AlexNet/ ImageNet Classification with Deep CNN(2)
이전 내용에 이어 논문 나머지 부분을 추가 정리하겠습니다.
CNN과 같은 Neural Network의 문제점은 파라미터가 너무 많아지는 것입니다. 이렇게 파라미터가 너무 많아지게 되면 overfitiing이 될 수 있습니다. 이 논문에서는 Overfitting을 줄인 방식에 대해 2가지 내용을 설명하고 있습니다.
1번째, data argumentation입니다. data argumentation도 2가지로 나뉘게 되는데 우선 Image Translation and horizontal reflection(좌우반전)부터 설명드리겠습니다.
 기존 256x256 이미지를 horizontal reflection을 사용해 이미지의 양을 2배로 늘립니다. 그 후 이 256x256 이미지를 랜덤하게 crop(잘라) 224x224(논문에선 224로 나와있지만 convolution 계산에는 227이 맞음, 하지만 argumentation 내용상으로는 224가 맞음) 이미지로 만들어서 1024(상하좌우로 32(256-224)개씩 움직일수 있으니 32x32=1024)배 늘립니다. 따라서 총 2048배 증가하게 됩니다.
기존 256x256 이미지를 horizontal reflection을 사용해 이미지의 양을 2배로 늘립니다. 그 후 이 256x256 이미지를 랜덤하게 crop(잘라) 224x224(논문에선 224로 나와있지만 convolution 계산에는 227이 맞음, 하지만 argumentation 내용상으로는 224가 맞음) 이미지로 만들어서 1024(상하좌우로 32(256-224)개씩 움직일수 있으니 32x32=1024)배 늘립니다. 따라서 총 2048배 증가하게 됩니다.
테스트의 경우, 좌우반전으로 2배로 증가시킨 뒤 각 코너 4개와 중심 1개로 5배를 하여 총 10배의 argumentaion을 진행하였습니다. 그 후 각각의 이미지에 대한 softmax 결과 값을 평균을 내어 사용하였습니다.

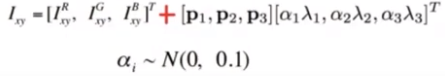 다음으로는 jittering입니다. 색깔에 변화를 주는 방식으로 RGB 픽셀 값을 랜덤하게 바꾸면 이상해질 수 있으므로 전체 이미지의 RGB 픽셀 값(즉 3x3) 공분산에서 고유값과 고유벡터를 구합니다. 그리고 위의 공식에 따라 나온 값을 각각의 픽셀에다가 더해줍니다. 위의 사진과 같이 여러가지 색으로 jittering이 됩니다.
다음으로는 jittering입니다. 색깔에 변화를 주는 방식으로 RGB 픽셀 값을 랜덤하게 바꾸면 이상해질 수 있으므로 전체 이미지의 RGB 픽셀 값(즉 3x3) 공분산에서 고유값과 고유벡터를 구합니다. 그리고 위의 공식에 따라 나온 값을 각각의 픽셀에다가 더해줍니다. 위의 사진과 같이 여러가지 색으로 jittering이 됩니다.
앞서 말씀드린 2가지 data argumentation을 통해 overfitting을 방지하고 Top1 error rate를 1% 이상 줄일 수 있었습니다.
2번째, DropOut입니다. 이 논문에서 DropOut은 0.5의 확률로 hidden neuron의 값을 0으로 바꿔줍니다. DropOut으로 0이 된 neuron들은 forward/backpropagation에 영향을 주지 않습니다. DropOut을 이용하면 neuron들 간의 의존성을 낮추어 co-adaption을 피할 수 있습니다(어떤 뉴런이 다른 특정 뉴런에 의존적으로 변하는 것으로 어느 시점에서 같은 층의 두 개 이상의 노드의 입력 및 출력 연결강도가 같아지면, 아무리 학습이 진행되어도 그 노드들은 같은 일을 수행하게 되어 불필요한 중복이 생기는 문제를 말함). 이 논문에서는 3개의 FC Layer 중에서 처음 2개에만 DropOut을 적용하고 테스트 시에는 DropOut을 하지 않고 결과에만 0.5를 곱하였습니다.
