1. Blue/Green 구조 변환 계기
회사에 합류하고 처음 맡은 과제는 서비스 무중단 배포 구조 마련이었습니다. 배포 과정에서 발생하는 다운타임은 곧바로 사용자 경험 저하로 이어지기 때문에, 이를 해결하기 위해 CI/CD 파이프라인과 안정적인 트래픽 전환 구조가 필요했습니다.
처음에는 Nginx 기반의 Blue/Green 포트 스위칭 방식을 적용했습니다. 이 방식은 비교적 간단하게 구현할 수 있었고, 빠른 전환이 가능하다는 장점이 있었습니다. 하지만 실제 서비스 환경에서는 전환 순간 일부 요청이 유실되거나 502 오류가 발생하는 문제가 나타났습니다.
이 문제를 해결하기 위해 구조를 재검토했고, 결국 AWS ALB + Target Group 기반의 Blue/Green 배포로 전환하게 되었습니다. ALB는 외부 요청 기준으로 헬스 체크를 수행할 수 있어 신뢰성 있는 무중단 배포를 보장할 수 있었고, 동시에 CI/CD와 자연스럽게 결합되어 자동화된 배포 파이프라인을 완성할 수 있었습니다.
2. 문제 상황
Blue/Green 배포를 처음 도입했을 때는 Nginx의 stream switch 기능을 사용했습니다. Nginx에서 두 개의 포트를 열어 Blue와 Green 환경을 동시에 유지하고, 전환 시에는 proxy_pass를 바꿔주는 방식이었죠. 구조 자체는 단순했습니다. ALB는 항상 단일 엔드포인트인 Nginx만 바라보고 있었고, 내부에서 Nginx가 Blue 포트와 Green 포트를 번갈아 연결하니 손쉽게 전환할 수 있었습니다.
하지만 여기서 치명적인 문제가 발생했습니다. 헬스 체크의 주체가 Nginx였다는 점입니다. ALB는 Nginx까지만 확인할 수 있었고, 실제 핵심인 WAS(Web Application Server)가 정상적으로 기동했는지는 전혀 보장되지 않았습니다.
결과적으로 이런 상황이 반복되었습니다:
-
ALB는 “Nginx가 살아있으니 OK”라고 판단
-
실제로는 새로 띄운 Green WAS가 아직 Warm-up 중
-
전환 직후 사용자들은 502/504 오류를 경험
즉, ALB와 WAS 사이에 놓인 Nginx가 일종의 헬스 체크 차단막처럼 동작하면서, 가장 중요한 애플리케이션 레벨의 검증이 이루어지지 않았던 것입니다.
여기서 중요한 포인트는 단순히 “502가 발생했다”는 사실이 아니라, 왜 ALB가 착각했는가입니다. ALB 자체는 원래 Layer 7(HTTP) 레벨의 헬스 체크를 지원합니다. /health 같은 엔드포인트를 직접 호출해 실제 애플리케이션이 정상 응답하는지를 확인할 수 있죠. 그러나 우리가 사용한 Nginx stream switch는 TCP 레벨에서 단순히 포트를 프록시하는 구조였습니다. 이 때문에 ALB는 Nginx 포트가 열려 있는지만 확인했고, 실제 WAS 레벨의 /health 요청까지는 닿지 못했습니다.
결국 구조상 ALB는 “서비스가 정상”이라고 잘못 판단했지만, 실제 사용자는 전환 직후 애플리케이션이 준비되지 않아 오류를 맞이하는 모순적인 상황이 벌어진 것입니다. 이로 인해 무중단 배포의 본질인 “사용자 기준 안정성 보장”을 달성할 수 없었습니다.
3. 대안 탐색
문제의 원인이 명확해지자, 곧바로 구조를 재검토했습니다. 핵심은 단순했습니다.
헬스 체크가 반드시 애플리케이션 레벨까지 도달해야 한다는 것이죠.
이를 해결하기 위한 대안으로 AWS ALB + Target Group 기반 Blue/Green 배포를 선택했습니다.
ALB의 장점: ALB는 기본적으로 Layer 7(HTTP) 헬스 체크를 지원하기 때문에, /health 같은 엔드포인트를 직접 호출해 실제 애플리케이션 응답을 검증할 수 있습니다.
Target Group 분리 운영: Blue/Green 환경을 각각 Target Group으로 나눠 관리하면, 새로운 버전의 WAS가 완전히 준비될 때까지는 트래픽이 전환되지 않습니다.
확장성: 이후 Auto Scaling이나 Canary 배포로 확장하기에도 자연스럽습니다.
즉, 단순히 포트 단위 전환에서 벗어나, 외부 요청 기준으로 서비스 정상 여부를 판단할 수 있는 구조가 필요했고, ALB + Target Group이 그 조건을 충족했습니다.
5. 구현 과정
대안으로 AWS ALB + Target Group 방식을 선택한 뒤, 실제로 적용하기 위해 다음과 같은 과정을 거쳤습니다.
1) ALB와 Target Group 구성
-
먼저 ALB를 생성하고, Blue/Green 두 개의 Target Group을 만들었습니다.
-
각 Target Group은 동일한 포트(예: 8080)에서 서로 다른 컨테이너 버전을 바라보도록 구성했습니다.
-
헬스 체크는 HTTP /health 엔드포인트, 200 OK 응답 코드, 2초 간격, 연속 2회 성공 시 정상 판정 조건으로 설정했습니다.
- 이렇게 하면 WAS가 Warm-up 중일 때는 Target Group에 Healthy 상태로 편입되지 않기 때문에, 전환 과정에서 사용자 요청이 유실되지 않습니다.
2) CI/CD 파이프라인 개선 (GitHub Actions)
-
배포 파이프라인은 GitHub Actions를 사용해 자동화했습니다.
-
새로운 커밋이 main 브랜치에 머지되면 다음 단계가 실행됩니다:
-
Docker 이미지를 빌드해 ECR에 Push
-
새로운 컨테이너를 EC2에 배포 (Blue 혹은 Green)
-
ALB Target Group에 새 컨테이너를 등록
-
헬스 체크 통과 시 Listener를 새 Target Group으로 전환
-
-
전환 후 일정 시간 동안 모니터링을 거쳐, 문제가 없으면 기존 Target Group을 정리합니다.
3) Nginx 제거 및 단일 진입점 단순화
-
기존에는 ALB → Nginx → WAS 구조였지만, 이제는 ALB가 직접 WAS 컨테이너로 트래픽을 전달합니다.
-
이로써 불필요한 Nginx 계층이 사라지고, ALB가 헬스 체크와 트래픽 분산을 동시에 관리하는 단순한 구조로 개선되었습니다.
이 과정을 통해 “외부 요청 기준의 무중단 배포”라는 목표를 달성할 수 있었습니다.
6. 비교 분석
변경 전
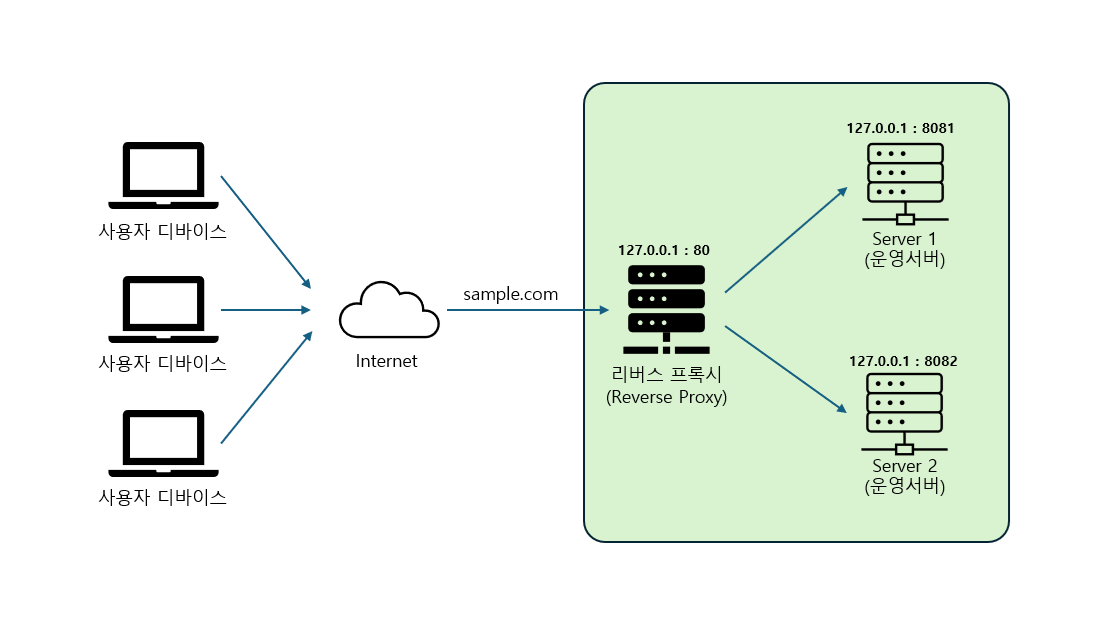
→ ALB는 Nginx까지만 확인, WAS 상태는 보장되지 않음.
변경 후
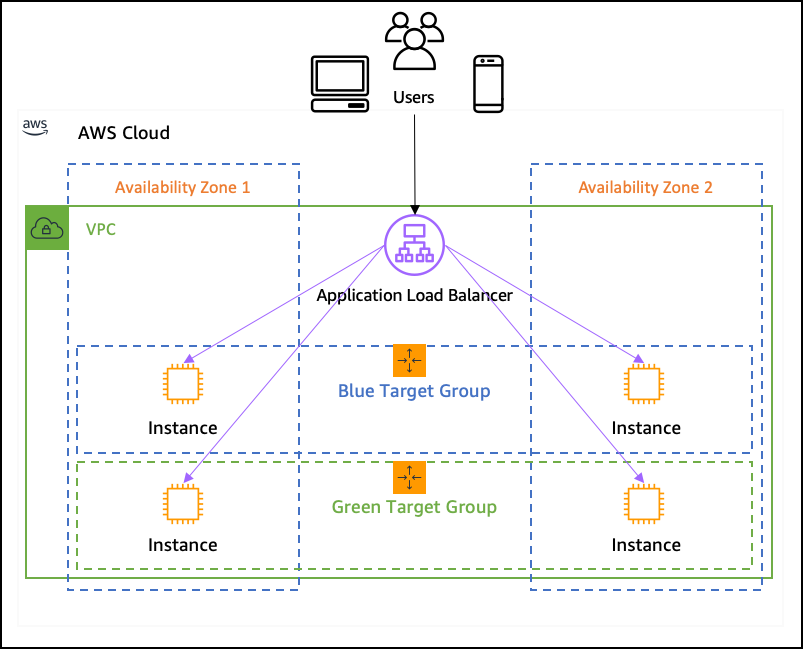
→ ALB가 직접 WAS /health를 체크, 애플리케이션 레벨까지 신뢰성 확보.
| 항목 | 변경 전 (Nginx stream switch) | 변경 후 (ALB + Target Group) |
|---|---|---|
| 헬스 체크 기준 | Nginx 포트 응답 확인 (TCP 레벨) | WAS /health 직접 확인 (HTTP 레벨) |
| 전환 시 안정성 | Warm-up 중에도 전환 → 502/504 발생 | 헬스 체크 통과 후에만 전환 |
| 구조 복잡도 | ALB → Nginx → WAS (중간 계층 존재) | ALB → WAS (단순화) |
| 확장성 | 포트 기반 전환 → Auto Scaling 어려움 | Target Group 확장 → Auto Scaling, Canary 가능 |
7. 결과와 효과
ALB + Target Group 기반으로 전환한 뒤, 배포 안정성과 사용자 경험에서 확실한 개선 효과를 확인할 수 있었습니다.
-
502/504 오류 제거
-
기존 전환 과정에서 빈번히 발생하던 오류가 사라졌습니다.
-
배포 시점에도 외부 사용자는 서비스 중단을 체감하지 않게 되었습니다.
-
-
사용자 경험 안정화
-
전환 과정에서 요청 유실이 없어졌습니다.
-
헬스 체크 검증을 거친 뒤에 전환되면서, 사용자 기준에서도 안정적인 요청 처리가 가능해졌습니다.
-
-
운영 효율성 향상
-
트래픽 전환 주체로 사용하던 Nginx 계층을 제거하면서 구조가 단순해졌습니다.
-
다만, 정적 파일 서빙이나 리버스 프록시 같은 웹서버 본연의 역할은 상황에 따라 여전히 필요할 수 있습니다.
-
여기서는 “배포 무중단 전환 로직”만 ALB에 맡기고, Nginx의 일반적인 웹서버 역할은 별도로 고려할 수 있도록 구분했습니다.
-
-
확장 가능성 확보
- Auto Scaling, Canary 배포와 같은 클라우드 네이티브 패턴을 적용할 수 있는 기반이 마련되었습니다.
