1. 인덱스
책의 마지막에 있는 "찾아보기"가 비유된다.
최대한 빠르게 찾아갈 수 있게 "ㄱ", "ㄴ", ...과 같은 순서로 인덱스도 정렬되어 있다.
DBMS의 인덱스는 항상 정렬 상태를 유지하고, 데이터 파일은 저장된 순서대로 별도의 정렬없이 저장한다.
2. Balanced-Tree 인덱스
가장 일반적인 인덱스 알고리즘으로, 값을 변형하지 않고 원래의 값을 인용해 인덱싱하는 알고리즘이다.
2-1. 구조 및 특성
최상위에
Root노드가 존재하고, 하위에 자식 노드가 붙어 있는 형태다.
- root node : 최상위에 단 하나 존재하는 노드
- leaf node : 가장 하위에 존재하며, 레코드 주소를 저장하는 노드
- branch node : root부터 leaf까지 중개자 역할을 하는 노드
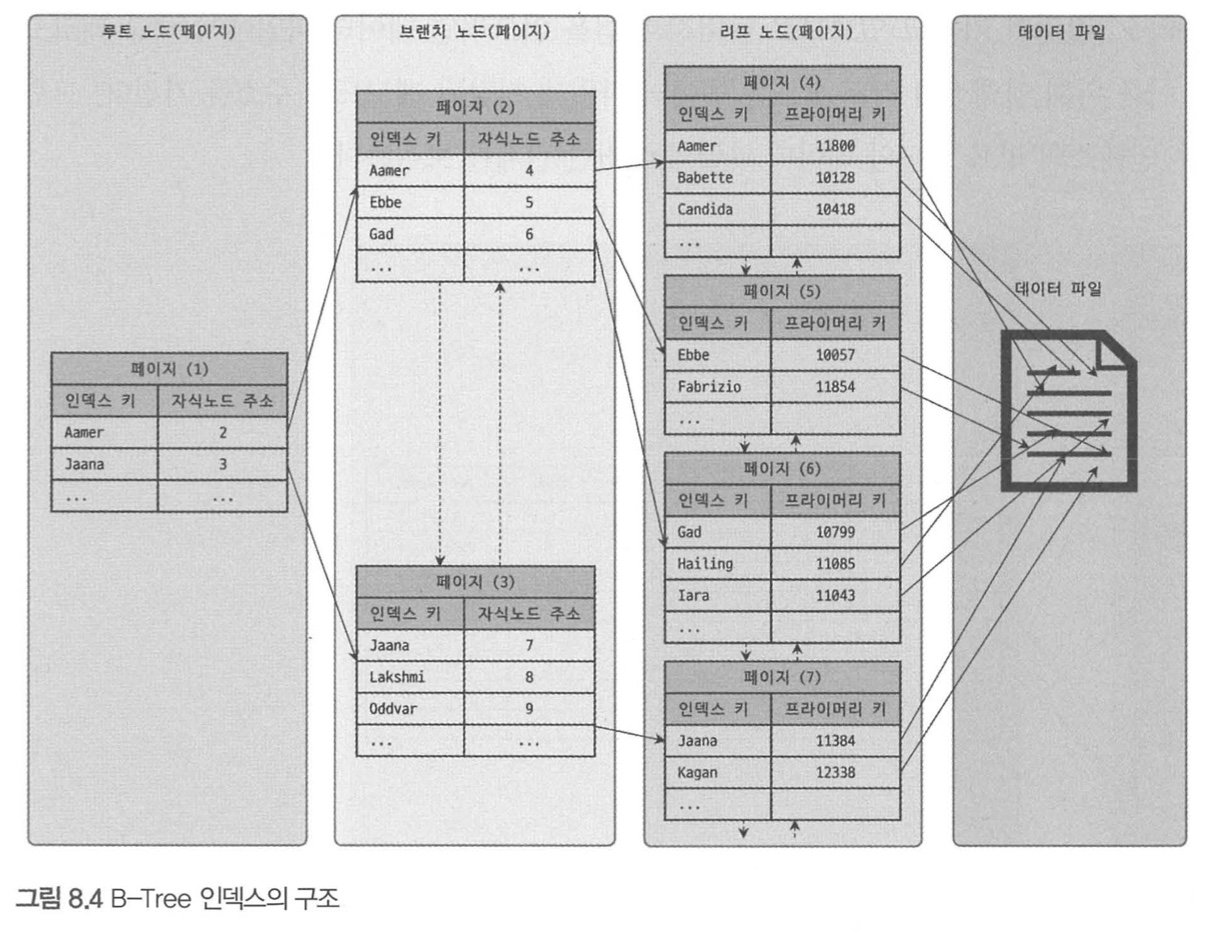
- 인덱스의 키 값은 모두 정렬돼 있지만, 데이터 파일의 레코드는 임의의 순서로 저장되어 있다.
- 레코드는 insert된 순서대로 저장되지만, 중간에 삭제되어 빈 공간이 생기면 그 다음의 insert시 재활용된다.
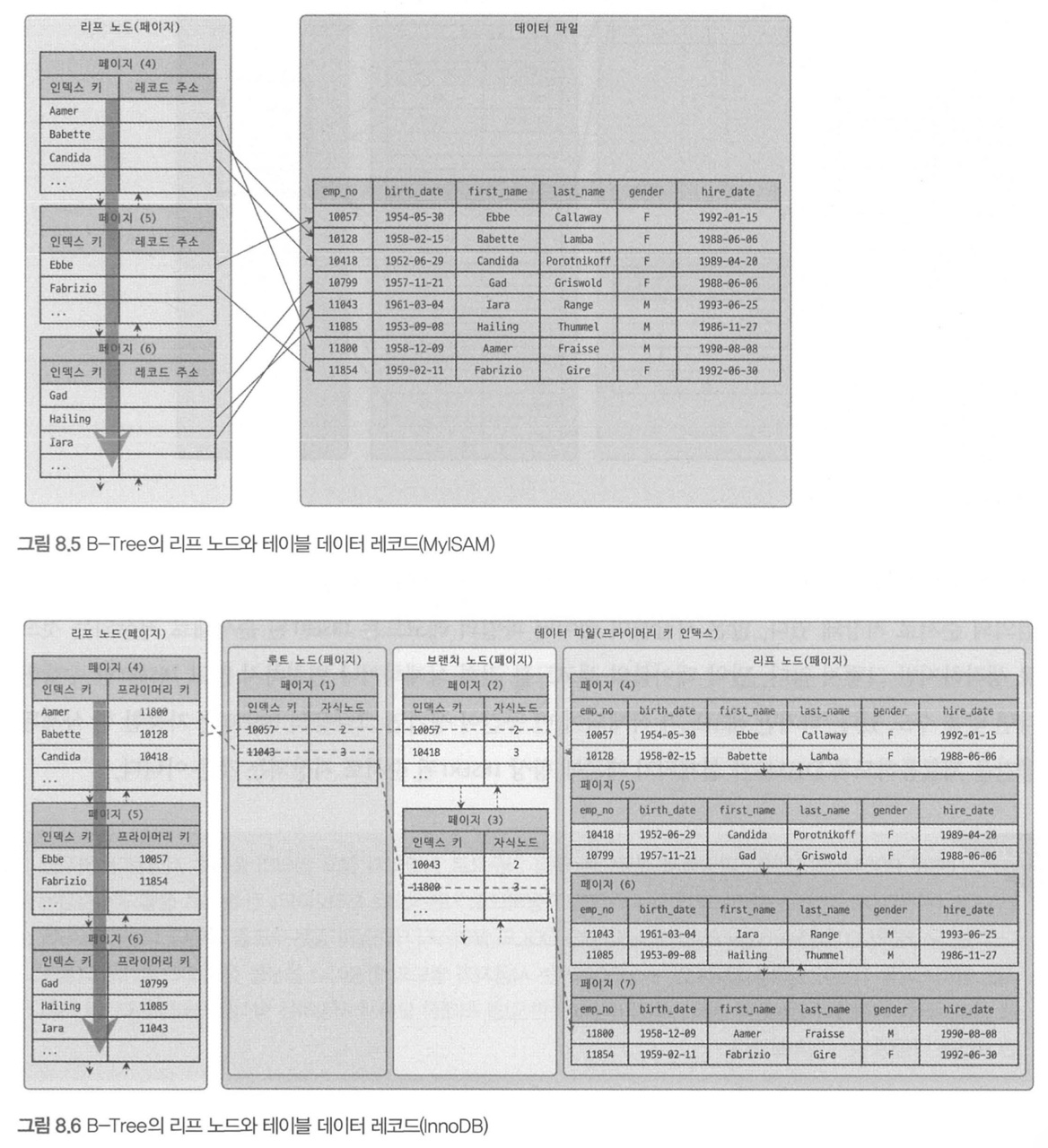
- MyISAM 테이블은 리프노드가 레코드 주소를 가진다.
- InnoDB 테이블은 논리적 주소(Primary Key값)을 가진다.
- 인덱스를 검색해 Primary Key 값을 확인
- Primary Key 인덱스를 검색해 레코드 주소를 확인
- 자세한 내용은 아래 클러스터링 인덱스 참조
인덱스 키 추가
- 저장될 값의 적절한 위치를 검색한다.
- B-Tree의 리프 노드에 키 값과 레코드의 정보를 저장한다.
- 리프 노드가 꽉차면, 리프 노드를 split한다. 이는 상위 브랜치 노드까지 처리 범위가 늘어난다. (쓰기 작업에 비용이 많이 드는 이유)
- 추가에 따른 비용 계산
- 인덱스가 없는 경우를 1이라고 가정하면,
- 인덱스가 있으면 1.5정도로 예측한다.
인덱스 키 삭제
- 키 값이 저장된 리프 노드를 탐색해서 삭제 마크한다.
- 삭제 마킹된 공간을 방치하거나 재활용한다.
인덱스 키 변경
- 키 값을 삭제한다.
- 새로운 키 값을 추가한다.
인덱스 키 검색
- 리프 노드까지 이동하면서 비교 작업을 수행한다.
- select뿐 아니라 update/delete를 처리하기 위해 레코드를 먼저 검색하는 경우도 사용된다.
- 인덱스가 사용되는 경우
- 100% 일치 검색
- prefix 일치 검색(suffix불가)
- 부등호 비교 조건
2-2. 인덱스 키 값의 크기
Page
- InnoDB에서 데이터를 저장하는 기본 단위로 디스크의 읽기/쓰기의 작업 단위다.
- 인덱스도 페이지 단위로 관리되며, 루트/브랜치/리프 노드를 구분하는 기준이다.
2-3. B-Tree의 자식 노드 갯수 계산하기
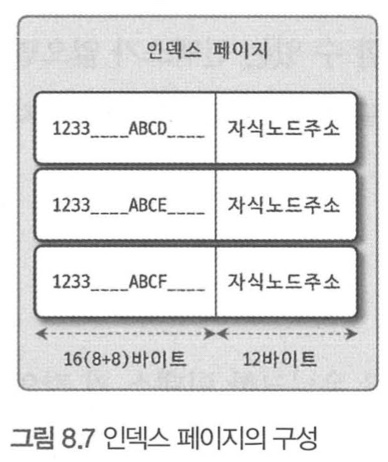
자식 노드 갯수 = 페이지크기 / ( 인덱스 크기 + 자식노드 주소 크기)
- 페이지 크기
- Default : 16KB
- MySQL 5.7 버전부터 InnoDB 페이지 크기를 innodb_page_size 변수를 이용해 4KB ~ 64KB 사이의 값으로 선택할 수 있다.
- 인덱스 크기 : 값에 따라 다름(아래의 샘플은 16KB라고 가정)
- 자식노드주소 : 페이지 종류별로 6B ~ 12B까지 다양하다.
계산해야하는 이유
16 * 1024 / (16 + 12) = 585개의 자식 노드를 가진다고 가정하면,
1,000개를 읽는 select에선 1번만 디스크로부터 읽으면 되지만,
500개를 읽는 select에선 최소 2번 디스크로부터 데이터를 읽어야한다.
2-4. 인덱스를 통한 데이터 읽기
인덱스 랜지 스캔
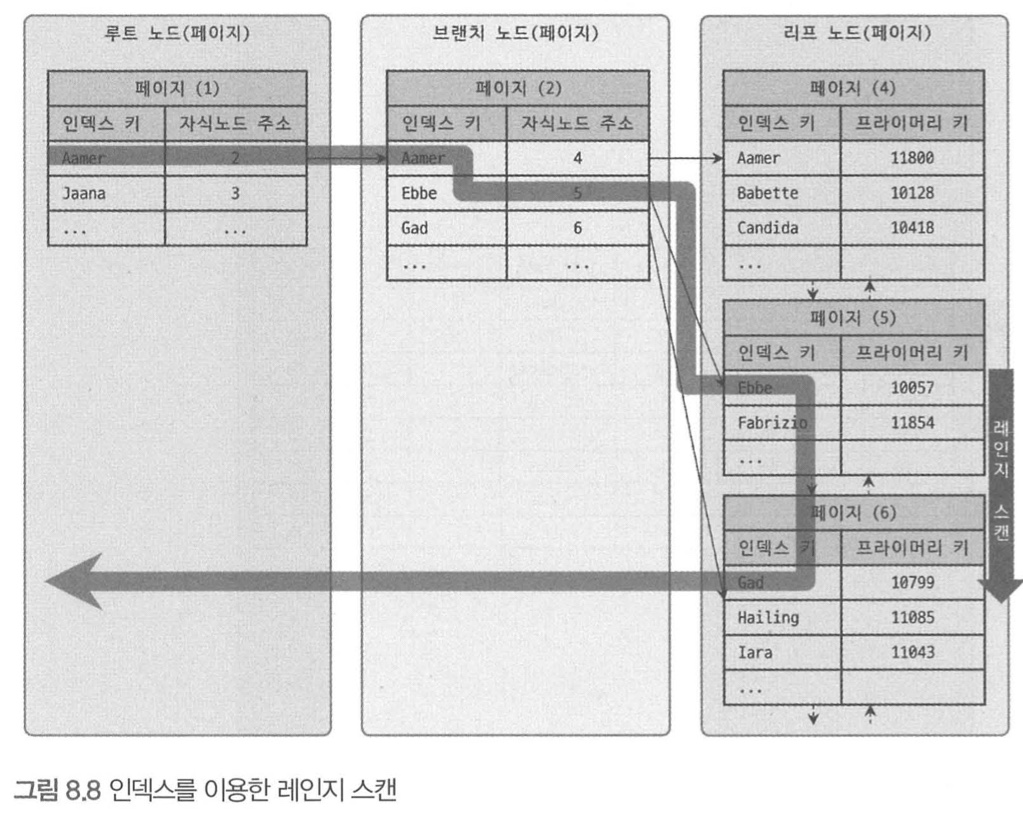
mysql> SELECT * FROM employees WHERE first_name BETWEEN 'Ebbe' AND 'Gad';- 인덱스의 접근 방법 중 가장 대표적인 접근 방식
- 검색해야 할 인덱스의 범위가 결정됐을 때 사용하는 방식
- 시작 위치만 찾으면, 리프 노드의 레코드만 순서대로 읽는다.
리프 노드에 저장된 레코드 한 건 한 건 단위로 랜덤 I/O가 발생한다.
인덱스 풀 스캔
- 인덱스의 처음부터 끝까지 모두 읽는 방식이다.
- 대표적으로 조건절에 사용된 칼럼이 인덱스의 첫 번째 칼럼이 아닌 경우다.
- index : A, B, C 칼럼순서
- 쿼리는 where B = ?와 같은 경우이다.
인덱스 스킵 스캔
mysql> ALTER TABLE employees
ADD INDEX ix_gender_birthdate (gender, birth_date);
/* 기존엔 index사용 불가 */
mysql> SELECT * FROM employees
WHERE birth_date >= '1970-01-01';
/* index 사용 */
mysql> SELECT * FROM employees
WHERE gender = 'M' and birth_date >= '1970-01-01';- MySQL 8.0부터 옵티마이저가 gender 칼럼을 건너뛰어 birth_date 컬럼만으로도 검색이 가능하게 해주는 기능이다.
- 동작 원리
- gender 칼럼의 유니크 값을 모두 조회
- gender 칼럼의 조건을 추가해서 쿼리를 다시 실행
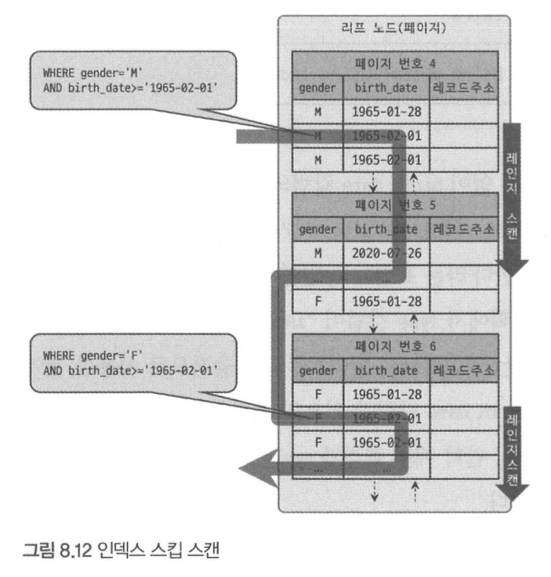
mysql> SELECT * FROM employees
WHERE gender = 'M' and birth_date >= '1970-01-01';
mysql> SELECT * FROM employees
WHERE gender = 'F' and birth_date >= '1970-01-01';2-5. 다중 칼럼 인덱스
- 인덱스의 N번째 칼럼은 N-1번째 칼럼에 의존해 정렬된다.
- A칼럼 정렬 후, A칼럼 값이 동일하면 B칼럼 정렬 ...
2-6. 인덱스의 정렬
인덱스 생성 시점에 오름/내림 차순으로 정렬이 결정되고,
쿼리에 따라 데이터를 읽는 시점에 인덱스를 오름/내림차순으로 읽는다.
- MySQL 5.7 까지는 칼럼 단위로 정렬 순서 혼합이 불가능
- MySQL 8.0 부터 아래와 같은 정렬 순서를 혼합한 인덱스 생성 가능
mysql> CREATE INDEX ix_xxx ON employees (team ASC, user DESC);인덱스 스캔 방향
mysql> SELECT * FROM employees
ORDER BY first_name DESC
LIMIT 1;- 위 쿼리는 인덱스를 역순으로 접근해 첫 번째 레코드를 읽어온다.
역순 정렬의 단점
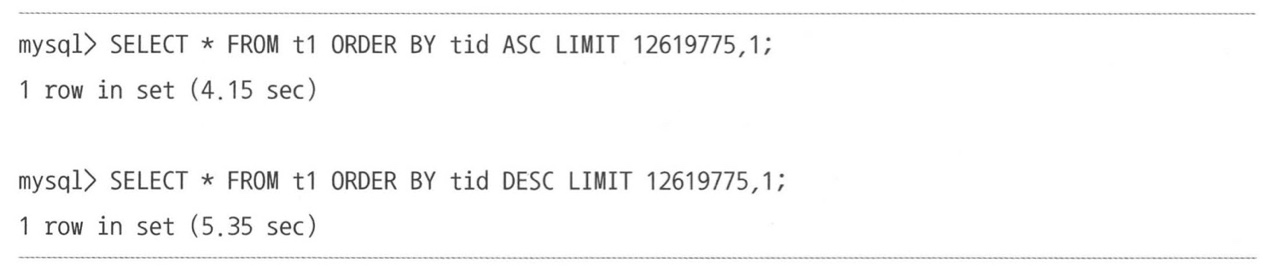
- 역순 정렬 쿼리가 정순 정렬 쿼리보다 28.9% 시간이 더 걸린다.
- InnoDB에서 역순 정렬이 느릴 수 밖에 없는 이유
- 페이지 잠금이 인덱스 정순 스캔에 적합한 구조이다.
- 페이지 내에서 인덱스 레코드가 단방향으로만 연결된 구조이다.
2-7. 인덱스 가용성과 효율성
비교 조건
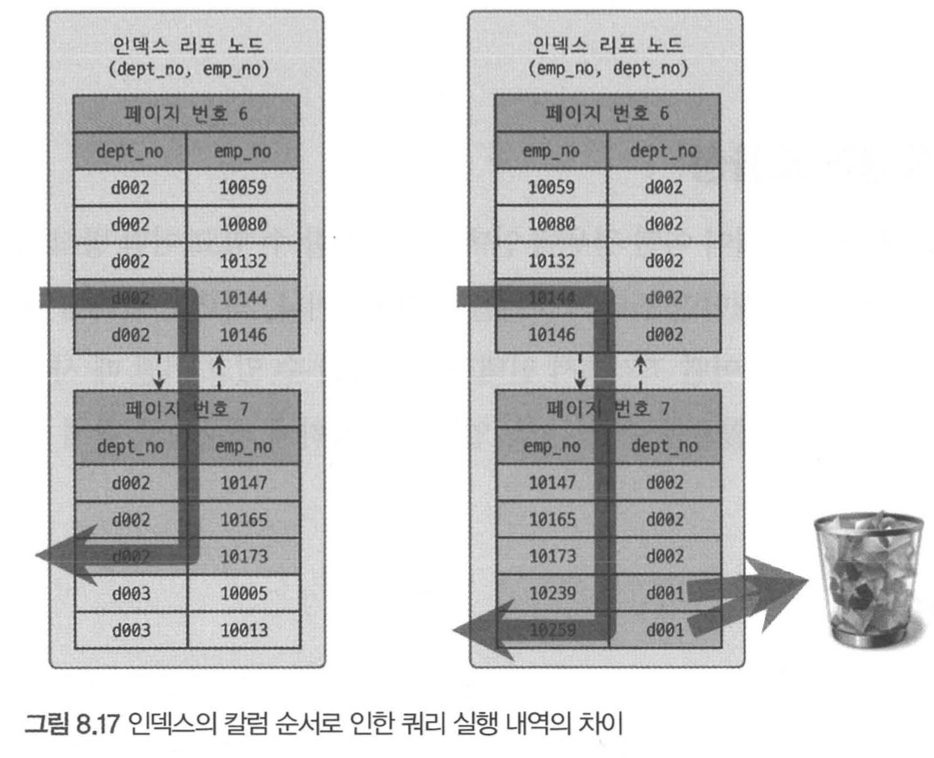
mysql> SELECT * FROM dept_emp
WHERE dept_no='d002' AND emp_no >= 10114;- case A : index(dept_no, emp_no)
- dept_no='d002' and emp_no >= 10114 시작 점을 찾는다.
- dept_no='d002'가 아닐 때까지 인덱스를 읽는다.
- 조건에 맞는 레코드를 찾는 데 꼭 필요한 비교 작업만 수행한다.
- case B : index(emp_no, dept_no)
- emp_no >= 10114 and dept_no='d002' 를 찾는다.
- dept_no='d002'인지 비교한다.
- dept_no의 값을 만족(필터링)하는 레코드를 가져온다.
- 필터링으로 인해 부가적인 비교 작업이 필요하다.
가용성과 효율성 판단
인덱스의 비교 작업을 줄여줄 수 없는 조건들이다.
- NOT-EQUAL
- WHERE column '<>'
- WHERE column NOT IN (10, 11, 12)
- WHERE column IS NOT NULL
- LIKE '%??'
- WHERE column LIKE '%hustle';
- 인덱스 칼럼 값이 변경된 후 비교
2-8. 이 외 알고리즘
B+Tree
B+Tree의 경우, leaf노드끼리 linkedlist로 연결되어 있어 선형 탐색이 가능하다.
Hash 인덱스 알고리즘
- 칼럼의 값으로 해시값을 계산해서 인덱싱하는 알고리즘
- 매우 빠른 검색을 지원
- 값을 변형해서 인덱싱하므로 prefix일치와 같은 검색은 불가
3. 클러스터링 인덱스
클러스터링 : 여러 개를 하나로 묶는다
테이블의 레코드를 비슷한 것(Primary Key기준)들끼리 묶어서 저장하는 형태로 구현되고, 비슷한 값들을 동시에 조회하는 경우가 많다는 점에 착안됐다.
MySQL에서는 InnoDB 스토리지 엔진만 지원한다.
- 테이블의 Primary Key에 대해서만 적용된다.
- Primary Key값에 의해
레코드의 저장 위치가 결정된다. - Primary Key가 변경되면 레코드의 물리적 저장 위치가 바뀐다.
- Primary Key기반의 검색이 매우 빠르다.
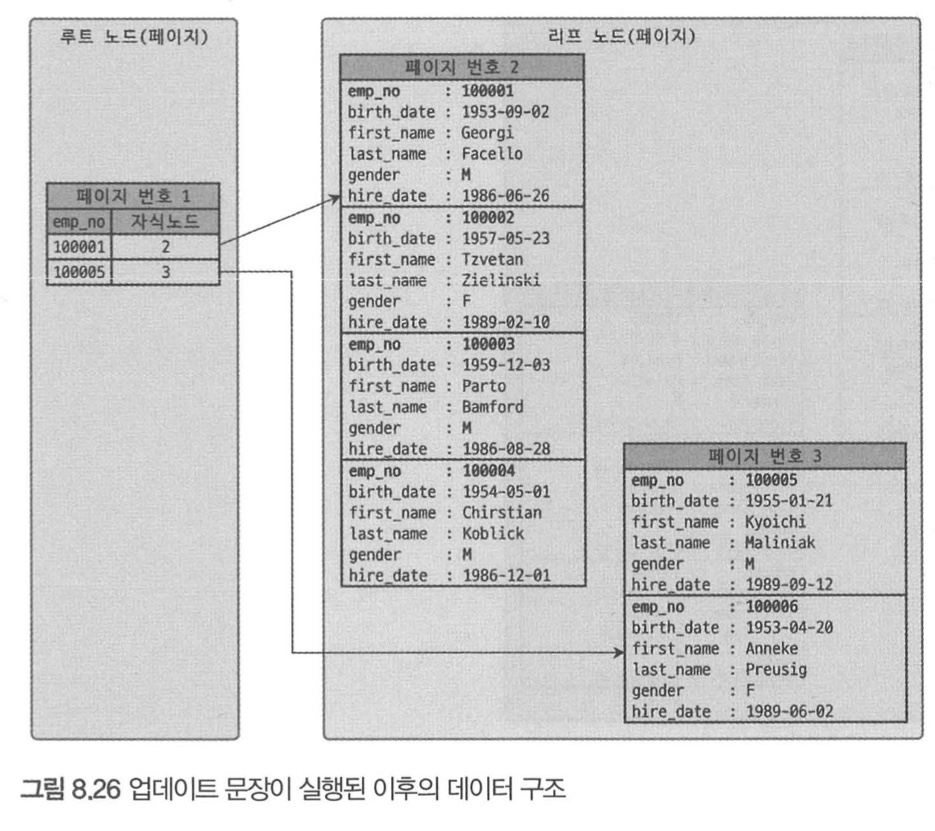
mysql> UPDATE table SET emp_no=100002 WHERE emp_no=100007;- B-Tree 리프 노드와 달리
레코드의 모든 칼럼이 같이 저장돼있다. - 위와 같이 update query를 실행하면, 레코드의 물리적 위치(페이지 위치)가 변경된다.
3-1. Primary Key가 없으면?
테이블에 Primary Key가 없으면, InnoDB는 아래의 순서대로 대체할 칼럼을 선택한다.
- Primary Key
- NOT NULL 옵션의 Unique Index 중 첫 번째 인덱스
- 내부적으로 auto_increment를 추가(사용자는 사용불가)
3-2. 세컨더리 인덱스에 미치는 영향
InnoDB의 경우, 세컨더리 인덱스가 실제 레코드를 가지고 있다면?
클러스터링 키 값이 변경될 때마다 레코드의 주소가 변경되고, 그 때마다 레코드 위치를 변경해야한다.
위의 오버헤드를 줄이기 위해
- 세컨더리 인덱스는 레코드 주소가 아닌 Primary Key를 저장

- MySIAM
- ix_firstname 인덱스를 검색, 레코드 주소 확인
- 주소의 레코드를 가져옴
- InnoDB
- ix_firstname 인덱스를 검색, Primary Key 값을 확인
- Primary Key 인덱스를 검색, 최종 레코드를 가져옴
3-3. 장/단점
장점
- Primary Key로 검색할 때 처리 성능이 매우 빠름(범위 검색은 매우 빠름)
- 테이블의 모든 secondary index가 primary key를 가지기 때문에 인덱스만으로 처리될 수 있는 경우가 많음(커버링 인덱스)
단점
- 테이블의 모든 secondary index가 primary key를 가지기 때문에 키 값이 클 경우 전체적으로 인덱스의 크기가 커짐
- secondary index를 통해 검색할 때 primary key로 다시 한 번 검색하므로 느림
- insert할 때 primary key에 의해 레코드의 저장 위치가 결정돼서 느림
- primary key를 변경할 때, 레코드를 delete/insert 작업이 필요해 느림
3-4 주의사항
- primary key가 커지면 secondary index도 자동으로 커짐
- 아래는 5개의 secondary index를 가지는 테이블의 경우

primary key 고려사항
- auto-increment보다는 업무적인 칼럼으로 생성
- primary key로 검색할 때, 클러스터링 되어 있기 때문에 매우 빠른 처리 기대
- 따라서, 레코드를 대표할 수 있다면 primary key로 설정
- primary key는 반드시 명시할 것
- 아무것도 설정하지 않아도 내부적으로 auto_increment 생성
- 내부적으로 명시했을 때와 차이가 없기 때문에 명시하고, 사용할 것을 추천
- auto-increment를 인조 식별자로 사용할 경우
- secondary index가 필요한데, primary key가 큰 경우 auto-increment사용
4. 유니크 인덱스
결론 : 유일성이 꼭 보장돼야 하는 경우 생성하고, 아니면 세컨더리 인덱스를 생성하자.
유니크 인덱스는
- NULL 저장 가능하고,
- NULL의 경우 2개 이상 저장 가능
vs 세컨더리 인덱스
읽기
- 성능상 거의 차이가 없다.
- 하나의 값을 검색하는 경우, 실행 계획이 약간 다르다
쓰기
- 유니크 인덱스의 키는 중복된 값이 있는지 체크 과정이 더 필요
- 읽기 잠금을 사용
- 쓰기를 할 때는 쓰기 잠금을 사용
- 위 과정 때문에 데드락 자주 발생
- 따라서 세컨더리 인덱스보다 느리다
Reference
- Real MySQL 8.0
