파이썬 - 텍스트 요약 알고리즘
Text Summarization
- 텍스트 요약
글의 핵심적인 내용을 추출하여 보다 적은 문장 수의 글로 간추리는 것을 말한다.
크게 ,
-
추출적 요약
-
추상적 요약
- 추출적 요약
- 추출적 요약은 말 그대로 기존의 글에서 중요도가 높거나 핵심이 되는 문장 그대로 추출해서 요약글을 만드는 것이다. 즉 ,새로운 단어가 생겨나거나 새로운 문장이 생성되지 않는 요약이다.
2.추상적 요약
- 추상적 요약은 새로운 단어와 새로운 문장을 생성해서 요약을 하는 방법이다.
먼저 , 추출적 요약부터 시작해보도록 하겠다.
추출적 요약법에도 다양한 기계번역 모델이나 알고리즘이 있지만 , 가장 대표적인 것이 바로 TextRank이다.
Text Rank Model
구글의 PageRank 논문 - The PageRank Citation Ranking: Bringing Order to the Web 을 기반으로 한 알고리즘이다.
PageRank
하이퍼 링크를 가지는 웹페이지에 대해서 얼마나 참조가 됐는지 , 또는 유입이 되었는지 등으로 페이지의 순위를 매기는 알고리즘을 말한다.
간단하게 설명하자면,
하이퍼 링크를 가지는 웹 페이지에 대해서 얼마나 참조가 됐는지, 또는 유입이 되었는지 등으로 페이지의 순위를 매기는 알고리즘을 말한다.
즉 , 링크를 클릭할 확률로 그 순위를 매긴다고 한다.
다시 본론으로 들어와서,
TextRank는 PageRank의 알고리즘을 활용한 것으로 , 페이지의 개념을 단어의 개념으로 바꾼 알고리즘이다.
즉 , 텍스트로 이루어진 글에서 특정 단어가 다른 문장과 얼마만큼의 관계를 맺고 있는지를 계산하는 것이다.
TextRank:Bringing Order into Texts 논문에 따르면 TextRank는 그래프 기반의 랭킹 모델로 , 이러한 순위를 매기는 방법이 문단의 추출적 요약에 매우 효과적일 것이라 생각되어 개발했다고 한다.
그렇다면 ,
어떻게 순위를 매기는 것일까.
논문에 따르면 , 'voting' 또는 'recommendation'의 아이디어를 생각했다고 한다.
예를 들어 , 한 vertex(node) 가 다른 vertex와 연결된다면 , 이를 연결한 vertex에 투표(casting a vote) 했다고 본다. 이렇게 다른 vertex에 투표하는 수가 많아질 수록 , 특정 vertex 의 중요도는 점점 커지게 된는 것이다.
그리고 이 투표 수는 그 vertex의 순위를 매기게 되는 값이 되는 것이다.
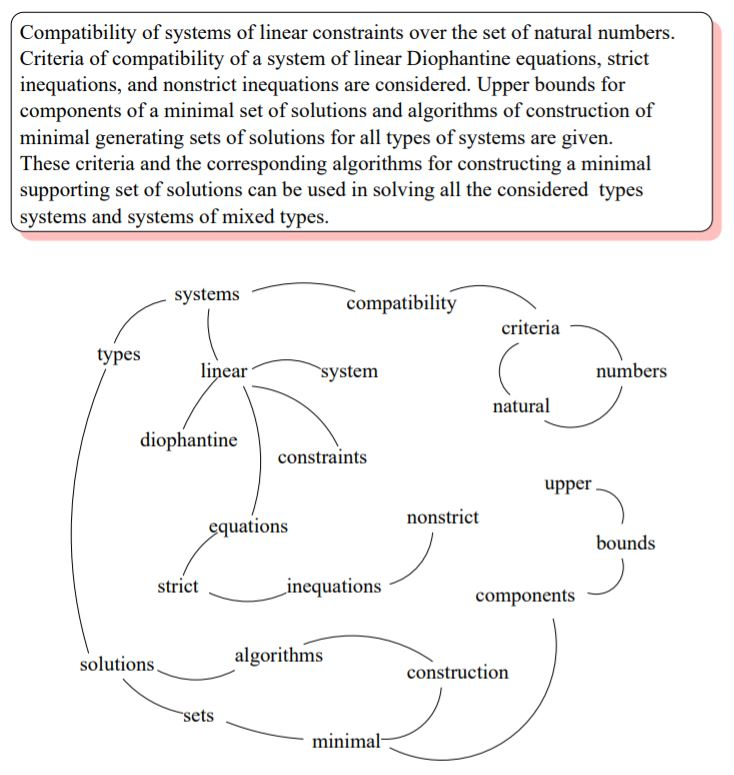
위 이미지는 상단에 주어진 글에 대해 텍스트 간 관계를 나타낸 그래프로 그린 샘플 이미지이다.
내용과 그래프를 비교해보면 각 문장에서 단어 간의 관계를 선으로 연결하는 모습을 살펴볼 수 있는데 , 순위는 다음과 같은 수식에 의해 매긴다고 한다.
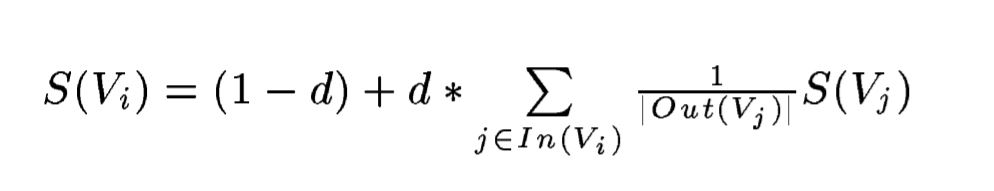
위 식에서 , S가 최종적으로 구하려는 TextRank값을 의미하고 , Wji는 해당 문장이나 단어 i와 j사이의 가중치를 의미한다. (wji 관련한 수식은 논문에 기입)
이렇게 vertex마다 위 식을 통해 TextRank값을 구하고 나면 , 그 크기대로 정렬을 해서 순위를 매기게 된다고 한다.
TextRank 구현하기 - Python
파이썬에서 구현할 수 있는 모듈을 제공한다.
- colab 에서 진행
from gensim.summarization.summarizer import summarize - 코드 설명
이 코드는 Gensim 라이브러리의 summarization 모듈에서 summarize 함수를 불러와 사용하는 것입니다. Gensim은 Python에서 자연어 처리와 토픽 모델링을 위한 라이브러리 중 하나입니다.
summarize 함수는 텍스트 요약에 사용됩니다. 이 함수는 주어진 텍스트에서 중요한 문장들을 추출하여, 원래 텍스트보다 더 짧은 요약된 버전을 생성합니다. 이것은 대량의 텍스트를 처리할 때 요약된 버전을 빠르게 검토할 수 있도록 도와줍니다. 이 함수는 특정 요약 방법을 사용하여 요약문을 생성합니다. 예를 들어, "summarize(text, ratio=0.5)"는 입력 텍스트의 50% 정도를 요약된 문장으로 출력합니다.
error
- ModuleNotFoundError: No module named 'gensim.summarization'
해결을 위해선 ,
!pip install gensim이 필수이나 , gensim의 버전이 새로운 버전으로 업그레이드 되었을 수 있다.
이 경우에는 "summarization" 모듈이 최신 버전에서 더 이상 사용되지 않을 경우가 있으므로 , 예전 버전을 사용해야 된다.
!pip install gensim==4.0.1
버전을 install하자.
그래도 안된다면 , 파이썬의 다른 라이브러리를 사용하자.
1. Sumy
Sumy는 자연어 처리 라이브러리 중 하나로 , 다양한 요약 기술을 지원한다.
이중에서 , "LexRank" 알고리즘을 사용하여 텍스트 데이터를 요약하는 기능을 제공한다.
- import sumy
!pip install sumyfrom sumy.summarizers.lex_rank import LexRankSummarizer
from sumy.nlp.tokenizers import Tokenizer
from sumy.parsers.plaintext import PlaintextParser- 텍스트 데이터를 가져오는 함수
def get_text(filename):
with open(filename, 'r') as f:
text = f.read()
return text- 텍스트 요약 함수
def summarize_text(text, sentences_count=3):
parser = PlaintextParser.from_string(text, Tokenizer('english'))
summarizer = LexRankSummarizer()
summary = summarizer(parser.document, sentences_count)
summary = [str(sentence) for sentence in summary]
return ' '.join(summary)
filename = "/content/junjoypython.txt"
text = get_text(filename)- 결과값
이제 greeting 메서드를 살펴보자. maria = Person('마리아', 20, '서울시 서초구 반포동') 즉 , 다음과 같이 Person 의 괄호 안에 넣은 값은 init 메서드에서 self 뒤에 있는 매겨변수에 차례대로 들어간다. 더 나은 개발이 되길 바라며:) 심준보 develope / exercise / fashion 다음 포스트 Python - 예외 처리 사용하기 0개의 댓글 댓글 작성 Python - 예외 처리 사용하기 mmm.junjoy.log 로그인 mmm.junjoy.log 로그인 Python - 예외 처리 사용하기 sjb2010·2023년 1월 16일 0 python 0 Python 목록 보기 2/6 Python - 예외 처리 사용하기 예외(exception)란 코드를 실행하는 중에 발생한 에러를 뜻합니다.
요약본이 다소 아쉬운 부분이 있어 , 새로운 요약 라이브러리 하나 더 해보려고한다.
더 나은 개발이 되길 바라며:)
