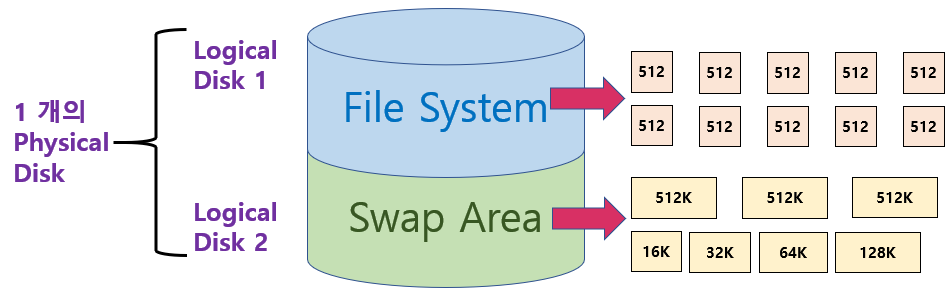
디스크를 사용하는 2가지 이유(보조기억장치)
1) 메모리의 휘발성: 파일 시스템은 비휘발성 사용해야함
2) 프로그램을 실행하기 위한 메모리 공간의 부족: Swap Space
Swap Space
물리적인 Disk를 파티셔닝 해서 논리적 Disk를 만들 수 있다.(OS는 이를 서로 다르게 구분함)
- 공간 효율성보다 속도 효율성을 우선시한다. 그 이유는 프로세스가 끝나면 Swap Area의 내용은 어차피 다 사라져버린다.
- Seek time을 줄이기 위해 단위가 매우크다(킬로바이트)
RAID(Redundant Array of Indepenent Disks)
여러개의 디스크를 묶어서 사용한다.(중복저장, 분산저장)
RAID의 사용목적
1) 디스크 처리속도 향상
여러 디스크에 데이터가 중복저장되어 있으면 호스트 컴퓨터에서 데이터를 읽어오라고 디스크에 요청시, 여러 군대에서 동시에 조금씩 조금씩 읽어올 수가 있다(병렬적으로 읽어옴)
이러면 서로 협력하기 때문에 더 빠르다.
2) 신뢰성 향상
중복 저장하면 디스크 하나가 failure발생하더라도 멀쩡한 디스크에서 데이터를 읽어올 수 있기 때문에 신뢰성을 높일 수 있다.(Mirroring, Shadowing)
Parity
단순한 중복 저장이 아니라 일부 디스크에 parity를 저장하여 공간의 효율성을 높일 수 있다.
- Parity를 통해 중복저장의 정도를 낮게 할 수 있다. 즉 오류가 생겼는지를 알아내고 복구할 수 있을 정도의 중복저장만 아주 간략하게 한다.
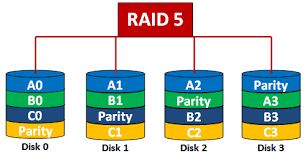
P = C1 ⊕ C2 ⊕ C3
이 상황에서 C2가 소실되면
C2 = p ⊕ C1 ⊕ C3
로 다시 복구할 수 있다.
