[논문리뷰] MEDAGENTS : Large Language Models as Collaborators for Zero-shot Medical Reasoning
LLM
목록 보기
2/4
MEDAGENTS : Large Language Models as Collaborators for Zero-shot Medical Reasoning 논문 바로가기
Overview
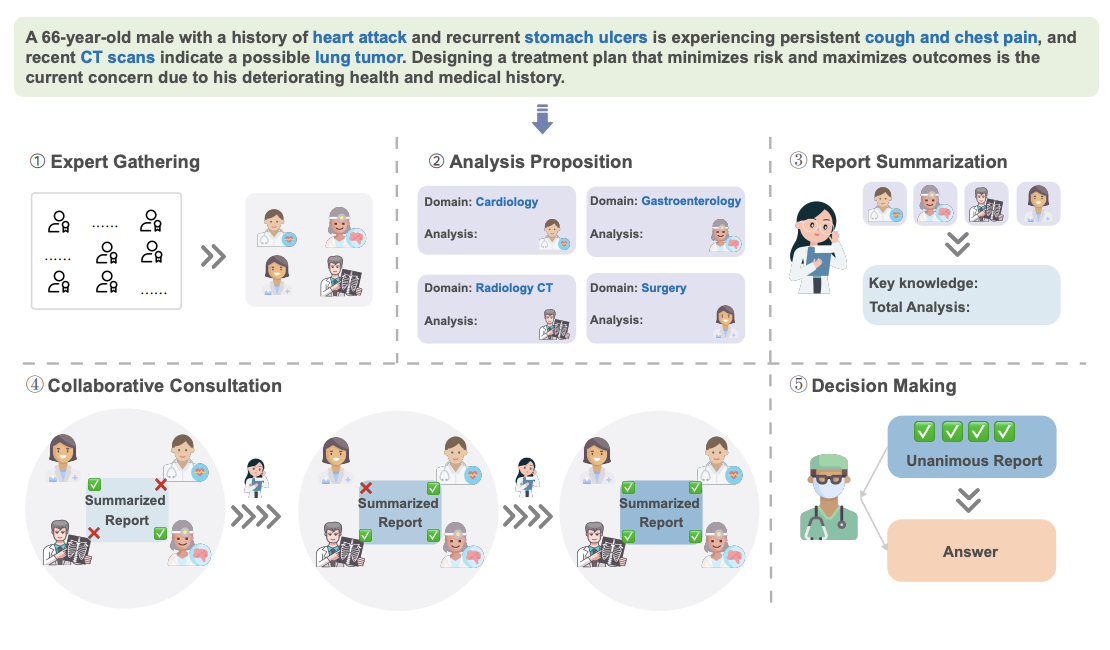
- MedAgent는 역할극(role-playing) 환경에서 LLM 기반 에이전트들이 협업적 다중 라운드 토론에 참여하여, LLM의 숙련도와 추론 능력 향상
- 도메인 전문가 모집, 개별 분석 제안, 분석을 보고서로 요약, 합의에 도달할 때까지 반복 토론, 최종 의사결정의 과정 수행
- 실제 시나리오에 적용 가능한 제로샷 환경에 초점
- github 링크 : https://github.com/gersteinlab/MedAgents
1. Introduction
LLM이 의료 도메인에서 task를 효과적으로 처리하지 못하는 2가지 이유
- 방대한 일반 텍스트와 비교했을 때 의료 훈련 데이터 양과 특이성이 제한적 (because 비용과 개인정보 보호 문제)
- 광범위한 도메인 지식과 고급 추론 기술에 대한 수요는 단순 프롬프팅만으로 의료 전문 지식을 끌어내기 어려움
→ 다중 에이전트 협업을 통해 인간 활동의 시뮬레이션을 진행해 전문 지식을 효과적으로 표면화
2. Methods
MedAgent의 다섯가지 프레임 워크
- 전문가 모집(Experting Gathering) : 임상 질문에 따라 다양한 학문 분야의 전문가 모집
- 분석 제안(Analysis Proposition) : 도메인 전문가들이 각자의 전문 지식 기반으로 분석 제시
- 보고서 요약(Report Summarization) : 이전 분석을 바탕으로 보고서 요약
- 협업적 자문(Collaborative Consultation) : 전문감들이 함께 요약 보고서 검토하고 토론. 모든 전문가가 승인할 때까지 반복적으로 수정
- 의사결정(Decision Making) : 만장일치 보고서로부터 최종결론 도출
2.1 전문가 모집
임상 질문 q와 옵션 집합 {}에 대해,
질문 도메인 전문가 집합 와 옵션 도메인 전문가 모집
, 은 질문 q와 옵션 op에 대해 도메인 전문가를 모집하기 위한 시스템 역할과 가이드라인 프롬프트
2.2 분석 제안
-
해당 도메인 전문가들에게 추후 추론을 위해 분석을 생성하도록 요청
{} , {} -
질문 분석
질문 q와 질문 도메인 가 주어졌을 때, LLM에게 도메인 에 특화된 전문가 역할을 수행하여 질문 q에 대한 분석 수행
- 옵션 분석
옵션 도메인 와 질문분석 가 주어졌으므로, 옵션과 질문 간의 관계를 고려하여 옵션을 추가적으로 분석
2.3 보고서 요약
- 이전 분석 를 요약 및 종합. LLM에게 의료 보조자의 역할을 맡겨, 핵심 지식과 종합 분석 추출
2.4 협업적 자문
- 다양한 도메인의 전문가들이 여러 라운드의 토론에 참여하여 모두가 동의하는 요약 보고서 도출
도출 알고리즘
1. 각 라운드 전문가들이 yes or no 투표
2. no 라고 투표한 경우 수정 의견 제시 → 그 후 보고서는 수정 의견 기반으로 개정
3. 해당 과정 반복 후 모두가 yes라고 투표할 때까지 진행 or 토론 횟수가 최대 시도 횟수에 도달할 때까지 반복

2.5 의사결정
만장일치 보고서 를 참조하여 임상 질문 q의 최종 답을 도출
3. Experiments
3.1 Setup
-
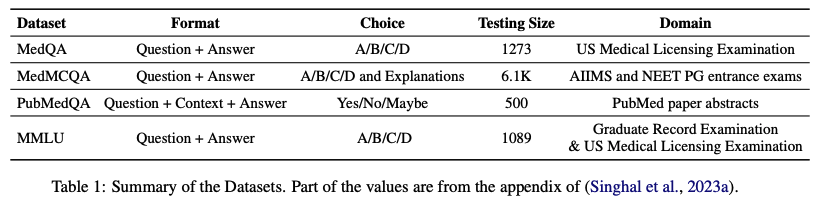
평가 벤치마크 : MedQA, MedMCQA, PubMEdQA, MMLU
구현(Implementation)
- 사용 모델 : GPT-3.5-Turbo, GPT-4
- 모든 실험은 제로샷 설정에서 수행
- 생성 temperature = 0.1
- top_p = 1.0
- SC(Self-consistency) 반복 횟수 = 5
- temperature = 0.7
- 옵션 수 k = 3 or 4
- 질문 도메인 전문가 수 m = 5
- 옵션 도메인 전문가 수 n = 2
- 최대 시도 횟수 t = 5
각 데이터셋에서 300개의 예시를 무작위 추출하여 실험 수행
비용 : 100개의 QA 예시에 대해 1.41 달러, 예시당 추론 시간 약 40초
Baselines
- COT 없는 설정
- zero shot : 주어진 질문에 "A : The answer is"라는 프롬프츠 덧붙임
- few shot : 템플릿 시연(예: [Q: q, A: The answer is a])을 입력 질문 앞에 추가
- COT 있는 설정
- zero shot COT : 질문 뒤에 "Let's think step by step"라는 프롬프트 추가하여 추론 유도
- few shot COT : 답 도출 전에 추론 과정 포함
- SC 설정
- zeroshot COT 및 fewshot COT 위에서 추가 샘플링 기법으로 동작, 여러 추론 체인을 샘플링한 뒤 다수결로 최종 답 도출
3.2 Main Results
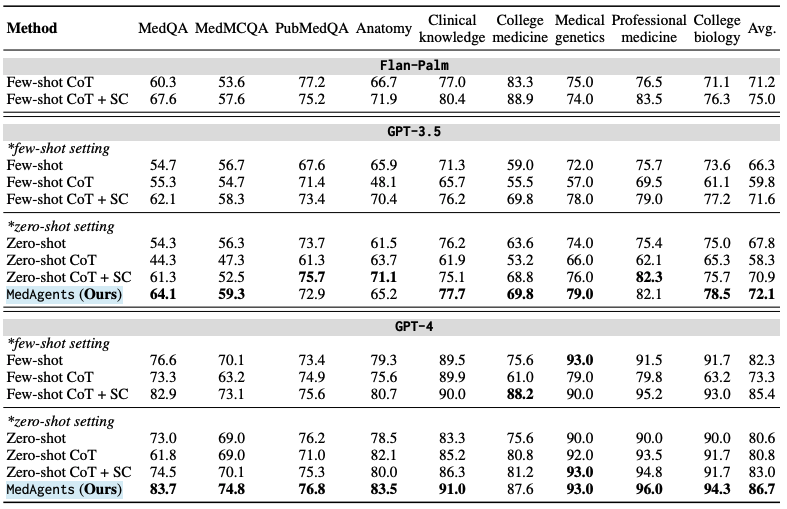
Insight : 제로샷 환경에서도 유사한 성능을 달성 + CoT는 환각 현상을 초래
4. Analysis
4.1 Ablation Study
- 세 가지 주요 프로세스 분석 제안, 보고서 요약, 협업적 자문 을 제거하여 연구 수행하여 프로세스의 중요도 확인
- 분석 제안 단계가 성능을 매우 향상시킴
- 그 외의 과정들은 이전 단계 대비 비교적 작은 성능 향상
4.2 오픈소스 의료 모델과의 비교
- 오픈소스 의료 모델이 GPT+MedAgent 보다 성능이 더 나오지 않음
4.3 에이전트 수
- 에이전트 수의 변화가 성능에 미치는 영향 조사 → 도메인 관련성이 가장 높은 전문가와 가장 낮은 전문가 선택적 제거

- 어떤 에이전트를 제거해도 기준선 대비 성능 크게 향상
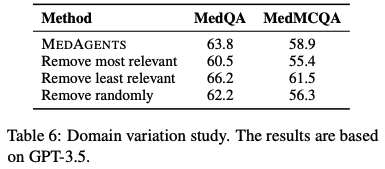
4.4 도메인 변이 연구
- 도메인 변동의 영향에 매우 강건
4.5 에이전트 수량 연구
- 도메인 에이전트 수를 줄이면서 성능 변화 관찰
4.6 오류 분석
- 도메인 지식 부족 : 모델이 정확한 응답을 제공하는데 특정 의료 지식을 충분히 이해하지 못함
- 도메인 지식 오인출 : 모델이 필요한 도메인 지식을 갖고 있지만, 주어진 맥락에서 이를 올바르게 검색하거나 적용하지 못함
- 일관성 오류 : 동일한 진술에 대해 상충되는 응답 제공, 모델이 기저 지식의 이해나 적용에서 혼동
- CoT 오류 : 모델이 부정확한 추론 과정 형성
77%의 오류가 도메인 지식에 의해 발생
4.7 교정 능력과 해석 가능성
- MEDAgents 프레임워크가 협업적 합성을 통해 응집력 있는 결론 도출
5. Related Work
5.1 의료 분야에서의 LLMs
의료 도메인에서 2가지 연구 주제
- 도구 보강 방법
- GeneGPT : LLM이 NCBI 웹 API를 활용하여 다양한 생의학 정보를 충족하도록 유도
- Zakka et al. : 의료 지침과 치료 권고를 검색할 수 있는 기능을 가진 프레임워크 ALmanac 제안
- Kang et al. : LLM이 생성한 추론을 활용하여 소규모 LMs 미세조정 + 비매개 메모리에서 외부지식 보강하는 방법(KARD)
- 지지 조정 방법
- 외부 임상 지식 기반과 자기 프롬프트 데이터를 활용하여 지시 데이터셋 구축
5.2 LLM 기반 다중 에이전트 협업
- Solo Preformance Prompting(SPP) : 여러 페르소나를 동적으로 식별하고 참여시켜, 다중 지성 결합
- Camel : 역할극을 활용하여 대화형 에이전트들이 상호 소통하면서 과제 완수
6. Conclusion
한계
- LLM 내부의 지식은 지속적 업데이트 필요함
- 프레임워크 속 단계에서 여러 모델을 통합하는 것 필요
- 더 넓은 범위의 언어에 적용할 필요 있음
comment
- 의료 도메인에서 Agent 설계의 특징
의료 분야에서의 할루시네이션은 환자의 생명과도 직결될 수 있는 문제이기 때문에 올바르지 않은 정보가 출력되지 않는 것이 매우 중요하다고 생각하고, 그런 취지에서 다중 토론으로 인해 보다 명확한 정답이 나오는 Multi Agent를 설계한 것이라고 생각. 이러한 점이 agent 간의 토론 알고리즘을 통해 엿볼 수 있음
- 다수결로 인한 의사결정이 아닌, 한 명이랑 No라고 답하는 경우 답변을 재수정해가는 알고리즘을 통해서 답변이 신뢰성을 높이려고 노력하는 것 같음- Chaing of Thought
일반적으로 COT 기법이 모델의 출력 성능을 높인다고 생각할 수 있지만, 이렇게 전문 지식을 많이 요구하는 분야에서 CoT 방식이 오히려 할루시네이션을 유발할 수 있음
어떠한 모델 설계에 있어서 해당 도메인에 대한 충분한 이해가 밑바탕이 되어야 할 것 같다.

Data Scientist