
DJNAGO의 Select과 Prefetch
The only reason to use either of these methods is when a single large query is preferable to many small queries. Django uses the large query to create models in memory preemptively rather than performing on demand queries against the database
.
장고에는 select_related와 prefetch_related라는 메소드가 있다. 해당 함수들이 왜 있는지 알아보았는데, DJANGO의 공식 문서에 따르면, 하나의 큰 쿼리를 보내는 것이 작은 쿼리들을 여러개 날리는 것보다 더 선호되고, 이렇게 하나의 큰 쿼리로 DB의 쿼리를 줄이고 DJANGO 서버의 메모리에 임시저장하여 데이터베이스와의 통신을 줄이는 것이 더 효율적이라고 생각하는 것 같다. 이 철학의 정당성에 관해서는 DJANGO 측에서도 다양한 실험을 통해 산출한 결과이기 때문에, 모든 상황에서 다 이렇지는 않겠지만, 대부분의 경우에서 더 좋은 Performance를 낸다는 가정하에 이 DB Query의 수를 줄이는 방법에 대하여 얘기해볼까 한다.
Select_Related
select_related는 A 라는 모델이 B 라는 모델의 외부키 (Foreign Key)를 가지고 있을 때, A라는 모델에서 B모델에 대한 정보가 필요할 시, SQL의 join을 이용하여 B 테이블의 정보도 A 모델의 테이블과 붙여서 가져오게 된다. 이렇게 말로 백번 설명해봐야 하나의 예제를 통해 설명하는 것이 더 좋다는 것을 알기 때문에 실제 내 프로젝트때 사용했던 예시를 통해 설명하자면, 아래와 같은 모델이 있다.
- AqueryTool of Gitomp
- 비번 : m3k858
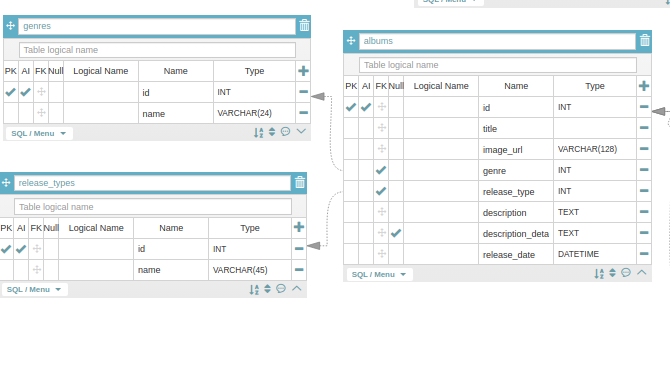
select_related의 효율성 실험 시나리오
- Album 모델이 있고 해당 모델은 genre라는 데이터를 foreignkey로 가지고 있다.
- 나는 "Album" 모델을 통해서 해당 앨범의 "장르"의 "이름"을 얻고 싶다.
- select_related가 적용됐을때와 안적용 됐을때를 같은 로직으로 실제 DB SQL을 확인해보자.
1. select_related 미적용시 DB 쿼리
여기서 만약 자신의 DJANGO에서 DB 쿼리가 안보인다고 한다면, 전에 포스팅한 Django- DB QUERY LOGGING 확인해주길 바란다.
# 먼저 album 모델과 genre 모델이 import되어 있다고 가정한다.
# from ~~~~ import Album, Genre
# test를 위해 준비한 View이다.
class TestView(View):
def get(self, request):
album_a = Album.objects.get(id=1)
genre_name = album_a.genre.name
return JsonResponse({"장르이름":genre_name},status=200)(0.001) SELECT `albums`.`id`, `albums`.`title`, `albums`.`image_url`, `albums`.`cd_image_url`, `albums`.`description`, `albums`.`description_detail`, `albums`.`release_date`, `albums`.`genre_id`, `albums`.`release_type_id` FROM `albums` WHERE `albums`.`id` = 1 LIMIT 21; args=(1,)
(0.001) SELECT `genres`.`id`, `genres`.`name` FROM `genres` WHERE `genres`.`id` = 2 LIMIT 21; args=(2,)2. select_related 적용시 DB 쿼리
# 먼저 album 모델과 genre 모델이 import되어 있다고 가정한다.
# from ~~~~ import Album, Genre
# test를 위해 준비한 View이다.
class TestView(View):
def get(self, request):
album_a = Album.objects.select_related("genre").get(id=1)
genre_name = album_a.genre.name
return JsonResponse({"장르이름":genre_name},status=200)(0.001) SELECT `albums`.`id`, `albums`.`title`, `albums`.`image_url`, `albums`.`cd_image_url`, `albums`.`description`, `albums`.`description_detail`, `albums`.`release_date`, `albums`.`genre_id`, `albums`.`release_type_id`, `genres`.`id`, `genres`.`name` FROM `albums` LEFT OUTER JOIN `genres` ON (`albums`.`genre_id` = `genres`.`id`) WHERE `albums`.`id` = 1 LIMIT 21; args=(1,)3. 결과해석
둘의 차이점은 오직 1번 primary key (pk)를 가지고 있는 앨범 데이터를 가져올 때, select_related()를 적용했나 안했나 뿐이다. 하지만, 그 결과의 차이는 2배에 해당하는 sql이 발생한다는 점이다. 지금 이 예시에서는 한개의 foreign_key의 하나의 column에 해당하는 데이터만 가져오기 때문에 감이 안 올수 있기 때문에 2개의 상황을 더 설명하자면 ...
3-1 하나의 foreign_key가 여러개의 column을 가지고 있을때
3-1번 같은 경우, 이렇게 코드가 작성 될 수 있다.
class TestView(View):
def get(self, request):
album_a = Album.objects.get(id=1)
genre_name = album_a.genre.name
genre_created_year = album_a.genre.created_year
genre_founder = album_a.genre.founder
genre_idealogy_year = album_a.genre.idealogy_year
# 기타 등등 ... 장르 테이블이 만약 총 10개의 column을 가지고 있다고 치면 ...
...이렇게 되었을때, 각 genre에 대한 데이터에 접근할 때마다 추가적인 쿼리가 발생하기 때문에, 외부키 Column의 숫자만큼 추가적인 query가 발생한다. 즉, 10개의 column면 10+1개의 쿼리가 발생하게 된다. (1개는 1번 앨범데이터 조회할때 발생)
하지만, 이 경우에서 select_related를 적용 시키면 1번 쿼리(1번 앨범 데이터를 조회할 때)를 날릴때 "1번 앨범의 장르에 해당하는 데이터 전부"를 SQL의 JOIN으로 가져오기 때문에 처음의 예제처럼 1개의 쿼리만 발생되게 된다. 즉, 1개 쿼리 vs 불특정 N개 쿼리인 것이다. 하지만, 여기서 끝이 아니다. 아래의 경우도 한번 보자 !
3-2 여러개의 foreign_key를 가진 테이블에서 전체 foreign_key의 데이터를 필요로 할때
3-2번 같은 경우, 이렇게 코드가 작성 될 수 있다.
class TestView(View):
def get(self, request):
album_a = Album.objects.get(id=1)
album_genre = album_a.genre.name
album_artist = album_a.artist.name
album_company = album.company.name
album_link = album.link.url
...
# 기타 등등 ... 총 10개의 foreign_key를 가지고 있다고 치면 ...
...이렇게 되었을 때도 위와 같이 모든 외부키에 해당하는 데이터를 가져와야 되기 때문에 외부키 하나당 추가적인 Query가 발생한다. 그렇기 때문에 위와 같은 로직을 구성해야 될 경우 추가적인 테이블을 조인해야된다.
class TestView(View):
def get(self, request):
album_a = Album.objects.select_related(
"genre",
"artist",
"company",
"link"
...
).get(id=1)이렇게 한다면 해당 1번 앨범에 해당하는 "앨범","아티스트","회사","링크" 테이블을 한번에 가져오기 때문에 3-1과 같이 1개의 쿼리 vs 불특정 다수의 N개 쿼리인 것이다.
3-3 종합
만약 그렇다면 3-1과 3-2와 같은 상황이 동시에 이루어 진다면 select_related 를 사용하지 않았을때 (M X N) + 1개의 쿼리가 발생되고, select_related를 사용한다면 총 1개의 DB 쿼리가 발생되는 것이다. 거기다가 만약 다수의 앨범을 조회하게 된다면 여기서도 곱하기가 또 되기 때문에 그 DB 쿼리의 숫자는 엄청나게 차이가 나게 되고 실제로 내가 프로젝트를 진행하면서 터미널 창을 꽉채운 sql과 1개의 SQL문을 눈으로 확인하니 해당 select_related를 사용하는 이유를 알 수 있었다.
번외 : 메모리 문제 및 테이블 조인
Select_related에 관해서 더 생각해보면, 첫번째로 메모리 문제를 생각할 수 있다. 결국, select_related로 가져오는 다른 테이블의 데이터는 임시저장되어, 데이터베이스에 쿼리를 보내지 않고 DJANGO 내부적으로 데이터를 뽑아내는 식이다. 그렇다면, 불필요한 데이터를 너무 많이 가져와서 메모리에 부하가 가해질 수 있기 때문에 해당 문제를 해결할 수 있는 only()나 values()나 defer()같은 메소드도 있는듯하다. 해당 메소드에 대해서 공식문서를 검색하면 설명이 잘 나와있기 때문에 필요할 때 읽어서 사용하는 식으로 해야겠다.
두번째로 생각한 것은 SQL에서 테이블이 JOIN된다고 해서 단순하게 합쳐진다고 생각하면 안된다. 내가 사용한 Mysql과 다른 관계형 데이터베이스도 다양한 Join을 통해서 적절하게 데이터를 참조해서 가져오는 방식이기 때문이다. 해당 Join에 대한 부분은 아직 내 이해가 완전하지 않기 때문에 참고할 수 있는 블로그 링크를 아래에 남겨두고, 추후에 포스트해야겠다.
Mysql Join 정리 : https://futurists.tistory.com/17
1부 끝 🌈
