1) 프롬프트 엔지니어링의 핵심
GPT모델 자체에 아무 정보없이 질의하는 것은 아무의미가 없다.
그것보다 관련한 context를 주는것이 매우 중요함(질문한 사람에 맞게 해준다)
- 그 이유는 LLM은 할루시네이션의 성질을 가진다. 어떻게든 답변을 만들어냄...
또한 그 질의 결과를 다시 context에 넣어서 챗봇형식의 대화가 가능한 것이다.
결론: 즉 핵심은 2가지이다.
1) 어떤 컨텍스트를 추가로 프롬프트에 넣어 줄것인가
2) 어떤 프롬프트를 만들것이냐
그렇다면 어떻게 관련 정보를 가져올수 있을까?
2) Vector Search
1) 임베딩
텍스트를 벡터화 시키는것, 이 벡터화 과정에서도 모델이 작용하는데 이 모델역시 LLM으로 되어있음(Bert, GPT등 -> 시초들)
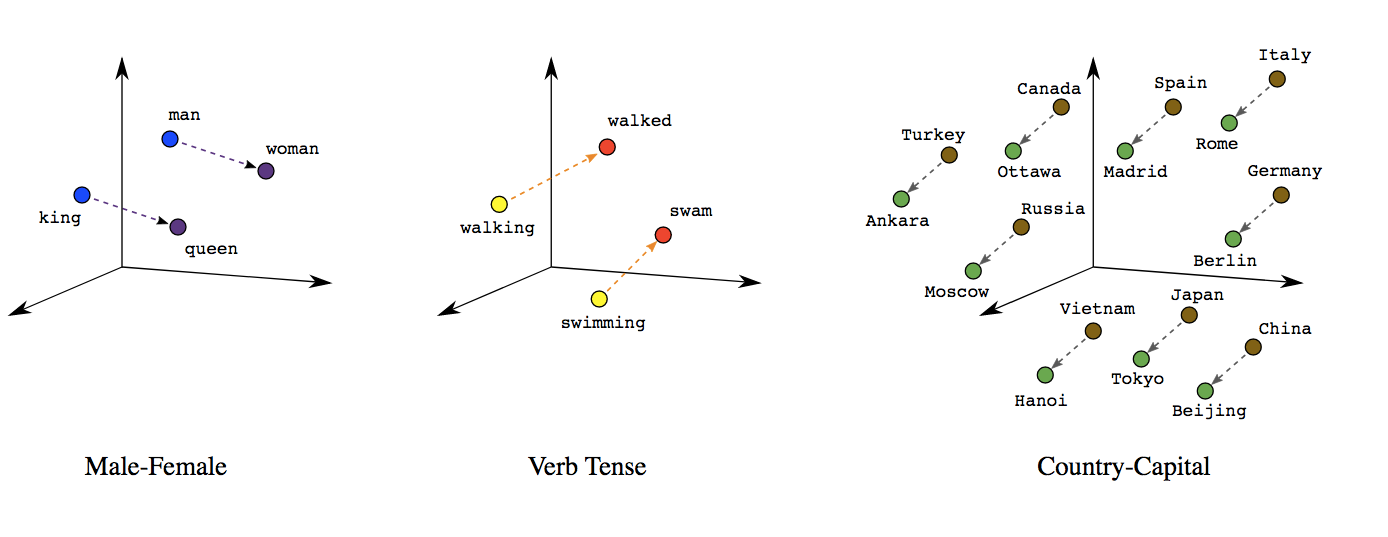
여러 차원에 걸쳐서 이 단어들이 어떤 위치에 있는지를 알려주는 것이다. 만약 유사한 의미를 가진 단어라면 모여있다.
Open AI에서 제공하는 임베딩 모델은 1000차원이 넘는다.
단어임베딩, 문장임베딩 둘다 가능하다.
문장임베딩은 옆에 column으로 계속 붙음
2) 시맨틱서치
과거에도 이 기술이 있었지만 GPT와 같은 LLM모델이 등장하면서 임베딩의 성능이 매우 좋아짐(의미를 잘 찾음)
시맨틱 서치에 벡터 서치가 포함되는 개념인듯...
3) 속도문제
그러나 1000개이상의 단어의 벡터값 간의 거리를 계산하고 비교하는 것은 속도문제가 있다.
근사값을 찾아서 그것들만 비교하는 방법이 있지만 이러면 성능이 떨어진다.
하이브리드 서치를 통해 해결할 수 있다.(후에 설명)
4) 하이브리드 서치
검색정확도를 높이기 위해, 키워드 필터링이나 Dense, Sparse벡터 등을 조합해 검색하는 방식
ex>
1) 전체문서에서 키워드에 맞는 문서 선택
2) 그 문서들에서 벡터서치로 가장가까운 문서찾기
그러나 만약에 너무 많은 문서들이 들어가면 속도나 비용문제 발생할 수 있다. 따라서 쓰는 기술이 바로 Re-rank임
-
Re-rank
1) 키워드 검색이나 다른 경량화된 임베딩 모델을 통한 벡터서치로 문서를 추려옴2) 1차 결과를 LLM에 넣고 재정렬함(가장 유사한거 선택하라고 함)
3) 다시 이거를 LLM에 컨텍스트로 제공
