[https://d3s0tskafalll9.cloudfront.net/media/images/E-2-3.max-800x600_mMmzi4T.jpg]
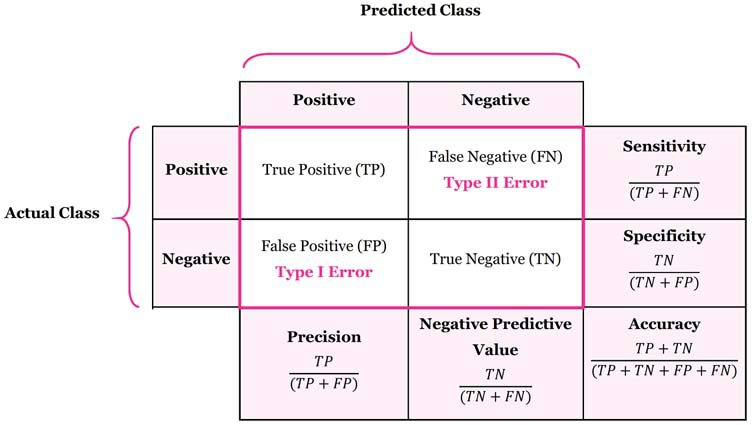
위의 그림은 confusion matrix를 나타낸다.
각 행은 실제 데이터 클래스를 나타내고, 각 열은 예측한 데이터의 클래스 값을 나타낸다.
- TP(True Positive) : 실제 Positive 데이터를 Positive하다고 예측한 경우
- TN(True Negative) : 실제 Negative 데이터를 Negative하다고 예측한 경우
----------위의 경우는 모두 제대로 예측한 경우들---------- - FP(False Positive) : 실제 Positive 데이터를 Negative하다고 예측한 경우 - 제 2 오류형
- FN(False Negative) : 실제 Negative 데이터를 Positive하다고 예측한 경우 - 제 1 오류형
실제 사례를 들어 설명하자면
- TP : 실제 환자에게 암 판정
- TN : 건강한 사람에게 건강하다 판정
- FP : 건강한 사람에게 암 판정 - 제 2 오류형
- FN : 실제 환자에게 건강하다 판정 - 제 1 오류형
이러한 수치로 계산되는 성능 지표 중 대표적으로 쓰이는 것은 Accuracy, Recall(Sensitivity), Precision, f1score 이다.
Accuracy는 전체데이터 중 올바르게 판단한 데이터개수의 비율이다.
위의 표에서 볼 수 있듯이 Precision과 Recall의 분자는 모두 TP이다. 이 값은 올바르게 판단한 값이므로 높을수록 좋다. 하지만 분모에 있는 FN과 FP는 잘못 판단된 값이므로 낮을수록 좋다.
즉, Precision과 Recall값은 클수록 좋다.
- Precision 이 크려면 negative한데 positive라고 판단하는 경우가 적어야,
- Recall이 크려면 positive한데 negative라고 판단하는 경우가 적어야 한다.
예를 들어 스팸메일을 거르는 모델에서 스팸메일을 positive, 정상메일을 negative라고 생각할때, 정상메일(negative)을 스팸메일(positive)로 판단하면 안되기 때문에 Precision이 중요한 지표가 된다.
하지만 암환자를 진단하는 모델에서는, 암환자(positive)를 건강하다(negative)고 판단하면 문제가 생기므로 Recall 지표가 더 중요하다고 볼 수 있다.
F1score는 Recall과 Precision의 조화평균이다. 이에 대한 내용은 따로 글을 남겨야 할 듯.

![[https://d3s0tskafalll9.cloudfront.net/media/images/E-2-3.max-800x600_mMmzi4T.jpg]](https://d3s0tskafalll9.cloudfront.net/media/images/E-2-3.max-800x600_mMmzi4T.jpg){kind=link}