[AI 미션코스 WEEK2]
하이퍼파라미터(Hyperparameter)
[개념]
최적의 훈련 모델을 구현하기 위해, 모델에서 설정하는 변수
- 하이퍼파라미터 튜닝 기법을 적용하여 훈련 모델의 최적값들을 찾을 수 있다.
[특징]
1. 개발자에 의해서 수동으로 설정할 수 있다.(임의 조정 가능)
2. 학습 알고리즘의 샘플에 대한 일반화를 위해 조절된다.
[예시]
학습률, 손실 함수, 일반화 파라미터, 미니배치 크기, 에포크 수(훈련 반복 횟수), 가중치 초기화, 은닉층의 개수, K-NN의 K값
각 개념들에 대한 역할 정리
[VOCAB_SIZE]: 모델이 처리할 수 있는 고유한 단어/토큰의 총 개수.NLP 작업에서 임베딩 레이어의 입력 차원으로 사용됨.
[EMBEDDING_DIM]: 단어를 고차원 벡터로 표현할 때 각 벡터가 가지는 차원의 크기.
[MAX_LEN]: 모델 입력으로 사용되는 시퀀스의 최대 길이. 길이가 이보다 짧은 시퀀스는 패딩(padding)되고, 긴 시퀀스는 잘린다.
[EPOCHS]: 에포크 수. 전체 학습 데이터셋이 신경망을 한번 완전히 통과하는 횟수를 의미.
[BATCH_SIZE]: 모델의 가중치를 업데이트하기 위해 한번의 반복동안 사용되는 학습 샘플의 수.
EPOCHS를 늘리면 무조건 성능이 좋아질까?
(과적합(overfitting)과 함께 설명!)
초기에는 성능이 향상되지만, 특정한 시점 이후에는 성능이 저하될 수 있다. EPOCHS를 늘릴수록 모델은 동일한 데이터셋을 더 많이 학습하게 된다.
그러나 일정 횟수 이상으로 증가하게 되면, 모델이 훈련 데이터에 포함된 불필요한 노이즈나 특정 패턴까지 과도하게 암기하게 된다. 따라서 훈련 데이터에 대한 성능은 높아지지만, 새로운 데이터에 대한 일반화 성능은 떨어지게 된다. 이를 과적합!이라고 한다.
Embedding이란?
사람이 쓰는 단어, 문장, 이미지 같은 다양한 데이터를 컴퓨터가 이해할 수 있는 숫자 벡터로 변환하는 과정.
[종류]
단어 임베딩, 문장 임베딩, 벡터 임베딩.
Pooling이란?
특징을 뽑아내는 과정. 해당하는 image data를 작은 size의 image로 줄이는 과정
[종류]
Max Pooling, Min Pooling, Mean Pooling.
[선형함수 VS 비선형함수 비교]
비선형함수를 활성화함수(relu, sigmoid)와 관련시켜 정리해보기!
선형함수: 입력변수 변화에 대해 출력값이 일정하게 비례하여 증가하거나 감소하는 직선적인 관계를 가지며, 비선형 함수는 이와 달리 입력변수 변화에 대해 출력변수의 변화량이 일정하지 않은 복잡한 관계를 갖는다.
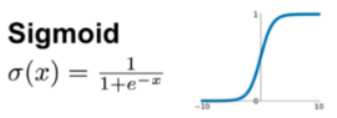
Sigmoid(시그모이드): S자 형태의 곡선 함수로, 입력값을 0과 1 사이의 값으로 압축. 그래프가 직선이 아닌 곡선.
ReLU (Rectified Linear Unit): 입력값이 0보다 크면 그 값을 그대로 출력하고, 0보다 작으면 0을 출력한다.
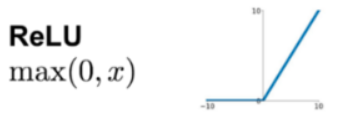
Dense Layer의 역할?
이전 레이어의 모든 뉴런이 다음 레이어의 모든 뉴런과 연결되어 복잡한 패턴을 학습하는 역할을 한다.
각 입력신호는 고유한 가중치와 곱해져 결과에 미치는 중요도를 조절한다.
예측, 분류, 회귀 등 다양한 작업을 수행하도록 돕는다.
주어졌던 코드에서 입력층, 은닉층, 출력층에 해당하는 코드 옆에 주석 달기
model = tf.keras.Sequential([
tf.keras.layers.Embedding(VOCAB_SIZE, EMBEDDING_DIM, input_length=MAX_LEN) #입력층,
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(64, activation='relu') #은닉층,
tf.keras.layers.Dense(1, activation='sigmoid')]) #출력층
model.summary()
Optimizer(최적화 함수)?
ML모델의 손실 함수를 최소화하는 방향으로 모델의 가중치(파라미터)를 업데이트하는 알고리즘이다.
학습 과정에서 모델의 성능을 개선하기 위해 필요한 최적의 매개변수를 찾아가는 과정을 수행하는 도구.
Loss Function(손실 함수)?
ML모델의 예측값과 실제 정답 사이의 차이를 수치화하여 모델의 성능을 평가하는 함수. 손실 함수의 값이 낮을수록 모델의 예측이 실제값에 더 가깝다는 것을 의미함.
Metrics(평가지표)?
ML 모델의 예측 성능을 정량적(숫자)으로 판단하기 위해 사용되는 기준들.
# 모델의 주요 설정값들을 미리 정의해줍니다.
VOCAB_SIZE = 2000
EMBEDDING_DIM = 128
MAX_LEN = 25
EPOCHS = 30
BATCH_SIZE = 32
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
history = model.fit(
train_X, train_Y,
epochs=EPOCHS,
batch_size=BATCH_SIZE,
validation_split=0.2,
verbose=1
)# epoch=30
import matplotlib.pyplot as plt
# 학습 결과에서 accuracy와 loss 가져오기
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(1, len(acc) + 1)
# ---- 그래프 그리기 ----
plt.figure(figsize=(12, 5))
# Accuracy 그래프
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.title('Accuracy over Epochs')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.grid(True)
# Loss 그래프
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.title('Loss over Epochs')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.grid(True)
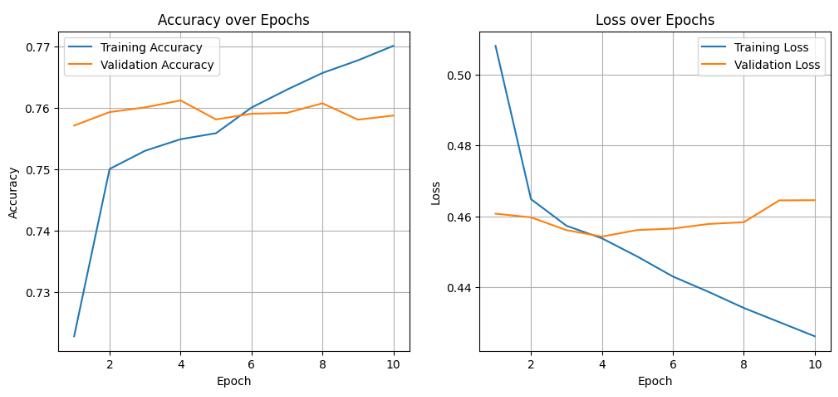
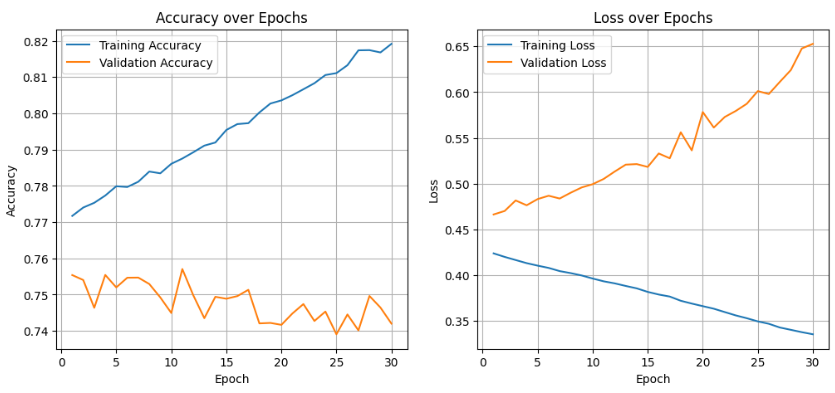
plt.show()시각화된 그래프를 바탕으로, 과적합(Overfitting)이 왜 발생했는가?
- epoch로 인해 training 횟수가 증가하고, train data에 대한 Accuracy가 증가하게 됐다.
오히려 이로 인해 test data에 대한 accuracy는 감소하는 것을 확인할 수 있다. - train data에 대해 모델이 맞춰지며 학습하게 되므로 일반화 성능이 떨어지게 된다.
시각화된 그래프처럼 Validation Accuracy는 감소하게 된다. - training loss는 감소하지만, validation loss은 증가하게 되며 과적합이 발생한다.
