BEYOND-SW-CAMP-13 2주차
1

12/16(월) DB - 데이터 형식과 내장 함수
수업 내용
- DATA TYPE 정리
- 형변환함수
- 제어함수
- 문자열함수
- 수학함수
- 날짜-시간함수
- 순위-분석함수
얻어 가는 내용
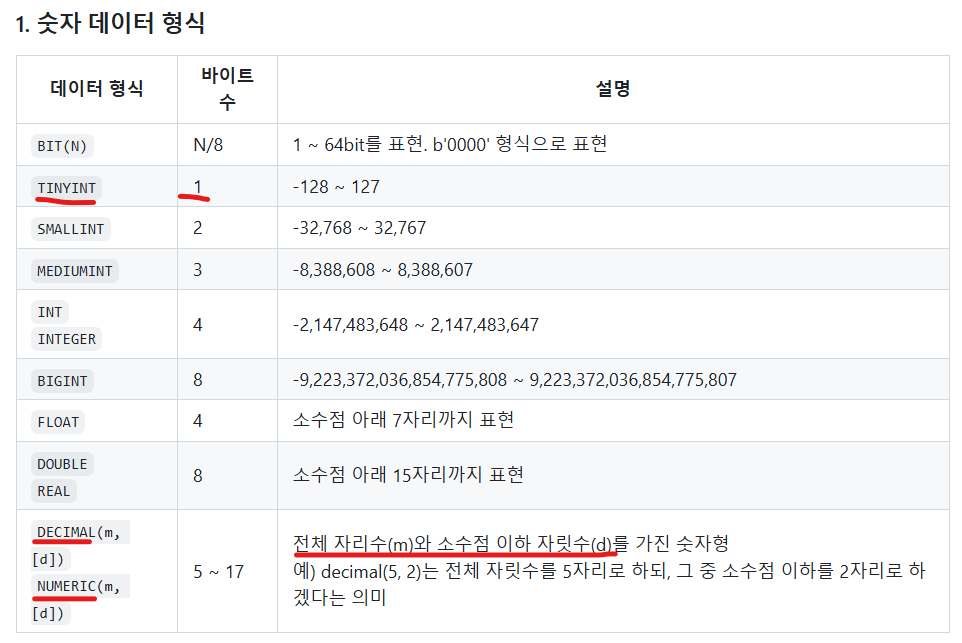
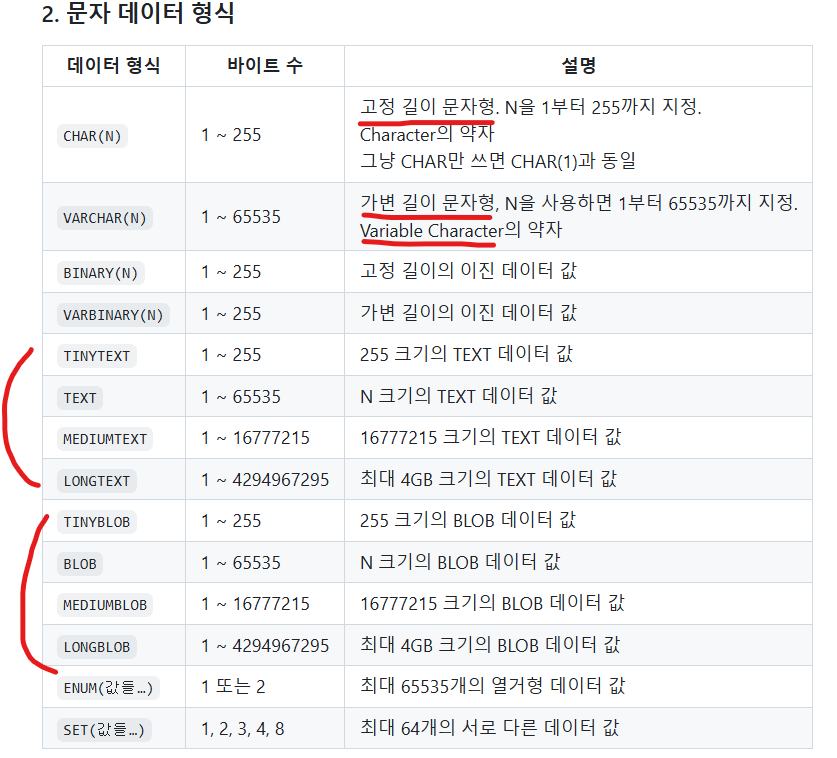
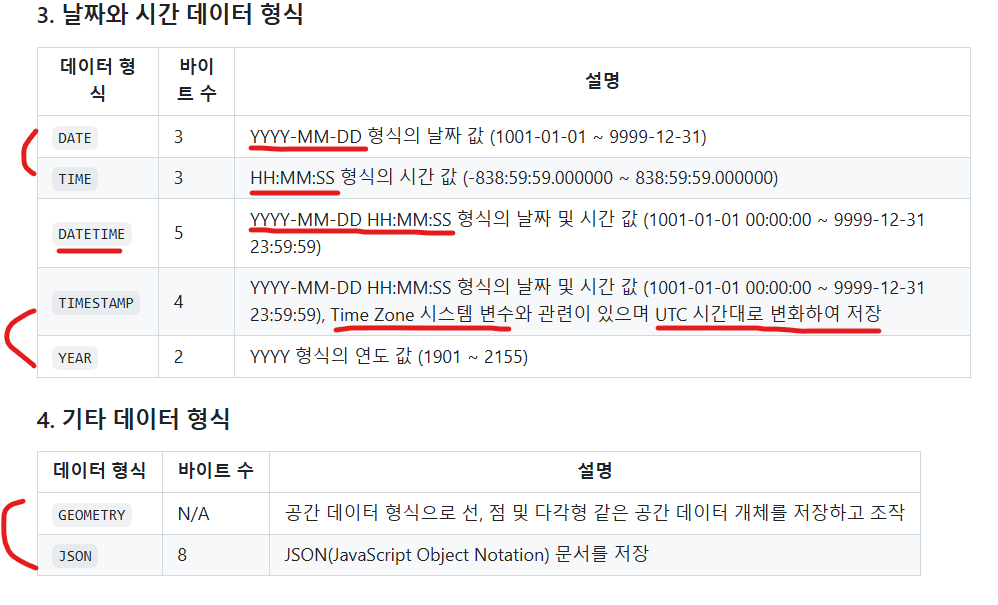
DATA TYPES
형변환함수
> 기본 사용법
SELECT CONVERT(123456789, CHAR);
SELECT CAST(123456789 AS CHAR);
> REPLACE 함수와의 활용
SELECT CONVERT(REPLACE('10,000,000',',',''), INT);
> usertbl 테이블에서 mobile1의 데이터를 숫자 데이터로 형 변환 후 조회
SELECT NAME, convert(mobile1, INT), mobile1
FROM usertbl;
> maria db에서 convert나 cast는 매우 유용하지만 모든 데이터타입 변환이 가능한 것은
아니다.
select CONVERT(2024,smallint);
> LITERAL 연산
SELECT '100' + '200'; -- 정수로 변환되어 연산된다.
SELECT CONCAT('100','200'); -- 문자와 문자를 연결한다.
SELECT CONCAT(100,'200'); -- 정수가 문자로 변환되어 연결된다.
SELECT 1 > '2mega'; -- 산술 연산 -> '2mega' -> 2
SELECT 0 = 'mega'; -- 'mega' 변환 -> 문자로만 구성 -> 0으로 변환;제어-흐름함수

> ifnull과 NVL 함수
SELECT IFNULL(NULL,'값이 없음'), IFNULL(100, '값이 없음');
SELECT nvl(NULL, '값이 없음'), nvl(100,'값이 없음');
> NVL2 함수 -> NVL2('EXP', IF TRUE, IF FALSE);
SELECT nvl2(NULL, 100, 200), nvl2(300,100,200);
> case 연산자
SELECT case 10
when 1 then '일'
when 5 then '오'
when 10 then '십'
ELSE '모름'
END AS '결과';
SELECT case
when 10 > 20 then '10 > 20'
when 10 = 20 then '10 = 20'
ELSE '모름'
END AS '결과';
문자열함수
> concat, concat_ws 함수
SELECT CONCAT('2024', '12', '16'),
CONCAT_ws('/','2024', '12', '16');
> elt, field, find_in_set, instr, locate 함수
SELECT ELT(5,'하나', '둘', '셋', '넷','다섯'); // n번째 문자열을 출력한다.
SELECT FIELD('하나', '하나', '둘', '셋'); // 문자열들에서 해당 문자열의 위치를 출력
SELECT FIND_IN_SET('둘', '하나,둘,셋'); // 문자열에서 문자열의 위치를 출력
SELECT INSTR('하나둘셋', '하나'); // 문자열에서 문자열의 위치를 확인
SELECT LOCATE('구옥', '주악구옥주희'); // 문자열의 위치를 문자열에서 확인
> format 함수
SELECT FORMAT(1234567.89, 1); // 자릿수 표시와 함께 소숫점 반올림까지
> insert,left,right 함수
SELECT INSERT('abcdefghi', 3, 4, '####'); -> ab####ghi
SELECT LEFT('naver', 5); -> naver
SELECT RIGHT('baemin', 6); -> baemin
> lpad, rpad 함수
SELECT LPAD('hello',10); SELECT RPAD('hello',10,'#');
> ltrim, rtrim, trim, substring
SELECT LTRIM(' hello ');
SELECT RTRIM(' hello ');
SELECT TRIM(' hello ');
SELECT SUBSTRING('대한민국만세', 3 ,3);
SELECT SUBSTRING('대한민국만세' FROM 3);
SELECT SUBSTRING('대한민국만세' FROM 3 FOR 2);
SELECT SUBSTRING('대한밈ㄴ국만세' FROM -2 FOR 2);
> SUBSTRING_INDEX 함수
SELECT SUBSTRING_INDEX('cafe.naver.com', '.', 2),
SUBSTRING_INDEX('cafe.naver.com', '.', -2);
수학함수
> ceilng, floor 함수
SELECT CEILING(4.3), FLOOR(4.7), ROUND(4.4), ROUND(4.5), ROUND(4.355, 2);
SELECT TRUNCATE(123.456, 2), TRUNCATE(123.45,-1); -> 123.45, 120
날짜 및 시간 함수
SELECT ADDDATE('2025-01-01', INTERVAL 10 DAY), ADDDATE('2025-01-01', INTERVAL 1 MONTH); -> '2025-01-11', '2025-02-01'
SELECT DATEDIFF(CURDATE(), '2024-05-25'),
TIMEDIFF(CURTIME(), '09:00:00');
> dayofweek, monthname, dayofyear, last_day 함수
SELECT DAYOFWEEK(CURDATE()),
MONTHNAME('2024-05-25'),
DAYOFYEAR(CURDATE()),
LAST_DAY(CURDATE());
> makedate, maketime, period_add, period_diff 함수
SELECT MAKEDATE(2025,100),
MAKETIME(22,58,59),
PERIOD_ADD(202402,12),
PERIOD_DIFF(202405,202505),
PERIOD_DIFF('2025-05', '2024-05'); 순위-분석(윈도우)함수
> 순위 관련 함수
> order by height desc key로 내림차순 정렬 한 후에 row_number() 함수로 순번을 매긴다.
SELECT ROW_NUMBER() OVER(ORDER BY height DESC) AS 'num', NAME, addr, height
FROM usertbl
ORDER BY height DESC;
> 지역 별로 순위를 매겨서 주소, 순위, 이름, 키를 조회
SELECT addr, ROW_NUMBER() OVER(partition by addr order by height DESC) AS 'num', NAME, height
FROM usertbl;
> 동순위 발생 시 다음 등 수 생략
SELECT RANK() over(order by height DESC), NAME, height
FROM usertbl;
> 동순위 발생하여도 다음 등 수 이어감
SELECT dense_RANK() over(order by height DESC), NAME, height
FROM usertbl;
> 전체 인원을 키 순서로 세운 후에 4개의 그룹으로 분할
SELECT NTILE(4) OVER(ORDER BY height DESC) 'num', NAME, height
FROM usertbl;
> 분석 윈도우 함수
> usertbl 테이블에서 키 순서대로 정렬 후 다음 사람과 키 차이를 조회
SELECT NAME, addr, height,
height - LEAD(height, 1) OVER(ORDER BY height DESC) AS 'lead'
FROM usertbl
ORDER BY height DESC;
> usertbl 테이블에서 키 순서를 정렬 후 이전 사람과 키 차이를 조회
SELECT NAME, addr, height,LAG(height,1) OVER(ORDER BY height DESC) - height AS '키차이'
FROM usertbl;
> usertbl 지역별로 가장 키 큰 사람과 차이를 조회
SELECT addr, NAME, height, FIRST_VALUE(height) OVER(partition by addr ORDER BY height DESC) - height
FROM usertbl;
느낀 점
DB 공부하면서 제일 힘들었던 파트
12/17(화) DB - 조인
수업 내용
- INNER JOIN
- OUTER-JOIN
- CROSS-JOIN/SELF-JOIN
- UNION-ALL
얻어 가는 내용
INNER JOIN
> 특정 조건을 만족하는 행들 끼리 하나의 행을 만든다.
> 23개의 employees -> 21개의 join (employee에서 dept_code 가 null인 행)
SELECT * FROM employee e INNER JOIN department d ON e.dept_code = d.dept_id;
> NATURAL JOIN: 동일한 이름의 열이 더 있을 때 -> join 조건이 이상해지고 원하지 않는 결과가 나올 수 있다.
SELECT emp_id, emp_name, job_code, job_name
FROM employee
NATURAL JOIN job;
> INNER JOIN에 WHERE 절 사용
SELECT emp_no, emp_name, bonus, d.dept_title
FROM employee e
INNER JOIN department d ON e.dept_code = d.dept_id
WHERE bonus IS not NULL;OUTER JOIN
> outer join 실습
> 1) left outer join (왼쪽의 테이블은 모두 포함)
SELECT * FROM employee e
LEFT /*OUTER*/ JOIN department d ON e.dept_code = d.dept_id
ORDER BY e.dept_code;
> 2) right outer join (부서에 속해있는 사원이 없어도 부서에 대한 정보가 출력된다.)
SELECT e.emp_name, d.dept_id, d.dept_title, e.salary FROM employee e
right /*OUTER*/ JOIN department d ON e.dept_code = d.dept_id
ORDER BY e.dept_code;
CROSS/SELF JOIN
> cross join 23rows * 9rows -> 207rows
SELECT * FROM employee
CROSS JOIN department;
> self join -> inner join을 자기 자신( 하나의 테이블)로 진행
SELECT e.emp_id, e.emp_name, e.dept_code, m.emp_id '사수id', m.emp_name '사수 이름'
FROM employee e
> none equal join (비등가 조인)
> sal_grade에서 조건에 맞는 행이 mapping 된다.
SELECT employee.emp_id AS 'id', employee.emp_name AS 'name', sal_grade.sal_level AS 'salary_level'
FROM employee
INNER JOIN sal_grade ON employee.salary BETWEEN sal_grade.min_sal AND sal_grade.max_sal;
실습문제와 UNION
> 실습문제
-- 테이블을 다중 JOIN 하여 사번, 직원명, 부서명, 지역명, 국가명 조회
SELECT e.emp_id,
e.emp_name,
d.dept_title,
l.local_name,
n.national_name
FROM employee e
LEFT OUTER JOIN department d ON e.dept_code = d.dept_id
LEFT OUTER JOIN location l ON d.location_id = l.local_code
LEFT OUTER JOIN national n ON l.national_code = n.national_code;
-- 한국과 일본에서 근무하는 직원들의 직원명, 부서명, 지역명, 근무 국가를 조회하세요.
SELECT e.emp_name,
d.dept_title,
l.local_name,
n.national_name
FROM employee e
INNER JOIN department d ON e.dept_code = d.dept_id
INNER JOIN location l ON d.location_id = l.local_code
INNER JOIN national n ON l.national_code = n.national_code
WHERE n.national_name IN ('한국', '일본');
-- 1) UNION 연산자
SELECT emp_id,
emp_name,
dept_code,
salary
FROM employee
WHERE dept_code = 'D5'
UNION
SELECT emp_id,
emp_name,
dept_code,
salary
FROM employee
WHERE salary > 3000000;
-- 위 쿼리문 대신에 WHERE 절에 OR 연산자를 사용해서 처리가 가능하다.
SELECT emp_id,
emp_name,
dept_code,
salary
FROM employee
WHERE dept_code = 'D5' OR salary > 3000000;
-- 2) UNION ALL 연산자
SELECT emp_id,
emp_name,
dept_code,
salary
FROM employee
WHERE dept_code = 'D5'
UNION ALL
SELECT emp_id,
emp_name,
dept_code,
salary
FROM employee
WHERE salary > 3000000;느낀 점
DB를 잘하자.
12/18(수) DB - 서브쿼리
수업 내용
- SUB QUERY
- 단일행 서브쿼리
- 다중행 서브쿼리
- 다중열 서브쿼리
- 다중행 다중열 서브쿼리
- 인라인 뷰
얻어 가는 내용
SUBQUERY
> 서브 쿼리 실습
-- 하나의 sql 문 안에 또 다른 sql 문을 서브 쿼리라 한다.
-- 서브 쿼리 예시
-- 노웅철 사원과 같은 부서원들을 조회
-- 1) 노웅철 사원의 부서 코드를 조회
SELECT emp_name, dept_code
FROM employee
WHERE emp_name = '노옹철';
-- 2) 부서코드가 노옹철 사원의 부서 코드와 동일한 사원들을 조회
SELECT emp_name, dept_code
FROM employee
WHERE dept_code = 'D9';
SELECT emp_name, dept_code
FROM employee
WHERE dept_code = (
SELECT dept_code
FROM employee
WHERE emp_name = '노옹철');
단일행 서브쿼리
-- 1) 단일행 서브 쿼리 서브쿼리 조회 결과 값의 개수가 1일 떄
-- 전 직원의 평균 급여 보다 더 많은 급여를 받고 있는 직원들의 사번, 직원명, 직급 코드, 급여를 조회
SELECT AVG(salary)
FROM employee;
SELECT emp_id, emp_name, job_code, salary
FROM employee
WHERE salary >= (SELECT AVG(salary) FROM employee);
다중행 서브쿼리
-- 2) 다중행 서브 쿼리 서브 쿼리 조회 결과 값의 개수가 여러 행 일 떄
-- 각 부서별 최고 급여를 받는 직원의 이름, 직급 코드, 부서 코드, 급여 조회
-- 부서별 최고 급여 조회
SELECT max(salary), dept_code FROM employee
GROUP BY dept_code;
SELECT emp_name, job_code, dept_code, salary
FROM employee
WHERE salary IN (SELECT MAX(salary) FROM employee GROUP BY dept_code)
ORDER BY salary desc;
-- 직원들의 사번, 직원명, 부서 코드, 구분(사원/사수) 조회
SELECT DISTINCT manager_id
FROM employee
WHERE manager_id IS NOT NULL;
SELECT emp_id, emp_name, dept_code
, case
when emp_id IN (SELECT DISTINCT manager_id
FROM employee
WHERE manager_id IS NOT NULL) then '사수'
ELSE '사원'
END AS 구분
FROM employee;
-- 대리 직급에도 과장 직급들의 최소 급여보다 많이 받는
-- 직원의 사번, 이름, 직급 코드, 급여 조회
SELECT salary
FROM employee
WHERE job_code = 'J5';
SELECT min(salary)
FROM employee e
INNER JOIN job j ON e.job_code = j.job_code
WHERE j.job_name = '과장';
-- any는 서브 쿼리의 결과 값의 목록 중 하나라도 조건을 만족하면 참이 된다. (ALL은 모든 조건이 만족되어야 한다)
SELECT emp_id, emp_name, job_code, salary
FROM employee
WHERE job_code = 'J6' AND salary > ANY(
SELECT min(salary)
FROM employee e
INNER JOIN job j ON e.job_code = j.job_code
WHERE j.job_name = '과장');다중열 서브쿼리
-- 3) 다중열 서브 쿼리 서브 쿼리 조회 결과 1행에 여러 개의 열의 값일 때
-- 부서 코드가 D5이면서 직급 코드가 j5인 사원들을 조회
SELECT emp_name, dept_code, job_code
FROM employee
WHERE (dept_code, job_code) = (
SELECT dept_code, job_code
FROM employee
WHERE emp_name = '하이유'
);
다중행 다중열 서브쿼리
-- 4) 다중행 다중열 서브 쿼리 서브 쿼리 조회 결과 여러 행 여러 열의 값이 조회 될 때
-- 각 부서별 최고 급여를 받는 직원의 사번, 직원명, 부서 코드, 급여 조회
-- 부서별 최고 급여 조회
SELECT dept_code, MAX(salary)
FROM employee
GROUP BY dept_code;
SELECT emp_no, emp_name, IFNULL(dept_code,'부서없음'), salary
FROM employee
WHERE (IFNULL(dept_code, '부서없음'), salary) IN (
SELECT IFNULL(dept_code, '부서없음'), MAX(salary)
FROM employee
GROUP BY dept_code
)
ORDER BY dept_code desc;
인라인 뷰
-- 인라인 뷰
-- from 절에 서브 쿼리 작성 및 서브 쿼리 수행 결과를 마치 테이블 처럼 사용
SELECT e.*
FROM (
SELECT emp_id AS '사번',
emp_name AS '이름',
salary AS '급여',
salary*12 AS '연봉'
FROM employee
) e;
-- employee 테이블에서 급여로 순위를 매겨서 출력
SELECT e.*
FROM (
SELECT ROW_NUMBER() OVER(ORDER BY salary DESC) AS 'num',
emp_name,
salary
FROM employee
) e
WHERE e.num BETWEEN 6 AND 10;
느낀 점
서브쿼리 까지 남일;ㅣ마ㅓㅇㄻ;ㅏㅣㄴㅇ럼ㅇ;라ㅣㅓ
12/19(목) DB - 모델링
수업 내용
- DB모델링
- 개념적모델링
- 논리적모델링
- 물리적모델링
얻어 가는 내용
DB 모델링
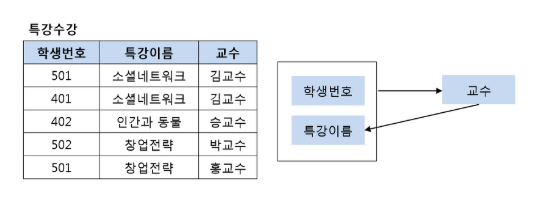
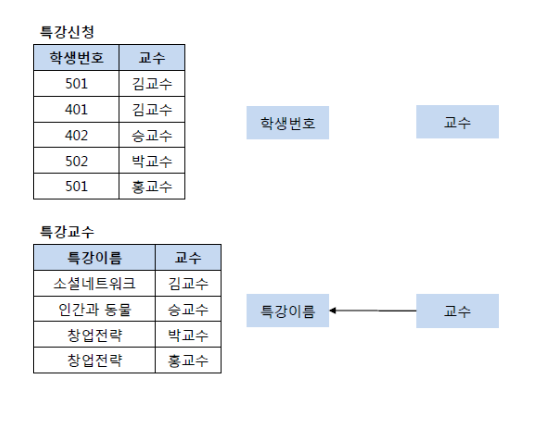
- 개념적 모델링: 개념적 모델링은 ENTITY 간의 관계를 정의하여 ERD를 제작하는 과정을 의미한다.
- 논리적 모델링: ERD를 사용하려는 DBMS 맞게 사상(MAPPING)하여 관계 스키마 모델을 만드는 과정
- 물리적 모델링: 작성된 논리적 모델을 실제 저장장치에 저장하기 위한 물리적 구조를 정의하는 과정
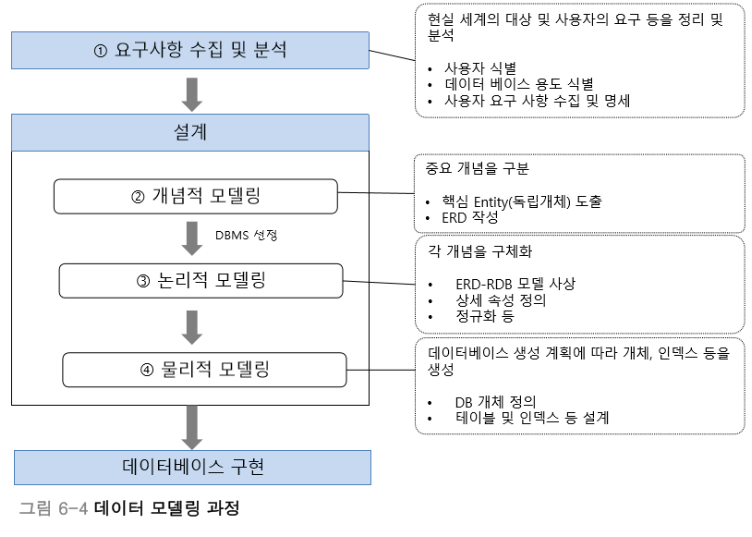
개념적 모델링
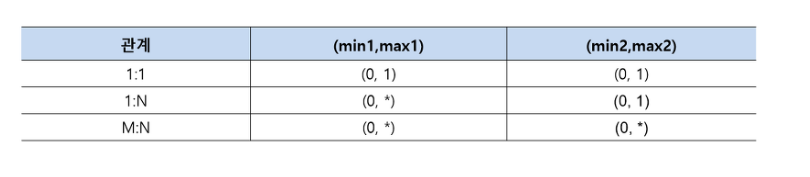
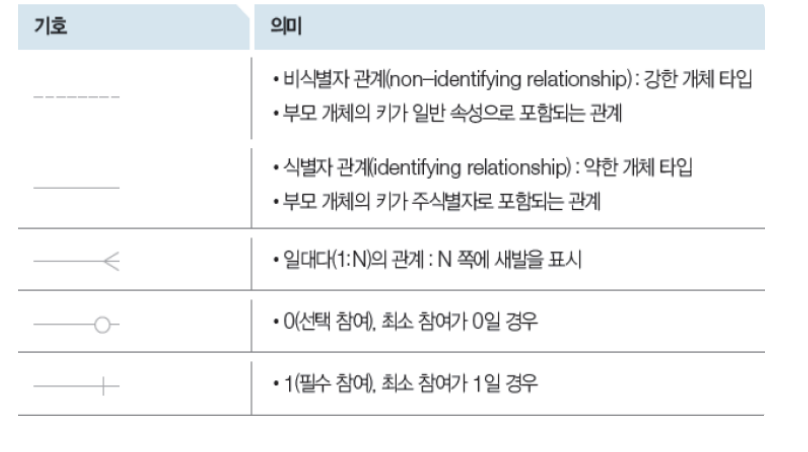
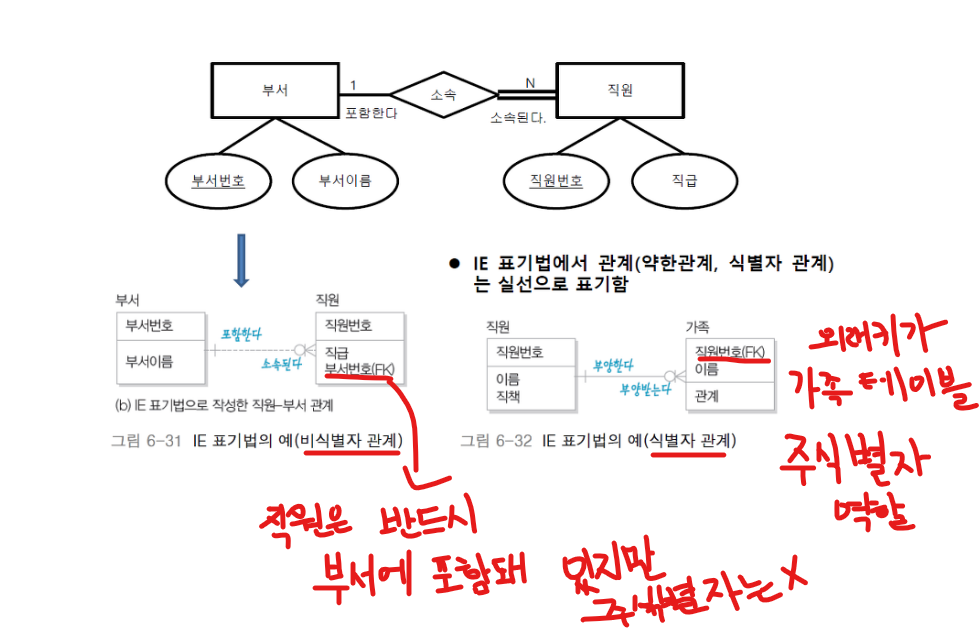
논리적 모델링
Keys
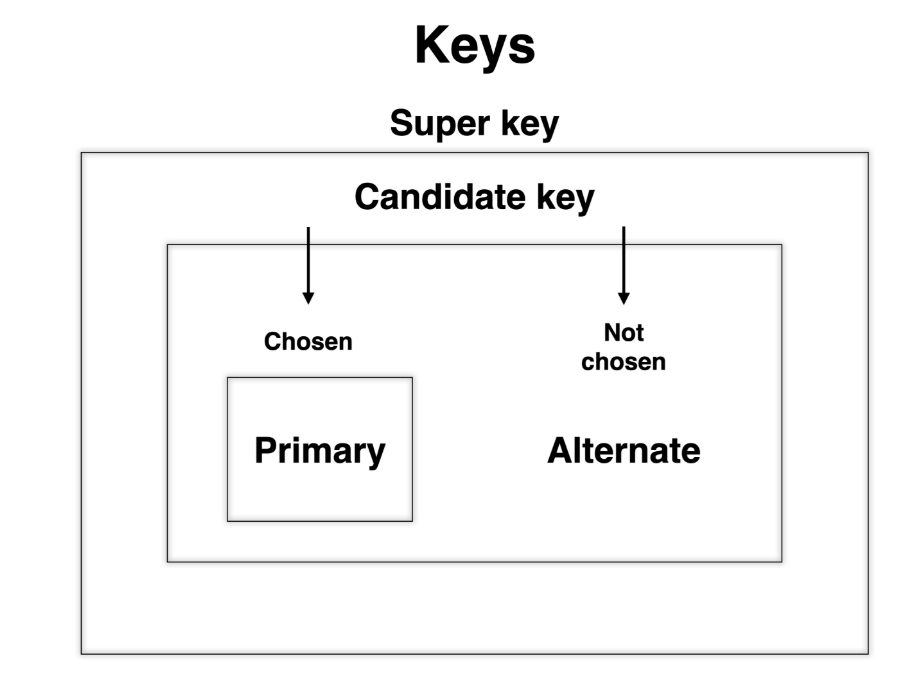
- 슈퍼키 ( 유일성 o, 최소성 X)
- 후보키 ( 유일성 O, 최소성 O)
- 기본키 ( 후보키 중 하나 , 가장 단순한 속성 집합이어야 좋음)
- 복합키 ( 결정자적 컬럼 두 개 이상으로 구성 된 기본키)
- 외래키 ( 속성 참조를 위해 필요한 다른 테이블의 기본키 -> 해당 테이블 데이터 수정 시 무결성을 유지 시켜준다.)
- 대체키 ( 후보키 집합 중 기본키를 제외한 나머지 키)
이상현상(anomaly) : 테이블에서 공유하는 데이터 임에도 각 튜플에 독립적으로 존재하기 때문에 나타나는 현상
- 삽입이상
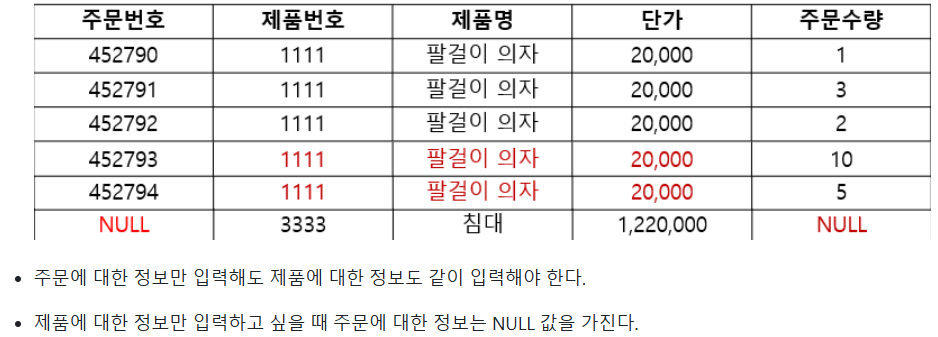
- 삭제이상
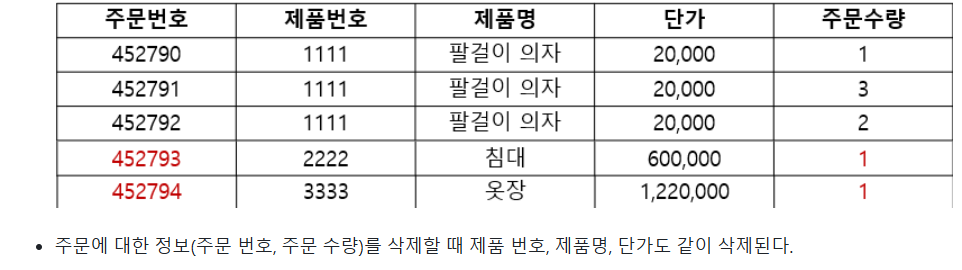
- 수정이상
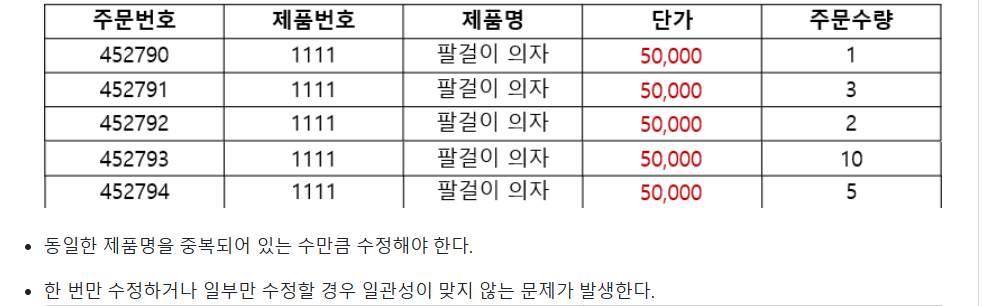
함수 종속성

- 다이어그램
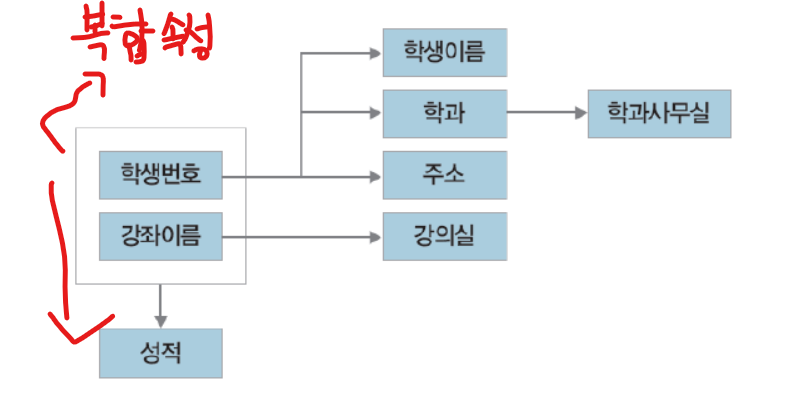
정규화
1. 기본키는 릴레이션의 다른 모든 속성을 결정할 수 있어야 한다.
2. 기본키가 아닌 속성이 결정자일 때, 이상현상이 발생한다.
정규화는 이상현상이 있는 릴레이션을 분해하여 이상현상을 없애는 과정이다.
제1정규형
릴레이션의 모든 속성값을 원자값으로 한다.
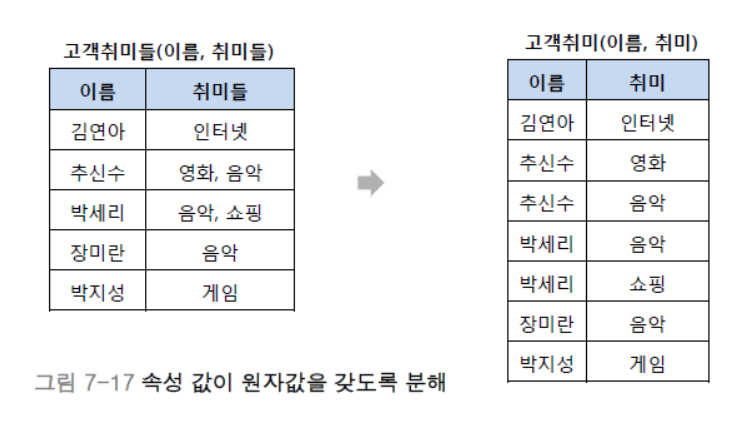
제2정규형
제 1정규형을 만족하고, 릴레이션의 모든 속성이 기본키에 완전 함수 종속이 되게 한다.- 이때 기본키의 부분집합이 결정자 (부분 함수 종속) 가 되어서는 안된다.
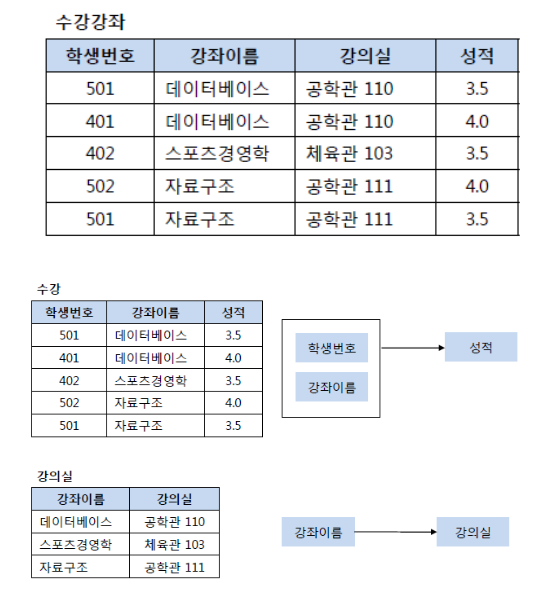
제3정규형
제 2정규형을 만족하고, 릴레이션 내 속성 간 이행적 종속을 제거하고 분해하여 참조하도록 한다.- 기본키가 아닌 속성은 기본키에만 종속하도록 한다.
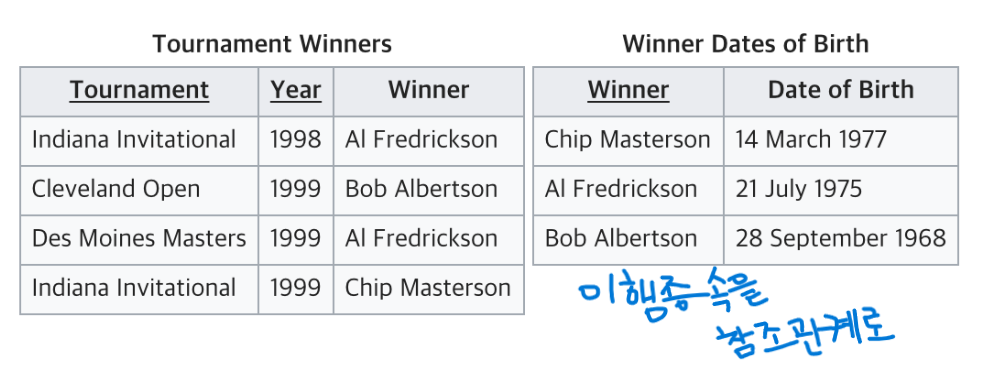
BCNF정규형
제 3정규형을 만족하고, 모든 결정자는 후보키여야 한다.
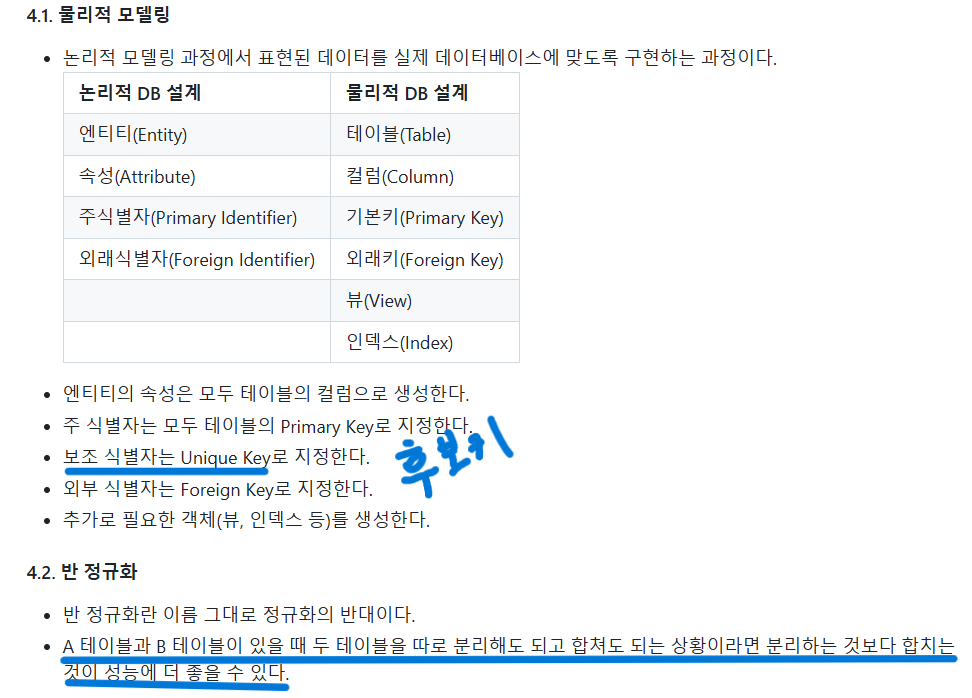
물리적모델링
느낀 점
폼성일
12/20(금) DB - 데이터 변경
수업 내용
- 테이블생성과 제약조건
- 테이블수정/삭제
- 뷰
- 인덱스
얻어 가는 내용
테이블 생성
> DROP TABLE <-> CREATE TABLE
> DEFAULT KEYWORD를 통해 DEFAULT 값을 지정해 줄 수 있다
DROP TABLE `tb_member`;
CREATE TABLE `tb_member` (
`mem_no` INT NOT NULL,
`mem_id` VARCHAR(20) NOT NULL,
`mem_pass` VARCHAR(20) NOT NULL,
`mem_name` VARCHAR(15) NOT NULL,
`enroll_date` DATE DEFAULT CURDATE()
);
제약조건
- NOT NULL : NULL 값을 입력 받지 않는다
- PRIMARY KEY: 유일성 + NOT NULL (UNIQUE + NOT NULL)
- UNIQUE: 유일성 (중복값 입력불가)
- CHECK: 입력 값 범위 또는 조건 지정
- REFERENCES: FOREIGN KEY 제약

컬럼 제약조건

테이블 제약조건 (NOT NULL은 테이블제약조건으로 설정할 수 없다)
- 제약조건에 이름을 설정할 수 있다. (컬럼 제약조건도 내부적으로는 ALIAS 참조 가능)
- CONSTRAINT
CON_NAMEUNIQUE(FIELD_NAME);
> PRIMARY KEY 제약 조건의 경우 여러 개의 열을 묶어서 하나의 기본 키를 생성할 수 있다. 이 때, 한 열의 중복값은 허용된다.
> UNIQUE 제약 조건도 여러 개의 열을 묶어서 하나의 제약 조건으로 생성할 수 있다.
CREATE TABLE `tb_member` (
`mem_no` INT AUTO_INCREMENT, --> INT AUTO_INCREMENT 를 하나의 데이터타입처럼 사용
`mem_id` VARCHAR(20) NOT NULL,
`mem_pass` VARCHAR(20) NOT NULL,
`mem_name` VARCHAR(15) NOT NULL,
`enroll_date` DATE DEFAULT CURDATE(),
/* CONSTRAINT */ PRIMARY KEY(mem_no),
-- PRIMARY KEY(mem_no, mem_id),
CONSTRAINT uq_tb_member_mem_id UNIQUE(mem_id)
-- UNIQUE(mem_id, mem_id)
);
테이블 수정/삭제
> ALTER TABLE : 열 또는 제약조건의 추가, 수정, 삭제, 이름 변경의 작업 진행
> DROP TABLE: TABLE을 삭제
-- usertbl 테이블에 gender 열을 추가 (단, 기본값을 남자로 지정)
ALTER TABLE usertbl ADD gender CHAR(10) DEFAULT 'male' NOT NULL;
-- usertbl 테이블에 age 열을 추가 (단, 기본값은 0으로, birthYear 뒤에 생성, 맨 앞은 first keyword)
ALTER TABLE usertbl ADD age TINYINT DEFAULT 0 AFTER birthyear;
-- usertbl 테이블에서 name 열의 데이터 유형을 CHAR(15)로 변경
ALTER TABLE usertbl MODIFY NAME CHAR(15) NULL;
-- 열의 이름을 변경
ALTER TABLE usertbl RENAME COLUMN `NAME` TO uname;
-- 위 내용을 한 번에 변경
ALTER TABLE usertbl CHANGE COLUMN NAME uname VARCHAR(20) DEFAULT '없음' NOT NULL;
ALTER TABLE usertbl DROP column age;
ALTER TABLE usertbl ADD CONSTRAINT `CONS_NAME` PRIMARY KEY('FIELD_NAME');
ALTER TABLE usertbl ADD CONSTRAINT 'CONS_NAME' FOREIGN KEY('FIELD NAME') REFERENCES 'TABLE_NAME'('FIELD_`NAME`');
ALTER TABLE tb_member ADD CONSTRAINT CHECK(gender = '남자' OR gender = '여자');
ALTER TABLE usertbl DROP CONSTRAINT PRIMARY KEY;
ALTER TABLE usertbl DROP CONSTRAINT `CONS_NAME`;
-- 테이블 삭제
DROP TABLE tb_member;
DROP TABLE tb_member_grade;
DROP TABLE tb_member, tb_member_grade;
-- 테이블 이름 변경
RENAME TABLE salary_grade TO sal_grade;
뷰
- 가상의 테이블, 읽기전용, 뷰 안에서 데이터 수정 가능
- 직접 테이블을 전해주기보다는 필요한 형태로 정보를 가공하고 권한을 제한해서 보여줄 수 있는 장점이 있다.
- 조인 연산이나 서브쿼리 사용 등 복잡한 쿼리 자주 사용해야한다면 해당 쿼리를 매번 작성하기 보다는 뷰를 생성하여 필요할 때마다 간단하게 조회
CREATE VIEW v1
AS SELECT emp_name, phone, d.dept_title FROM employee
LEFT OUTER JOIN department d ON employee.dept_code = d.dept_id;
SELECT * FROM v1;
> SELECT 절에 함수나 산술 연산이 기술되어 있는 경우 별칭을 지정해야 한다.
CREATE OR REPLACE VIEW v_employee
AS SELECT emp_id,
emp_name,
IF(SUBSTRING(emp_no, 8, 1) = '1', '남자', '여자') AS 'gender',
salary
FROM employee;
> 뷰를 이용해서 DML(INSERT, UPDATE, DELETE) 사용
CREATE VIEW v_job
AS SELECT *
FROM job;
SELECT job_code, job_name FROM v_job;
INSERT INTO v_job VALUES ('J8', '알바');
UPDATE v_job
SET job_name = '인턴'
WHERE job_code = 'J8';
DELETE
FROM v_job
WHERE job_code = 'J8';
> 산술 연산이 정의된 뷰의 데이터 수정 작업은 실행 되지 않는다.
CREATE VIEW v_emp_salary
AS SELECT emp_id,
emp_name,
emp_no,
salary * 12 AS 'salary'
FROM employee;
INSERT INTO v_emp_salary
VALUES ('300', '홍길동', '950525-1234567', 30000000);
UPDATE v_emp_salary
SET salary = 30000000
WHERE emp_id = '200';
SELECT * FROM v_emp_salary;
DROP VIEW v1;
인덱스
-
추가적인 쓰기 작업과 저장공간을 활용하여 검색속도를 향상시키는 자료구조
-
인덱스를 사용하지 않는 컬럼은 조회 시 full scan을 진행한다.
-
인덱스를 사용하면 select 외에도 update,delete 작업에서 속도가 향상한다(조회가 포함되기 때문에)
-
또한 insert 작업 시, 새로운 데이터에 인덱스 추가, delete 시, 해당 데이터의 인덱스 사용하지 않음, update 시, 기존 인덱스 사용하지 않음/ 새로운 인덱스 사용과 같은 작업으로 부하가 추가 될 수 있다.
-
PRIMARY KEY에 CLUSTERD INDEX 하나가 기본으로 생성, 이외에는 보조 인덱스 (UNIQUE 제약 조건 하에는 보조 인덱스가 기본으로 생성)
인덱스의 장점
- 조회 속도로부터 성능 향샹
- 시스템의 부하를 줄여줌
인덱스의 단점- db 전체 저장공간의 10% 가량을 사용
- 인덱스 관리를 위한 추가적이 작업이 필요
- 잘못 사용 시, 오히려 성능이 저하
- CREATE, DELETE, UPDATE가 빈번한 테이블의 경우에는 인덱스 사용이 부적합하다, 이러한 쿼리가 잦아질 경우 인덱스가 비대해져 데이터보다 많은 공간을 차지 하게 될 수 있다.
인덱스를 사용하면 좋은 경우- 규모가 큰 테이블
- JOJN/WHERE/ORDERBY 절이 잦은 경우
- INSERT/UPDATE/DELETE 절이 적은 테이블
- 컬럼 내 중복 데이터가 적은 경우(B+TREE의 KEY/VALUE 구조 탐색이기 때문)
인덱스설계

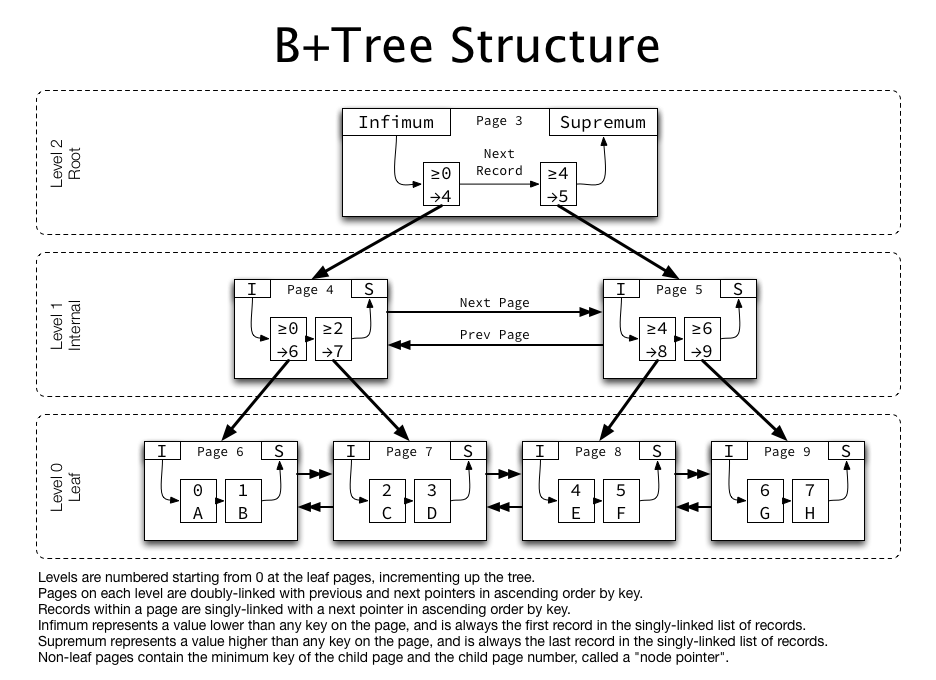
CREATE OR REPLACE INDEX idx_firstname ON employees(first_name);
CREATE OR REPLACE INDEX idx_lastname ON employees(last_name);
ANALYZE TABLE employees;
SELECT * FROM employees WHERE first_name = 'moon';
EXPLAIN SELECT * FROM employees WHERE first_name = 'moon';
> index 를 사용했을 때, 조회하는 행의 개수가 대폭 줄어든다.
CREATE OR REPLACE INDEX idx_firstlast ON employees(first_name, last_name);
> 두 개 이상의 컬럼을 인덱스로써 활용할 수 있다.
EXPLAIN SELECT * FROM employees WHERE emp_no = 100000;
EXPLAIN SELECT * FROM employees WHERE emp_no * 1 = 100000;
> emp_no = 100000으로 조회 했을 때, 한 개 행을 조회한 반면, emp_no * 1과 같이 where 절에 이항 연산자를 사용했을 때, 모든 행을 조회하였다.느낀 점
뷰르르

O_O