
유니티에서 자동으로 가상환경을 만들어주는 방법을 찾아보다 Blockade Lab Skybox와 Genesis를 활용하여 프롬프트를 통해 가상환경을 만들어주는 방법을 찾게되었다.
Blockade Lab Skybox
링크 https://skybox.blockadelabs.com/
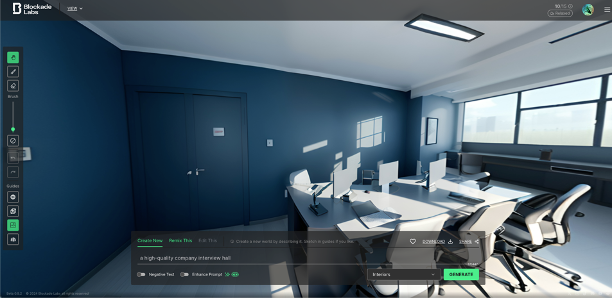
사용 결과
- 프롬프트 : a high-quality company interview hall
- 스타일 : interiors
Genesis
(GENESIS 패키지 사용하여 유니티에 적용)
링크 : https://github.com/julienkay/com.doji.genesis


상당히 높은 성능으로 뽑혀서 놀랐다
LDM3D 조사
다음으로 이 Blockade Labs는 어떤 모델을 사용하여 만들었는지 궁금하여 더 조사하게 되었다.
ldm3d 논문을 찾아보았을때 Blockade Lab과 협업했다는 것을 알 수 있었다. 또한 논문에서 파이프라인에서 유사한 렌더링 엔진으로도 projection할 수 있다고 함.
LDM3D의 잠재력을 보여주기 위해 생성된 2D RGB 이미지와 깊이 맵을 사용하여 TouchDesigner로 360° projection을 계산하는 애플리케이션인 DepthFusion을 개발했다. 사용자가 이전에는 불가능했던 방식으로 텍스트 프롬프트를 경험할 수 있는 몰입감 있고 매력적인 360° view를 생성함 이 방식은 TouchDesigner 플랫폼에 국한되지 않으며 파이프라인에서 RGB 공간과 깊이 색 공간을 활용할 수 있는 유사한 렌더링 엔진 및 소프트웨어 내에서도 복제될 수 있다.
내 생각은 논문에서는 ldm3d 를 제작하고 TouchDesigner라는 그래픽 툴로 DepthFusion이란걸 개발했는데 웹에서 보여주기위해서 Blocakde Lab에서 따로 또 만든거같다.
LDM3D ?
Stable Diffusion v1.4를 기반으로 하며 Latent Diffusion Model for 3D (LDM3D)를 제안한다. 원래 모델과 달리 LDM3D는 주어진 텍스트 프롬프트에서 이미지와 깊이 맵 데이터를 모두 생성할 수 있다. 이를 통해 사용자는 텍스트 프롬프트의 완전한 RGBD 표현을 생성하여 몰입감 있는 360° view에 생명을 불어넣을 수 있다.
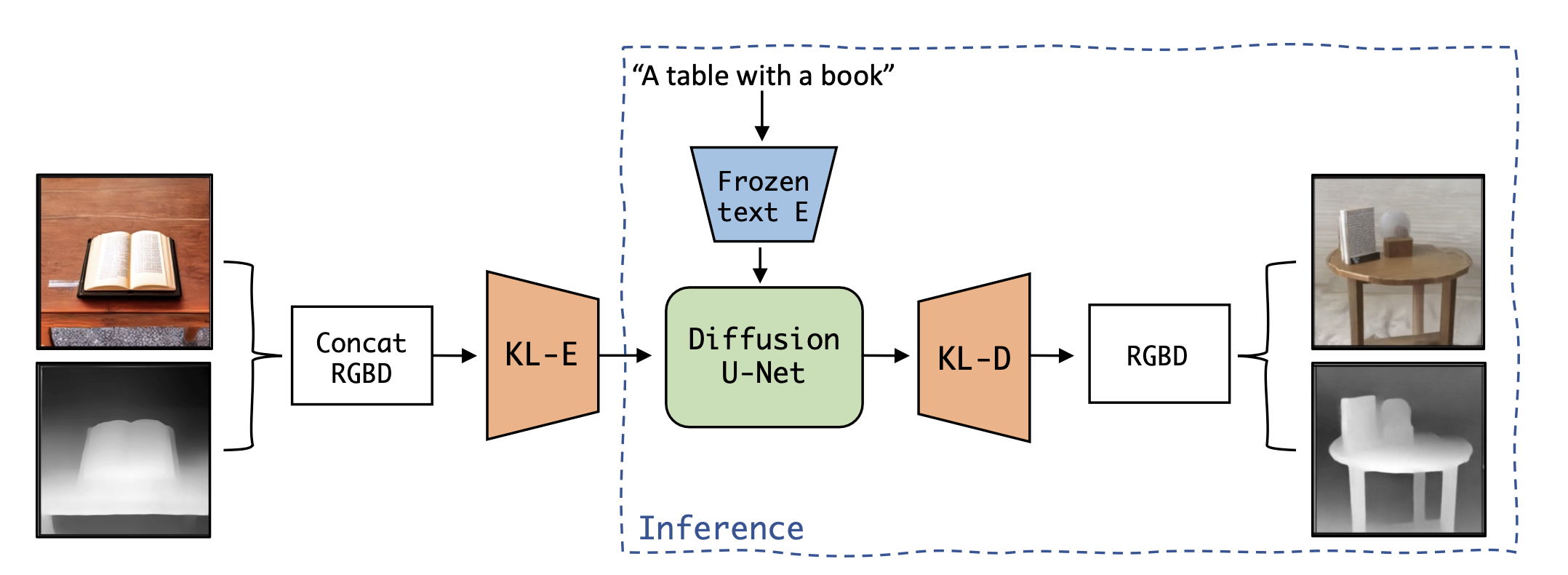
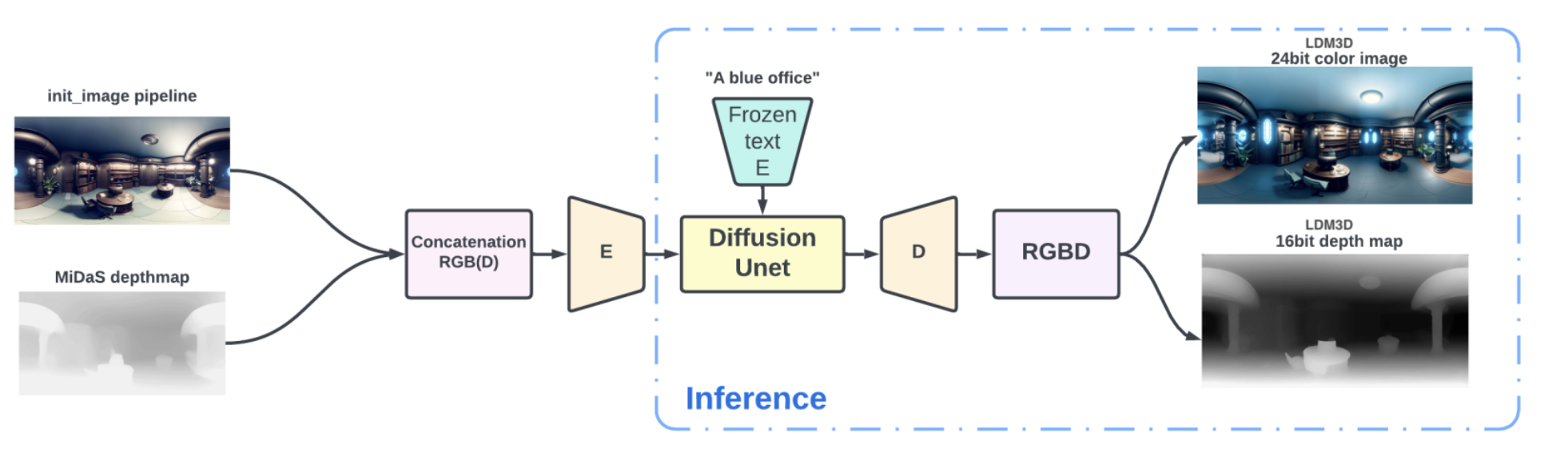
LDM3D overview
학습 및 출력 파이프라인
- 16-bit grayscale Depth map은 3-채널 RGB와 같은 깊이 이미지로 포장된 다음 채널 차원을 따라 RGB 이미지와 연결됩니다. 이 연결된 RGBD 입력은 수정된 KL-AE(KL-autoencoder)를 통해 전달되어 latent space에 매핑시킴.
- 모델에 사용된 KL-autoencoder (KL-AE)는 KL-divergence loss 항을 포함하는 VAE 아키텍처이다. 이 모델을 특정 요구 사항에 맞게 조정하기 위해 KL-AE의 첫 번째와 마지막 Conv2d 레이어를 수정한다. 이러한 조정을 통해 모델은 concat된 RGB 이미지와 깊이 맵으로 구성된 수정된 입력 형식을 수용할 수 있었다. 노이즈는 latent representation에 추가되고 DiffusionU-Net 모델에 의해 반복적으로 노이즈가 제거된다.
- Diffusion model은 주로 2D convolution layer로 구성된 U-Net backbone 아키텍처를 사용한다. Diffusion model은 학습된 저차원의 KL 정규화된 latent space에서 학습되었다. 픽셀 space에서 학습된 transformer 기반 diffusion model과 비교하여 보다 정확한 재구성과 효율적인 고해상도 합성이 가능하다.
- 텍스트 컨디셔닝을 위해 고정된 CLIP 텍스트 인코더가 사용되며 인코딩된 텍스트 프롬프트는 cross-attention을 사용하여 U-Net의 다양한 레이어에 매핑된다. 이 접근 방식은 복잡한 자연어 텍스트 프롬프트로 효과적으로 일반화되어 단일 패스에서 고품질 이미지와 깊이 맵을 생성하며 Stable Diffusion 모델에 비해 9,600개의 파라미터만 추가되었다.
- latent space에 디노이징된 출력은 KL 디코더에 공급되고 6채널 RGBD 출력으로 픽셀 공간으로 다시 매핑됩니다. 마지막으로 출력은 RGB 이미지와 16비트 그레이스케일 깊이 맵으로 분리된다.
ldm3d 파인튜닝 모델
사용한 모델은 ldm3d-pano
- ldm3d-pano : ldm3d-4c의 파인튜닝한 모델
- ldm3d-4c : ldm3d의 인코더를 파인튜닝해서 조금 성능개선한 모델
- ldm3d-sr : ldm3d생성된 이미지를 scale up 시키는 모델
https://huggingface.co/Intel/ldm3d-pano
ldm3d-pano 의 파인튜닝할떄쓴 데이터는 Text2Light를 사용하여 파라노마 이미지를 13852개의 훈련 샘플과 1606개의 검증 샘플을 포함하는 데이터 세트를 생성했습니다. 해당 샘플의 깊이 맵을 생성하기 위해 DPT-large를 사용 하고 캡션을 생성하기 위해 BLIP-2를 사용했습니다.
따라서 ldm3d-vr 논문에서는 ldm3d-pano + ldm3d-sr(스케일업해줌) 을 사용하여 만들어봐라 라고 제안합니다.
ldm3d-vr 논문의 요약은 다음과 같습니다. LDM3D-pano 및 LDM3D-SR을 포함하는 가상 현실 개발을 목표로 하는 확산 모델 제품군인 LDM3D-VR을 소개합니다. 이러한 모델을 사용하면 텍스트 프롬프트를 기반으로 파노라마 RGBD를 생성하고 저해상도 입력을 고해상도 RGBD로 각각 업스케일링할 수 있습니다. 우리의 모델은 파노라마/고해상도 RGB 이미지, 깊이 지도 및 캡션이 포함된 데이터 세트에서 기존의 사전 훈련된 모델을 통해 미세 조정되었습니다. 두 모델 모두 기존 관련 방법과 비교하여 평가됩니다.
ldm3d-pano 결과
output = pipe(
"realistic , high quality , interview room , office room”,
width=1024,
height=512,
guidance_scale=5.0,
num_inference_steps=50,
)



ldm3d-pano 문제점 : 해상도가 1024*512가 고정입니다. (변경 하면 이상하게나옴)
- 문제점 아래 사진은 2048*1024 크기로 파라미터를 수정하여 이미지를 생성하였다. 하지만 4개의 이미지를 붙여놓은 모습이다.

Blocakde Labs에서 생성된 파라노마 영상은 61443072 크기로 나와서 좋은 퀄리티의 이미지가 나오게 되는데. ldm3d-pano에서는 1024512가 최대 해상도 인것 같으므로 여기서 ldm3d-sr을 적용시킬려고 하였으나 huggingface 에서 제공한 모델이 오류가 발생하여 적용시키지 못했음.
