[논문리뷰] TimeMixer++: A General Time Series Pattern Machine for Universal Predictive Analysis
Time Series
논문 원문 링크: Paper
이번 ICLR 2025 submit된 논문인데 아마 accept될 것으로 보인다.
시계열 task를 전반적으로 모두 해결할 수 있는 통합된 프레임워크로 전체 태스크에서 모두 좋은 성능을 보인다는 것이 정말 대단하다고 느꼈다. 아래는 간략하게 정리한 내용이다.
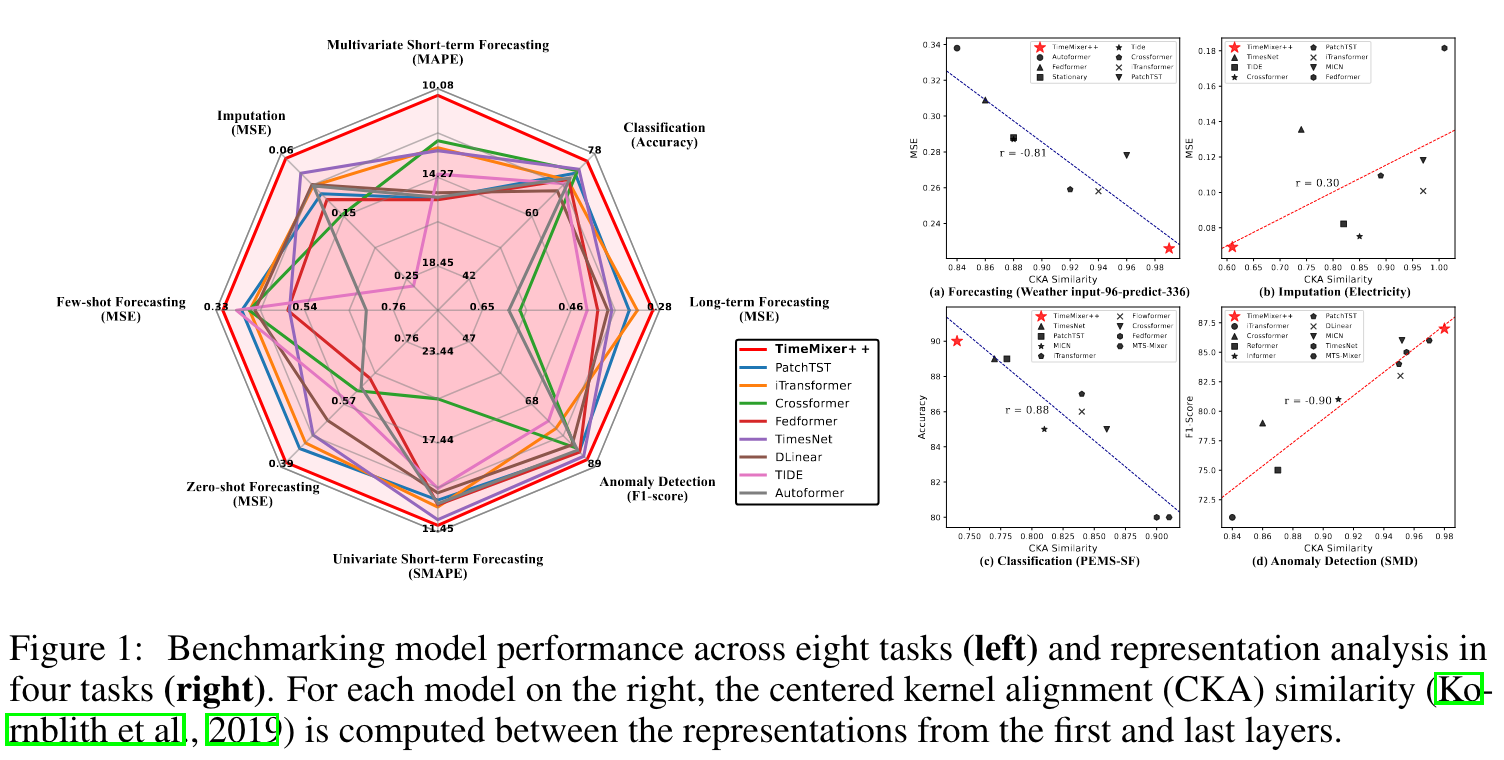
Intro
- TSPM (TIme Series pattern Machines): 다양한 시계열 문제를 한번에 풀 수 있는 모델
- 시계열 task의 경우 하나의 문맥이 있는 언어 태스크와 달리 일/주/연간의 단위로 나타나는 패턴의 오버랩이 태스크 해결을 어렵게 한다. 여기서 주된 연구 문제가 시작되는데, 바로 모델은 어떤일을 해야하며, 어떤 과제를 이겨내야하는가? 이다.
- 시계열 데이터는 multi scale, multi periodicity로 이루어져 있고, 각기 다른 temporal dynamics를 가진다. 예를 들어, CKA similarity가 낮은 경우는 더 다양한 representation이 존재하여 imputation, anomaly detection에는 유용하지만 forecasting, classification 등을 하고자 할 때에는 similarity가 높은 경우가 더 유리하다.
- CKA similarity: representation matrix 간의 유사도를 판단하는 기준으로 중심정렬커널을 통해 측정한다.
- https://cka-similarity.github.io
- TimeMixer++ 는 이런 다양한 상황을 반영하여 여러 태스크에 폭넓게 적용하기 위하여 4가지 프로세스를 혼합한다.
- Multi-resolution time imaging : Multi-scale 시계열을 multi-resolution 시계열로 변환 : temporal과 frequency 도메인에서 모두 feature를 가져올 수 있게 함
- time image decomposition : dual-axis attention을 통해 trend 와 seasonal 정보를 나누어 볼 수 있게 함
- multi-scale mixing : hierarchical하게 추출된 패턴들을 스케일 단위로 취합함
- multi-resolution mixing : 전체 resolution에 대해 추출된 정보들을 모두 혼합함
- 이러한 과정을 거쳐 TimeMixer++는 8개 task에서 general purpose, specific purpose model들을 모두 압도하는 성능을 보였으며 CKA similiarity score이 계속 변화하는 모습을 보여 여러가지 태스크에서 모두 잘 할 수 있음을 확인시켜주었다.
- Contributions
- TimeMixer++를 제안하고 시계열을 multi-resolution time image로 변환해 temporal, frequency domain 모두에서 pattern extraction을 가능케함
- Seasonality 와 trend 를 time image decomposition을 통해 분해하고 adaptive aggregation을 통해 여러 스케일과 주파수에서의 Pattern integration을 가능케 함
- 8개 task에 대해서 모두 SOTA를 기록함
Method: TimeMixer++
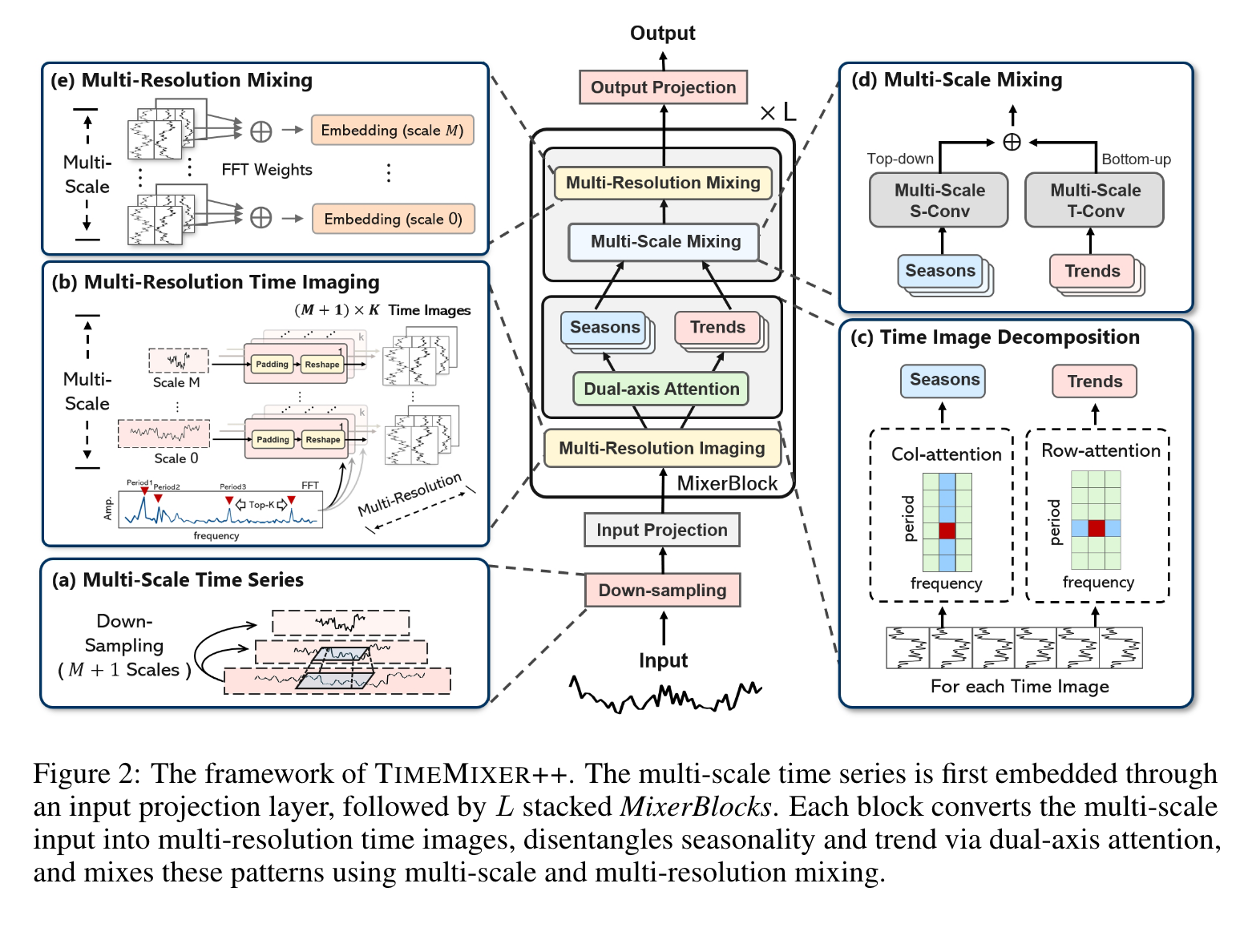
- 전체 아키텍처는 3개의 요소로 구성됨
- input projection : 기존에는 채널 간 독립적인 전략을 사용했으나 여기에선 channel mixing 을 이용하여 cross variable interation을 이용하고자 함
- channel mixing: self-attention to variate dimension at the coarsest scale : 최대한 글로벌한 문맥 정보를 가져와서 변수 간 정보 혼합을 효과적으로 하고자 함
- Q, K, V는 Linear mapping
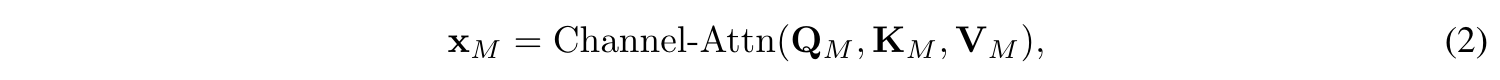
- Q, K, V는 Linear mapping
- embedding: multi scale time series 를 deep pattern set으로 embedding
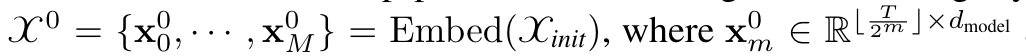
- channel mixing: self-attention to variate dimension at the coarsest scale : 최대한 글로벌한 문맥 정보를 가져와서 변수 간 정보 혼합을 효과적으로 하고자 함
- Mixer blocks: L개의 블록을 쌓아서 multi-scale representation set X^L을 생성함
- residual way로 쌓아서 잔차 연결도 진행함
- output projection
-
task마다 다양한 패턴을 보이므로 여러개의 Prediction head를 사용하고 각 head의 결과를 앙상블
→ task adaptive : 하나의 헤드가 자기 스케일에 연관된 feature에 집중하게 할 수 있음
→ 앙상블을 통해 추가적으로 필요한 정보들을 덧붙일 수 있음
-
- input projection : 기존에는 채널 간 독립적인 전략을 사용했으나 여기에선 channel mixing 을 이용하여 cross variable interation을 이용하고자 함
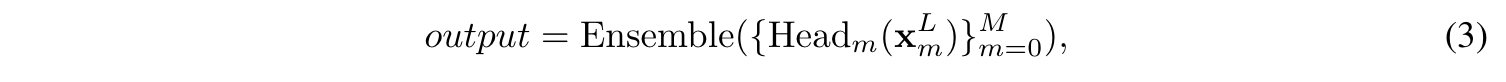
- Multi-scale time series : 하나의 input 시계열이 주어졌을 때 downsampling을 통해 multi-scale representation을 만듦(conv(stride=2)
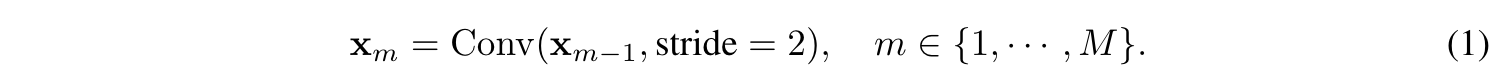
MixerBlock
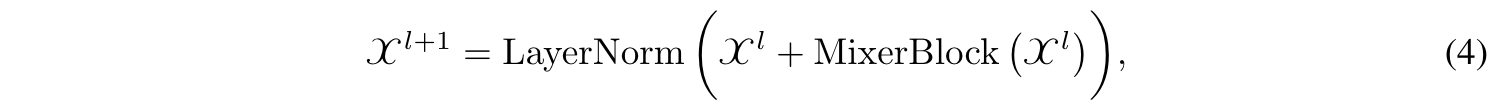
-
시계열을 multi-scale과 multi-periodic 으로 분석하기 위해서 multi-resolution time image로 바꿔서 분석함. 이 때 frequency analysis를 활용하여 기존 데이터를 보존하고자 함
-
Multi-resolution time imaging: coarsest scale로 파악해서 먼저 주기성 확인, global interaction을 확인(FFT 적용하여 top -K개의 highest amplitude 선택)

- 즉 푸리에 변환 → topK개의 주기 선택 → 변환된 것 만큼가져오고 빈 부분에 대해서 패딩, 2D로 변환
-
Time image decomposition
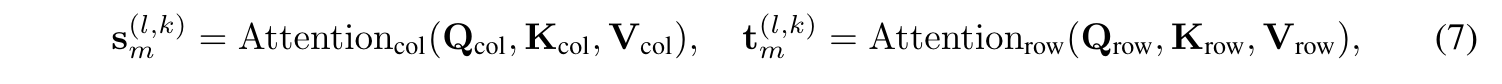
- multi-resolution image로 처리함으로서 moving average보다 더 정교하게 seasonality와 trend를 바꿀 수 있게됨.
- 2D convolution을 통해 long range patternr과 temporal dependency 를 추출할 수 있게 함
- column-wise Attention : seasonality across periods
- Row-wise attention : trend across periods
- Q, K, V 는 둘 다 2D convolution을 통해 처리함
-
multi-scale mixing
-
각 period 마다 M+1개의 seasonal time image, trend time image를 얻게 됨
-
계절성 이미지에 대해서 긴 패턴은 작은 패턴들의 조합이라고 볼 수 있음. 따라서 여기서는 fine-scale에서 coarse-scale 순으로 조합을 진행함. 2D convolution 을 mth scale에 residual 을 포함하여 적용
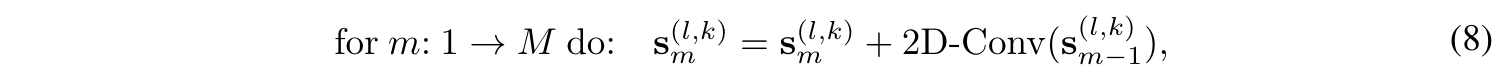
-
trend는 반대로 coarse scale이 전체적인 트렌드를 보여주므로 top-down으로 mixing을 진행함
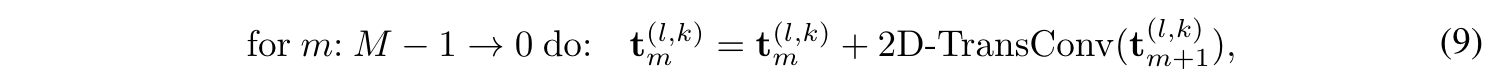
-
mixing 후에 pattern aggregation을 진행함
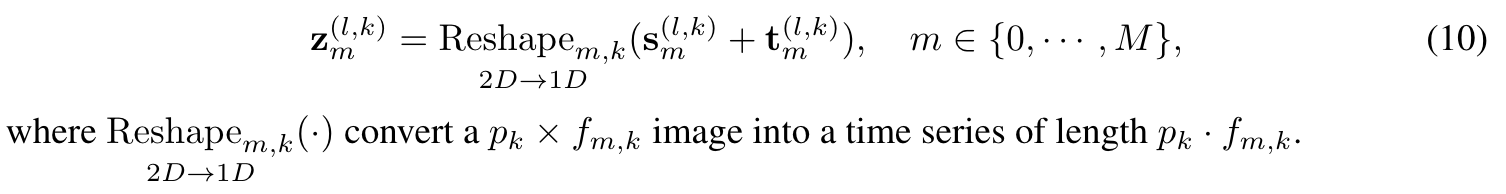
-
- multi-resolution mixing
- K개의 period에 대해서 mixing을 진행함. Amplitude가 각 period의 중요성을 보여주므로 이것을 기준으로 mixing을 진행
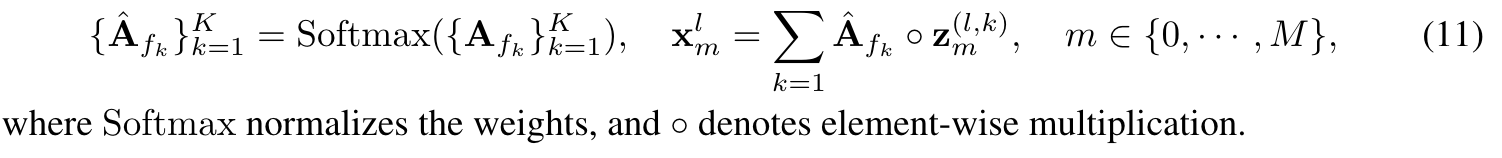
- K개의 period에 대해서 mixing을 진행함. Amplitude가 각 period의 중요성을 보여주므로 이것을 기준으로 mixing을 진행
Experiments
-
8개의 task에서 30개의 벤치마크에 대해 27개의 베이스라인을 제치는 좋은 성능을 보였음
-
실험한 task
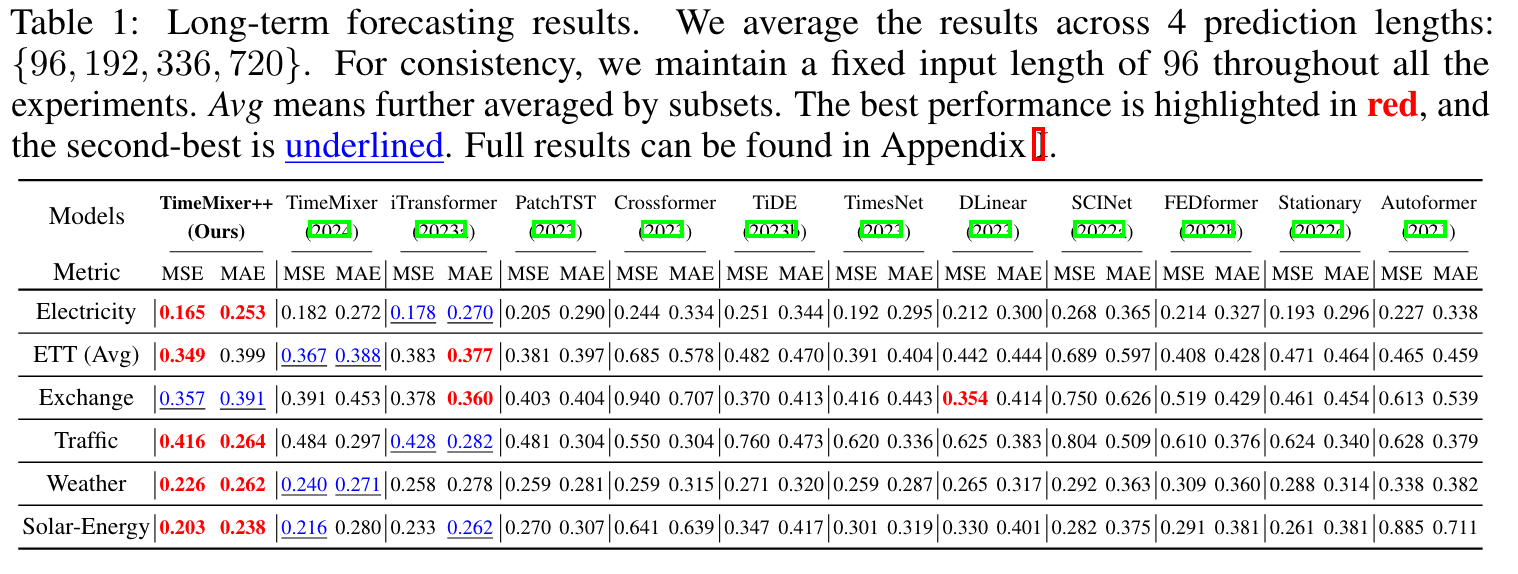
-
long term forecasting (ETT, Electricity, Weather, Traffic, Solar) : 비등~상향
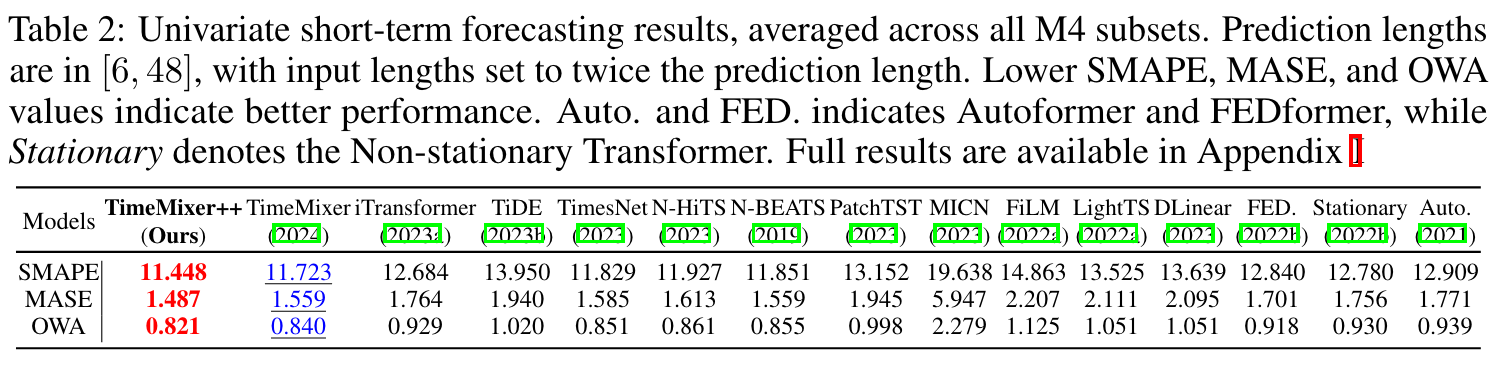
-
univariate short-term forecasting (M4) : 상향
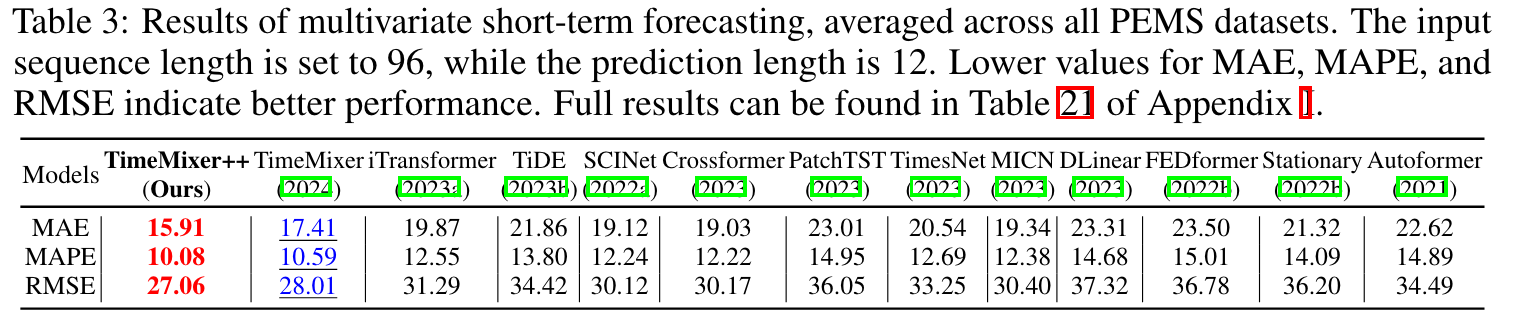
-
Multivariate short-term forecasting (PEMS03, PEMS04, PEMS07, PEMS08): 상향

-
Imputation (ETT, ECL, Weather) : improved
- especially when input length upto 1K - very robust
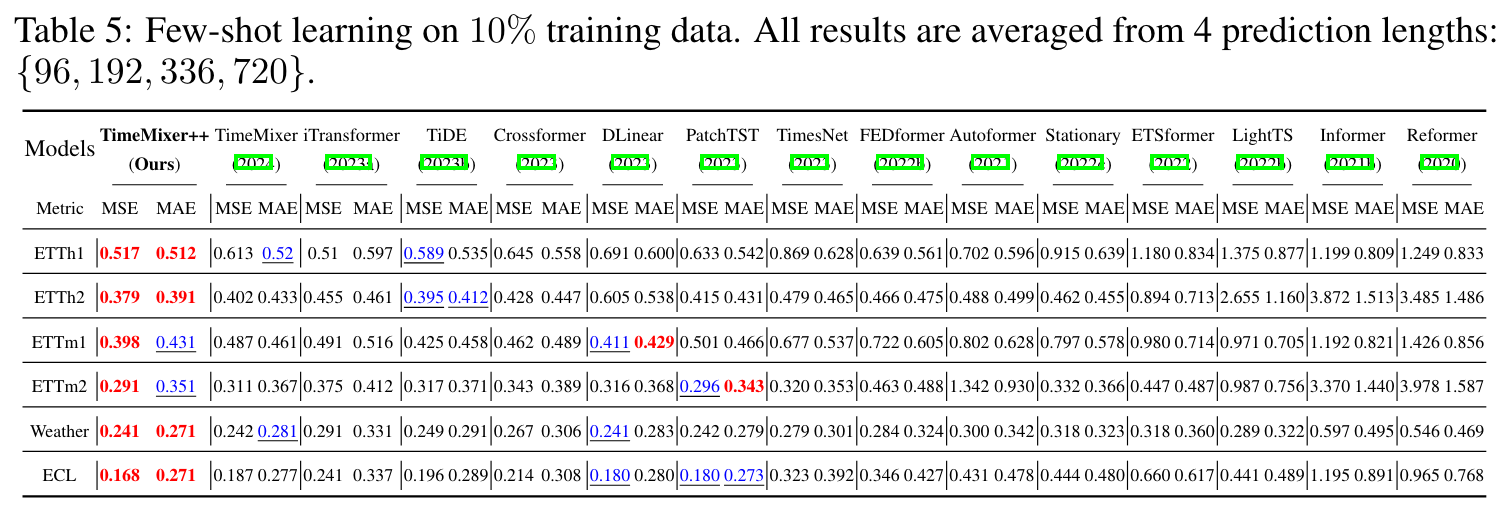
- especially when input length upto 1K - very robust
-
Few-shot forecasting (ETT, ECL, Weather) : improved
- 다른 데이터셋으로 학습, 예측할 데이터셋 10%만 볼 수 있게 하기
- 다른 데이터셋으로 학습, 예측할 데이터셋 10%만 볼 수 있게 하기
-
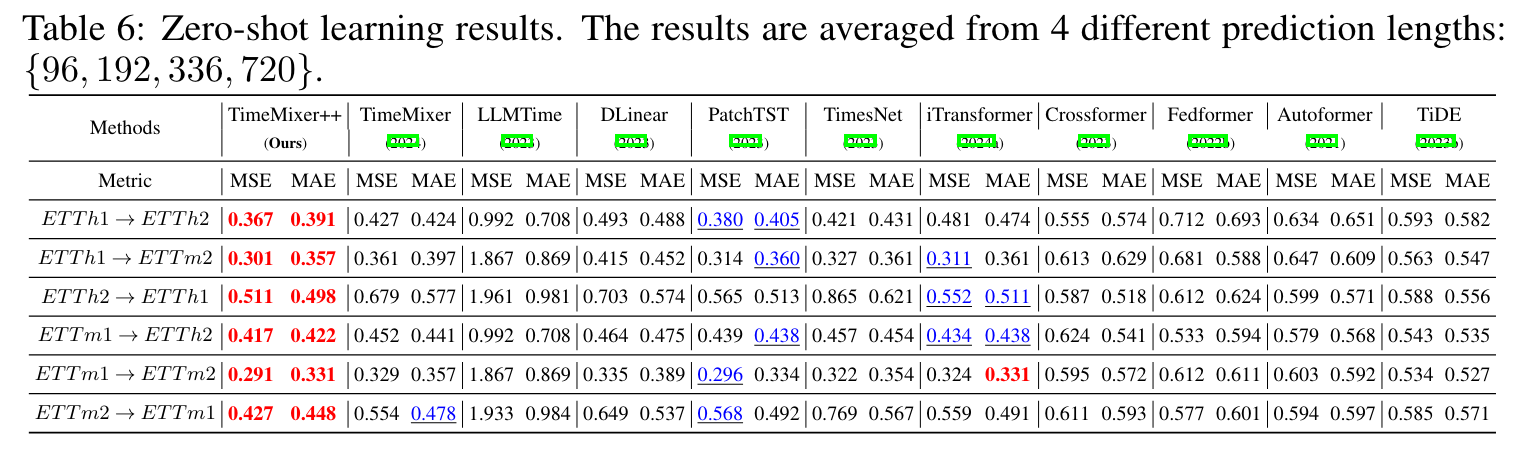
Zero-shot forecasting : improved
- A dataset으로 학습된 모델에게 B 데이터셋 결과 예측시키기
- A dataset으로 학습된 모델에게 B 데이터셋 결과 예측시키기
-
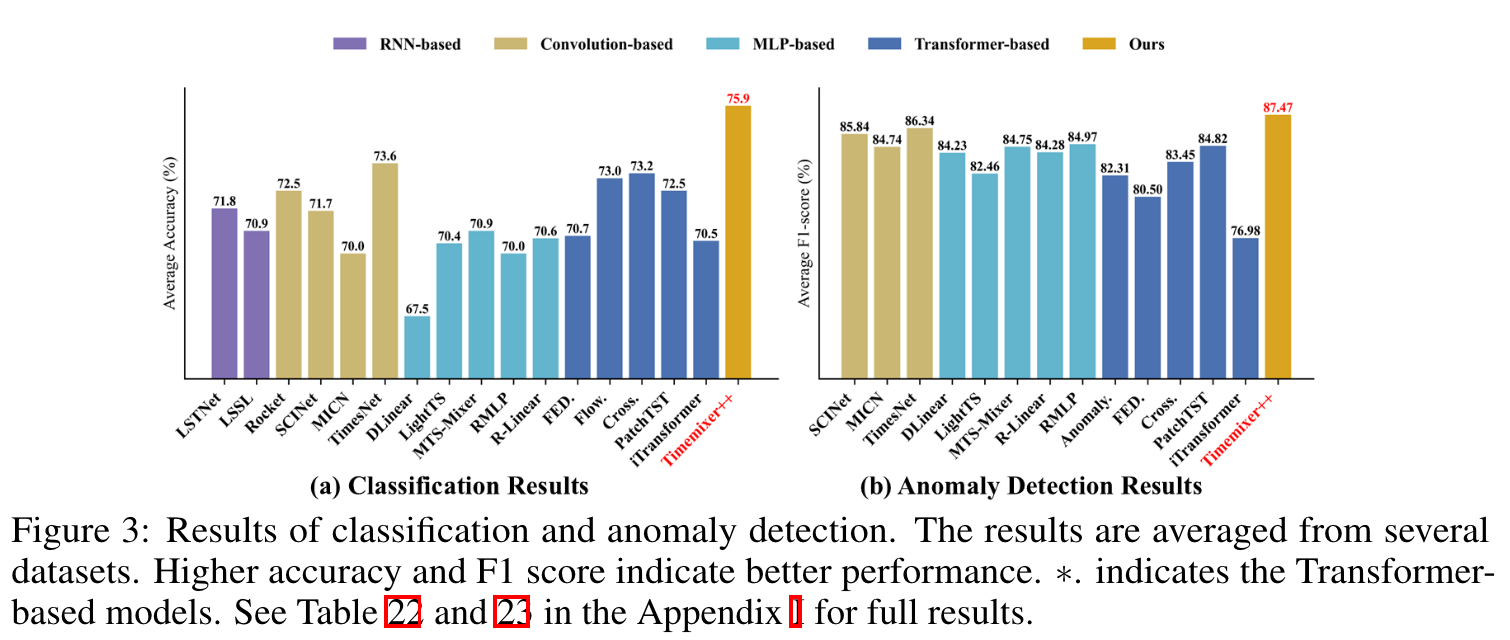
Classification (UEA) : improved
-
Anomaly Detection (SMD, SWaT, PSM, MSL, SMAP) : improved
-
-
Ablation
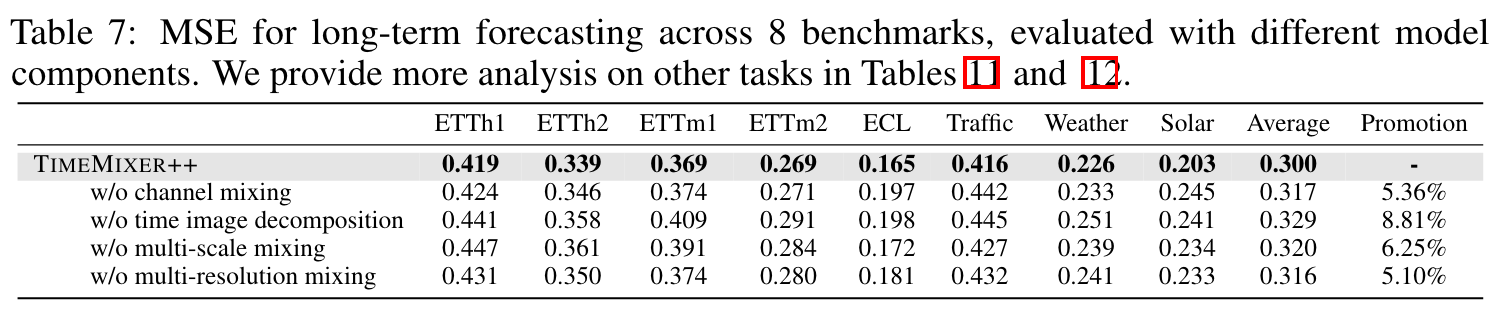
- less predictable dataset에 대해서 multi scale mixing이 도움이 되는 것을 보임
- multi-resolution hybrid 의 중요성을 보여줌
-
Representation analysis
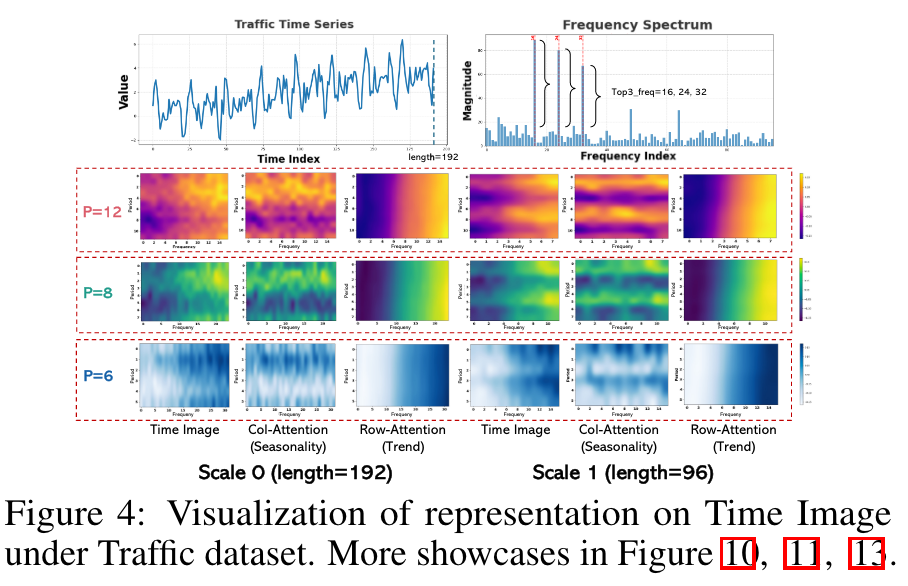
- periodic characteristic이 매우 다르게 나타나는 것을 확인할 수 있음
- diverse pattern domain을 잘 배우는 것을 볼 수 있음
- CKA similarity의 직관대로 모델 레이어의 특성이 드러나는 것도 볼 수 있음
