출처들) 한권으로 읽는 컴퓨터 구조와 프로그래밍.
1. 티스토리에 책내용 정리하신 분
2. 깃헙에 그룹스터디로 책내용 정리하신 분들
3. 티스토리에 책내용 정리하신 다른분
4. 깃헙에 책의 굵직한 부분만 요약해주신분
5. velog에 책의 내용정리하신 분
6. velog에 책내용 정리하신 다른분
1. 언어란 무엇인가
> 모든언어는 기호의 집합으로 인코딩 된다.
언어가 제대로 작동하려면 의사소통하는 당사자들이
모두 같은 문맥을 공유해야 한다.
어떤기호가 있다면,
모든사람이 그 기호에 같은 의미를 부여할 수 있어야 한다.
이를 구분할 수 있는 요소는 문맥이다.
문맥에 따라 해당 기호가 어떤 의미로 사용하고있는지 구분해야한다.2. 비트
3가지 구성요소가 문자언어의 틀을 이룬다.
- 기호가 들어갈 상자 (상자)
- 상자에 들어갈 기호 (기호)
- 상자의 순서
상자란 자연어에서는 문자라고 부르고,
컴퓨터에서는 bit(비트)라고 부른다.
비트 : 바이너리(binary) + 디지트(digit)
- 바이너리(binary) : 2진법( 0, 1 )
- 디지트(digit) : 10진수( 0~9 )왜 컴퓨터에서 비트를 사용하는지는 2장에서 살펴본다!
비트는 2진법(점,선)을 사용하는데 중요한것은 기호의 순서와 문맥.
ex) 말하는 사람 : 점-점-선
듣는 사람 : 쌀-쌀-보리
-> 이러면 소통이 안됨.비트를 순서에 따라 의미를 부여해 언어로 사용하게 된다.
비트는 데이터를 나타내는 최소 단위.
모든 데이터는 0과 1의 조합으로 구성됨.
0 또는 1이 하나의 비트.
1개의 비트는 (1과 0) 두가지 상태를 나타낼 수 있으므로
n개의 비트는 2의 n제곱 가지의 상태를 나타낼 수 있음.3. 논리연산
비트 사용법 중 하나로
다른 비트들이 표현하는 내용으로 부터 새로운 비트를 만들어내는 동작.
예/아니오, 참/거짓 으로 표현1) 불리언 대수(==조합논리) (+2장에서 추가)
대수는 수에대한 연산규칙의 집합.
불리언 대수란 비트에 대해 사용할 수 있는 연산규칙의 집합.
결합법칙, 교환법칙, 분배법칙 모두 적용가능
기본적인 불리언 연산자는 NOT,AND,OR. + XOR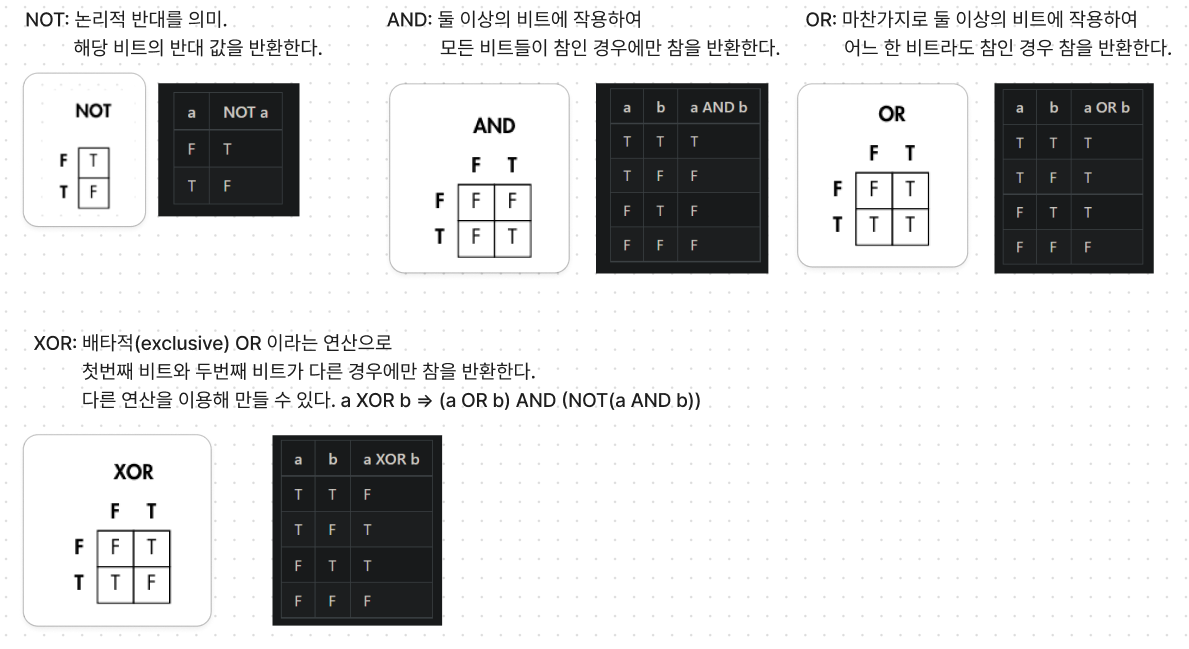
2) 드모르간의 법칙
드모르간이 불리언대수에 법칙을 추가함.
NOT연산을 이용해 AND→OR연산으로 또는 OR→AND연산으로 나타낼 수 있다.
이를 통해 입력에 따라 연산을 최소화해
계산속도를 높힘과 동시에 비용을 절감할 수 있다.
컴퓨터에서 입력을 늘 원하는 형태로만 얻을 수 없기 때문에
이런 성질이 유용.
ex)나는 사랑에 빠지지 않을 수 없었어.(이중부정) = 나는 사랑에 빠졌어.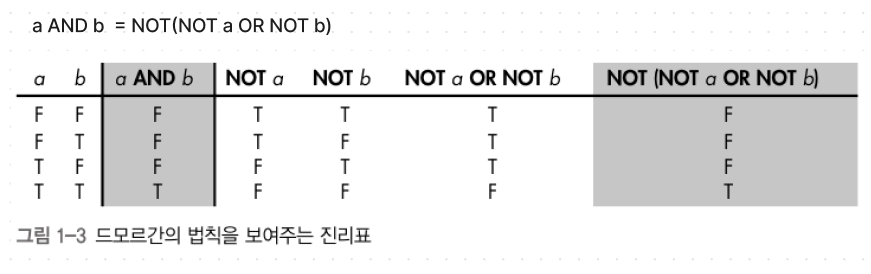
정논리 : 긍정적인 논리.
부논리 : 부정적인 논리.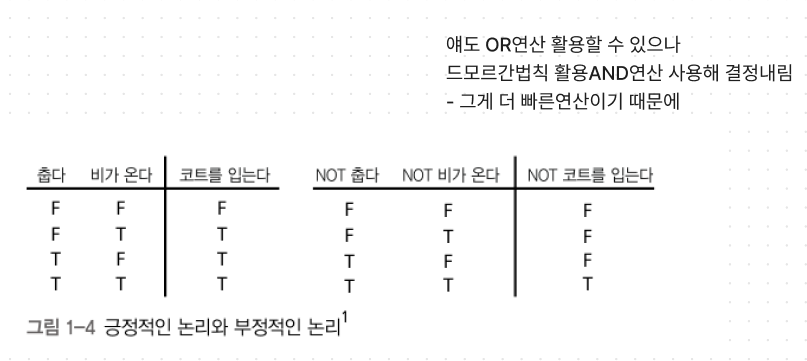
드모르간의 법칙을 알면 오른쪽 표가 표현하는 논리가
‘춥다 OR 비가온다’와 동등함을 알 수 있다.
+ 왜 같음? 보기엔 다른데...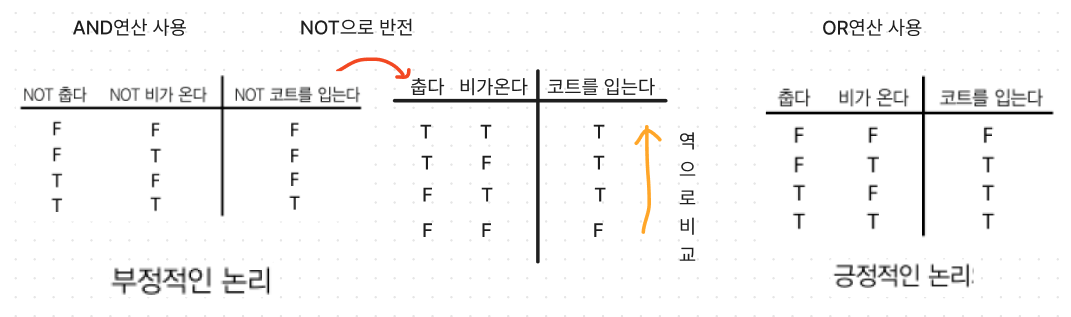
4. 정수를 비트로 표현하는 방법
앞서 비트(bit)는 binary와 digit가 합쳐진 말로,
적은 비용으로 편리하게 기호를 담을 수 있는 상자라고 했다.
이제 2진법을 사용하는 비트로 특정 수를 표현하는 방법을 알아본다.
수는 논리보다 복잡하지만 단어보다는 단순하다.1) 양의 정수 표현
비트로 정수를 표현하는 방법을 알아보기 전에,
우리가 일상생활에서 사용하는 10진수 체계부터 알아보자.10진수
10진수 체계에서는 10가지 기호인 숫자(0~9)를 상자에 담을 수 있다.
이때 상자는 오른쪽에서 왼쪽으로 쌓여가며,
각 상자마다 각기 다른 이름이 붙어있다.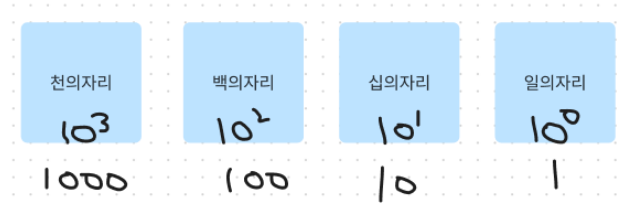
십진수는 지수를 적용할 밑으로 10을 사용하기 때문에
밑이 10인 시스템이라고 부른다.
5028이라는 수를 10진수로 표현하면 아래 사진과 같다.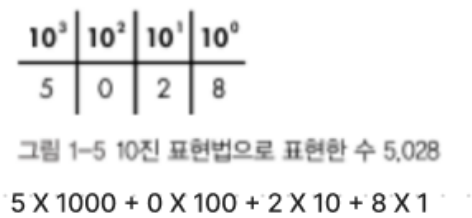
2진수
비트를 사용해 값을 만들 때도 이와 비슷하게 접근할 수 있다.
비트는 2진수 체계이기 때문에,
각 상자에 들어갈 수 있는 수는 0과 1 두 가지뿐이다.
이외에는 10진수 체계로 수를 표현한 것과 동일하다.
각 상자 위치를 표현하는 밑(base)은 2인 수체계이다.
그리고 10진수에서는 어떤 자리의 수가 9를 넘어가면,
10을 추가로 제곱한 자리(좌측 상자)가 추가되지만,
2진수에서는 1이 넘어가면 상자가 추가된다.
그렇다면 5028을 2진수로 표현한다면?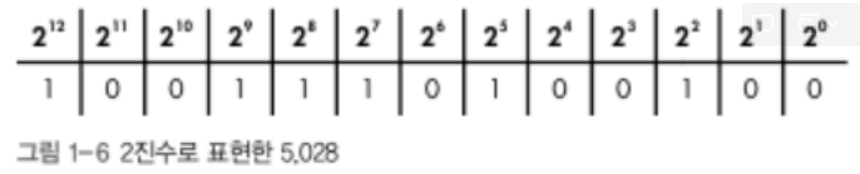
10진수에서는 5,028이 4자리 숫자이지만,
이처럼 2진수로 동일한 값을 표현하면 13자리 숫자(13비트 수)가 된다.
그런데 이 그림을 보면 16비트이다.
다시 상기해보자면 비트라는 것은 수가 아니라 수를 담는 상자라고 했다.
컴퓨터가 미리 정해진 수의 비트를 한덩어리로 사용하도록 만들어졌기 때문에,
2진수를 쓸떄는 이런식으로 항상 일정한 개수의 비트를 사용해
값을 표현하는 경우가 종종 있다.
(이런식으로 추가된 0들을 리딩제로(leading zero)라고 한다.)
2진수에서 가장 오른쪽비트를 가장작은 유효비트`LSB(Least Significant Bit),`
반대로 가장 왼쪽의 비트를 가장 큰 유효비트 `MSB(Most Significant Bit)` 라고 부른다.
가장 오른쪽의 비트를 변경하면 값이 가장 작게 변경되고,
가장 왼쪽의 비트를 변경하면 가장 크게 변하기 때문이라고 한다.2진수 덧셈(+9/29일 추가)
한번 더 상기하자.
10진수는 합쳤을때 10이되면 올려서 더하지만,
2진수는 합쳤을때 1보다 크면 1을 다음자리로 올린다.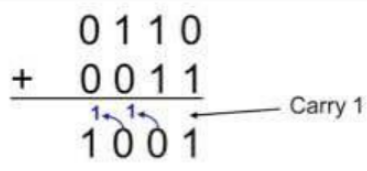
2진수의 덧셈의 규칙을 논리연산을 사용해 아래처럼 표현할 수 있다.
(이는 2장에서 컴퓨터 하드웨어가 2진수 덧셈을 어떻게 수행하는지 설명할 때,
이 사실을 살펴본다.)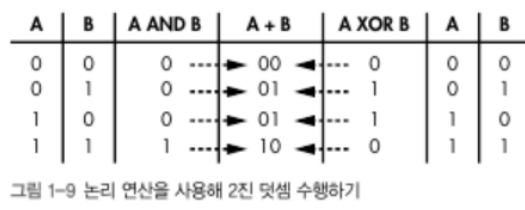
(+10월 6일 추가)
두비트를 서로 더한 결과는 두 비트를 XOR한 값과 같고,
올림은 두비트를 AND한 값과 같다.
위 그림에서 1과 1을 더한 결과가 10임을 보면 이 설명이 참임을 알 수 있다.
1과 1을 더하면 올림이 1인데 이 값은 (1 AND 1)을 계산한 값과 같다.
마찬가지로 (1 XOR 1)은 0인데, 이 값은 두 비트를 더한 결과에서
원래 위치에 넣을 값과 같다.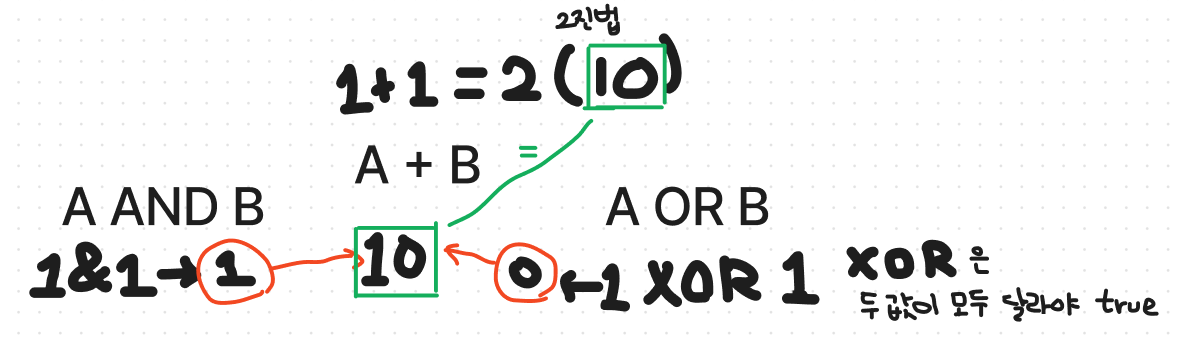
오버플로
덧셈결과가 우리가 사용할 비트개수를 넘어가면 어떻게 해야할까?
오버플로우는 MSB에서 올림이 발생했다는 뜻이다.
4비트 덧셈 1001(9)+1000(8) = 10001(17)로 5비트 결과가 나온다.
하지만 추가로 사용할 수 있는 비트가 없다면 결과는 0001이 된다.
나중에 알게되겠지만 컴퓨터에는 조건코드 레지스터 라는곳에
몇가지 이상한 정보를 담아두며 이 정보들 중에 오버플로우 비트가 있다.
이 비트에는 MSB에서 발생한 올림 값이 들어간다.
이 비트 값을 통해 오버플로우가 발생했는지 여부를 알 수 있다.언더플로
MSB 위쪽에서 1을 빌려오는 경우 발생.
이 조건코드도 컴퓨터에 들어있음.2) 음수표현
비트들을 사용해 음수를 표현하는 방법을 살펴보자.
**4비트를 쓴다고 가정**
4비트로는 0부터 15까지 16가지 수를 표현할 수 있다.
4비트로 수를 16가지만 표현할 수 있다는 말이
꼭 4비트로는 0부터 15까지만 표현 할 수 있다는 뜻은 아니다.
기억하라.
언어는 문맥과 의미를 통해 작용한다.
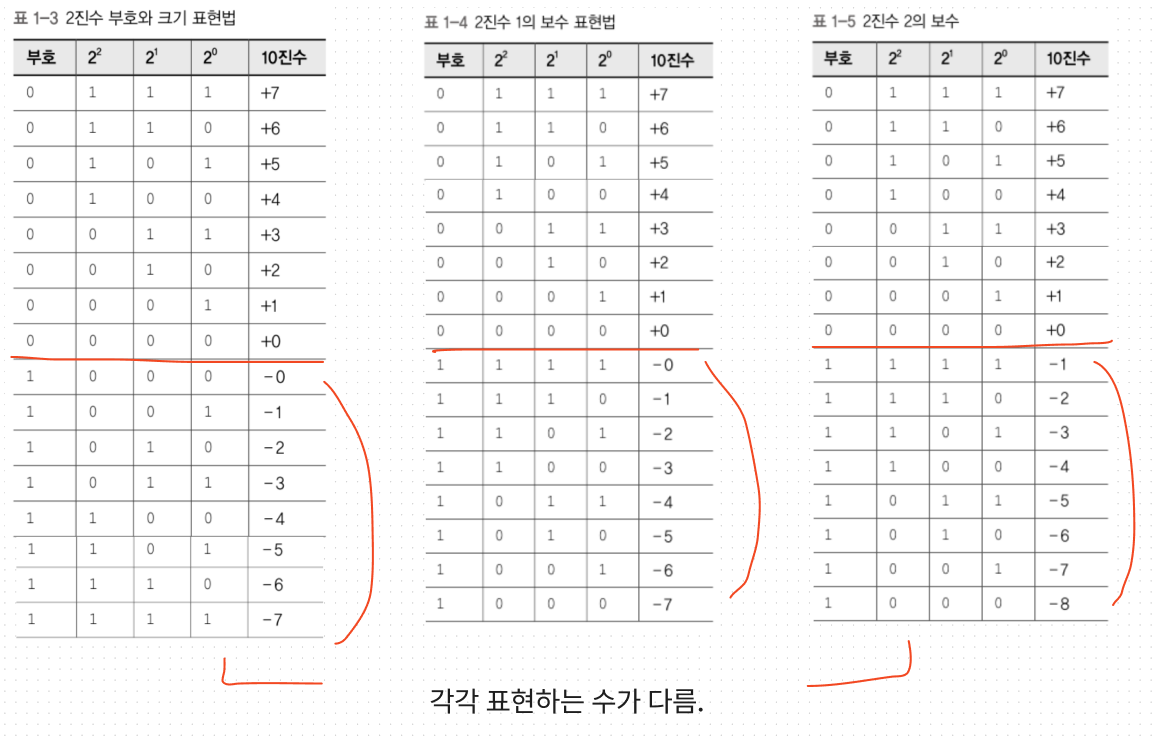
이 말은 비트들을 해석하는 새로운 문맥을 만들 수 있다는 뜻이기도 하다.① 부호와 크기 표현법
한 비트를 부호에 사용하고 나머지비트를 0부터의 거리(절대값)을 표현하기 위해
사용하는 방법.
음수와 양수를 구별하기 위해
가장 왼쪽비트(MSB)를 부호표시에 사용. (부호비트)
따라서 4비트중에 3비트가 남고,
이를 사용하면 0부터 7까지 수를 표현할 수 있다.
부호비트가 0이면 이 수를 양수로 취급하고,
부호비트가 1이면 이 수를 음수로 취급.단점 :
-0을 표현하는 방식이 두가지라 비용낭비
-이표현법은 and와 xor통한 덧셈 사용불가.② 1의보수 표현법
음수를 표현하기 위해 양수의 모든 비트를 뒤집는 방법.
얘도 부호와 크기표현법과 비슷하게 비트들을 부호비트와 나머지로 나눔.
1의 보수 표현법의 문맥에서는 NOT연산을 통해 보수를 얻음.
왜 비트를 뒤집냐고?
내부적으로 비트들간의 덧셈과 뺄셈 연산을 쉽게하기 위함.
단점:
-0을 표현하는 방식 얘도 두가지.
-덧셈을 하려면 순환올림을 처리하기위한 하드웨어 추가해야함.따라서 현대컴퓨터에서 둘다 안씀.
③ 2의보수표현법
앞의 2개의 문제를 해결하는 표현법
+1에 더했을때 0이 나오는 비트퍁턴을 찾고 이패턴을 -1이라고 부른다.
4비트의 경우 +1은 0001 이다.
+1에 더했을때 0이 되는 수는 1111이다.
따라서 앞으로는 1111을(4비트에서) -1을 표현하는 비트패턴으로 사용
쉽게하려면 어떤수의 비트를 뒤집고( 즉 각비트의 NOT을 취하고)
1을 추가하면 음수를 얻을 수 있다.
이때 MSB에서 올림이 발생하면 이값은 버린다.
위의 예시를 통해 설명하면
+1 즉 0001의 비트를 뒤집으면 1110이고 여기에 1을 더하면 1111이 되며,
이 값이 -1을 표현한다.
비슷하게 +2는 0010이고, 비트를 뒤집으면 1101, 여기에 1을더하면 1110이다.
이 값이 -2를 표현한다.얘는 앞의 두 표현법과 달리 0이 중복되지 않는걸까?
4비트 기준!
0은 0000이다 이를 뒤집으면 1111 여기에 1을 더하면 10000이되는데,
이 숫자는 5비트이므로 1을 올림비트라 생각하고 무시.
결과적으로 0000이 되고 2의 보수표현법에서는 0을 표현하는 방법이 하나뿐이다.프로그래머들은 자신이 다뤄야 하는 수를 표현하기 위해
필요한 비트의 개수를 알 필요가 있음.
2의 보수를 사용해 표현할 수 있는 값의 범위는 아래 표와 같다.
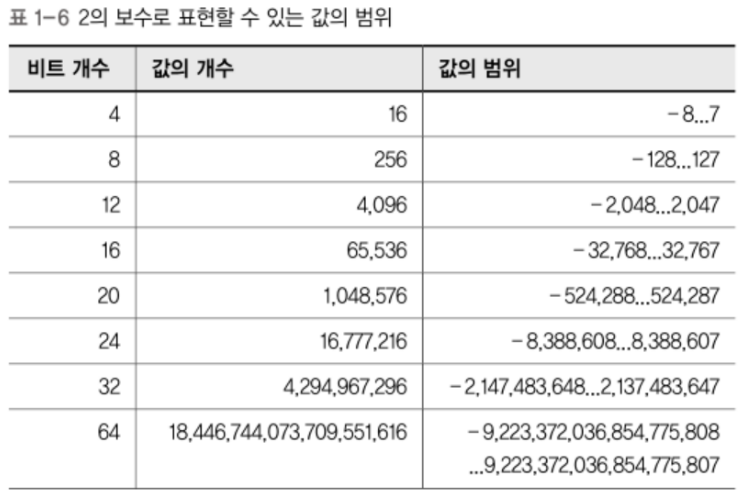
같은 숫자로 이루어진 수를 보더라도
문맥에 따라 표현하는 값이 달라질 수 있음.
따라서 내가 어떤 표현법을 사용하는지 알고 있어야 한다.
5. 실수를 표현하는 방법
(9/30일 추가)
밑이 10인 실수에는 10진 소수점이 포함된다.
따라서 밑이 2인경우, 실수를 표기하기 위해 2진소수점을 표현할 방법이 필요하다.
정수와 마찬가지로 문맥에 따라 실수를 표현하는 방법이 달라질 수 있다.① 고정소수점 표현법 (아 이런게 있구나~하고 넘어가도됨)
2진 소수점의 위치를 일정하게 정해놓고 표현하는 방법.
ex) 4비트가 있다면 그중 2비트는
2진 소수점의 오른쪽에 있는 분수들을 표현하는데 쓰고,
나머지 2비트는 왼쪽에 있는 숫자를 표현하는데 사용.
이 방법은 쓸모있는 범위의 실숫값을 표현하려면 비트가 많이 필요하기 때문에
범용 컴퓨팅에서는 사용되고 있지 않음.
DSP라는 디지털 신호처리장치에 쓰이는 일부 컴퓨터가 쓴다고는 한다.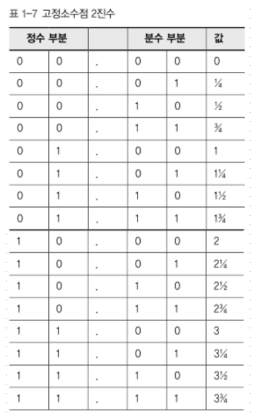
② 부동소수점 표현법
(->컴퓨터에서 계산을 수행할 때 실수를 표현하는 표준방법)
플랑크상수(양자역학 기본상수 중 하나) / 아보가드로 수
→ 두수의 범위는 10의 57제곱에 달하며, 대략 2의 191제곱정도나 된다.
거의 200비트가 필요.
이런 큰수를 2진수로 표현하기 위해 과학적 표기법을 2진수에 적용하는 방법
ex) 과학적 표기법에서는 0.0012를 1.2 X 10^-3(10의 -3제곱)으로 표기.
여기서 밑을 2로 바꾸면 됨.
단점: (4비트 예시 기준)
1. 비트 조합 중에 낭비되는 부분이 많다.
0을 표현하는 방법이 네 가지나 되고
1.0, 2.0, 4.0을 표현하는 방법도 2가지씩 존재
2. 비트 패턴이 가능한 모든 수를 표현하지는 못한다.
지수가 커질수록 가수의 한 패턴과 다른 패턴 사이의
값 차이가 커진다.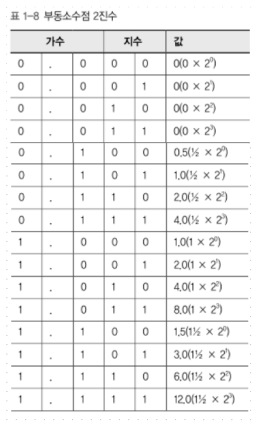
③ IEEE 부동소수점 수 표준
IEEE는 미국 전자전기공학회의 약자로(Insitute Of Electrical and Electronics Engineers)
표준 제정 등 다양한 활동을 하는 전문가 조직이다.
부동소수점 표보다 더많은 비트를 사용하며
가수와 지수에 대해 각각 부호비트를 사용.
다만 지수에 대한 부호비트는 지수의 비트 패턴에 감춰져 있다.
그리고 낭비되는 비트조합을 최소화 하고,
반올림을 쉽게 하기 위한 여러가지 트릭이 사용된다.
IEEE 754라는 표준은 이 모든 기능을 정의한다.
1. 정규화
- 같은 비트를 사용하더라도 정밀도를 높이고 싶을 때 사용
- 가수를 조정해서 맨 앞에 0이 없게 만드는 것
(가수조정하려면 지수도 조정해야함)
2. 디지털 이큅먼트(DEC)에서 고안한 것
- 가수 맨 왼쪽 비트가 어차피 1이기 때문에 생략하는 것
IEEE754중 두가지 부동소수점 수가 자주쓰인다는 사실을 알아둬야 함.
1. 기본정밀도 부동소수점 수(single precision, 단정도 실수)
332비트 사용, 7비트 정밀도로 표현가능
2. 2배 정밀도 부동소수점 수(double precision, 배정도 실수)
64비트 사용. 15비트 정밀도로 표현가능
기본정밀도 보다 지수가 3비트 크고, 가수가 29비트 크다
(but 비트를 2배 더 많이 사용한다 → 돈이 많이든다.)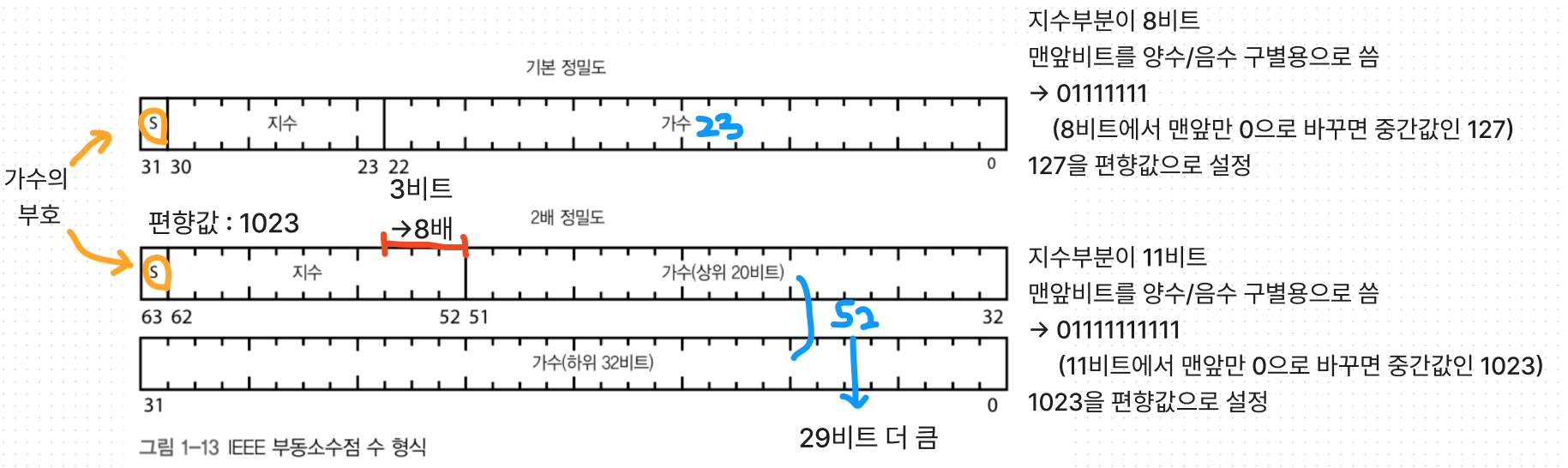
두 형태 모두 가수에 대한 부호를 사용한다. (위그림의 S)
하지만 지수에 대해 부호 비트가 따로 존재하지 않는다.
(그래서 지수부분의 맨앞비트가 부호비트로 사용됨)
IEEE 754 설계자들은 지수비트가 모두 0이거나 1인경우에 특별한 의미를 갖게하고,
실제 지숫값은 나머지 비트패턴에 집어넣고 싶었다.
IEEE 754 설계자들은 편향된 지숫값(bias)을 사용하여 비트 패턴을 활용했다.
기본 정밀도의 경우 편향값은 127, 2배 정밀도인 경우는 1023이다.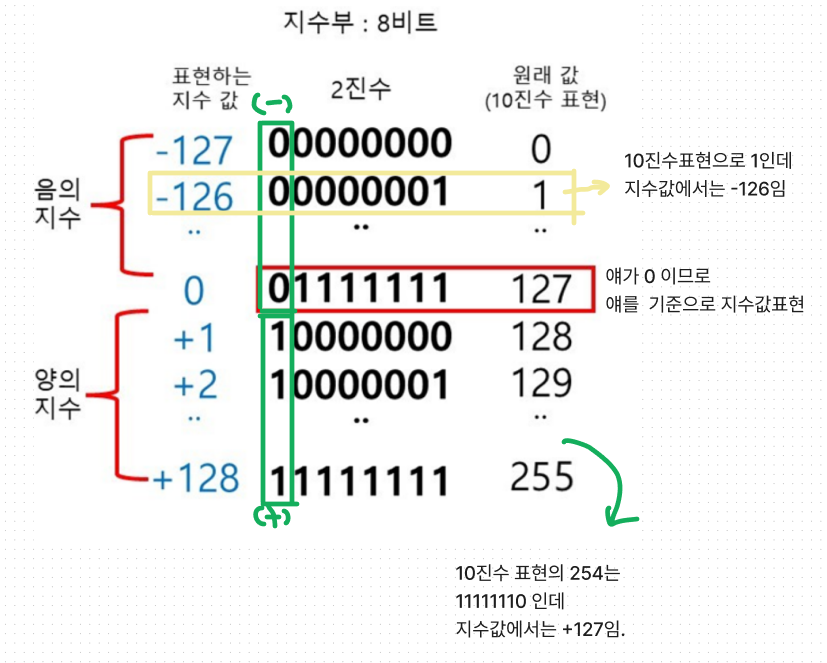
IEEE 754에서 편리한 점은 0으로 나눴을 때 생길 수 있는
양의 무한대나 음의 무한대를 표현하는 비트 패턴 등
여러 가지 특별한 비트 패턴을 제공한다.
이런 특별한 비트패턴들은 특별한 지숫값을(모든비트가 0이거나 모든비트가 1인지수)
사용한다.
'NaN'을 표현하는 특별한 값도 존재한다.
이로인해 부동소수점 수로 계산하던중 NaN 값이 생기면
뭔가 잘못된 산술연산을 수행했다는 뜻이다.6. 2진 코드화한 10진수 시스템(BCD)
(10/4일 추가)
4비트를 사용해 10진숫자를 하나로 표현한다.
디스플레이, 가속도 센서등이 BCD를 사용하는 경우가 있으나
요즘 컴퓨터는 BCD를 비트낭비로 인해 사용하지 않음.7. 2진수를 다루는 쉬운방법
2진수를 조작하다보면 눈이 아파진다.
그래서 사람들은 2지수를 더 읽기 쉽게 표현할 수 있는 방법을 고안해냄8진 표현법
8진이라는 말은 밑이 8이라는 뜻이다.
이는 2진수 비트들을 3개씩 그룹으로 묶는 아이디어다.
3비트를 2^3또는 0부터 7까지의 값으로 표현할 수 있다는 사실을
알 수 있어야 한다.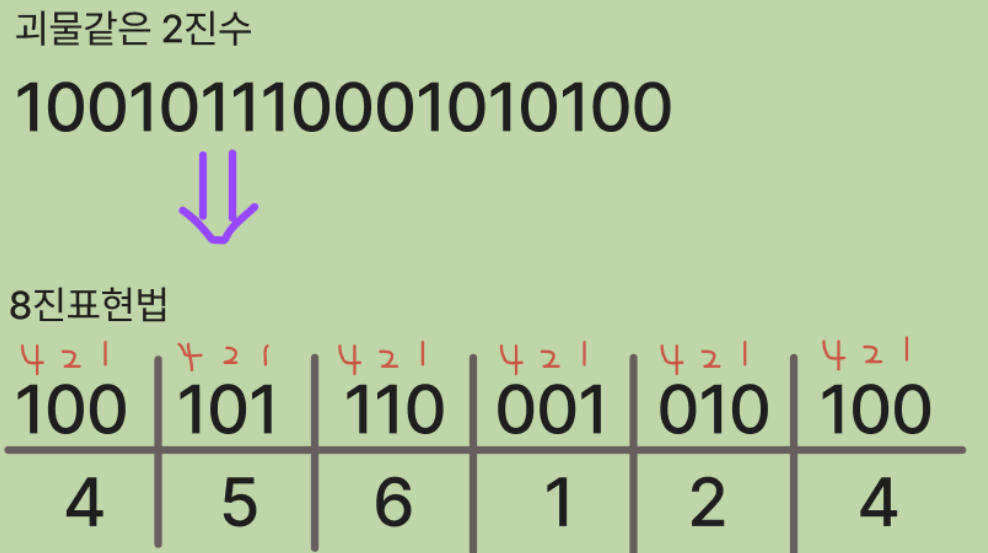
16진 표현법
16진 표현법은 밑이 16이라는 뜻이다.
8진표현법은 과거처럼 널리쓰이지 않고 대신 16진 표현법이 쓰이고 있다.
그 이유는 요즘 컴퓨터 내부가 8비트의 배수를 사용해 만들어지기 때문이다.
8의 배수는 4로는 균일하게 나눠지지만 3으로는 균일하게 나눠지지 않는다.
(16진수 한자리의 비트수) (8진수 한자리의 비트수)
2진수는 0과 1만 필요
8진수는 0 1 2 3 4 5 6 7 만 필요
16진수는 10가지 숫자만으로는 충분치 않음.
그리하여 0 1 2 3 4 5 6 7 8 9 a b c d e f 를 사용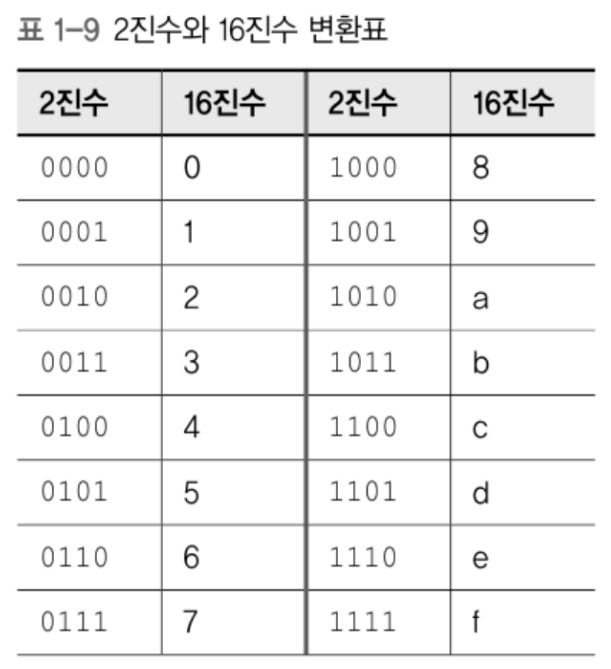
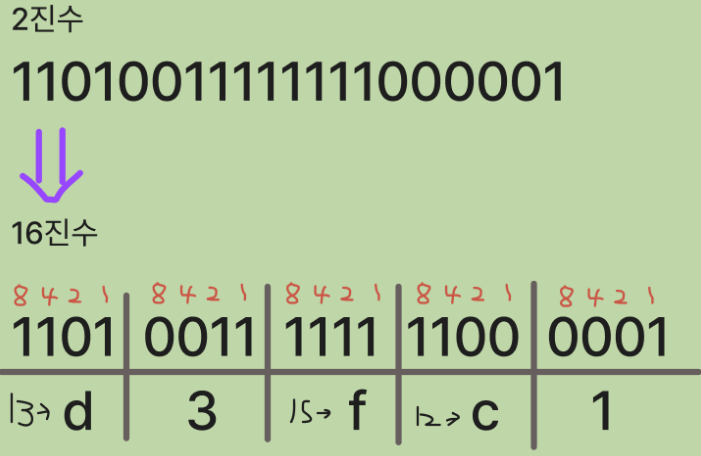
11010011111111000001를 d3fc1이라는 16진수로 표현 할 수 있음.프로그래밍 언어의 진법 표기법
수를 변환하는 방법은 어떻게 알 수 있을까?
예를 들어 10이라는 수가 2진수라면 10진수 2이고, 8진수라면 10진수 8이며,
10진수라면 10이고, 16진수라면 10진수 16이다.
수학책에서는 아래첨자로 각 진법을 구분한다.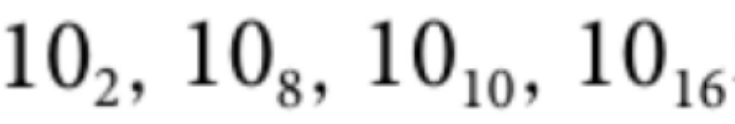
하지만 아래 첨자는 컴퓨터 키보드로 입력하기 불편하다.
여러 프로그래밍 언어에서는 다음과 같은 표기법을 따른다.
- 0으로 시작하는 숫자는 8진 숫자다.
예를 들어 017은 8진수이며 값은 10진수로 15다.
- 1부터 9사이의 숫자로 시작하는 숫자는 10진수다.
예를 들어 123은 10진수다.
- 0x가 앞에 붙은(접두사) 숫자는 16진수다.
예를 들어, 0x12f는 16진수이며 값은 10진수 303이다.
- C++같은 몇몇 언어는 0b라는 접두사를 사용해 2진수를 표현한다.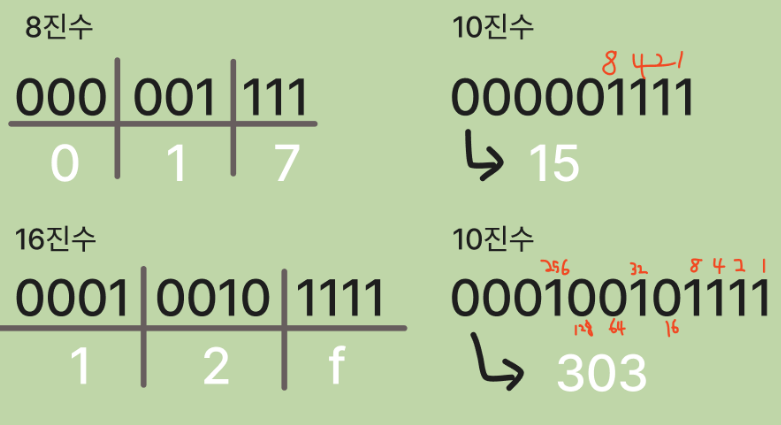
8. 비트그룹의 이름
컴퓨터는 제대로 조직화되지 않은 비트들로 이루어지지 않는다.
즉 컴퓨터가 사용할 비트의 개수와 비트의 조직을 결정해
컴퓨터가 유용하게 사용할 수 있도록 처리해야한다.
비트는 너무 작아 기본 단위로 사용하려면 유용성이 떨어진다.
따라서 비트를 좀 더 큰 덩어리로 조직화 해야함.
ex) 허니웰(HoneyWell) 시리즈 컴퓨터
- 36비트 덩어리를 기본 조직으로 함.
이를 18비트, 9비트, 6비트 덩어리로 나눠서
사용하거나 두 덩어리를 묶어서 72비트 덩어리로 사용
DEC PDP-8
- 12비트 덩어리 사용
점점 시간이 지남에 따라 8비트 덩어리가 기본 단위로 널리 쓰였고
이를 바이트(byte)라 부름.
다른 크기의 덩어리들도 가르키기 쉽도록 이름이 붙음.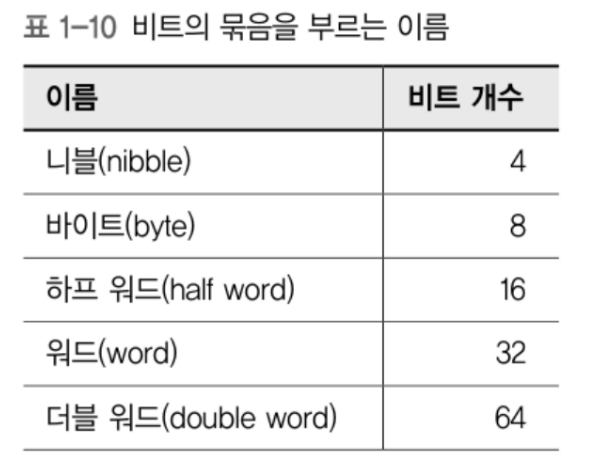
-워드: 각 컴퓨터가 설계상 자연스럽게 사용할 수 있는 비트의 묶음
→ 컴퓨터가 가장 빠르게 처리할 수 있는 가장 큰 덩어리)
- C, C++ 등의 언어에서 integer로 선언한 변수가
자연스러운 크기의 2진수를 표현한다.
- 이 외에도 몇가지 정해진 비트 크기의 변수를 선언할 수 있다.큰 수를 가리키기위해 사용하는 표준용어
원래 킬로/메가/기가/테라는 밑이 10이지만
컴퓨터용어에서는 밑이2인 값을 표현하게 됨.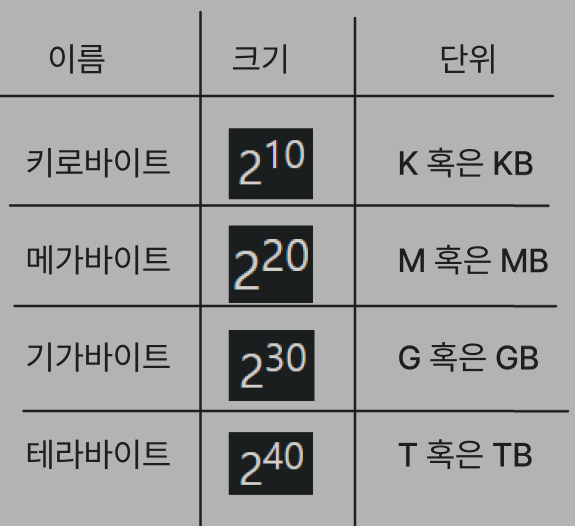
위와 같은 단위들은 밑을 2로 사용하고 있지만,
때때로 밑이 10인 용어를 뜻할 때도 있다
전통적으로 디스크 크기를 다룰때는 밑을 10으로 사용했다.
단위의 통일을 위해 새로운 IEC 표준 접두사가 만들어졌고 이는 아래와 같다.
9. 텍스트 표현
컴퓨터는 항상 비트를 다룬다는 사실과 비트를 사용해 수를 표현할 수 있다는 것을 알았다.
이제 수를 사용해 문자나 키보드에 있는 다른 기호등을 표현하는 방법을 살펴보자.① 아스키 코드 (ASCII)
정보 교환을 위한 미국 표준 코드 (ASCII)이다.
ASCII가 텍스트를 표현하는 방법은 키보드에 있는 모든 기호에 대해서
7비트의 수를 할당했다.
대부분의 문자 인코딩이 아스키에 기초를 두고 있다.
- 33개의 출력 불가능한 제어문자
->글자 출력이 아닌 장치제어에 쓰임.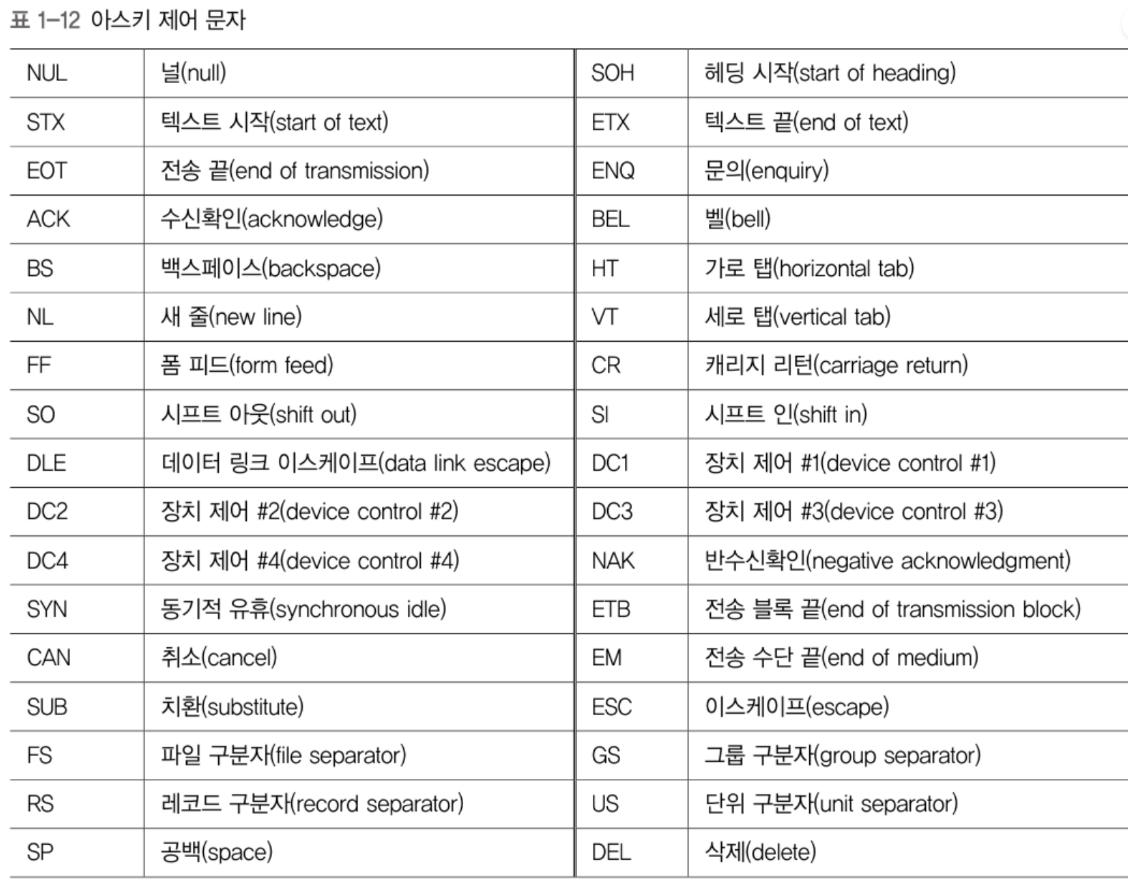
- 공백을 비롯한 95개의 출력 가능한 문자 총 128개로 이루어져 있다.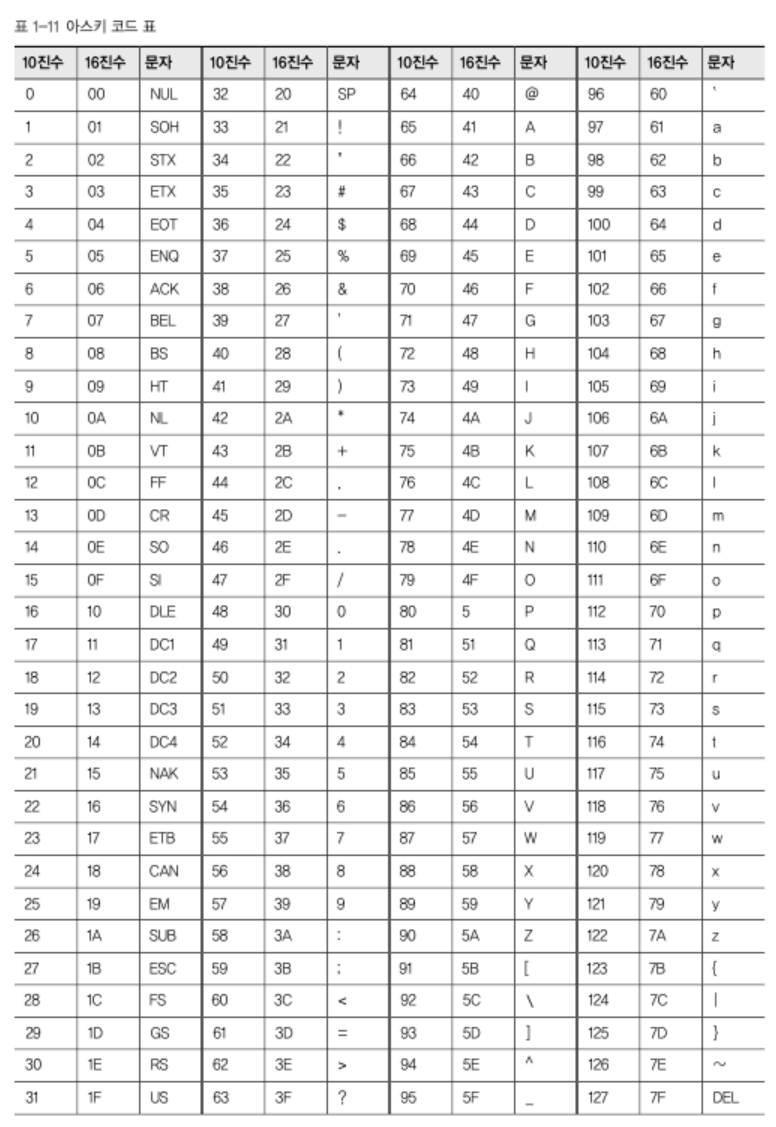
② 다른 표준의 진화
초기 컴퓨터는 대부분 미국산 아니면 영국산이었다.
그리고 아스키 코드는 영어를 표현하는데 필요한 모든 문자를 포함하고 있어
표준 역할을 오래 해왔다.
그러나 컴퓨터가 널리 쓰이면서 그 밖에 언어를 지원해야 할 필요가 늘어났다.
- 유럽: 국제 표준화 기구 (ISO)에서 ISO-646, ISO-8859 도입
- 아스키를 확장해 유럽 언어에 필요한 액센트 기호, 발음 구별 기호를 추가.
(128개 => 256개의 문자를 표현)
- 일본: JISX 0201 - 일본 문자 표현
- 한국: KS C 5601 등 표준이 생김
다양한 표준이 생긴 이유는 비트가 지금보다 더 비싼 시절에 표준이 만들어졌기 때문이다. 문자를 7비트나 8비트에 욱여넣었다.
그 후 비트 가격이 떨어면서 유니코드라는 새로운 표준이 만들어졌다.③ 유니코드 변환 형식 8비트
컴퓨터는 7비트 값을 처리하도록 설계되지 않았기 때문에 8비트를 사용해
아스키 문자를 저장한다.
유니코드는 문자 코드에 따라 각기 다른 인코딩을 사용해 이런문제를 해결한다.
인코딩은 다른 비트패턴을 표현하기 위해 사용하는 비트패턴을 뜻한다.
비트 같은 추상화를 사용해 숫자표현, 숫자를 사용해 문자를 표현,
다시 숫자를 사용해 문자를 표현하는 숫자를 표현.
유니코드 변환형식 8비트(UTF-8)라는 인코딩방법이 하위 호환성과 효율성 때문에
가장 널리 쓰이고 있다.
UTF-8은 모든 아스키 문자를 8비트로 표현하기 때문에
아스키 데이터를 인코딩할 때는 추가 공간이 필요하지 않다.
UTF-8은 아스키가 아닌 문자의 경우
아스키를 받아서 처리하는 프로그램이 깨지지 않는 방법으로 문자를 인코딩한다.
UTF-8은 문자를 8비트 덩어리(이를 옥텟(octet)이라고 부른다)의 시퀀스로 인코딩한다.
UTF-8에서 교묘한 부분은 첫번째 덩어리(8비트)의 MSB쪽에 있는 비트들이
8비트 덩어리(옥텟) 시퀀스의 길이를 표현하고,
(MSB쪽의 비트패턴이 겹치지 않아서) 덩어리의 맨 앞을 식별하기 쉽다는데 있다.
프로그램이 문자경계를 찾아야 하는 경우 이런 특성이 아주 유용하다.
모든 아스키 문자는 7비트에 들어가기 때문에 덩어리를 하나만 사용해 표현할 수 있다.cf)UTF-8 변환규칙
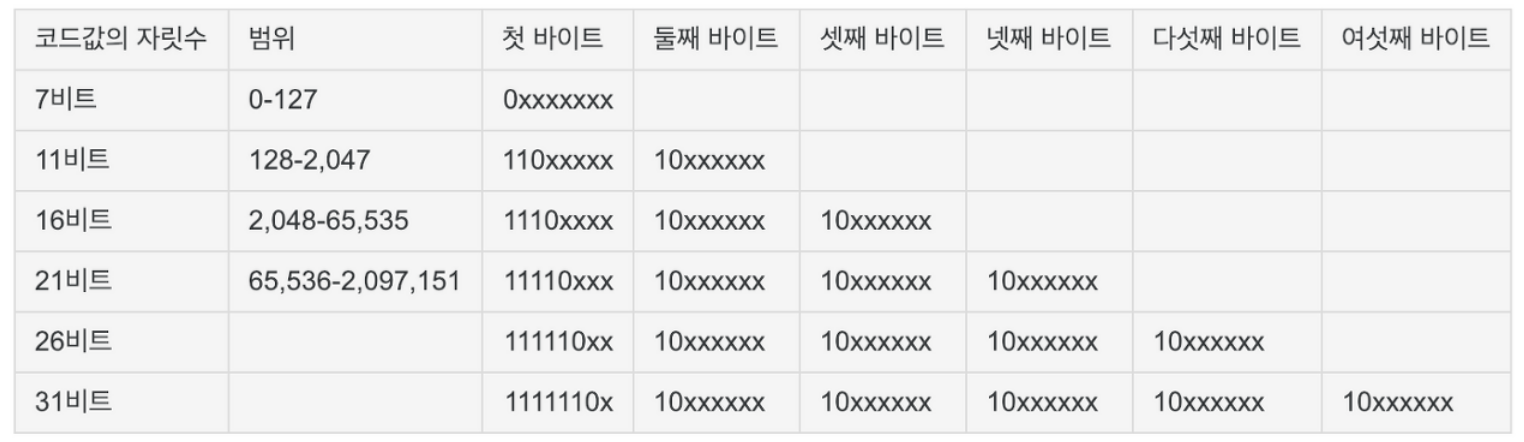
10. 문자를 사용한 수 표현
(10/6일 작성)
UTF-8은 문자(예: A)를 표현하는 비트들로 부터 나온 숫자들을
표현하는 숫자들(UTF-8로 인코딩한 값)을 표현하기 위해 숫자들을 사용한다.
하지만 이제 문자를 사용해 수를 표현할 수도 있다.
컴퓨터 간 통신 시작초기부터 사람들은 더 많은 정보를 송수신하고 싶었다.
그러나 2진데이터를 직접보내는것도 단순하지 않았음.
아스키 코드 중 상당수가 제어문자로 예약되어 있었고, 시스템에 따라 처리하는 방식이 달랐음.① 출력 가능하게 변경한 인코딩(QP인코딩 -쿼티드 프린터블 인코딩)
8비트 데이터를 7비트 데이터만 지원하는 통신경로를 통해 송수신하기 위한 인코딩 방법
QP인코딩은 전자우편 첨부를 처리하기 위해 만들어짐.
단점 :
- 1바이트를 표현하기 위해 3바이트를 사용. → 비효율적② 베이스 64 인코딩
QP인코딩에 비해 효율적.
3바이트 데이터를 4문자로 표현.
3바이트 데이터의 24비트를 네가지 6비트 덩어리로 나누고,
각 덩어리의 6비트 값에 출력 가능한 문자를 할당해 표현한다.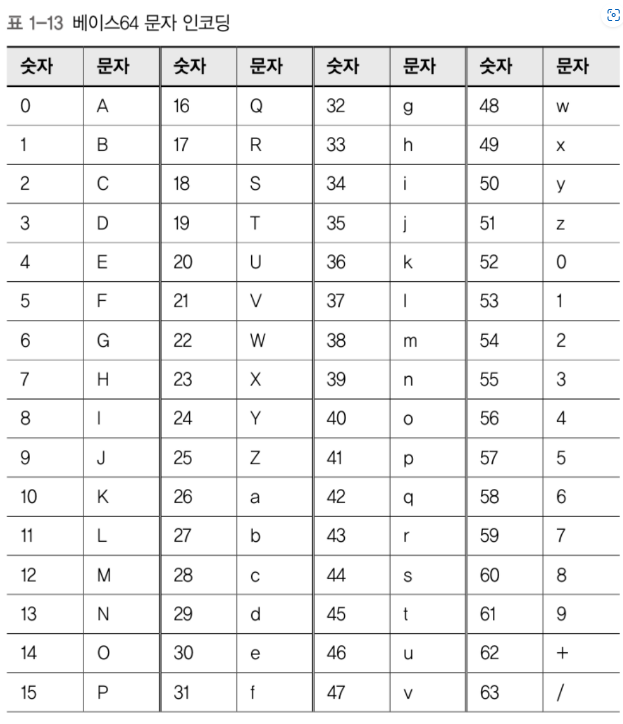
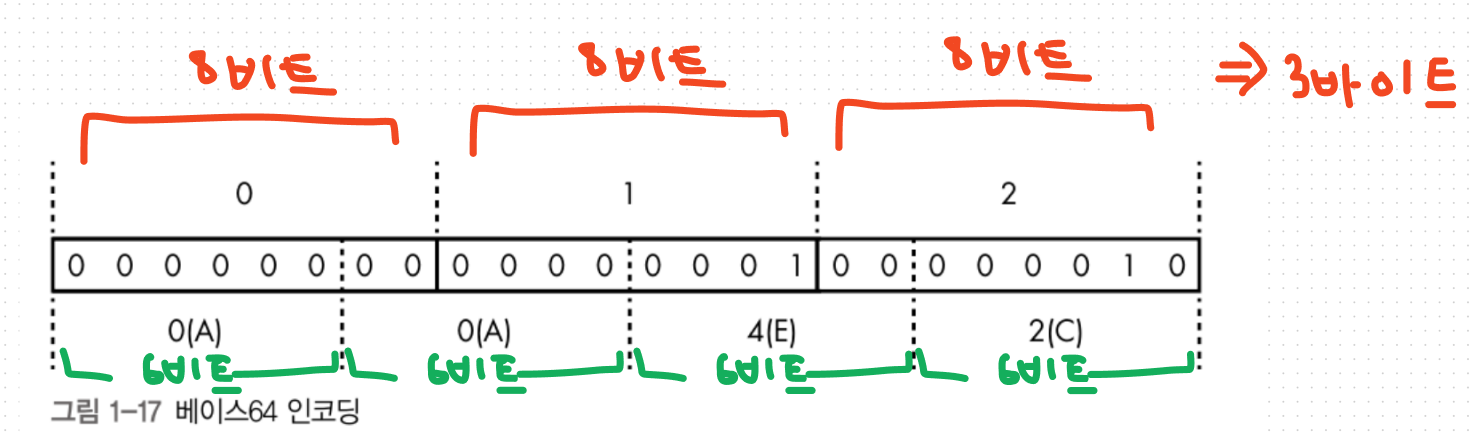
이 인코딩은 모든 3바이트 조합을 4바이트 조합으로 변환할 수 있다.
하지만 원본데이터 길이가 3바이트의 배수라는 보장은 없음.
패딩문자를 도입해 이런문제를 해결한다.
원본 데이터가 2바이트 남으면 끝에 =를 붙이고, 1바이트 남으면 끝에 ==를 붙인다.
이 인코딩 방식은 여전히 전자우편 첨부파일 전송에 많이 사용중.③ URL 인코딩(퍼센트 인코딩)
%뒤에 어떤 문자의 16진 표현을 덧붙이는 방식으로 문자를 인코딩함.
특별한 의미를 갖는 문자를 문자그대로(=리터럴) 의미로 사용하고 싶다면 %를 붙인다.
ex) /문자는 URL에서 특별한 의미를 가진다.
이 문자의 아스키 코드는 47, 16. 진수로는 2F이다.
→ %2F11. 색을 표현하는 방법
컴퓨터 그래픽스는
전자 모눈종이에 해당하는 것에 색을 표현하는 점을 찍어서 그림을 만드는 과정이다.
이때 모눈의 각 격자에 찍는 점을 그림원소라고 부르고, 줄여서 픽셀이라고 부른다.
컴퓨터 모니터는 빨간색, 녹색, 파란색 광선을 섞어서 색을 만들어내며,
이런 색 표현법을 RGB색 모델(RGB color model)이라고 부른다.
현대에는 24비트를 사용해 약 1천만의 제곱수에 해당하는 색을 표현할 수 있다.
24비트는 8비트 씩 나뉘어져 3가지 주요 색상(RGB)으로 표현한다.
그러나 현대 컴퓨터는 24비트 단위로 계산을 수행하도록 설계되지 않았기에,
32비트(워드) 에 색을 넣어 처리한다.
→ 이렇게 되면 사용하지 않는 8비트가 남는데, 이는 투명도를 표현하는 데 사용된다.(RGBA)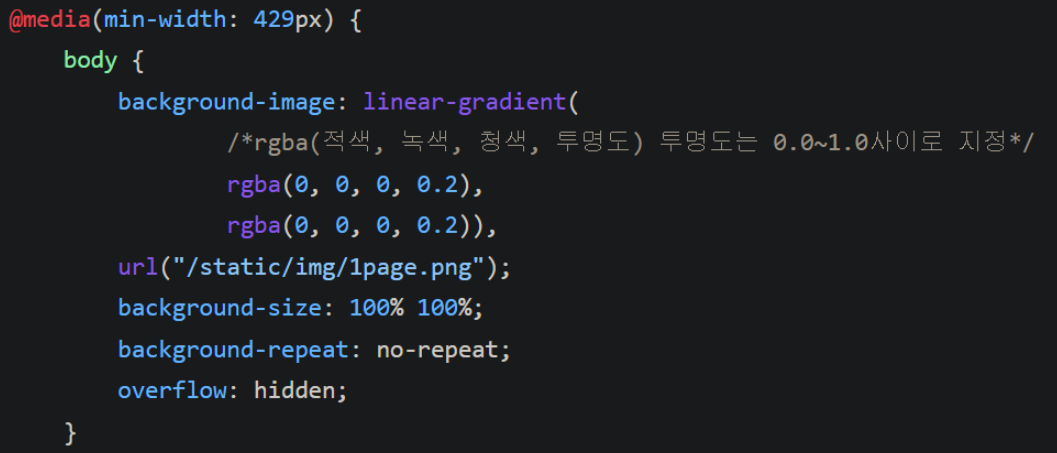
그래서 css에서 색 지정할때 rgba(0, 0, 0, 0) 으로 했던것.

색 인코딩
웹 페이지는
주로 사람이 읽을 수 있는 UTF-8문자의 시퀀스로 이뤄지는 텍스트를 표현하므로
텍스트를 사용해 색을 표현할 방법이 필요하다.
URL 인코딩과 비슷한 방법으로 색을 인코딩한다.
웹에서는 색을 16진 트리플렛 으로 표현한다.
#뒤에 여섯자리 16진 숫자를 추가해 #rrggbb처럼 표현하는 방식
여기서 rr은 빨강, gg는 녹색, bb는 파란색의 값이다.
나는야 코린이