
안녕하세요 !
오늘은 백준 - 그룹 단어 체커 문제를 다뤄보도록 하겠습니다.
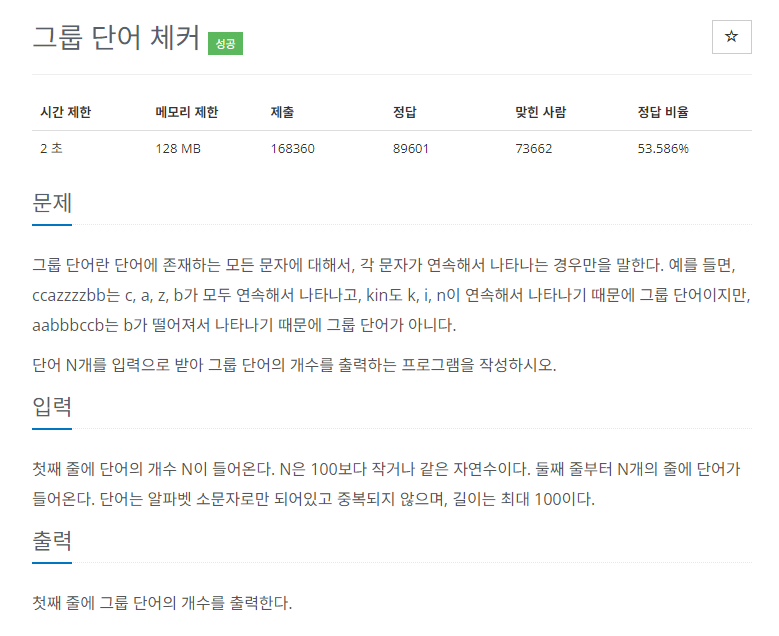
문제 설명
해결 방법
제가 문제를 해결한 방법은 다음과 같습니다.
- 단어의 수를 입력받는다.
- 입력받은 단어의 수만큼 단어를 입력받는다.
- 딕셔너리를 만들고 그 딕셔너리에 알파벳이 없으면 알파벳을 key로 인덱스를 value 값으로 넣는다.
- 딕셔너리 value 값을 통해 알파벳이 연속되는지 확인한다.
- 알파벳이 연속되지 않는 경우 그룹 단어가 아니기 때문에 카운트를 해준다.
- 전체 단어의 개수에서 그룹 단어가 아닌 개수를 빼주고 출력한다.
먼저 단어의 수를 입력받습니다.
num = int(input())
다음 입력받은 단어의 수만큼 단어를 입력받습니다.
for i in range(num): str = sys.stdin.readline()
그룹 단어인지 확인하기 위해 딕셔너리를 만들고 그 딕셔너리에 알파벳이 없으면 알파벳을 key로 인덱스를 value 값으로 넣습니다.
dict = {} for x in range(0, len(str)): if str[x] not in dict: dict[str[x]] = x
그 다음, 딕셔너리 value 값을 통해 알파벳이 연속되는지 확인한다.
딕셔너리에 해당 알파벳이 있다면 해당 알파벳의 value (인덱스 값)과 지금 알파벳의 인덱스 값이 1이 더 클 경우 알파벳의 value (인덱스 값)을 갱신한다.
else: pre = dict[str[x]] comp = pre + 1 if comp == x: dict[str[x]] = x
알파벳이 연속되지 않는 경우 그룹 단어가 아니기 때문에 카운트를 해준다.
딕셔너리에 해당 알파벳이 있지만 해당 알파벳의 value 값이 지금 알파벳의 인덱스 값과 2 이상으로 차이가 나는 경우 그룹 단어가 아니기 때문에 카운트한다.
else: cnt += 1 break
마지막으로 전체 단어의 개수에서 그룹 단어가 아닌 개수를 빼주고 출력합니다.
print(num - cnt)
전체 코드
import sys
num = int(input())
cnt = 0
for i in range(num):
str = sys.stdin.readline()
dict = {}
for x in range(0, len(str)):
if str[x] not in dict:
dict[str[x]] = x
else:
pre = dict[str[x]]
comp = pre + 1
if comp == x:
dict[str[x]] = x
else:
cnt += 1
break
print(num - cnt)
말하는 감자에서 개발자로 ( ´͈ ᵕ `͈ )◞♡