- 수치미분의 단점
단순하고 구현하기 쉽지만 계산 시간이 오래 걸림
"오차역전파법"을 통해 가중치의 기울기를 효율적으로 계산할 수 있다.
계산그래프
계산과정을 그래프로 나타낸 것
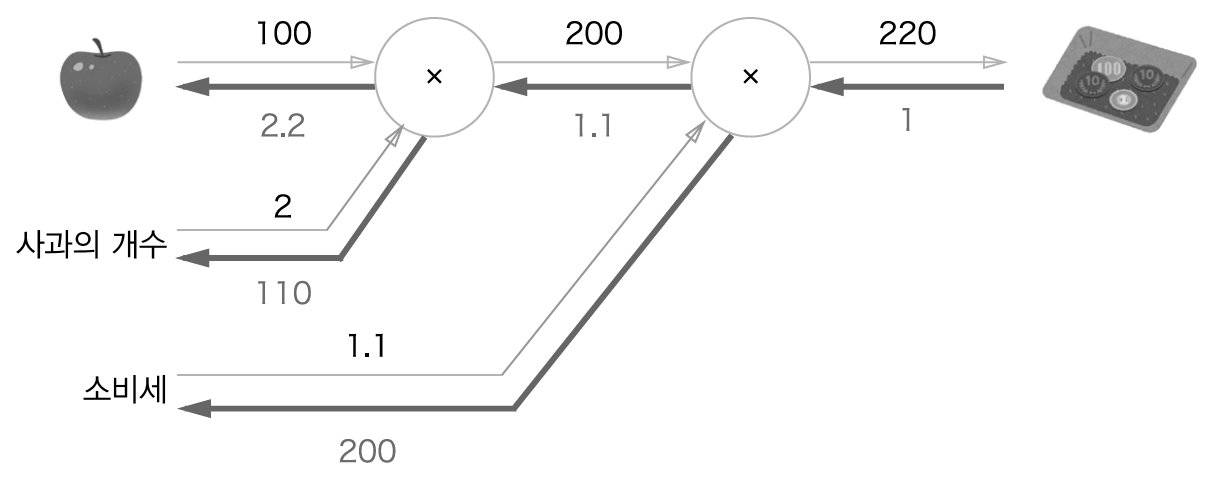
문제1: 수퍼에서 1개에 100원인 사과를 2개 샀습니다. 이때 지불 금액을 구하세요. 단 소비세가 10% 부과됩니다.

국소적 계산
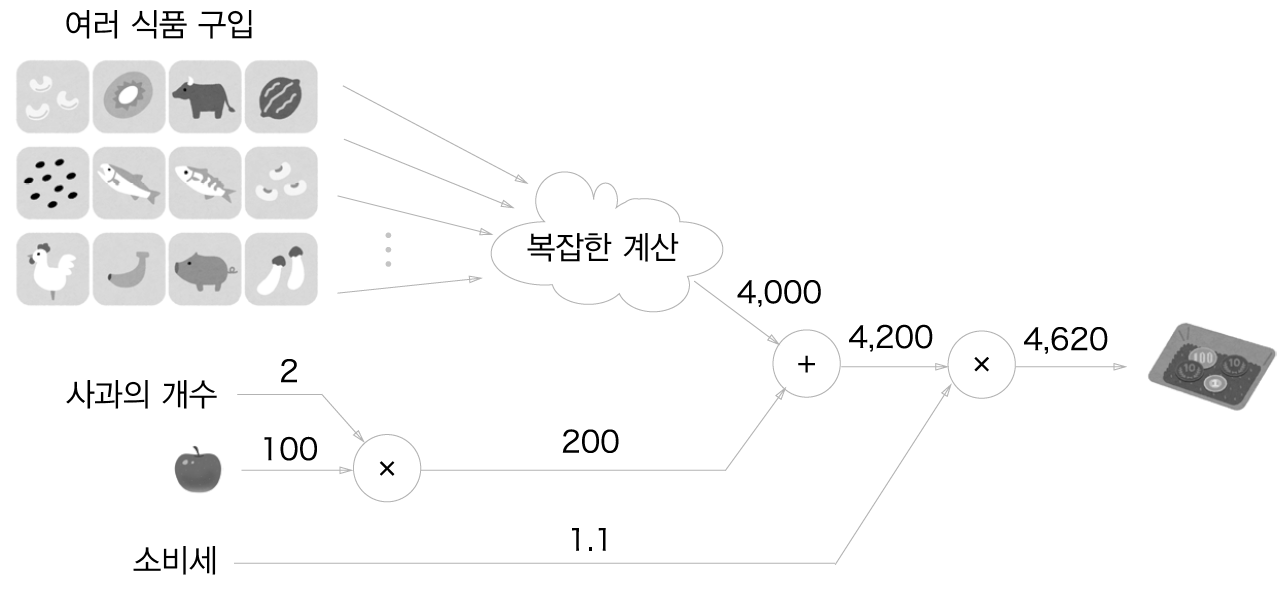
각 노드에서의 계산은 국소적 계산이다. (각 노드는 자신과 관련한 계산 외에는 아무것도 신경쓰지 않는다.)
국소적인 계산은 단순하지만, 각각 그 결과를 전달함으로써 전체적으로 복잡한 계산을 해낼 수 있다.
왜 계산그래프를 사용하나?
A: 역전파를 통해 '미분'을 효율적으로 계산할 수 있다.
위의 문제1에서 사과 가격이 오르면 최종 금액에 어떤 영향을 끼치는지 알고 싶다는 것은 "사과 가격에 대한 지불 금액의 미분"을 구하는 것과 같다. 이는 역전파를 통해 구할 수 있다.
이는 사과 값이 아주 조금 오르면 최종 금액은 그 아주 작은 값의 2.2배만큼 오른다라는 뜻이다.
이처럼 계산 그래프의 이점은 순전파와 역전파를 활용해 각 변수의 미분을 효율적으로 구할 수 있다는 것이다.

연쇄법칙
- 연쇄법칙: 국소적 미분을 전달하는 원리
1) 계산 그래프의 역전파
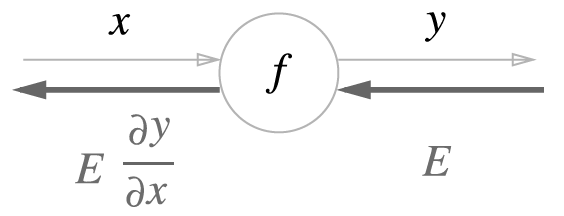
역전파의 계산 절차는 신호 에 노드의 국소적 미분 을 곱한 후 다음 노드로 전달 하는 것이다.
ex> 에서 는 가 된다.
2) 연쇄법칙이란
연쇄법칙은 함성 함수의 미분에 대한 성질이며, 다음과 같이 정의된다.
합성 함수의 미분은 함성 함수를 구성하는 각 함수의 미분의 곱으로 나타낼 수 있다.
1) 우선 는 와 의 곱으로 나타낼 수 있다.
2) 는 이고 는 1이다.(편미분)
따라서 이 둘의 곱은 이고 는 이므로 그 결과는 이다.
3) 연쇄법칙과 계산그래프
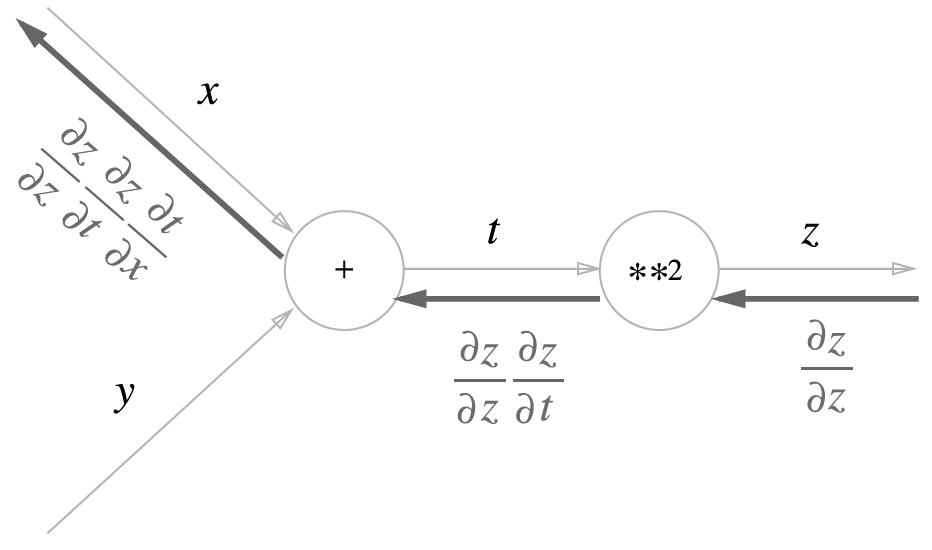
노드로 들어온 입력 신호에 그 노드의 국소적 미분(편미분)을 곱한 후 다음 노드로 전달한다.
ex> 입력에 국소적 미분인 를 곱하고 다음 노드로 넘긴다.
역전파
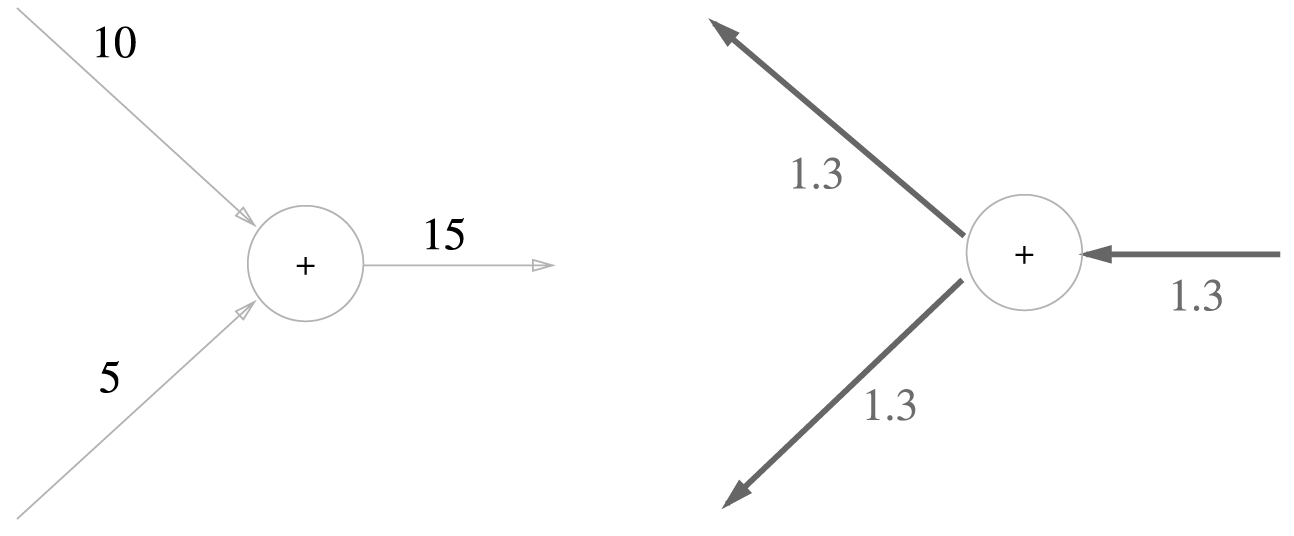
1) 덧셈 노드의 역전파
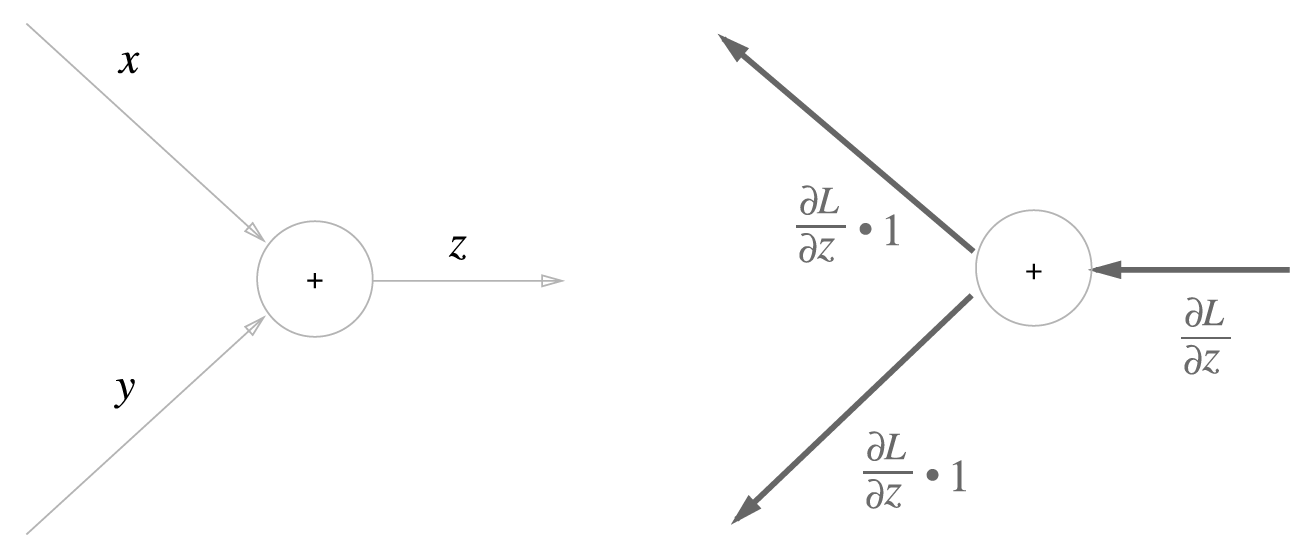
다음과 같이 라는 식에서 과 는 모두 1이다.
따라서 역전파 때는 에 1을 곱하여 흘린다.
즉 덧셈은 입력된 값을 그대로 다음 노드로 보낸다.
2) 곱셈노드의 역전파
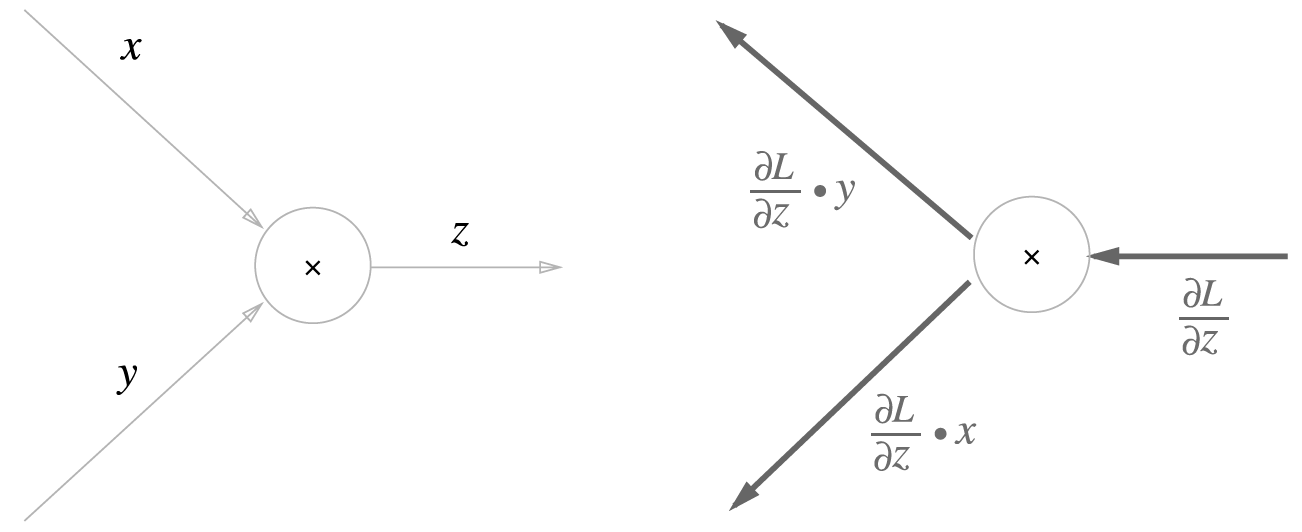
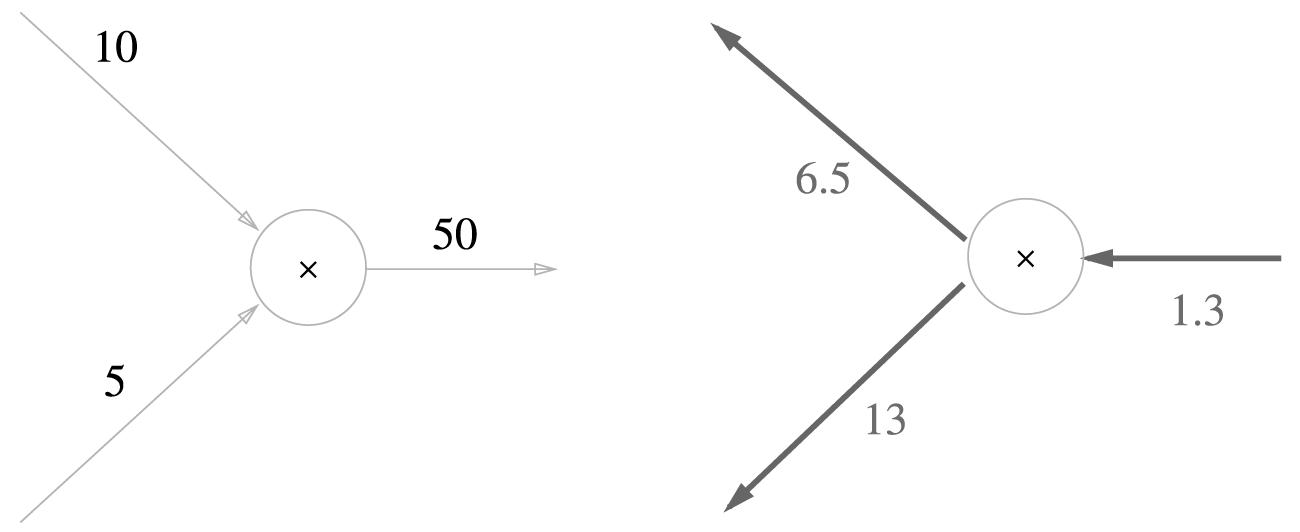
다음과 같이 라는 식에서 는 이고 는 이다.
따라서 곱셈은 역전파 때 에 입력 신호들을 "서로 바꾼값"을 곱하여 흘린다.
3) 사과쇼핑의 예
활성화 함수 계층 구현하기
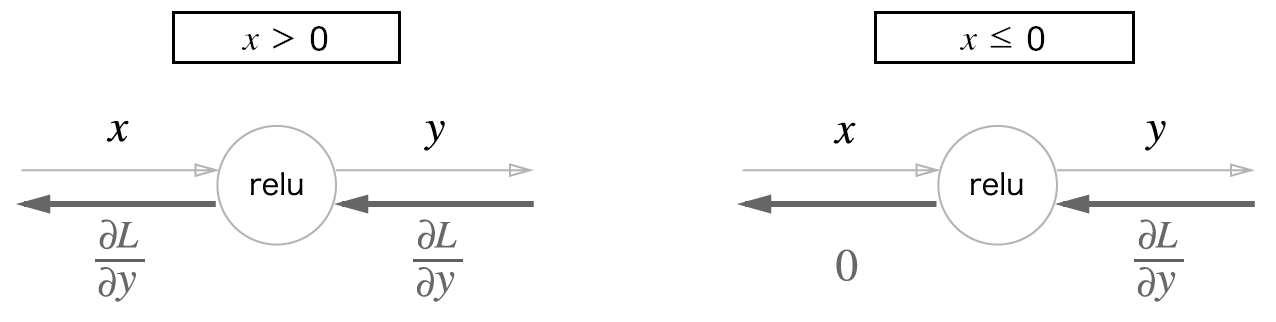
1) ReLU 계층
순전파 때의 입력인 x가 0보다 크면 역전파는 그대로 흘린다.
반면 순전파 때 x가 0이하면 역전파때는 하류로 신호를 보내지 않는다.(0을 보냄)
class Relu:
def __init__(self):
self.mask = None
def forward(self, x):
self.mask = (x <= 0)
out = x.copy()
out[self.mask] = 0
return out
def backward(self, dout):
dout[self.mask] = 0
dx = dout
return dxmask: True/False로 구성된 넘파이 배열
ex> x = np.array([[1.0, -0.5], [-2.0, 3.0]])
print(mask) -> [[False, True], [True, False]]
- 순전파
1) self.mask에 x가 0이하인 값들은 True로 0초과인 값은 False로 초기화 한다.(x와 똑같은 구조, 값은 True False)
2) out은 x와 똑같은 넘파이 배열이지만 True인값들(0이하인값들)은 모두 0으로 바꾼다.(Relu함수 특성)
3) out을 반환
- 역전파
1) 순전파 때 만들어 놓은 mask를 써서 mask의 원소가 True인 곳에는 dout을 0으로 설정함
2) dx에 dout을 넣고 dx를 반환
2) Sigmoid 계층
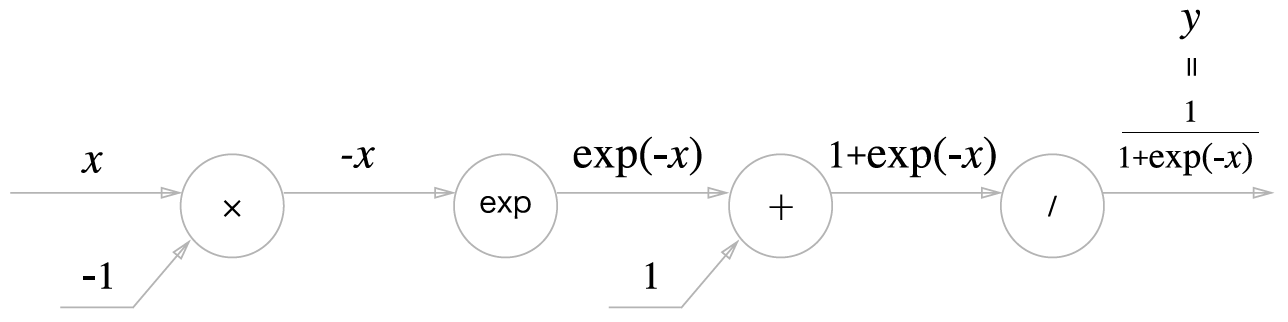
'exp'와 '/'노드가 새롭게 등장하였다.
1) Sigmoid 역전파 1단계
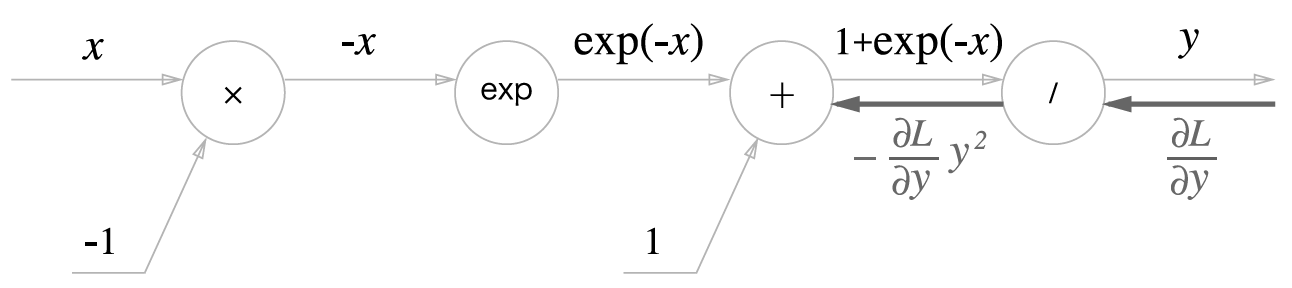
'/'노드, 즉 을 미분하면 위와같다.
즉 순전파에서 흘러온 값(y)을 제곱하고 마이너스를 붙인값을 역전파로 전달한다.
2) 2단계('+' 노드)
'+ '노드이기에 그대로 역전파로 전달한다.
3) 3단계(exp노드)
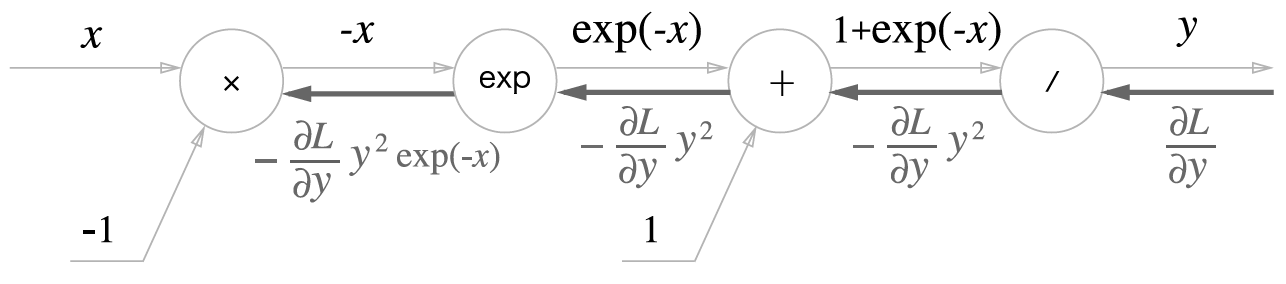
의 미분은 그대로이다.
따라서 이 경우에 를 그대로 역전파한다.
4) 4단계('x'노드)
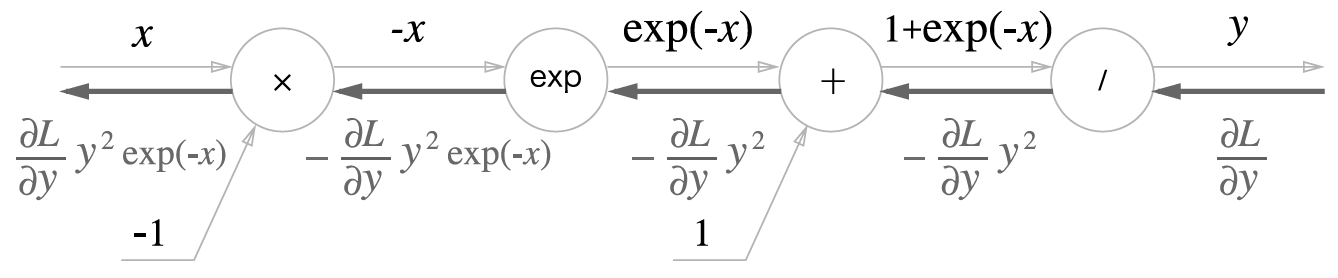
'x' 노드이기에 순전파 때의 값을 '서로바꿔' 곱한다.
최종출력
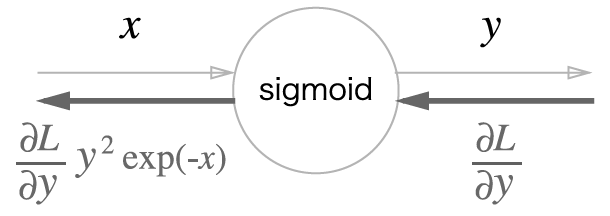
결론적으로 순전파의 입력 와 출력 만으로 최종출력인 을 계산할 수 있다.
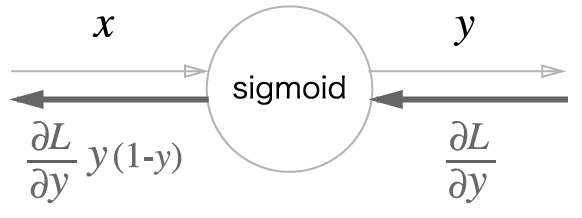
추가로 이를 더 간소화 할 수 있는데 이렇게 하면 가 된다.
class Sigmoid:
def __init__(self):
self.out = None
def forward(self, x):
out = 1 / (1+np.exp(-x))
self.out = out
return out
def backward(self, dout):
dx = dout * (1.0 - self.out) * self.out
return dxAffine/Softmax 계층 구현하기
1) Affine 계층
- 어파인 변환(Affine Transformation): 신경망의 순전파 때 수행하는 행렬의 곱을 기하학에서는 어파인 변환이라 한다.
- 어파인 계층: 어파인 변환을 수행하는 처리
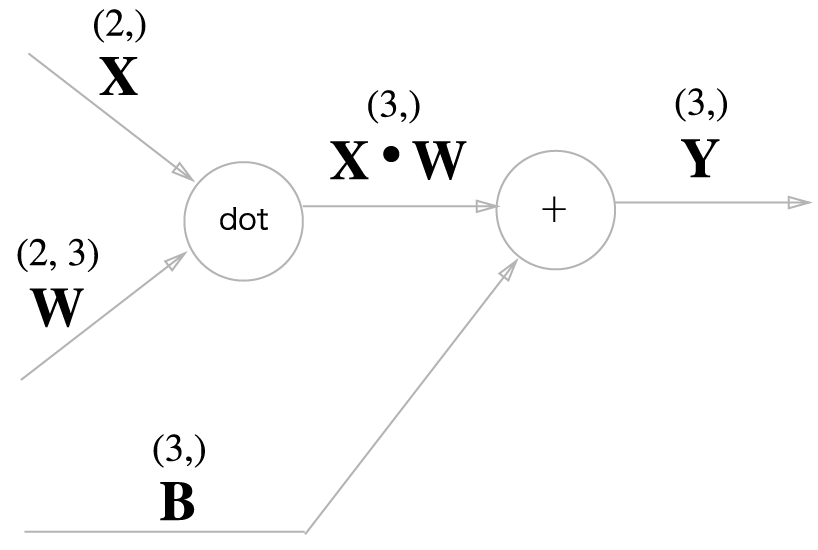
지금까지의 계산그래프는 노드 사이에 스칼라 값이 흘렀지만 이제 "행렬"이 흐른다.
행렬을 사용한 역전파도 핼려의 우너소마다 전개해보면 스칼라값을 사용한 지금까지의 계산그래프와 같은 순서로 생각할 수 있다.
는 의 전치행렬을 뜻한다.
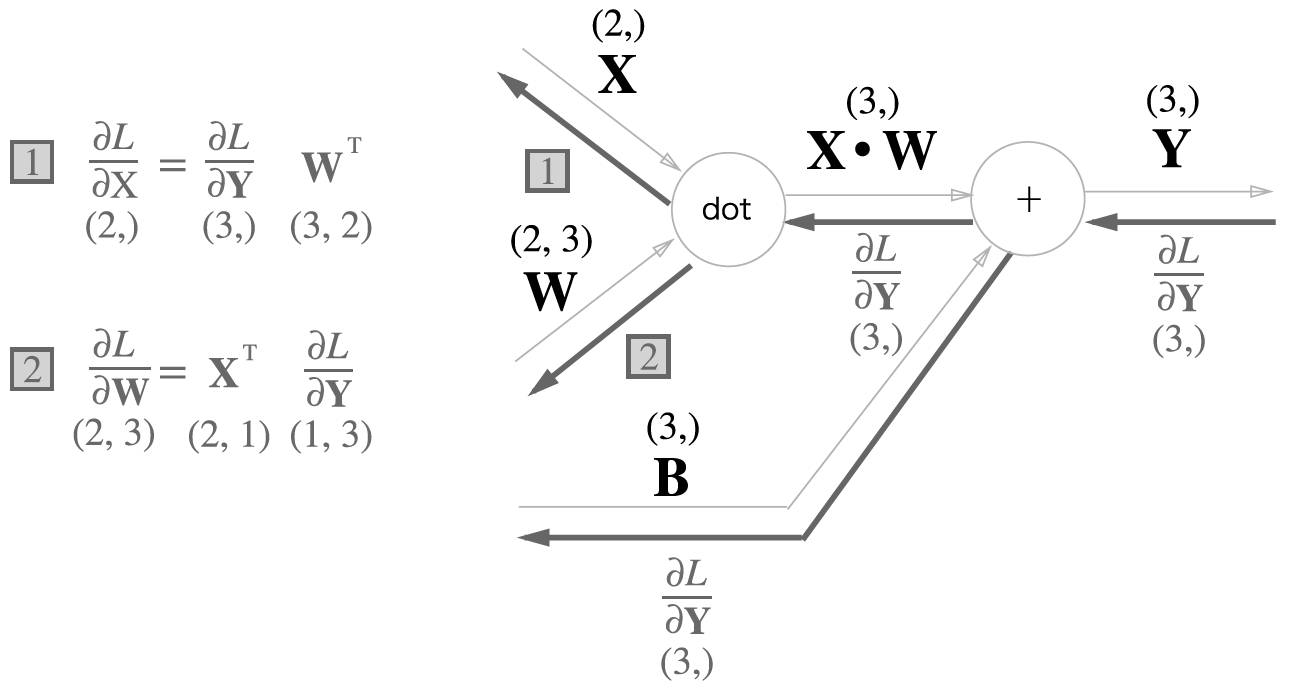
순전파때의 값을 바꾼 전치행렬을 dot연산하면 딱 맞는다.
와 의 형상이 같다. 와 도 형상이 같다.
2) 배치용 Affine 계층
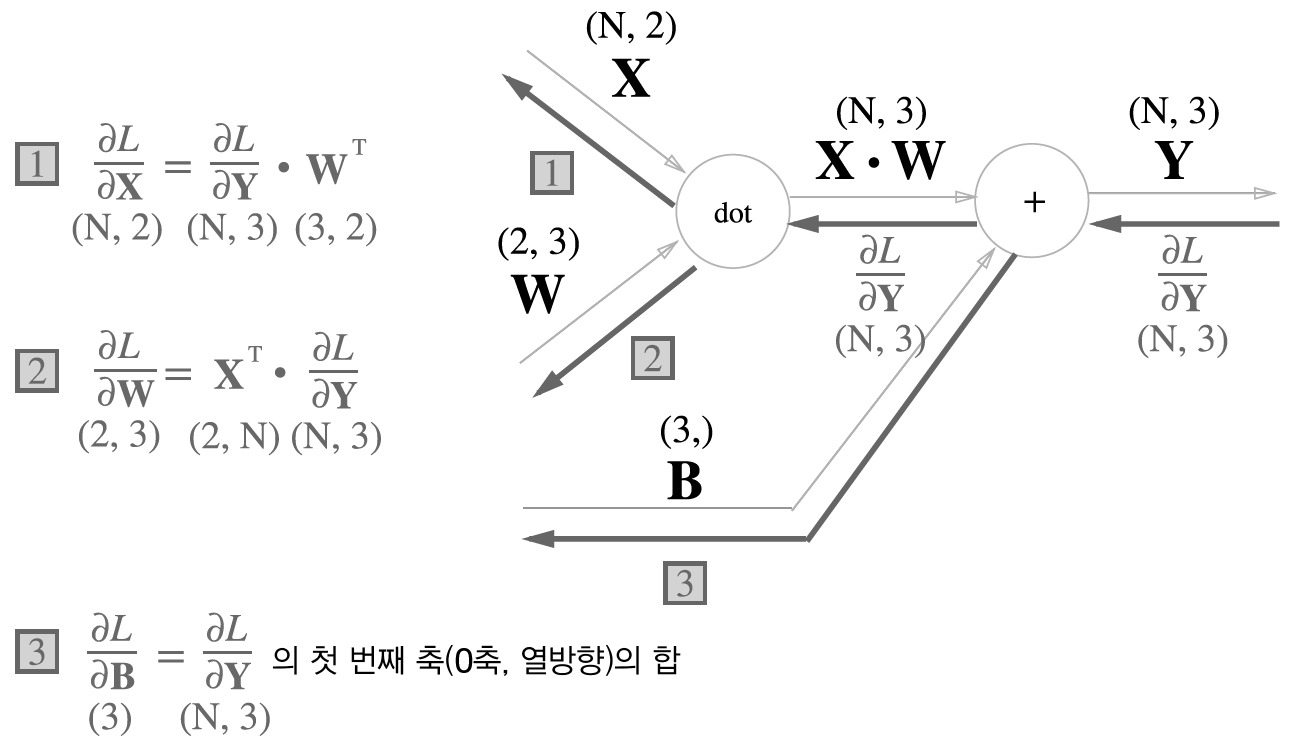
단순히 X 1개가 아니라 이제 형상이 (N, 2)가 되었을 뿐이다.
주의해야할점은 바로 편향(B)를 더할때의 역전파이다.
행렬에서의 덧셈은(2,3) + (3,) 이렇게 이루어진다.
따라서 역전파의 형상이 (3, )이 되어야한다.
즉 편향의 역전파는 그 두 데이터에 대한 미분을 데이터마다 더해서 구한다. 그래서 같은 열의 값을 더해서 총합을 구한다.
이를 코드로 나타내면dY = np.array([[1,2,3], [4,5,6]]) dB = np.sum(dY, axis=0)
class Affine:
def __init__(self, W, b):
self.W = W
self.b = b
self.x = None
self.dW = None
self.db = None
def forward(self, x):
self.x = x
out = np.dot(x, self.W) + self.b
return out
def backward(self, dout):
dx = np.dot(dout, self.W.T)
self.dW = np.dot(self.x.T, dout)
self.db = np.sum(dout, axis=0)
return dx 3) Softmax-with-Loss 계층
Softmax 계층은 입력값을 정규화(출력의 합이 1이 되도록 변형)하여 출력한다.
- 추론할때는 Softmax계층이 필요없다.(어차피 가장 높은 점수만 알면됨) 그러나 학습할 때는 Softmax 계층이 필요하다.
실제 구현시 손실함수(교차 엔트로피 오차)도 포함하여 Softmax-with-Loss 계층을 구현한다.
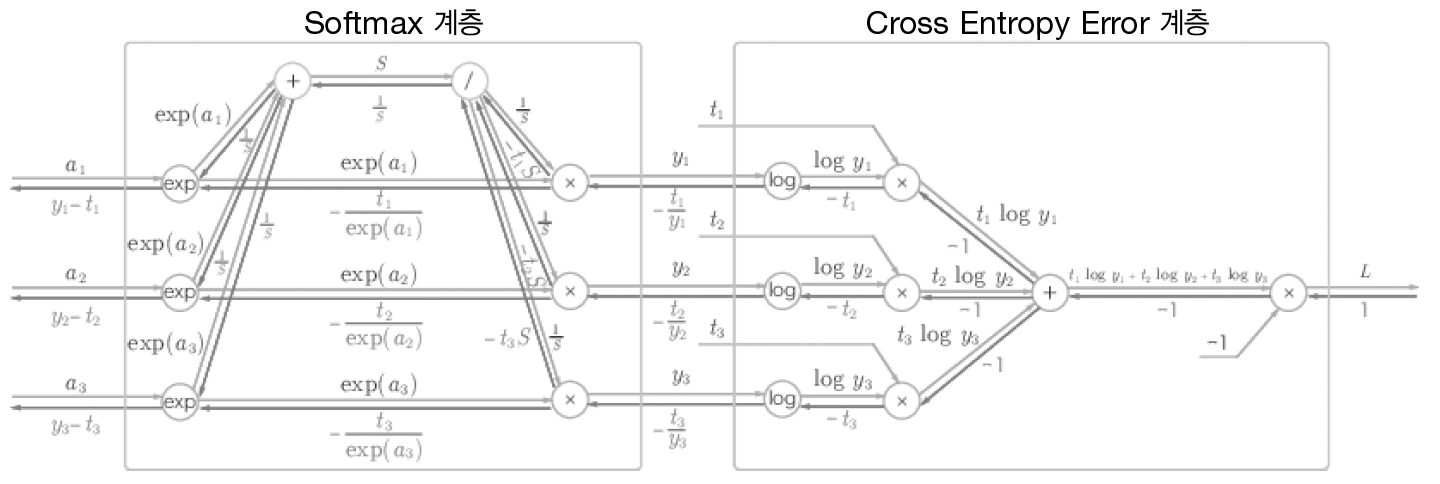
이를 밑처럼 간소화 시킬 수 있다.
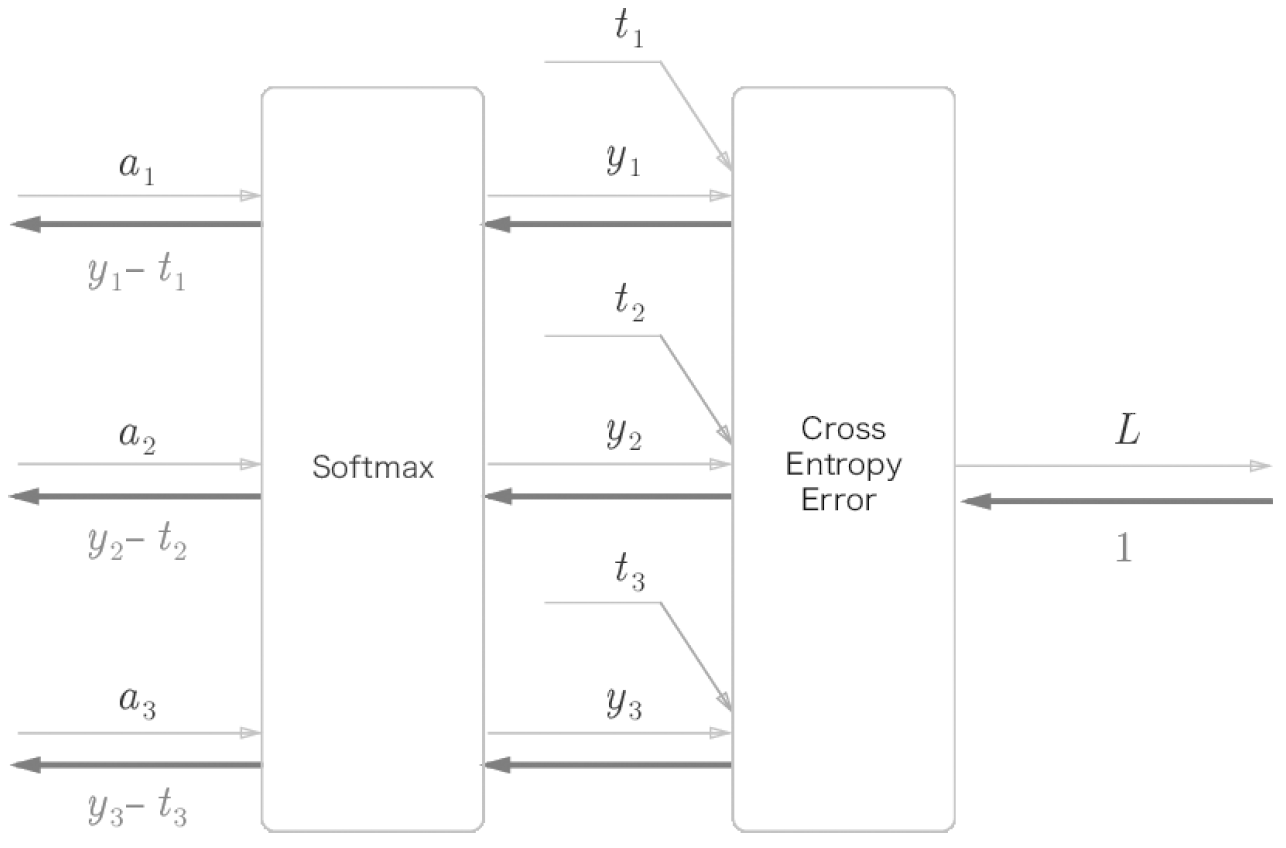
Softmax의 출력과 정답레이블의 차분을 역전파 한다.
예를들어 정답레이블이 (0, 1, 0)일떄 Softmax 계층이 (0.3, 0.2, 0.5)를 출력했다고 가정한다. 현재 출력에서는 정답의 확률이 0.2밖에 안되어 신경망은 제대로 인식을 못하고 있다. 이 경우 역전파는(0.3, -0.8, 0.5)라는 커다란 오차를 전파한다.
즉 큰 오차로부터 깨달음을 얻게 하는 것이다.
class SoftmaxWithLoss:
def __init__(self):
self.loss = None
self.y = None
self.t = None
def forward(self, x, t):
self.t = t
self.y = softmax(x)
self.loss = cross_entropy_error(self.y, self.t)
return self.loss
def backward(self, dout=1):
batch_size = self.t.shape[0]
dx = (self.y - self.t) / batch_size
return dx실제 구현에서는 역전파 때 전파하는 값을 배치의 수(batch_size)로 나눠서 데이터 1개당 오차를 앞계층으로 전파한다.
y = softmax(x) = [[0.2, 0.3, 0.1, 0.4], [0.1, 0.4, 0.2, 0.3], [0.3, 0.3, 0.3, 0.1]] t = [[0, 1, 0, 0], [0, 0, 1, 0], [1, 0, 0, 0]] y - t = [[ 0.2, -0.7, 0.1, 0.4], [ 0.1, 0.4, -0.8, 0.3], [-0.7, 0.3, 0.3, 0.1]]이 기울기는 각 데이터 포인트에 대한 오류를 나타내며, 각 데이터 포인트에 대해 손실이 어떻게 변화하는지를 보여준다. 그러나 이 기울기를 그대로 사용하면 미니배치의 크기가 큰 경우 파라미터 업데이트가 너무 강하게 이루어질 수 있다. 따라서, 이 기울기를 미니배치의 데이터 포인트 수(여기서는 3)로 나누어 평균 기울기를 계산한다.
dx = (y - t) / batch_size = [[ 0.2/3, -0.7/3, 0.1/3, 0.4/3], [ 0.1/3, 0.4/3, -0.8/3, 0.3/3], [-0.7/3, 0.3/3, 0.3/3, 0.1/3]]이렇게 계산된 dx는 각 파라미터 업데이트가 미니배치의 크기에 의존적이지 않도록 조정해줌으로써, 다양한 크기의 미니배치를 사용할 때 모델의 학습률을 안정적으로 유지할 수 있게 해준다.
오차역전파법 구현하기
기존의 기울기를 산출하는 목적은 똑같지만 방식을 바꾸는 것이다.
이전의 "수치미분"방식에서 "오차역전파법"으로 바꾸면 된다.
1) 신경망 구현
from collections import OrderedDict
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):
# 가중치 초기화
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
# 1) 계층 생성
self.layers= OrderedDict()
self.layers['Affine'] = Affine(self.params['W1'], self.params['b1'])
self.layers['Relu1'] = Relu()
self.layers['Affine2'] = Affine(self.params['W2'], self.params['b2'])
self.lastlayer = SoftmaxWithLoss()
def predict(self, x):
# 2) 순전파
for layer in self.layers.values():
x = layer.forward(x)
return x
# x : 입력 데이터, t : 정답 레이블
def loss(self, x, t):
y = self.predict(x)
return self.lastlayer.forward(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
if t.ndim != 1 : t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
# x : 입력 데이터, t : 정답 레이블
def numerical_gradient(self, x, t):
loss_W = lambda W: self.loss(x, t)
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads
def gradient(self, x, t):
# 순전파
self.loss(x, t)
# 3) 역전파
dout = 1
dout = self.lastLayer.backward(dout)
layers = list(self.lauers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
grads = {}
grads['W1'] = self.layers['Affine1'].dW
grads['b1'] = self.layers['Affine1'].db
grads['W2'] = self.layers['Affine2'].dW
grads['b2'] = self.layers['Affine2'].db
return grads1) 생성자에서 1> Affine1, 2> Relu1, 3> Affine2, 4> SoftmaxwithLoss 계층을 만든다.
- 추가로 신경망의 계층들을 OrderDict에 보관한다. OrderDict는 순서가 있는 딕셔너리이다.
2) 즉 추가한 순서를 기억한다는 것으로 순전파 때는 추가한 순서대로 각 계층의 forward() 메소드를 호출하기만 하면 처리가 완료된다.
3) 역전파때는 계층을 반대순서로 호출하면 된다.
