그럼 일단 Priority Queue(우선순위 큐)란 무엇인가를 알아보도록 하자.
우선순위 큐는 각 요소들이 각각의 우선 순위를 갖고있고, 요소들의 대기열에서 '우선 순위가 높은 요소'가 '우선 순위가 낮은 요소'보다 먼저 제공되는 자료구조다.
여기서 많은 분들이 가장 많은 오해를 하는 것은 "우선순위 큐 = 힙" 이라는 것이다. 어찌보면 '힙'과 유사한 구조를 갖고 있으나, 엄연히 따지자면 개념 자체는 다르다.
한번 다시 복기해보자. 힙은 '최솟값 또는 최댓값을 빠르게 찾아내기 위해 완전이진트리 형태로 만들어진 자료구조'다.
힙은 기본적으로 중점이 되는 것이 '최솟값 또는 최댓값 빠르게 찾기'인 반면에, 우선순위 큐는 우선순위가 높은 순서대로 요소를 제공받는 다는 점이다.
뭔 차이인지 잘 이해가 안갈 수도 있다. 좀 더 다른 예시를 들어보겠다.
우리는 '리스트' 자료구조를 배웠었다. 리스트는 '배열'을 이용한 ArrayList와 노드간의 연결을 이용한 LinkedList로 나뉜다. 이 둘을 '리스트'라고 흔히 부른다.
즉, 리스트라는 추상적인 자료구조 모델의 개념을 배열을 이용하느냐, 노드를 링크하는 방식을 이용하느냐를 통해 구체화 된 자료구조가 ArrayList나 LinkedList 처럼 나오는 것이다.
다른 예시를 들어볼까?
필자가 큐(Queue)에 대해서 포스팅을 두 개를 했다. 하나는 배열을 이용한 방식, 다른 하나는 연결리스트로 구현한 방식이었다. 즉, 큐(Queue)라는 추상적 개념을 구체화를 어떻게 하느냐에 따라 구현 형태가 달라지게 된다.
다시 우선순위 큐로 돌아가보자.
우선순위 큐는 우선순위를 갖는 요소를 우선적으로 제공받을 수 있도록 하는 자료구조다. 이는 리스트처럼 '추상적 모델' 개념에 좀 더 가깝고, 이를 구현하는 방식은 여러 방식이 있다.
그리고 우선순위 큐를 구현하는데에 있어 가장 대표적인 구현 방식이 'Heap(힙)' 자료구조를 활용하는 방식이라는 것이다.
필자가 그동안 자료구조를 구현하면서 인터페이스(Interface)를 따로 둔 이유가 바로 이러한 이유로 추상적인 개념과 구체화 하는 과정을 보여주기 위함이었다. 그렇기 때문에 이번 포스팅은 정확히 말하자면 힙(Heap) 자료구조를 이용한 우선순위 큐(Priority Queue) 구현이라 봄이 맞다.
그럼 힙(Heap)을 사용한 우선순위 큐(Priority Queue)는 어떻게 구현되냐? 이 부분이 가장 큰 문제일 것이다. 이 부분은 힙과 내용이 겹치기 때문에 내용을 갖고와서 설명하겠다.
힙에서는 '최대 혹은 최소값'을 빠르게 찾기 위한다고 했다. 이를 우선순위가 높은 요소를 빠르게 찾기 위한다고 바꾸어 생각하면 좀 더 편할 것이다.
여러분이 어떤 리스트에 값을 넣었다가 빼낼려고 할 때, 우선순위가 높은 것 부터 빼내려고 한다면 대개 정렬을 떠올리게 된다.
쉽게 생각해서 숫자가 낮을 수록 우선순위가 높다고 가정할 때 매 번 새 원소가 들어올 때 마다 이미 리스트에 있던 원소들과 비교를 하고 정렬을 해야한다.
문제는 이렇게 하면 비효율적이기 때문에 좀 더 효율이 좋게 만들기 위하여 다음과 같은 조건을 붙였다.
'부모 노드는 항상 자식 노드보다 우선순위가 높다.'
즉, 모든 요소들을 고려하여 우선순위를 정할 필요 없이 부모 노드는 자식노드보다 항상 우선순위가 앞선다는 조건만 만족시키며 완전이진트리 형태로 채워나가는 것이다.
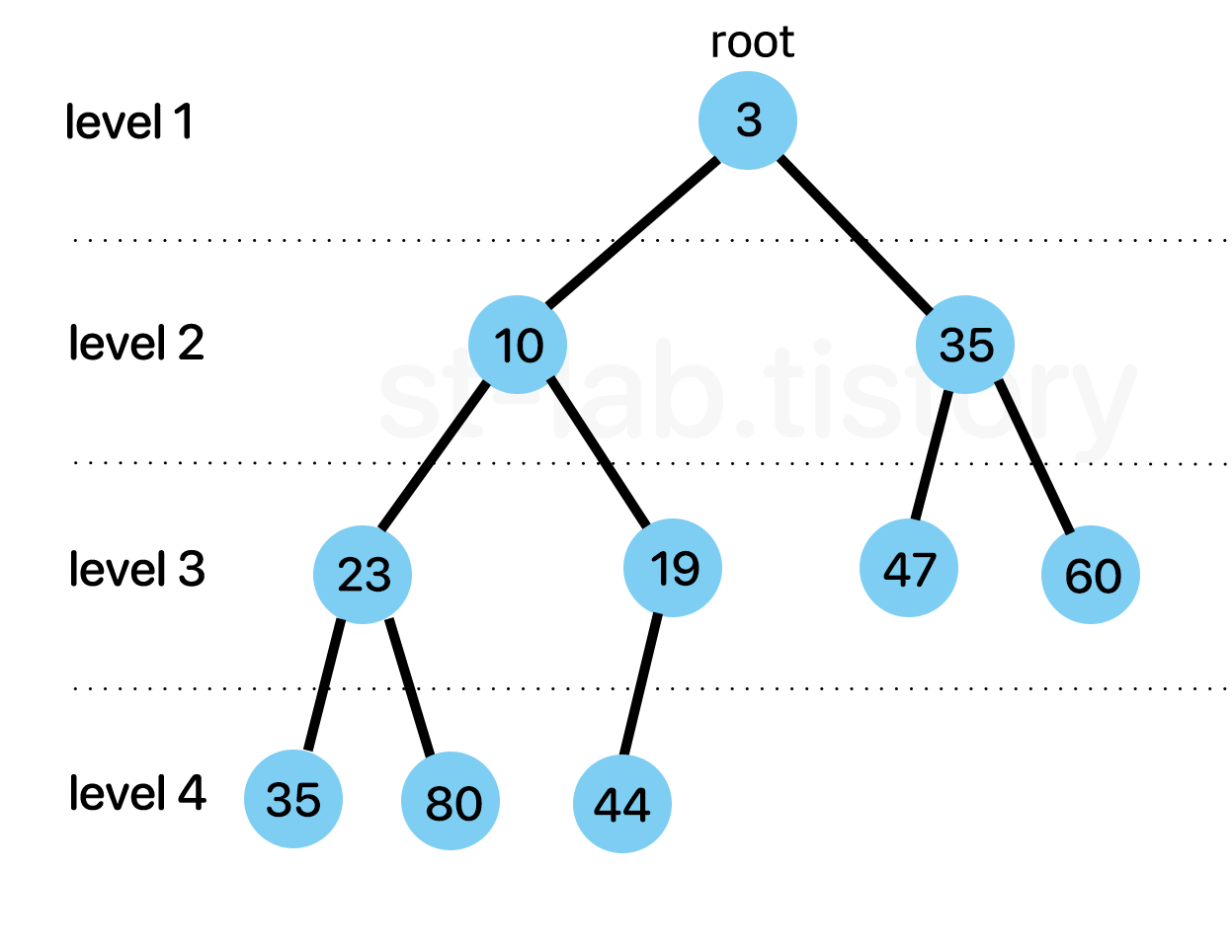
이를 조금만 돌려서 생각해보면 루트 노드(root node)는 항상 우선순위가 높은 노드라는 것이다. 이러한 원리로 최댓값 혹은 최솟값을 빠르게 찾아낼 수 있다는 장점(시간복잡도 : O(1))과 함께 삽입 삭제 연산시에도 부모노드가 자식노드보다 우선순위만 높으면 되므로 결국 트리의 깊이만큼만 비교를 하면 되기 때문에 O(logN) 의 시간복잡도를 갖아 매우 빠르게 수행할 수 있다.
그리고 위 이미지에서도 볼 수 있지만 부모노드와 자식노드간의 관계만 신경쓰면 되기 때문에 형제 간 우선순위는 고려되지 않는다.
이러한 정렬 상태를 흔히 '반 정렬 상태' 혹은 '느슨한 정렬 상태' , '약한 힙(weak heap)'이라고도 불린다.
그럼 이런 질문이 나올 수 있다. "왜 형제간의 대소비교가 필요 없다는 거죠?"
우선순위가 높은 순서대로 뽑는 것이 포인트다. 즉, 원소를 넣을 때도 우선순위가 높은 순서대로 나올 수 있도록 유지가 되야하고 뽑을 때 또한 우선순위가 높은 순서 차례대로 나오기만 하면 된다.
말로하면 어려울 수도 있으나 구현부분을 보면 바로 이해할 수 있을 것이다.
- Heap을 이용한 Priority Queue의 종류
앞서 힙은 우선순위가 높은 순서대로 나온다고 했다. 이 말은 여러분이 어떻게 우선순위를 매기냐에 따라 달라지겠지만, 기본적으로 정수, 문자, 문자열 같은 경우 언어에서 지원하는 기본 정렬 기준들이 있다.
예로들어 정수나 문자의 경우 낮은 값이 높은 값보다 우선한다.
우리가 예로 {3, 1, 6, 4} 를 정렬한다고 하면 낮은 순서대로 {1, 3, 4, 6} 이렇게 정렬하게 된다. 이렇게 정렬되는 순서, 즉 기본적으로 어떤 것을 우선순위가 높다고 할지에 따라 두 가지로 나뉜다.
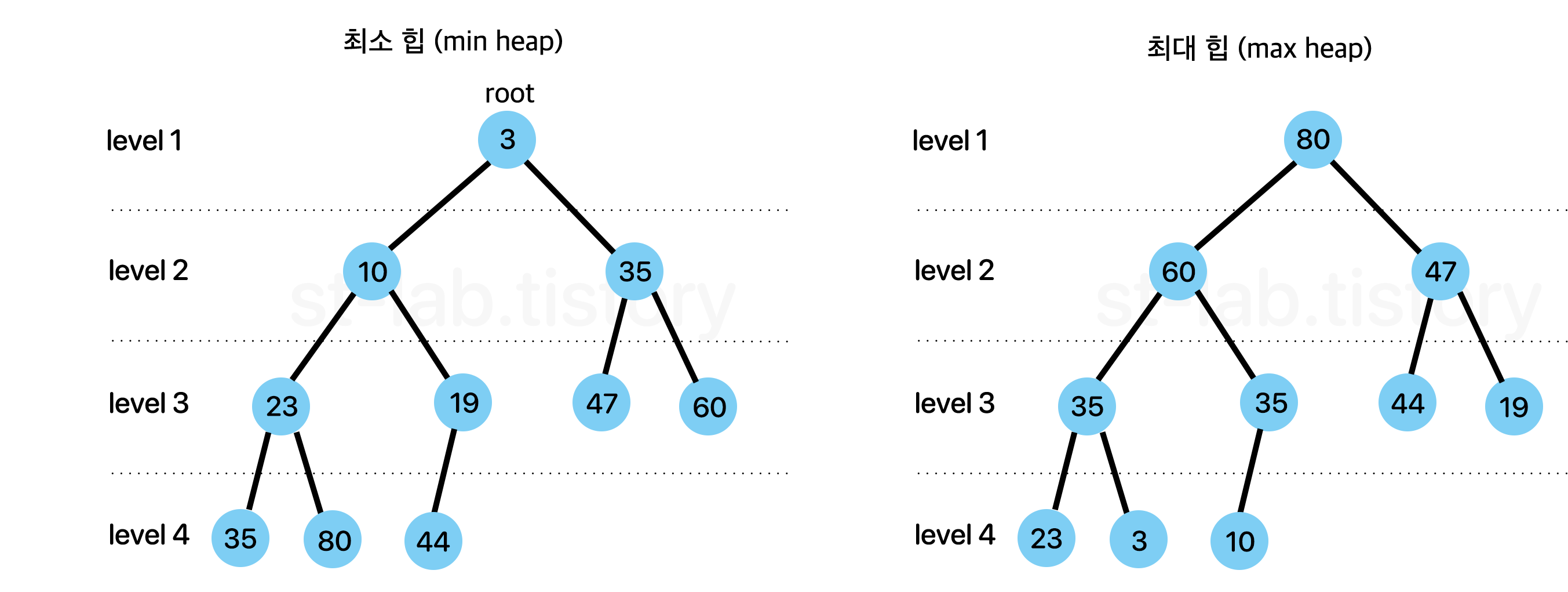
최소 힙 : 부모 노드의 값(key 값) ≤ 자식 노드의 값(key 값)
최대 힙 : 부모 노드의 값(key 값) ≥ 자식 노드의 값(key 값)
이렇게 두 가지로 나뉜다.
다만, 여기서 가장 기본으로 우선순위를 뽑는다고 하면 보통 '오름차순'을 생각하기도 하고 많은 언어들도 오름차순을 기본으로 하기 때문에 오늘을 '최소 힙'을 활용하여 구현해볼 것이다. (최대 힙을 이용하여 구현 할 경우 비교연산자만 바꿔주면 되기 때문에 어떤 것을 구현하더라도 크게 문제는 없다.)
그럼 위의 트리 구조를 어떻게 구현할 것인가?
가장 표준적으로 구현되는 방식은 '배열' 이다. 물론 연결리스트로도 구현이 가능하긴 하지만, 문제는 특정 노드의 '검색', '이동' 과정이 조금 더 번거롭기 때문이다.
배열의 경우는 특정 인덱스에 바로 접근할 수가 있기 때문에 좀 더 효율적이기도 하다.
배열로 구현하게 되면 특징 및 장점들이 있다. 일단 아래 그림을 한 번 봐보도록 하자.
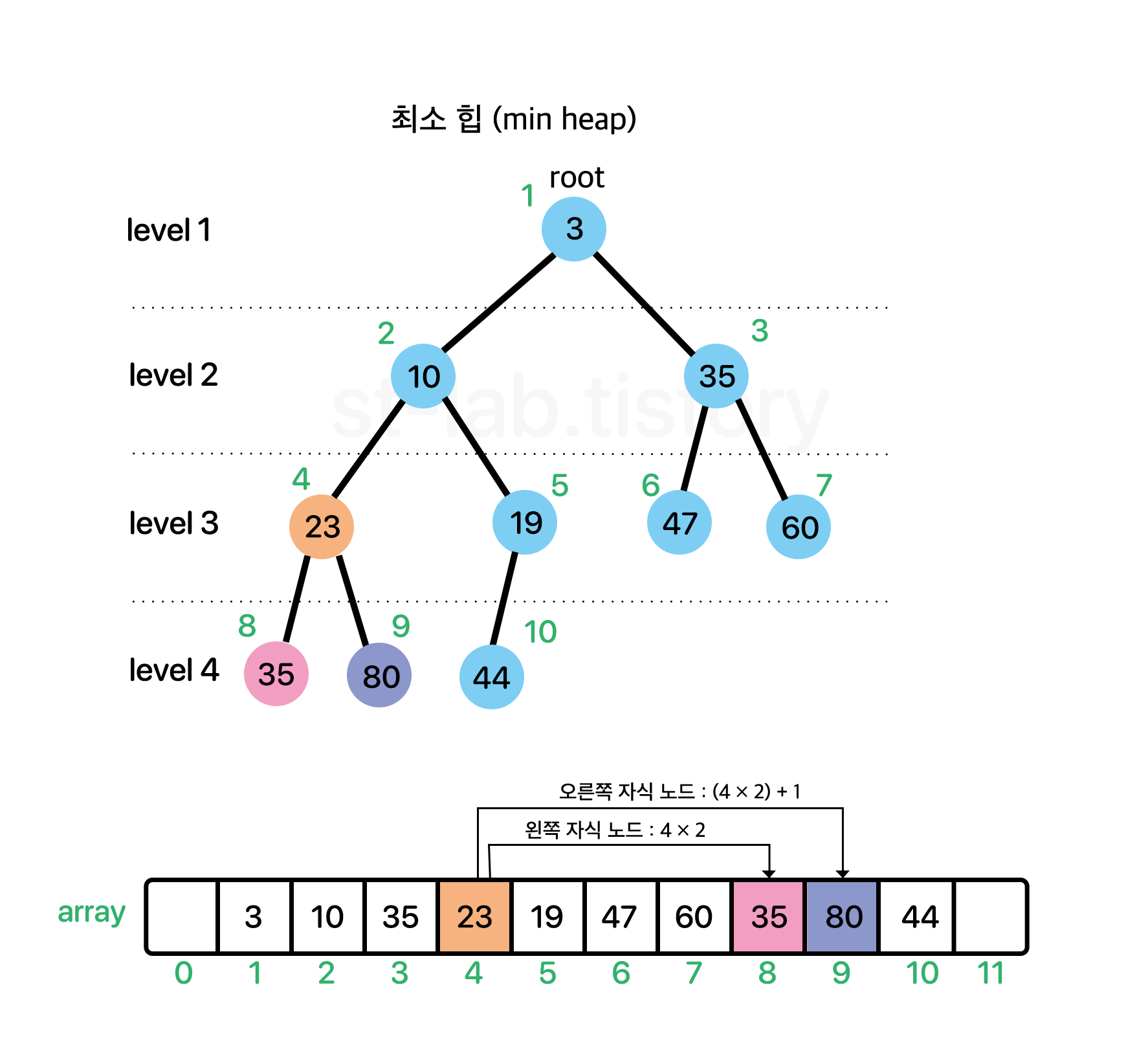
[특징]
-
구현의 용이함을 위해 시작 인덱스(root)는 1 부터 시작한다.
-
각 노드와 대응되는 배열의 인덱스는 '불변한다'
위 특징을 기준으로 각 인덱스별로 채워넣으면 특이한 성질이 나오는데 이는 다음과 같다.
[성질]
-
왼쪽 자식 노드 인덱스 = 부모 노드 인덱스 × 2
-
오른쪽 자식 노드 인덱스 = 부모 노드 인덱스 × 2 + 1
-
부모 노드 인덱스 = 자식 노드 인덱스 / 2
위 세개의 법칙은 절대 변하지 않는다.
예로들어 index 3 의 왼쪽 자식 노드를 찾고 싶다면 3 × 2를 해주면 된다. 즉 index 6 이 index 3 의 자식 노드라는 것이다.
반대로 index 5의 부모 노드를 찾고 싶다면 5 / 2 를 해주면 된다.(몫만 취함) 그러면 2 이므로 index 2가 index 5의 부모노드라는 것이다.
그러면 위 설명을 바탕으로 한 번 구현해보도록 해보자.
- Heap을 이용한 Priority Queue 구현
앞서 말했지만, 일단 기본적으로 최소 힙(Min Heap)을 기준으로 설명드리도록 하겠다. 최대 힙 또한 원리가 크게 다른 건 아니라 만약 최대힙을 이용하여 우선순위 큐를 구현하고 싶은 경우 비교 연산만 반대로 해주면 된다.
[Priority Queue 클래스 및 생성자 구성하기]
이 번에 구현 할 우선순위 큐는 배열 기반으로 구현한 Heap을 기반으로 구현된다는 것을 알았으면 한다. PriorityQueue 이라는 이름으로 생성한다.
또한 Queue Interface 포스팅에서 작성했던 Queue 인터페이스를 implements 해준다. (필자의 경우 인터페이스는 Interface_form 이라는 패키지에 생성해두었다.)
implements 를 하면 class 옆에 경고표시가 뜰 텐데 인터페이스에 있는 메소드들을 구현하라는 것이다. 어차피 모두 구현해나갈 것이기 때문에 일단은 무시한다.
[PriorityQueue.java]
import Interface_form.Queue;
import java.util.Comparator;
public class PriorityQueue<E> implements Queue<E> {
private final Comparator<? super E> comparator;
private static final int DEFAULT_CAPACITY = 10; // 최소(기본) 용적 크기
private int size; // 요소 개수
private Object[] array; // 요소를 담을 배열
// 생성자 Type 1 (초기 공간 할당 X)
public PriorityQueue() {
this(null);
}
public PriorityQueue(Comparator<? super E> comparator) {
this.array = new Object[DEFAULT_CAPACITY];
this.size = 0;
this.comparator = comparator;
}
// 생성자 Type 2 (초기 공간 할당 O)
public PriorityQueue(int capacity) {
this(capacity, null);
}
public PriorityQueue(int capacity, Comparator<? super E> comparator) {
this.array = new Object[capacity];
this.size = 0;
this.comparator = comparator;
}
// 받은 인덱스의 부모 노드 인덱스를 반환
private int getParent(int index) {
return index / 2;
}
// 받은 인덱스의 왼쪽 자식 노드 인덱스를 반환
private int getLeftChild(int index) {
return index * 2;
}
// 받은 인덱스의 오른쪽 자식 노드 인덱스를 반환
private int getRightChild(int index) {
return index * 2 + 1;
}
}변수부터 먼저 차례대로 설명해주도록 하겠다.
comparator : 여러분들이 객체를 정렬하고자 할 때, 혹은 임의의 순서로 정렬하고 싶을 때 Comparator 를 파라미터로 받아 설정할 수 있도록 한 변수다. 즉, 우선순위를 결정해주는 변수라고 보면 된다.
DEFAULT_CAPACITY : 배열의 기본 및 최소 용적이다. 한마디로 요소를 담을 배열의 크기를 의미한다. 배열을 동적으로 관리 할 때 최소 크기가 10 미만으로 내려가지 않기 위한 변수다. 그리고 요소의 개수랑은 다른 의미이므로 이 점 헷갈리지 말자.
size : 배열에 담긴 요소(원소)의 개수 변수
array : 요소를 담을 배열이다.
그리고 생성자는 크게 4가지로 나누었다.
먼저 데이터(요소)의 개수를 예상할 수 있어 배열의 크기(용적)를 최적으로 하고 싶을 때 초기에 생성할 배열의 크기를 설정 해줄 수 있도록 만든 방법과 사용자가 정렬 방법을 따로 넘겨주고자 할 때 쓸 수 있도록 Comparator을 받는 방법을 조합하여 4가지로 나누었다.
그리고 힙 설명에서 힙을 배열로 구현하게 될 때의 성질에 관해 배웠다.
[성질]
-
왼쪽 자식 노드 인덱스 = 부모 노드 인덱스 × 2
-
오른쪽 자식 노드 인덱스 = 부모 노드 인덱스 × 2 + 1
-
부모 노드 인덱스 = 자식 노드 인덱스 / 2
위 세 가지 성질을 이용하기 위해 각각 부모 또는 자식의 인덱스를 반환해주는 메소드를 생성해주었다.
[resize 메소드 구현]
모든 자료구조는 기본적으로 동적으로 만들 수 있어야 한다.
만약 배열에 요소들이 모두 차면 배열의 크기를 늘려야하고, 만약 요소가 배열 용적에 비해 현저히 적으면 낭비되는 메모리가 크므로 적절히 줄여줄 수 있어야 한다.
그럴 때 배열의 크기를 재조정하기 위해 쓰는 메소드다.
/**
* @param newCapacity 새로운 용적 크기
*/
private void resize(int newCapacity) {
// 새로 만들 배열
Object[] newArray = new Object[newCapacity];
// 새 배열에 기존에 있던 배열의 요소들을 모두 복사해준다.
for(int i = 1; i <= size; i++) {
newArray[i] = array[i];
}
/*
* 현재 배열은 GC 처리를 위해 null로 명확하게 처리한 뒤
* 새 배열을 array에 연결해준다.
*/
this.array = null;
this.array = newArray;
}위 과정대로 새 배열을 생성하고 기존에 있던 배열의 요소들을 복사해준 뒤, 새 배열을 가리키도록 새로 연결해주면 된다.
이 부분 자체는 어려울 건 없을 것이다.
[offer 메소드 구현]
이제 본격적으로 PriorityQueue에 데이터를 추가할 수 있도록 해보자.
힙을 다룰 때는 add라고 했지만, 우선순위 큐는 Queue 인터페이스를 구현해야 하며, 그 안에 offer라는 메소드가 삽입 연산에 해당되니, offer로 명칭을 대체하겠다.
우선순위 큐의 삽입은 크게 두 가지로 나뉜다.
1. 사용자가 Comparator을 사용하여 정렬 방법을 PriorityQueue 생성단계에서 넘겨받은 경우 (comparator가 null이 아닌 경우)
2. 클래스 내에 정렬 방식을 Comparable로 구현했거나 기본 정렬 방식을 따르는 경우 (comparator가 null인 경우)
이 두 가지로 나누어 봐야한다.
기본적으로 Heap에서 원소가 추가되는 과정을 다음 이미지와 같다.
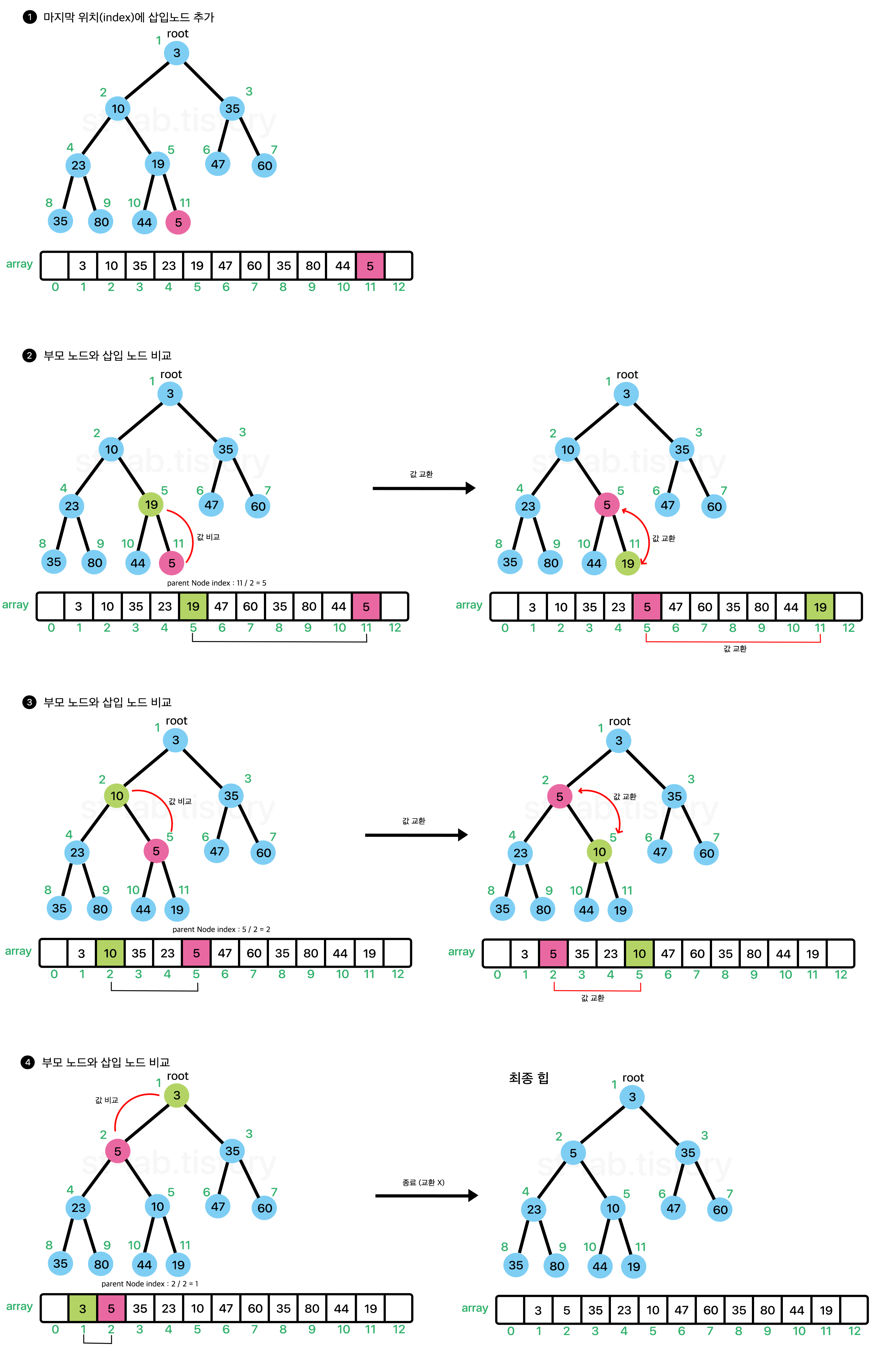
즉, 배열의 마지막 부분에 원소를 넣고 부모노드를 찾아가면서 부모 노드가 삽입 노드보다 작을 때 까지 요소를 교환해가면서 올라간다. 위와 같은 과정을 흔히 위로 올라가면서 선별한다고 하여 sift-up (상향 선별) 이라고도 불린다.
즉, 값을 추가 할 때는 size + 1 위치에 새로운 값을 추가하고 상향 선별 과정을 거쳐 '재배치'를 해준다고 생각하면 된다.
이 때, 재배치 되는 노드를 위 분홍색 노드 즉, 타겟노드(target)라고 생각하면 된다.
그럼 위 과정을 코드로 옮겨보자.
@Override
public boolean offer(E value) {
// 배열 용적이 꽉 차있을 경우 용적을 두 배로 늘려준다.
if(size + 1 == array.length) {
resize(array.length * 2);
}
siftUp(size + 1, value); // 가장 마지막에 추가되는 위치와 넣을 값(타겟)을 넘겨줌
size++; // 정상적으로 재배치가 끝나면 사이즈(요소 개수) 증가
return true;
}
/**
* 상향 선별
*
* @param idx 추가할 노드의 인덱스
* @param target // 재배치 할 노드
*/
private void siftUp(int idx, E target) {
/*
* comparator가 존재한다면 comparator을 넘겨주고,
* 아닐경우 Comparable로 비교하도록 분리해준다.
*/
if(comparator != null) {
siftUpComparator(idx, target, comparator);
}
else {
siftUpComparable(idx, target);
}
}
// Comparator을 이용한 sift-up
@SuppressWarnings("unchecked")
private void siftUpComparator(int idx, E target, Comparator<? super E> comp) {
// root노드보다 클 때 까지만 탐색한다.
while(idx > 1) {
int parent = getParent(idx); // 삽입노드의 부모노드 인덱스 구하기
Object parentVal = array[parent]; // 부모노드의 값
// 타겟 노드 우선순위(값)이 부모노드보다 크면 반복문 종료
if(comp.compare(target, (E) parentVal) >= 0) {
break;
}
/*
* 부모노드가 타겟노드보다 우선순위가 크므로
* 현재 삽입 될 위치에 부모노드 값으로 교체해주고
* 타겟 노드의 위치를 부모노드의 위치로 변경해준다.
*/
array[idx] = parentVal;
idx = parent;
}
// 최종적으로 삽입 될 위치에 타겟 노드 요소를 저장해준다.
array[idx] = target;
}
// 삽입 할 객체의 Comparable을 이용한 sift-up
@SuppressWarnings("unchecked")
private void siftUpComparable(int idx, E target) {
// 타겟노드가 비교 될 수 있도록 한 변수를 만든다.
Comparable<? super E> comp = (Comparable<? super E>) target;
// 노드 재배치 과정은 siftUpComparator와 같다.
while(idx > 1) {
int parent = getParent(idx);
Object parentVal = array[parent];
if(comp.compareTo((E)parentVal) >= 0) {
break;
}
array[idx] = parentVal;
idx = parent;
}
array[idx] = comp;
}주석으로 설명을 해 놓았지만, 다시 한 번 글로 설명을 하자면 이렇다.
일단 요소를 추가하기 전에 추가 할 공간이 있는지를 검사해야 한다. 만약 배열의 길이(용적)가 10이고, 요소의 개수인 size가 9일 경우 배열의 마지막 인덱스까지 꽉 찼다는 의미다. (힙은 index 1부터 채우므로)
그렇기에 용적의 크기를 2배로 늘려 준 뒤, siftUp 메소드를 호출 해준다.
그 다음 앞서 말했던 Comparator로 넘겨받은 것이 있는지, 없는지에 따라 Comparator가 있을 경우 compre()을, 없을 경우 compareTo()를 사용하여 요소를 비교해야 하므로 검사를 한 뒤 각각의 siftUp 메소드로 넘어가 재배치 작업을 해준다.
위와같이 추가해보다보면 알겠지만 결국 '마지막 삽입 되는 인덱스'부터 부모노드를 비교하면서 올라가기 때문에 항상 완전 이진 트리를 만족하면서, 부모노드는 자식노드보다 우선순위가 높다는 것 또한 침해받지 않는다.
그리고 만약 최대힙을 구현하고 싶은 경우 compare 혹은 compareTo에서의 >= 0 비교연산자를 <= 로 바꿔주면 된다.
[add 메소드 묶어보기]
[poll 메소드 구현]
그럼 삭제 및 반환은 어떻게 구현해야할까? 간단한 해답은 offer와 정반대로 하면 된다.
offer의 경우 맨 마지막 노드에 추가하고 부모노드와 비교하면서 자리를 찾아갔다. 이를 거꾸로 하면 삭제연산의 경우 root에 있는 노드를 삭제하고, 마지막에 위치해있던 노드를 root Node로 가져와 offer와는 반대로 자식노드가 재배치하려는 노드보다 크거나 자식노드가 없을 때 까지 자신의 위치를 찾아가면 된다.
이렇게 글로 쓰면 이해가 쉽게 되지 않을테니 한 번 그림으로 보자.
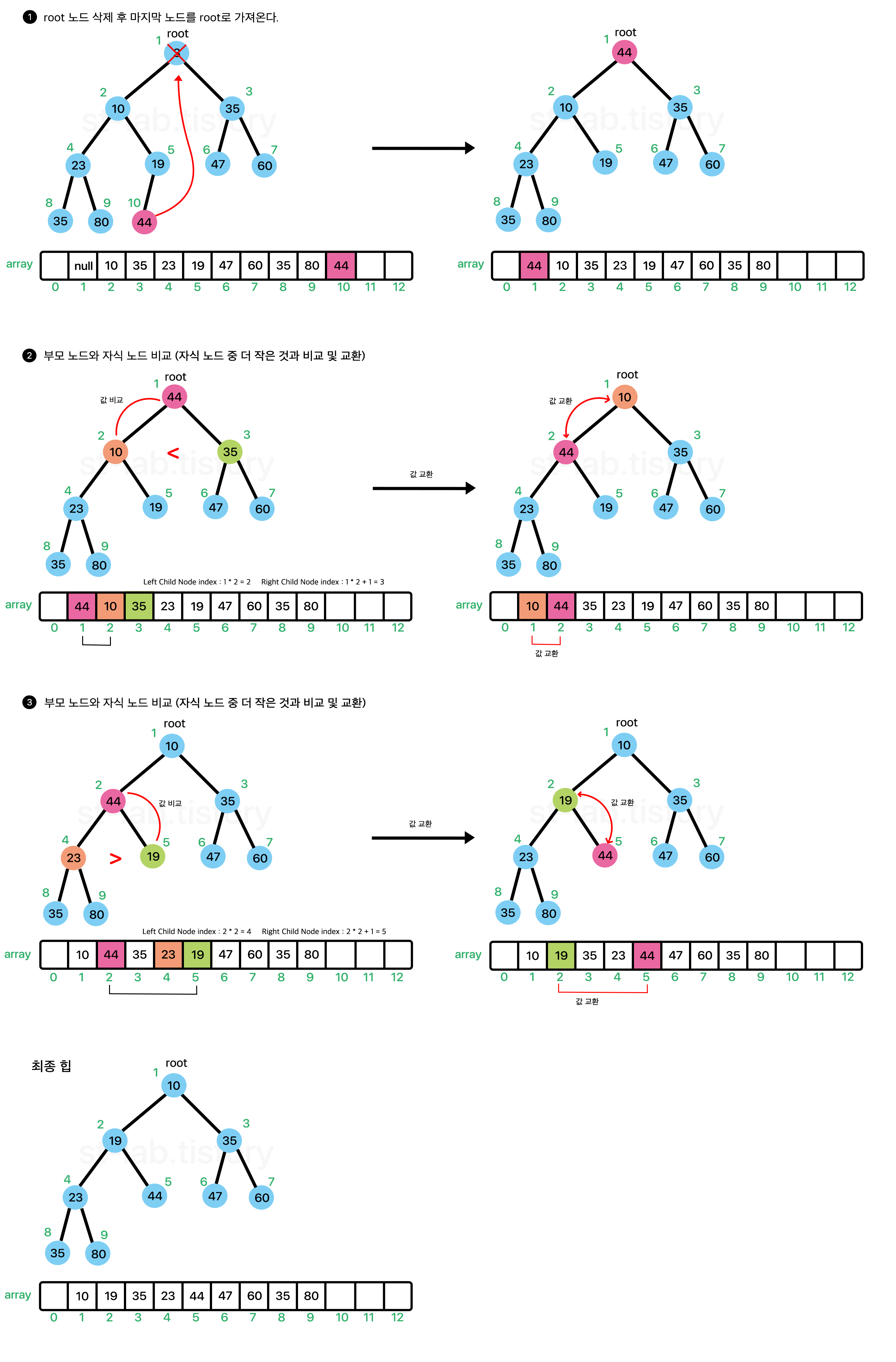
위와 같이 마지막 노드를 root노드로 가져온 뒤, 자식 노드와 비교하면서 자리를 찾아가면 된다. 즉, 비교 대상이 되는 '분홍색 노드'는 타겟(target)이 되는 것이다. 이 타겟을 다른 노드와 비교하면서 타겟 노드가 배치 될 자리를 찾아가야 한다.
중요한 점은 왼쪽 자식 노드와 오른쪽 자식 노드 중 '작은 값을 가진 노드'랑 재배치 할 노드와 비교해야한다.
그래야 최소 힙을 만족시킬 수 있다. 만약 반대로 된다면 첫 비교 교환 단계에서 35가 root노드에 배치되어버리는데, 이는 왼쪽 자식노드인 10보다 큰 값을 갖게 되면서 최소힙을 만족하지 못한다.
이렇게 아래로 내려가면서 재배치 하는 과정을 이러한 과정을 sift-down (하향 선별)이라고도 한다.
이렇게 삭제된 요소는 우선순위가 높은 순서대로 반환이 되는 것이다.
그리고 삽입과정과 마찬가지로 Comparator을 쓰느냐, Comparable을 쓰느냐를 나누면서 만들겠다.
참고로 여기서 추가 되는 것은 Queue API를 보면 알겠지만, remove()의 경우에는 뽑으려는 root 노드가 null일경우 예외(NoSuchElementException)를 던지지만, poll()의 경우는 null을 반환한다.
(참고 링크 : docs.oracle.com/en/java/javase/11/docs/api/java.base/java/util/Queue.html)
그러니 기존에 Heap 구현에서 썼던 remove()메소드를 그대로 갖고오면서 poll()이 remove()를 호출하도록 하겠다.
@Override
public E poll() {
// poll은 뽑으려는 요소(root)가 null일경우 null을 반환한다.
if(array[1] == null) {
return null;
}
// 그 외의 경우 remove()에서 반환되는 요소를 반환한다.
return remove();
}
@SuppressWarnings("unchecked")
public E remove() {
if(array[1] == null) { // 뽑으려눈 요소(root)가 null일경우 예외를 던지도록 한다.
throw new NoSuchElementException();
}
E result = (E) array[1]; // 삭제된 요소를 반환하기 위한 임시 변수
E target = (E) array[size]; // 타겟이 될 요소
array[size] = null; // 타겟 노드(index)을 비운다.
size--; // 사이즈를 1 감소
siftDown(1, target);
return result;
}
/**
* 하향 선별
*
* @param idx 삭제할 노드의 인덱스
* @param target 재배치 할 노드
*/
private void siftDown(int idx, E target) {
if(comparator != null) {
siftDownComparator(idx, target, comparator);
}
else {
siftDownComparable(idx, target);
}
}
// Comparator을 이용한 sift-down
@SuppressWarnings("unchecked")
private void siftDownComparator(int idx, E target, Comparator<? super E> comp) {
array[idx] = null; // 삭제 할 인덱스의 노드를 삭제
int parent = idx; // 삭제 노드부터 시작 할 부모 노드 인덱스를 가리키는 변수
int child; // 교환 될 자식 인덱스를 가리키는 변수
// 왼쪽 자식 노드의 인덱스가 요소의 개수보다 작을 때 까지 반복
while((child = getLeftChild(parent)) <= size) {
int right = getRightChild(parent); // 오른쪽 자식 인덱스
Object childVal = array[child]; // 왼쪽 자식의 값 (교환될 요소)
/*
* 오른쪽 자식 인덱스가 size를 넘지 않으면서
* 왼쪽 자식이 오른쪽 자식보다 큰 경우
* 재배치 할 노드는 작은 자식과 비교해야 하므로 child와 childVal을
* 오른쪽 자식으로 바꾸어 준다.
*/
if(right <= size && comp.compare((E) childVal, (E) array[right]) > 0) {
child = right;
childVal = array[child];
}
// 재배치 할 노드가 자식 노드보다 작을 경우 반복문을 종료
if(comp.compare(target ,(E) childVal) <= 0){
break;
}
/*
* 현재 부모 인덱스에 자식 노드 값을 대체해주고
* 부모 인덱스를 자식 인덱스로 교체
*/
array[parent] = childVal;
parent = child;
}
// 최종적으로 재배치 되는 위치에 타겟이 된 값을 넣어준다.
array[parent] = target;
/*
* 용적 사이즈가 최소 용적보다는 크면서 요소의 개수가 전체 용적의 1/4 미만일 경우
* 용적을 반으로 줄임 (단, 최소용적보단 커야 함)
*/
if(array.length > DEFAULT_CAPACITY && size < array.length / 4) {
resize(Math.max(DEFAULT_CAPACITY, array.length / 2));
}
}삭제 과정 위와 같이 하면 된다.
그리고 마찬가지로 최대 힙을 구현하고 싶다면 비교과정을 반대로 해주면 된다.
[remove 메소드 묶어보기]
[size, peek, isEmpty, contains, clear 메소드 구현]
현재 우선순위 큐에 저장 된 요소의 개수를 알고 싶을 때 size값을 리턴하기 위한 메소드로 size()를 하나 만들고, 또한 가장 우선순위가 높은 원소인 루트 노드의 값만 확인하고 싶을 때 쓰는 메소드를 위해 peek() 메소드를 만들 것이다. 데이터를 삭제하지 않고 확인만 하고싶을 때 쓰는 것이 peek() 메소드다. 한마디로 poll() 메소드에서 삭제과정만 없는 것이 peek() 이다.
그리고 의외로 자주 쓰이는 현재 우선순위 큐(Priority Queue)에 요소가 아무 것도 없는 경우를 판별하기 위한 메소드도 하나 만들어주자. 이 때 힙에 아무 요소가 없다는 것은 size 가 0이라는 소리이므로 size == 0 인지를 반환해주면 된다.
또한 contains로 찾고자 하는 요소가 PriorityQueue의 배열에 존재하는지 볼 수 있도록 아주 간단하게 구현해볼 것이다.
마지막으로 가끔 우선순위 큐에 있는 모두 요소들을 비우고싶을 때가 있다. 그럴 때 쓸 수 있는 clear 메소드도 같이 보도록 하자.
size, peek, isEmpty, contains, clear 메소드
public int size() {
return this.size;
}
@Override
@SuppressWarnings("unchecked")
public E peek() {
if(array[1] == null) { // root 요소가 null일 경우 예외 던짐
throw new NoSuchElementException();
}
return (E)array[1];
}
public boolean isEmpty() {
return size == 0;
}
public boolean contains(Object value) {
for(int i = 1; i <= size; i++) {
if(array[i].equals(value)) {
return true;
}
}
return false;
}
public void clear() {
for(int i = 0; i < array.length; i++) {
array[i] = null;
}
size = 0;
}[size, peek, isEmpty, toArray 메소드 묶어보기]
[toArray, clone 메소드 구현]
이 부분은 굳이 구현하는데 중요한 부분은 아니라 넘어가도 된다. 다만 조금 더 많은 기능을 원할 경우 추가해주면 좋은 메소드들이긴 하다. toArray는 사용자가 main 함수에서 특정 배열로 반환받고싶다거나 복사하고 싶을 때 PriorityQueue에 저장된 데이터들을 배열로 반환해주는 역할을 하기 위해 만들었다. clone은 기존에 있던 객체를 파괴하지 않고 요소들이 동일한 객체를 새로 하나 만드는 것이다.
1. toArray() 메소드
toArray()는 크게 두 가지가 있다.
하나는 아무런 인자 없이 현재 있는 큐의 요소들을 객체배열(Object[]) 로 반환해주는 Object[] toArray() 메소드가 있고,
다른 하나는 큐를 이미 생성 된 다른 배열에 복사해주고자 할 때 쓰는 T[] toArray(T[] a) 메소드가 있다.
즉 차이는 이런 것이다.
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();
// get priorityQueue to array (using toArray())
Object[] q1 = priorityQueue.toArray();
// get priorityQueue to array (using toArray(T[] a)
Integer[] q2 = new Integer[10];
q2 = priorityQueue.toArray(q2);1번의 장점이라면 우선순위 큐에 있는 요소의 수만큼 정확하게 배열의 크기가 할당되어 반환된다는 점이다.
2번의 장점이라면 객체 클래스로 상속관계에 있는 타입이거나 Wrapper(Integer -> int) 같이 데이터 타입을 유연하게 캐스팅할 여지가 있다는 것이다. 또한 큐의 원소 5개가 있고, q2 배열에 10개의 원소가 있다면 q2에 0~4 index에 원소가 복사되고, 그 외의 원소는 기존 q2배열에 초기화 되어있던 원소가 그대로 남는다.
두 메소드 모두 구현해보자면 다음과 같다.
public Object[] toArray() {
return toArray(new Object[size]);
}
@SuppressWarnings("unchecked")
public <T> T[] toArray(T[] a) {
if(a.length <= size) {
return (T[]) Arrays.copyOfRange(array, 1, size + 1, a.getClass());
}
System.arraycopy(array, 1, a, 0, size);
return a;
}먼저 첫 번째 toArray() 메소드의 경우 두 번째 toArray(T[] a) 로 보내도록 하겠다. (동작 구현이 겹치기 때문이다.)
두 번째 T[] toArray(T[] a) 메소드를 보자.
이 부분은 제네릭 메소드로, 우리가 만들었던 PriorityQueue의 E타입하고는 다른 제네릭이다. 예로들어 E Type이 Integer라고 가정하고, T타입은 Object 라고 해보자.
Object는 Integer보다 상위 타입으로, Object 안에 Integer 타입의 데이터를 담을 수도 있다. 이 외에도 사용자가 만든 부모, 자식 클래스 같이 상속관계에 있는 클래스들에서 하위 타입이 상위 타입으로 데이터를 받고 싶을 때 쓸 수 있도록 하기 위함이다.
즉, 상위타입으로 들어오는 객체에 대해서도 데이터를 담을 수 있도록 별도의 제네릭메소드를 구성하는 것이다.
그리고 중요한 점이 있다. 기본적으로 toArray(T[] a) 에서 a로 들어오는 파라미터 배열의 길이가 우선순위 큐에 들어있는 요소 개수보다 작은 경우 요소 개수를 모두 복사할 수 있도록 고려해야한다는 점이다.
그러면 크게 두 가지로 나누어 볼 수 있다.
하나는 a 배열이 현재 우선순위 큐에 요소보다 작은 사이즈일 경우다. 그럴 때는 Arrays 클래스의 copyOfRange()메소드를 활용하면 된다.
copyOfRange() 메소드에 대한 자세한 내용은 아래를 보면 된다.
쉽게 말하면 이렇다.
copyOfRange(원본 배열, 복사 시작 위치, 복사 끝 위치(포함X), 반환 될 배열 클래스(타입))
위 적용을 예로 설명하자면 이렇다.
array를 대상으로 복사를 하는데, 첫번째 위치부터 size + 1 직전 위치까지 복사(1 ≤ index < size + 1)하여 a 의 클래스 타입으로 반환하겠다는 것이다.
우선순위 큐의 원소를 첫 번째 부터 복사하는 이유는 우선순위 큐의 index 0은 항상 비워두고 첫 번째 인덱스부터 시작하기 때문이다.
그 외에는 우선순위 큐의 요소 개수보다 a 배열이 더 큰 경우이므로, 우선순위 큐의 첫 번째 인덱스부터 size 위치까지의 요소를 a 배열에 0번째 인덱스부터 복사해주면 된다.
이는 System.arraycopy() 메소드를 써주면 된다.
만약 파라미터로 들어오는 배열의 경우 Arrays.copyOfRange() 로 지정된 범위 만큼 복사하여 크기를 맞춰주어야 하며, front와 rear의 위치에 따라 front가 rear보다 앞에 있는 경우 front + 1 ~ rear 까지 복사하면 되고, 만약 rear가 front 가 앞설 경우 front + 1 부터 시작하는 뒷 부분을 먼저 저장 한 뒤, 0번째부터 rear까지 뒤이어서 복사해주어야 한다
2. clone() 메소드
만약 사용자가 사용하고 있던 PriorityQueue를 새로 하나 복제하고 싶을 때 쓰는 메소드다. Java에서는 PriorityQueue에 clone() 메소드를 제공하지는 않고 생성자에 PriorityQueue를 파라미터로 넘겨줌으로써 만드는 방식으로 지원하고 있다.
하지만, 그렇게 하기에는 글이 길어지기도 하고 가장 쉽게 클로닝을 하기 위해 작성했다.
clone()은 얕은 복사가 아닌 깊은 복사로 아예 다른 하나의 클론을 만드는 것이다.
단순히 = 연산자로 객체를 복사하게 되면 '주소'를 복사하는 것이기 때문에 복사한 객체에서 데이터를 조작할 경우 원본 객체까지 영향을 미친다. 즉 얕은 복사(shallow copy)가 된다는 것이다.
PriorityQueue<Integer> original = new PriorityQueue<>();
original.offer(10); // original에 10추가
PriorityQueue<Integer> copy = original;
copy.offer(20); // copy에 20추가
System.out.println("original PriorityQueue");
int i = 0;
for(Object a : original.toArray()) {
System.out.println(i + "번 째 data = " + a);
i++;
}
System.out.println("\ncopy PriorityQueue");
i = 0;
for(Object a : copy.toArray()) {
System.out.println(i + "번 째 data = " + a);
i++;
}
System.out.println("\noriginal PriorityQueue reference : " + original);
System.out.println("copy PriorityQueue reference : " + copy);[결과]
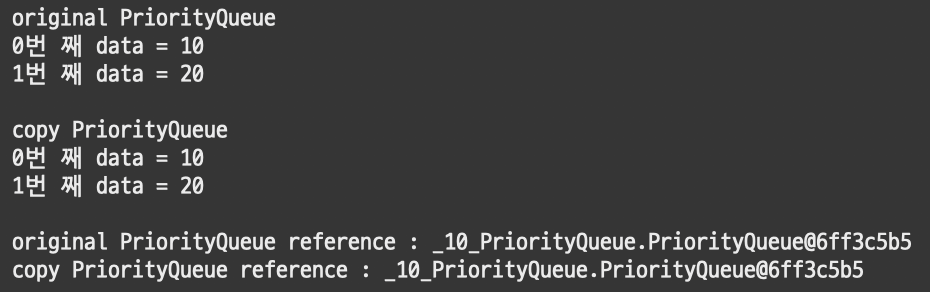
보다시피 객체의 주소가 복사되는 것이기 때문에 주소와 데이터 모두 같아져버리는 문제가 발생한다.
이러한 것을 방지하기 위해서 깊은 복사를 하는데, 이 때 필요한 것이 바로 clone()이다. Object에 있는 메소드이지만 접근제어자가 protected로 되어있어 구현해야 할 경우 반드시 Clonable 인터페이스를 implement 해야한다.
즉, public class PriorityQueue implements Queue 에 Cloneable도 추가해주어야 한다.
그리고나서 clone()을 구현하면 되는데, 다음과 같이 재정의를 하면 된다.
@Override
public Object clone() {
// super.clone()은 CloneNotSupportedException 예외를 처리해주어야 한다.
try {
PriorityQueue<?> cloneHeap = (PriorityQueue<?>) super.clone();
cloneHeap.array = new Object[size + 1];
// 단순히 clone()만 한다고 내부 데이터까지 깊은 복사가 되는 것이 아니므로 내부 데이터들도 모두 복사해준다.
System.arraycopy(array, 0, cloneHeap.array, 0, size + 1);
return cloneHeap;
}
catch (CloneNotSupportedException e) {
throw new Error(e);
}
}조금 어려워 보일 수 있는데, 이해하지 못해도 된다. 자료구조에서 중요한 부분은 아니니...
설명을 덧붙이자면, super.clone() 자체가 생성자 비슷한 역할이고 shallow copy를 통해 사실상 new PriorityQueue<>() 를 호출하는 격이라 제대로 완벽하게 복제하려면 clone한 큐의 array 또한 새로 생성해서 해당 배열에 copy를 해주어야 한다.
위와같이 만들고 나서 clone()한 것 까지 포함해서 테스트를 해보자.
PriorityQueue<Integer> original = new PriorityQueue<>();
original.offer(10); // original에 10추가
PriorityQueue<Integer> copy = original;
PriorityQueue<Integer> clone = (PriorityQueue<Integer>) original.clone();
copy.offer(20); // copy에 20추가
clone.offer(30); // clone에 30추가
System.out.println("original PriorityQueue");
int i = 0;
for (Object a : original.toArray()) {
System.out.println(i + "번 째 data = " + a);
i++;
}
System.out.println("\ncopy PriorityQueue");
i = 0;
for (Object a : copy.toArray()) {
System.out.println(i + "번 째 data = " + a);
i++;
}
System.out.println("\nclone PriorityQueue");
i = 0;
for (Object a : clone.toArray()) {
System.out.println(i + "번 째 data = " + a);
i++;
}
System.out.println("\noriginal PriorityQueue reference : " + original);
System.out.println("copy PriorityQueue reference : " + copy);
System.out.println("clone PriorityQueue reference : " + clone);[결과]
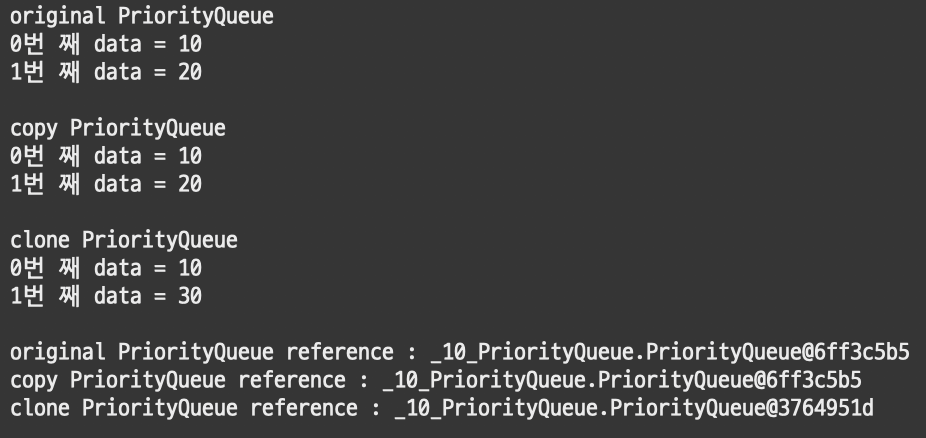
결과적으로 clone으로 복사한 PriorityQueue 는 원본 PriorityQueue에 영향을 주지 않는다.
[toArray, clone 메소드 묶어보기]
- 전체 코드
import java.util.Arrays;
import Interface_form.Queue;
import java.util.Comparator;
import java.util.NoSuchElementException;
public class PriorityQueue<E> implements Queue<E>, Cloneable {
private final Comparator<? super E> comparator;
private static final int DEFAULT_CAPACITY = 10; // 최소(기본) 용적 크기
private int size; // 요소 개수
private Object[] array; // 요소를 담을 배열
// 생성자 Type 1 (초기 공간 할당 X)
public PriorityQueue() {
this(null);
}
public PriorityQueue(Comparator<? super E> comparator) {
this.array = new Object[DEFAULT_CAPACITY];
this.size = 0;
this.comparator = comparator;
}
// 생성자 Type 2 (초기 공간 할당 O)
public PriorityQueue(int capacity) {
this(capacity, null);
}
public PriorityQueue(int capacity, Comparator<? super E> comparator) {
this.array = new Object[capacity];
this.size = 0;
this.comparator = comparator;
}
// 받은 인덱스의 부모 노드 인덱스를 반환
private int getParent(int index) {
return index / 2;
}
// 받은 인덱스의 왼쪽 자식 노드 인덱스를 반환
private int getLeftChild(int index) {
return index * 2;
}
// 받은 인덱스의 오른쪽 자식 노드 인덱스를 반환
private int getRightChild(int index) {
return index * 2 + 1;
}
/**
* @param newCapacity 새로운 용적 크기
*/
private void resize(int newCapacity) {
// 새로 만들 배열
Object[] newArray = new Object[newCapacity];
// 새 배열에 기존에 있던 배열의 요소들을 모두 복사해준다.
for(int i = 1; i <= size; i++) {
newArray[i] = array[i];
}
/*
* 현재 배열은 GC 처리를 위해 null로 명확하게 처리한 뒤
* 새 배열을 array에 연결해준다.
*/
this.array = null;
this.array = newArray;
}
@Override
public boolean offer(E value) {
// 배열 용적이 꽉 차있을 경우 용적을 두 배로 늘려준다.
if(size + 1 == array.length) {
resize(array.length * 2);
}
siftUp(size + 1, value); // 가장 마지막에 추가되는 위치와 넣을 값(타겟)을 넘겨줌
size++; // 정상적으로 재배치가 끝나면 사이즈(요소 개수) 증가
return true;
}
/**
* 상향 선별
*
* @param idx 추가할 노드의 인덱스
* @param target // 재배치 할 노드
*/
private void siftUp(int idx, E target) {
if(comparator != null) {
siftUpComparator(idx, target, comparator);
}
else {
siftUpComparable(idx, target);
}
}
// Comparator을 이용한 sift-up
@SuppressWarnings("unchecked")
private void siftUpComparator(int idx, E target, Comparator<? super E> comp) {
// root노드보다 클 때 까지만 탐색한다.
while(idx > 1) {
int parent = getParent(idx); // 삽입노드의 부모노드 인덱스 구하기
Object parentVal = array[parent]; // 부모노드의 값
// 타겟 노드 우선순위(값)이 부모노드보다 크면 반복문 종료
if(comp.compare(target, (E) parentVal) >= 0) {
break;
}
/*
* 부모노드가 타겟노드보다 우선순위가 크므로
* 현재 삽입 될 위치에 부모노드 값으로 교체해주고
* 타겟 노드의 위치를 부모노드의 위치로 변경해준다.
*/
array[idx] = parentVal;
idx = parent;
}
// 최종적으로 삽입 될 위치에 타겟 노드 요소를 저장해준다.
array[idx] = target;
}
// 삽입 할 객체의 Comparable을 이용한 sift-up
@SuppressWarnings("unchecked")
private void siftUpComparable(int idx, E target) {
// 타겟노드가 비교 될 수 있도록 한 변수를 만든다.
Comparable<? super E> comp = (Comparable<? super E>) target;
// 노드 재배치 과정은 siftUpComparator와 같다.
while(idx > 1) {
int parent = getParent(idx);
Object parentVal = array[parent];
if(comp.compareTo((E)parentVal) >= 0) {
break;
}
array[idx] = parentVal;
idx = parent;
}
array[idx] = comp;
}
@Override
public E poll() {
// poll은 뽑으려는 요소(root)가 null일경우 null을 반환한다.
if(array[1] == null) {
return null;
}
// 그 외의 경우 remove()에서 반환되는 요소를 반환한다.
return remove();
}
@SuppressWarnings("unchecked")
public E remove() {
if(array[1] == null) { // 뽑으려눈 요소(root)가 null일경우 예외를 던지도록 한다.
throw new NoSuchElementException();
}
E result = (E) array[1]; // 삭제된 요소를 반환하기 위한 임시 변수
E target = (E) array[size]; // 타겟이 될 요소
array[size] = null; // 타겟 노드(index)을 비운다.
size--; // 사이즈를 1 감소
siftDown(1, target);
return result;
}
/**
* 하향 선별
*
* @param idx 삭제할 노드의 인덱스
* @param target 재배치 할 노드
*/
private void siftDown(int idx, E target) {
if(comparator != null) {
siftDownComparator(idx, target, comparator);
}
else {
siftDownComparable(idx, target);
}
}
// Comparator을 이용한 sift-down
@SuppressWarnings("unchecked")
private void siftDownComparator(int idx, E target, Comparator<? super E> comp) {
array[idx] = null; // 삭제 할 인덱스의 노드를 삭제
int parent = idx; // 삭제 노드부터 시작 할 부모 노드 인덱스를 가리키는 변수
int child; // 교환 될 자식 인덱스를 가리키는 변수
// 왼쪽 자식 노드의 인덱스가 요소의 개수보다 작을 때 까지 반복
while((child = getLeftChild(parent)) <= size) {
int right = getRightChild(parent); // 오른쪽 자식 인덱스
Object childVal = array[child]; // 왼쪽 자식의 값 (교환될 요소)
/*
* 오른쪽 자식 인덱스가 size를 넘지 않으면서
* 왼쪽 자식이 오른쪽 자식보다 큰 경우
* 재배치 할 노드는 작은 자식과 비교해야 하므로 child와 childVal을
* 오른쪽 자식으로 바꾸어 준다.
*/
if(right <= size && comp.compare((E) childVal, (E) array[right]) > 0) {
child = right;
childVal = array[child];
}
// 재배치 할 노드가 자식 노드보다 작을 경우 반복문을 종료
if(comp.compare(target ,(E) childVal) <= 0){
break;
}
/*
* 현재 부모 인덱스에 자식 노드 값을 대체해주고
* 부모 인덱스를 자식 인덱스로 교체
*/
array[parent] = childVal;
parent = child;
}
// 최종적으로 재배치 되는 위치에 타겟이 된 값을 넣어준다.
array[parent] = target;
/*
* 용적 사이즈가 최소 용적보다는 크면서 요소의 개수가 전체 용적의 1/4 미만일 경우
* 용적을 반으로 줄임 (단, 최소용적보단 커야 함)
*/
if(array.length > DEFAULT_CAPACITY && size < array.length / 4) {
resize(Math.max(DEFAULT_CAPACITY, array.length / 2));
}
}
@SuppressWarnings("unchecked")
private void siftDownComparable(int idx, E target) {
Comparable<? super E> comp = (Comparable<? super E>) target;
array[idx] = null;
int parent = idx;
int child;
while((child = (parent << 1)) <= size) {
int right = child + 1;
Object c = array[child];
if(right <= size && ((Comparable<? super E>)c).compareTo((E)array[right]) > 0) {
child = right;
c = array[child];
}
if(comp.compareTo((E) c) <= 0){
break;
}
array[parent] = c;
parent = child;
}
array[parent] = comp;
if(array.length > DEFAULT_CAPACITY && size < array.length / 4) {
resize(Math.max(DEFAULT_CAPACITY, array.length / 2));
}
}
public int size() {
return this.size;
}
@Override
@SuppressWarnings("unchecked")
public E peek() {
if(array[1] == null) {
throw new NoSuchElementException();
}
return (E)array[1];
}
public boolean isEmpty() {
return size == 0;
}
public boolean contains(Object value) {
for(int i = 1; i <= size; i++) {
if(array[i].equals(value)) {
return true;
}
}
return false;
}
public void clear() {
for(int i = 0; i < array.length; i++) {
array[i] = null;
}
size = 0;
}
public Object[] toArray() {
return toArray(new Object[size]);
}
@SuppressWarnings("unchecked")
public <T> T[] toArray(T[] a) {
if(a.length <= size) {
return (T[]) Arrays.copyOfRange(array, 1, size + 1, a.getClass());
}
System.arraycopy(array, 1, a, 0, size);
return a;
}
@Override
public Object clone() {
// super.clone()은 CloneNotSupportedException 예외를 처리해주어야 한다.
try {
PriorityQueue<?> cloneHeap = (PriorityQueue<?>) super.clone();
cloneHeap.array = new Object[size + 1];
// 단순히 clone()만 한다고 내부 데이터까지 깊은 복사가 되는 것이 아니므로 내부 데이터들도 모두 복사해준다.
System.arraycopy(array, 0, cloneHeap.array, 0, size + 1);
return cloneHeap;
}
catch (CloneNotSupportedException e) {
throw new Error(e);
}
}
}- 정리
오늘은 다른 때와 달리 이전 포스팅에서 다루던 힙을 그대로 이용하는 것이라 어렵지않게 구현해보았다.
아,, 위에서 구현한 코드가 잘 작동하는지 궁금하실 수도 있겠다.
마지막으로 테스트 한 것을 보여주고 이 포스팅을 마치도록 하겠다.
[test.java]
package _10_PriorityQueue;
import java.util.Random;
import java.util.Comparator;
public class test {
public static void main(String[] args) {
PriorityQueue<Student> pq1 = new PriorityQueue<>(); // Comparable 정렬 순서
PriorityQueue<Student> pq2 = new PriorityQueue<>(comp); // Comparator 정렬 순서
Random rnd = new Random();
char name = 'A';
for (int i = 0; i < 10; i++) {
int math = rnd.nextInt(10);
int science = rnd.nextInt(10);
pq1.offer(new Student(name, math, science));
pq2.offer(new Student(name, math, science));
name++;
}
// 힙 내부 배열의 요소 상태
System.out.println("[pq1 내부 배열 상태]");
for (Object val : pq1.toArray()) {
System.out.print(val);
}
System.out.println();
System.out.println();
// 힙 내부 배열의 요소 상태
System.out.println("[pq2 내부 배열 상태]");
for (Object val : pq2.toArray()) {
System.out.print(val);
}
System.out.println();
System.out.println();
System.out.println("[수학-과학-이름순 뽑기]");
System.out.println("name\tmath\tscience");
while(!pq1.isEmpty()) {
System.out.print(pq1.poll());
}
System.out.println();
System.out.println("[과학-수학-이름순 뽑기]");
System.out.println("name\tmath\tscience");
while(!pq2.isEmpty()) {
System.out.print(pq2.poll());
}
}
private static Comparator<Student> comp = new Comparator<Student>() {
/*
* 과학점수가 높은 순
* 과학점수가 같을 경우 수학 점수가 높은순
* 둘 다 같을 경우 이름순
*/
@Override
public int compare(Student o1, Student o2) {
if(o1.science == o2.science) {
if(o1.math == o2.math) {
return o1.name - o2.name;
}
return o2.math - o1.math;
}
return o2.science - o1.science;
}
};
static class Student implements Comparable<Student> {
char name;
int math;
int science;
public Student(char name, int math, int science) {
this.name = name;
this.math = math;
this.science = science;
}
/*
* 수학점수가 높은 순
* 수학점수가 같을 경우 과학 점수가 높은순
* 둘 다 같을 경우 이름순
*/
@Override
public int compareTo(Student o) {
if (this.math == o.math) {
if (this.science == o.science) {
return this.name - o.name;
}
return o.science - this.science;
}
return o.math - this.math;
}
public String toString() {
return name + "\t" + math + "\t" + science + "\n";
}
}
}[결과]
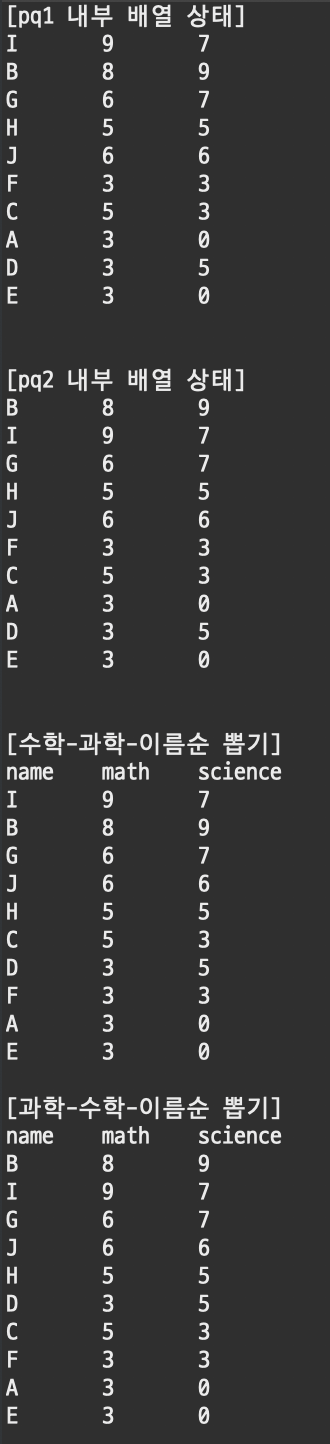
원하는 우선순위에 맞게 잘 순서대로 나오는 것을 볼 수 있다.
