LSH(Locality-Sensitive Hashing)
유사한 벡터들을 같은 해시 버킷에 저장하는 기법이다.
대부분의 해시 함수들과는 달리, LSH 해시 함수는 해시 충돌을 최대화하는 것이 목적이다.
LSH에서의 검색
- 모든 벡터를 해시된 벡터로 인덱싱한다.
- 쿼리 벡터를 입력한다. 쿼리 벡터 또한 동일한 LSH 함수로 해싱된다.
- 해싱된 쿼리 벡터를 다른 모든 해시 버킷들과 해밍 거리(Hamming distance) 기준으로 비교하여 가장 가까운 버킷을 식별한다.
- 해밍 거리(Hamming distance)
- 같은 길이의 두 문자열에서, 같은 위치에서 서로 다른 기호들이 몇 개인지를 센다.
- 예를 들어, "1011101"과 "1001001"의 해밍 거리는 2이다. (세 번째, 다섯 번째 자리가 다름)
LSH에는 여러 버전이 존재하며, 각각 다른 해시 구성 방식과 거리/유사도 측정 기준을 사용한다.
가장 많이 사용되는 두 가지 접근 방식은 다음과 같다:
- Shingling, MinHashing, 그리고 banded LSH (전통적인 방식)
- Random Hyperplanes 기법 — 내적(dot-product)과 해밍 거리(Hamming distance)를 함께 사용
Random Hyperplanes
예시를 들어서 random hyperplanes 접근법을 이해해보자.
쿼리 벡터 xq가 주어졌고, xb 배열에서 가장 가까운 k개의 이웃을 찾고 싶다.
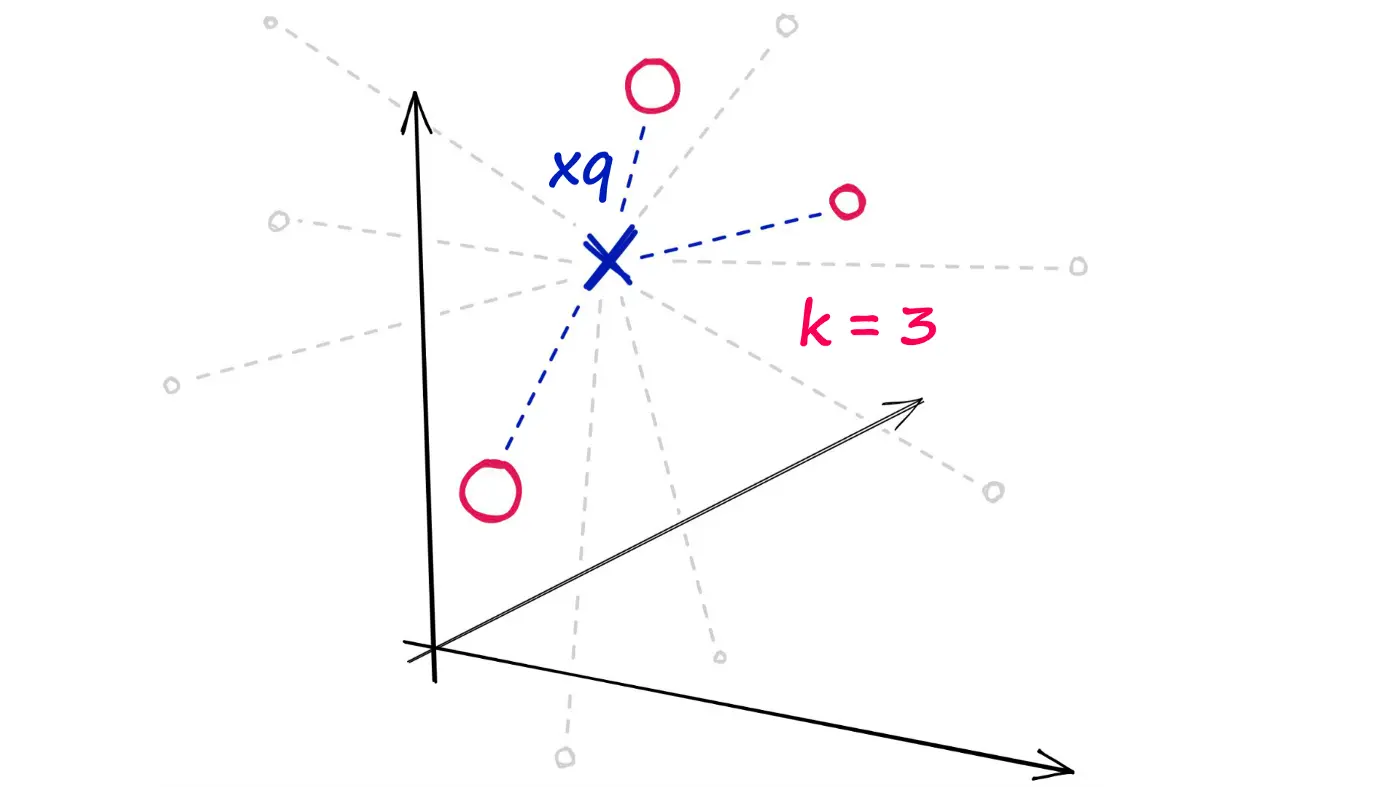
Random projection 방식을 사용하여 고차원의 벡터들을 저차원의 이진(binary) 벡터로 바꿀 것이다. 이진 벡터들을 얻게 되면, 벡터들 간의 거리를 해밍 거리를 사용하여 측정할 수 있다.
Hyperplane 생성
하이퍼플레인은 데이터 포인트들을 분리하기 위해 사용된다.
- 하이퍼플레인의 음수 쪽(negative side)에 위치한 데이터 포인트에는 0을 할당하고
- 양수 쪽(positive side)에 위치한 데이터 포인트에는 1을 할당한다.
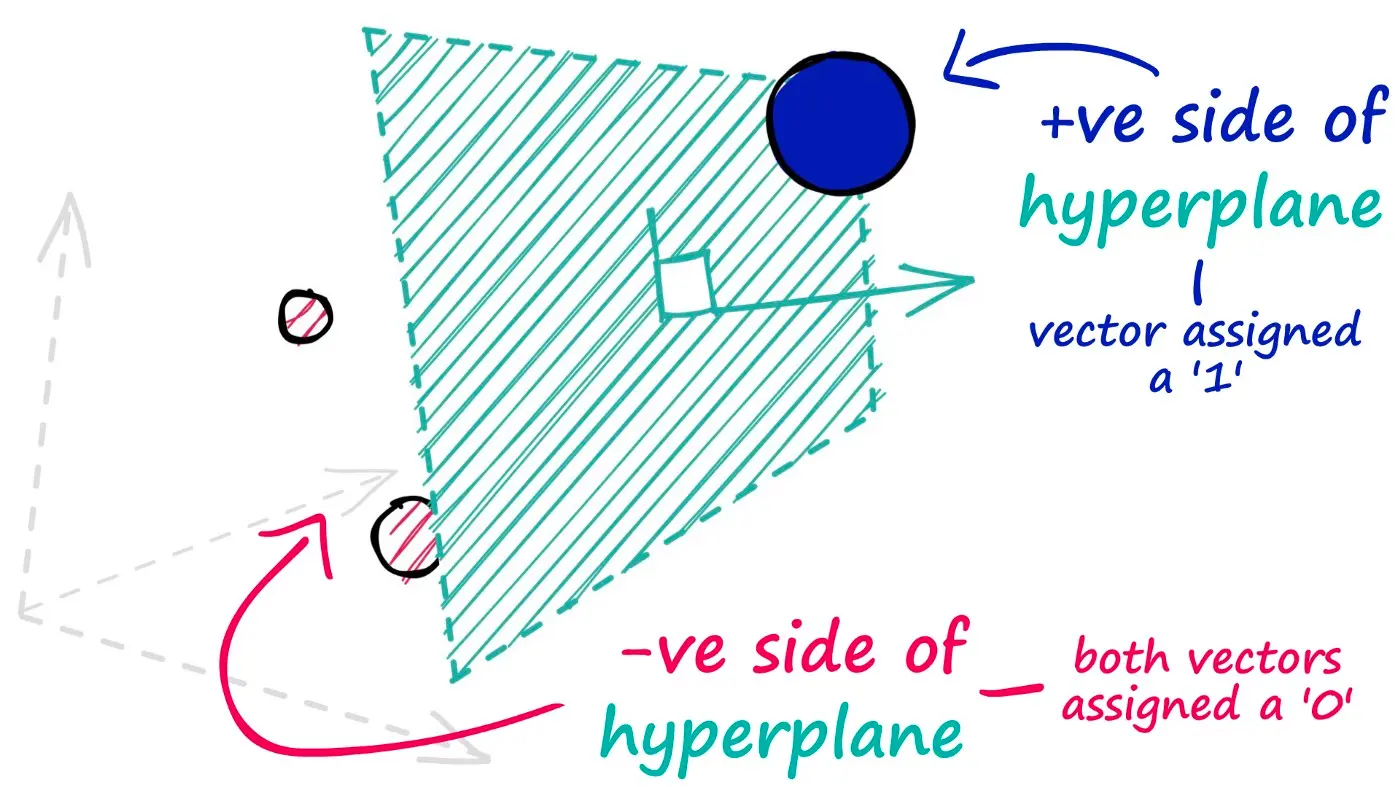
우리의 데이터 포인트가 하이퍼플레인의 어느 쪽에 위치하고 있는지는 하이퍼플레인의 법선 벡터(normal vector)로 알 수 있다.
- 데이터 포인트 벡터와 법선 벡터가 같은 방향을 가질 경우 내적(dot product) 결과는 양수가 된다.
- 방향이 다를 경우 내적 결과는 음수가 된다.
- 직각일 경우 내적 결과는 0이지만 해당 벡터를 음의 방향(0을 할당)으로 처리한다.
단 하나의 이진 값만으로는 두 벡터의 유사성을 판단하기 힘들다. 하지만, 하이퍼플레인의 수를 늘려가면 벡터가 가지는 정보의 양은 빠르게 증가한다.
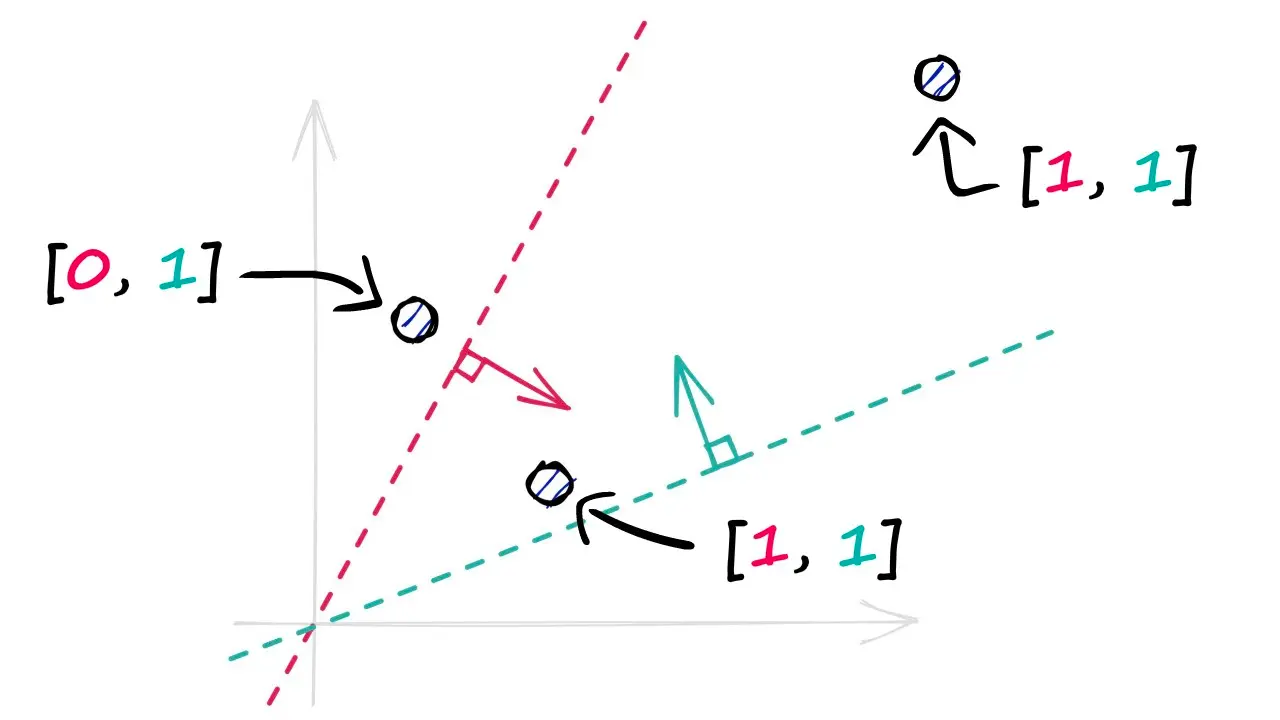
이러한 하이퍼플레인들을 사용해 벡터들을 저차원 공간으로 사영(projection)하면, 우리는 새로운 해시 벡터를 얻게 된다. 위 그림에서는 2개의 하이퍼플레인을 사용하고 있지만, 실제 상황에서는 훨씬 더 많은 하이퍼플레인이 필요하다.
만약 a, b, c 세 벡터가 있고 하이퍼플레인이 4개라면, 아래 그림과 같이 사영될 수 있을 것이다.
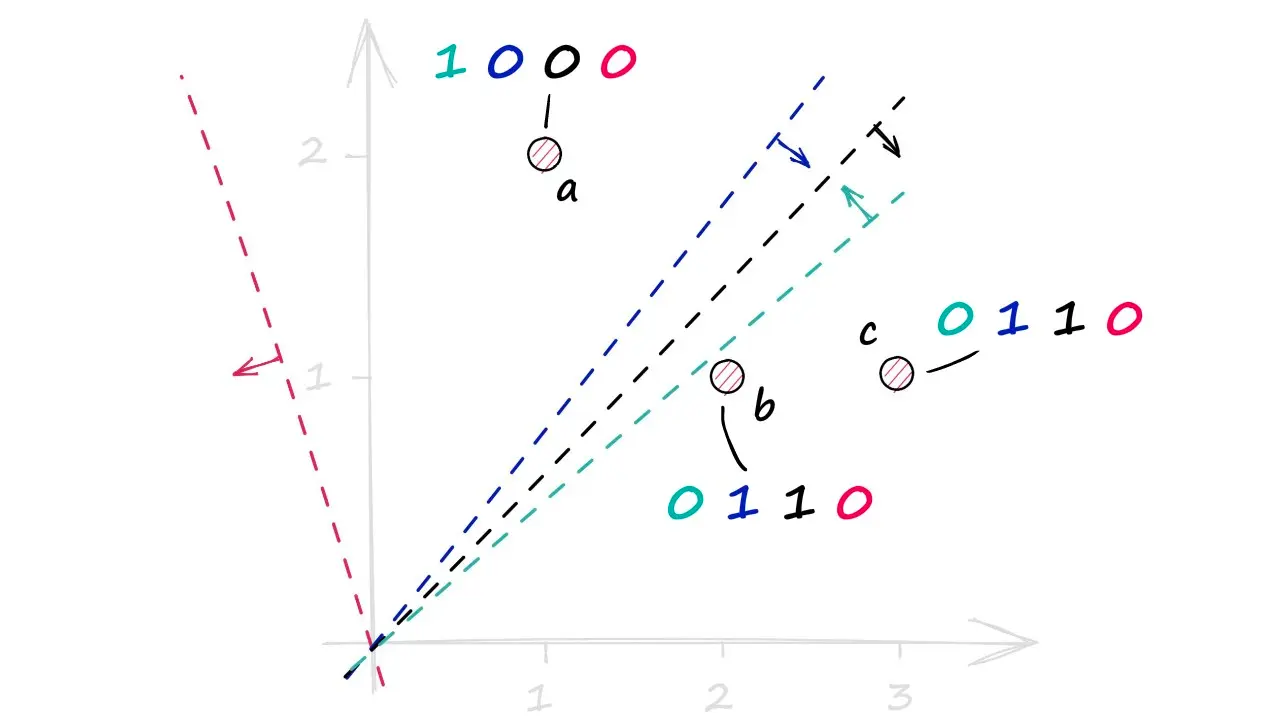
LSH는 이렇게 얻은 해시 값들을 버킷을 만들기 위해 사용한다. 이 버킷은 벡터에 대한 참조 정보(예: 벡터 ID)를 포함한다.
중요한 점은, 버킷 안에 원본 벡터는 저장하지 않는다는 것이다. 그렇게 할 경우 LSH 인덱스의 크기가 급격히 커지기 때문이다.
검색 복잡도의 변화
위 a, b, c 벡터의 예시 사진에 쿼리 벡터가 주어졌다고 하자. 쿼리 벡터는 해싱되어 0111이 되었다. 이 해시값을 가지고 LSH 인덱스에 있는 모든 버킷과 비교한다.
0111vs1000-> 해밍 거리 = 40111vs0110-> 해밍 거리 = 1
가장 가까운 매치는 0110이다.
원래 선형 시간 복잡도(linear complexity)를 갖던 검색을 서브 선형(sub-linear) 복잡도로 줄였다.
벡터들을 버킷으로 그룹화했고, 이로 인해 쿼리 벡터와 인덱스에 존재하는 모든 벡터 간의 거리를 일일이 계산할 필요가 없어졌기 때문이다.
다만, 벡터 1과 벡터 2가 둘 다 해시 값 0110을 가진다면 어느 쪽이 쿼리 벡터에 더 가까운지 알 수 없다. 이런 경우에는 검색 정확도가 일부 손실될 수 있다.
하지만 이는 근사 검색(Approximate Search)을 수행하기 위해 감수해야 할 대가일 뿐이다. 속도를 위해 정확도를 희생한다.
