Introduction
- KV caching 관련 연구들 중 Palu는 token을 삭제하거나, quantization하는 post-training 방법들과는 달리, 모든 토큰을 살리면서 low rank projection을 활용하는 방식이다.
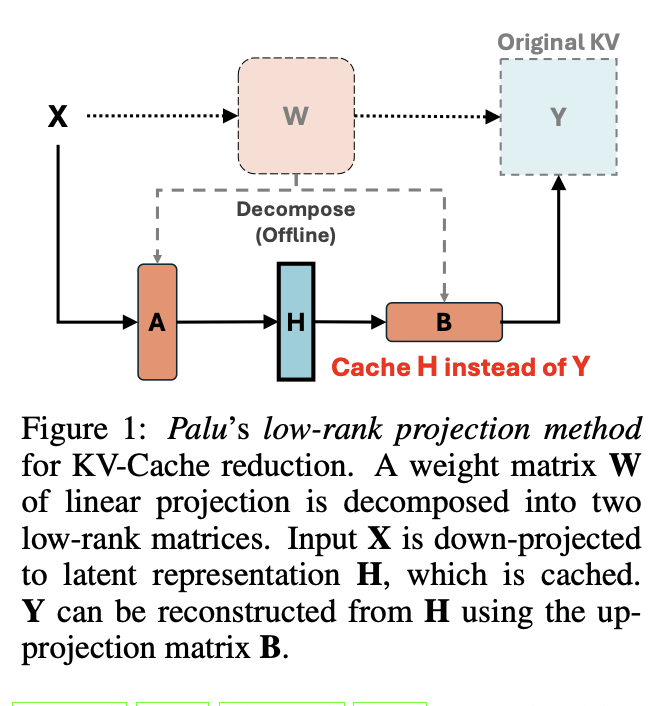
- Palu는 Linear layer를 low rank matrices로 분해하고, 분해한 행렬을 기반으로 압축된 hidden states를 캐싱해 두었다가 계산 시 복원하는 방식으로 메모리와 시간을 모두 감소하는 효과를 노린다.
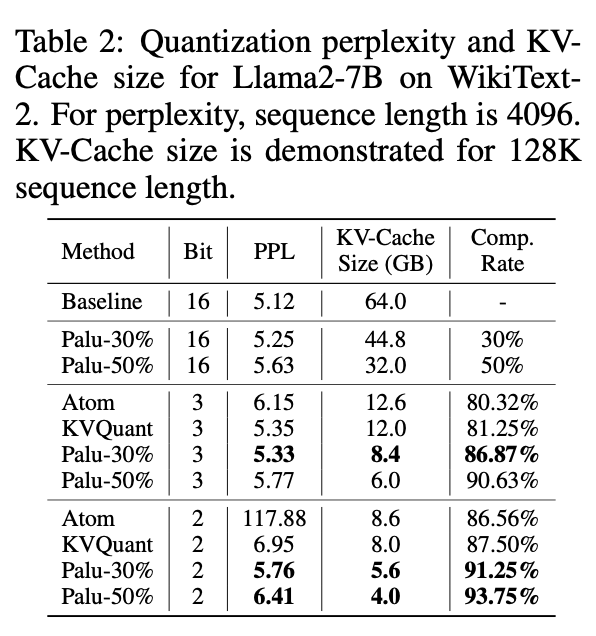
- Palu는 1) Medium-grained low-rank decomposition 2) Efficient Rank search 3) Low-rank aware quantization 4) optimized GPU kernel 을 통해, 50%까지 캐시를 압축할 수 있으며, 1.89배의 속도 향상을 이룩한다.
- Quantization과 함께 적용 시, 2.91배의 속도 향상과 더 나은 perplexity 값을 보이기도 한다. 메모리도 91.25%까지 압축률을 만들 수 있다! 어마어마한 압축률이다..
 .
.
Palu Framework
Compressing the KV-cache via Low-Rank Projection
-
Palu는 매 iteration마다 SVD를 적용하는 대신, projection weight를 SVD함으로서 보다 효과적인 압축 방식을 채택했다. 즉, 를 where 로 보고 low rank projection을 통해 압축을 진행하는 것이다.
-
이렇게 down-projection과 up-projection을 on-the-fly로 진행하며 메모리를 크게 감소시킨다.
-
-
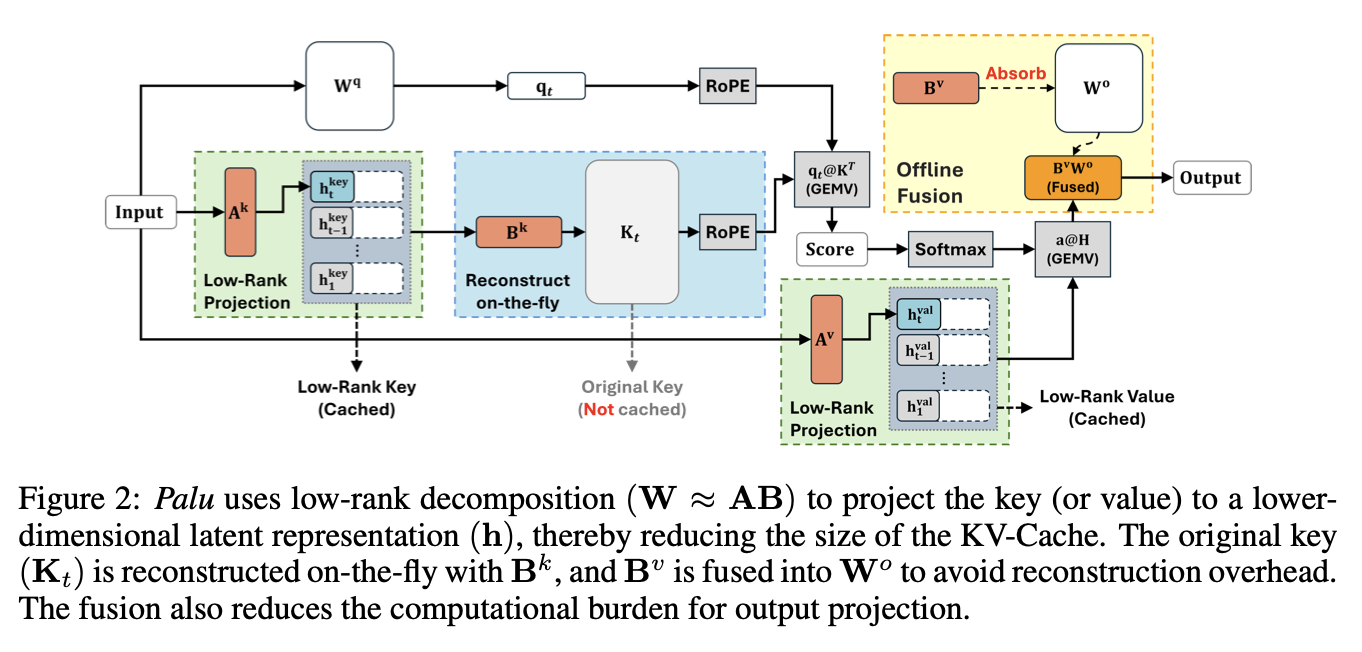
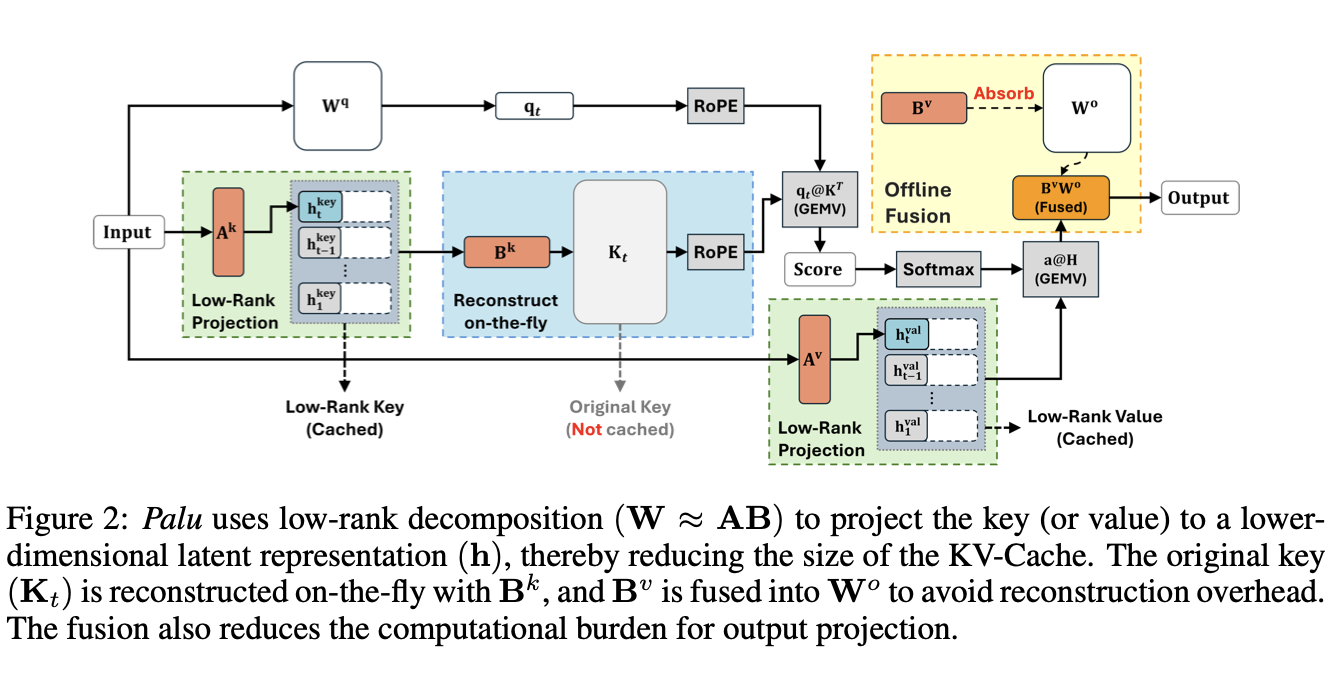
Palu는 key, value linear layer를 분해함으로서 구현된다. 아래 식과 같이 이해할 수 있다. 이 때, Value 에서 reconstruction matrix를 output projection matrix로 fuse 할 수 있어 explicit reconstruction을 하지 않고도 simple하게 reconstruction을 가능케한다.
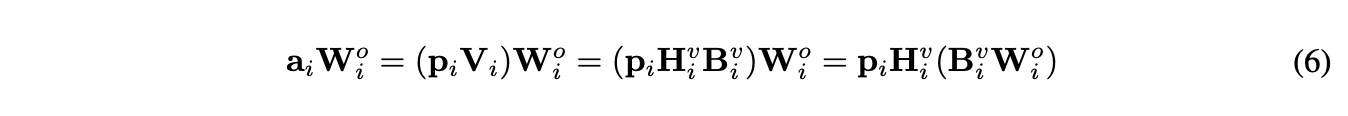
-
마찬가지로, key에서는 query layer에 reconstruction matrix를 fuse 할 수 있어 역시 간결한 계산이 가능하다.
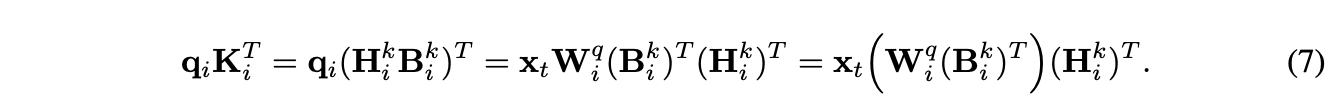
-
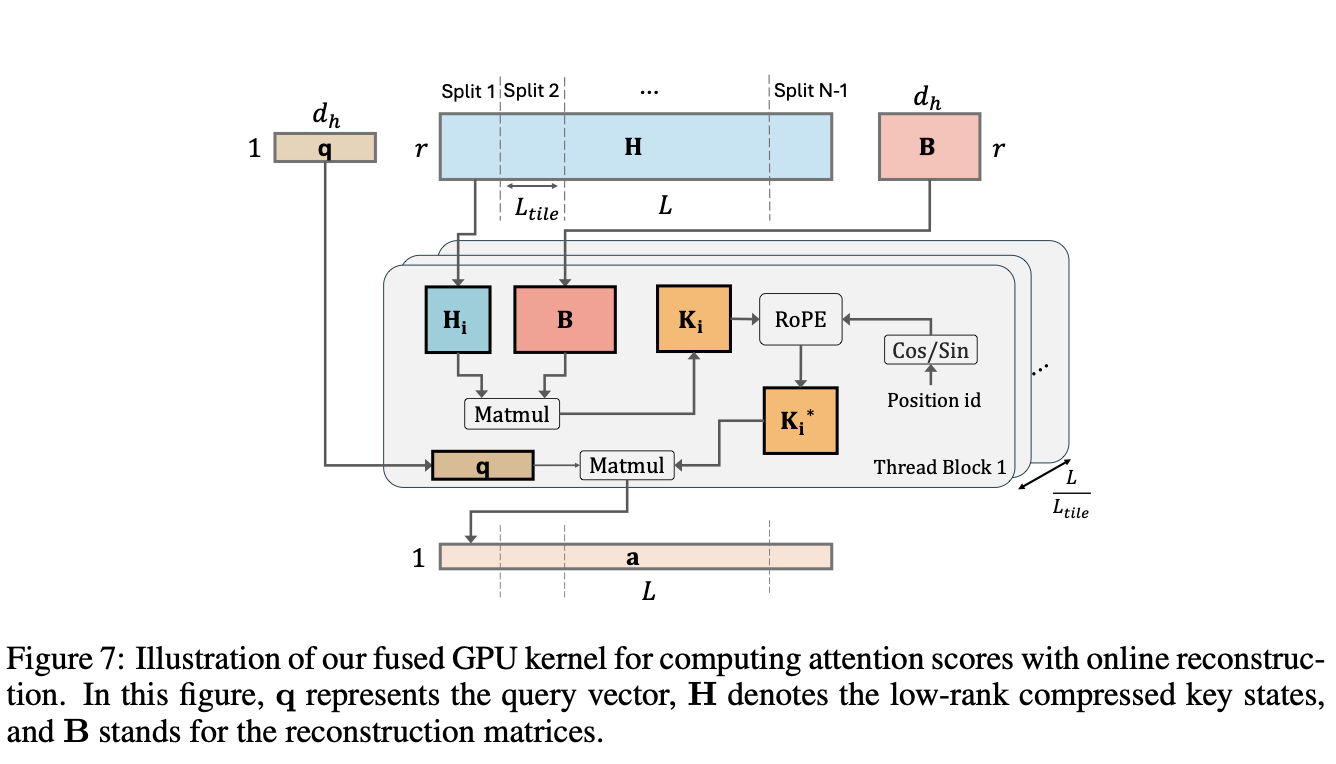
positional embedding과의 compatibility를 위하여, custom GPU kernel을 완성했다. key construction, RoPE, Query-key multiplication을 하나의 fused operation으로 진행하여 off-chip memory footprint를 최소화 한다. ALiBI와 같은 key에 직접 적용되지 않는 Postiional embedding 은 커널을 필요로 하지 않으며, 더 많은 speed up을 가능케 한다!
Decomposition Granularity
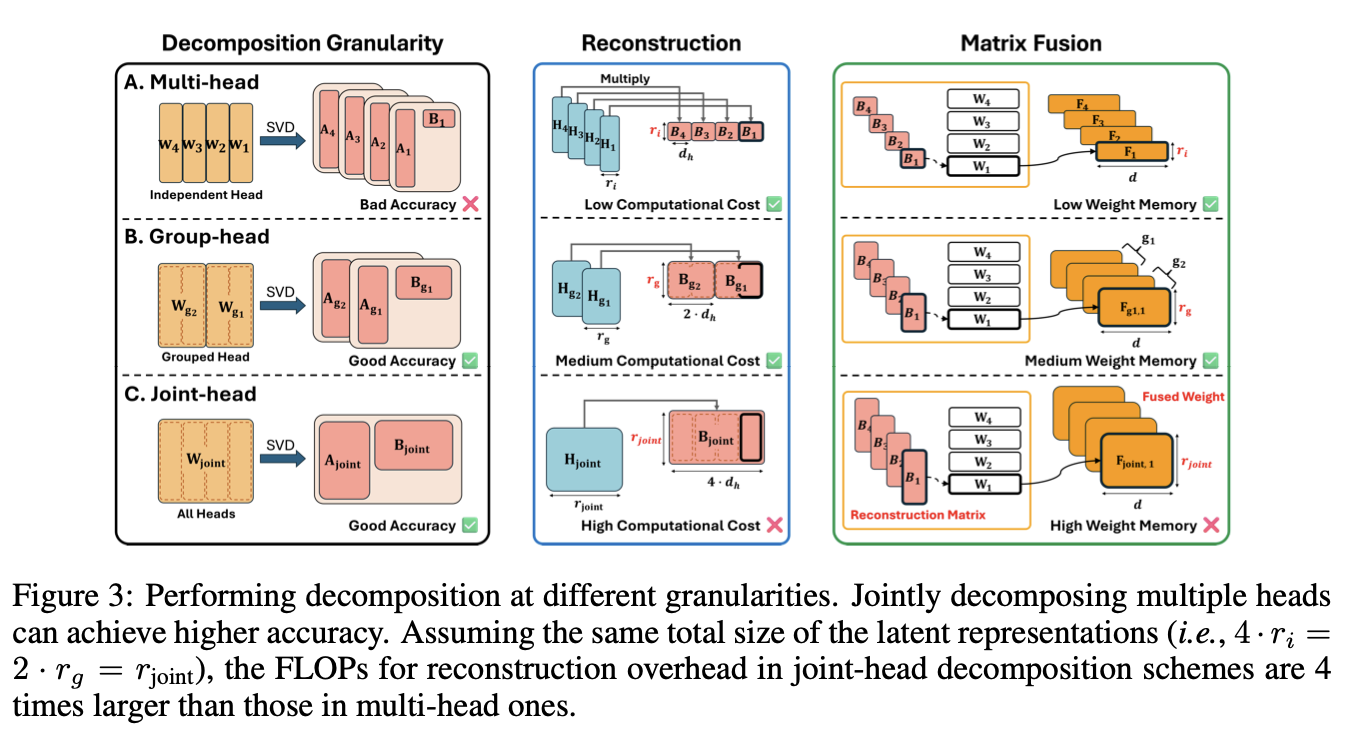
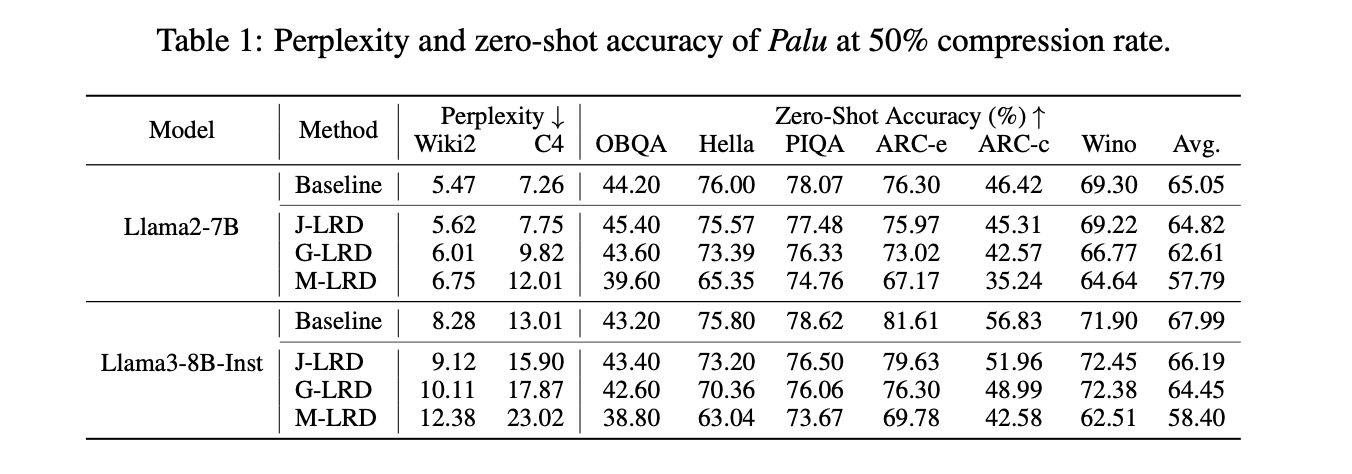
- Multi-head Low-rank decomposition (M-LRD) 은 모든 head에 대해 따로따로 분해를 적용하는 방식이다. 그러나, 이 방식은 헤드 간 공유되는 정보를 반영하지 못해서 model accuracy가 보장되지 않았다.
- Joint-head low-rank decomposition (J-LRD) 은 전체 헤드 단위로 분해를 진행한다. joint rank로 분해하여, A, B를 만드는 방식이다. 이 방식을 적용하면 dominant component를 잘 잡아내 성능을 유지하지만, computational cost가 M-LRD에 비해 n배 증가한다.
- Group-head low-rank decomposition (G-LRD) 는 그룹 단위로 헤드를 나누어 분해를 진행한다.
J-LRD에 비해서 group 개수만큼 M-LRD에 비해 computational cost가 증가하므로, 적당한 증가로 accuracy를 유지할 수 있다는 장점을 가진다. Palu의 최적 결과도 해당 방법에서 나왔다.
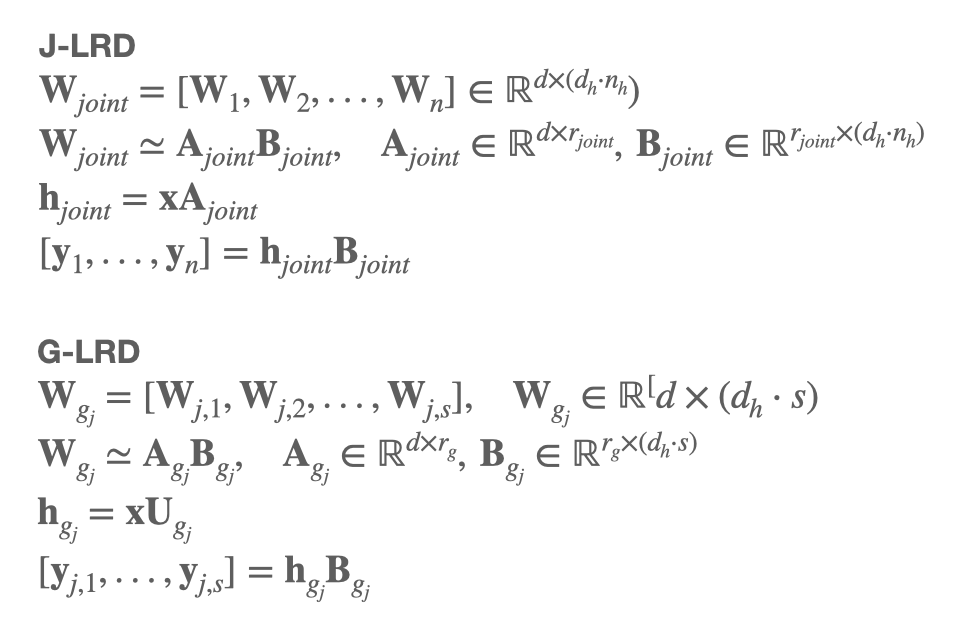 .
.
Automatic Rank Allocation
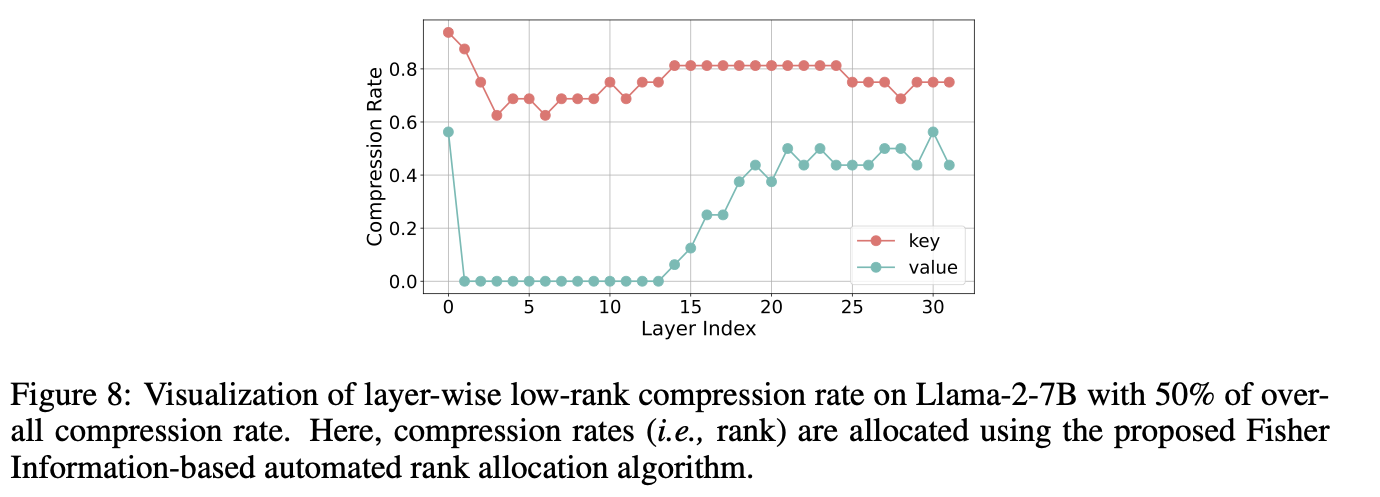
- 분해를 위한 최적의 랭크를 위해, fisher information based 랭크 계산을 진행한다. weight matrix의 중요도를 판별하고자, 각 linear layer의 fisher information의 합을 계산한다.
- Compression sensitivity를 Fisher information의 역이라고 가정하고, 전체 fisher information 대비 linear layer의 fisher information으로 rank를 결정한다.
- Ablation 결과를 보면, fisher info 기반 선택이 그냥 uniform하게 부여한 결과보다 나은 것을 확인할 수 있다.
Quantization Compatibility
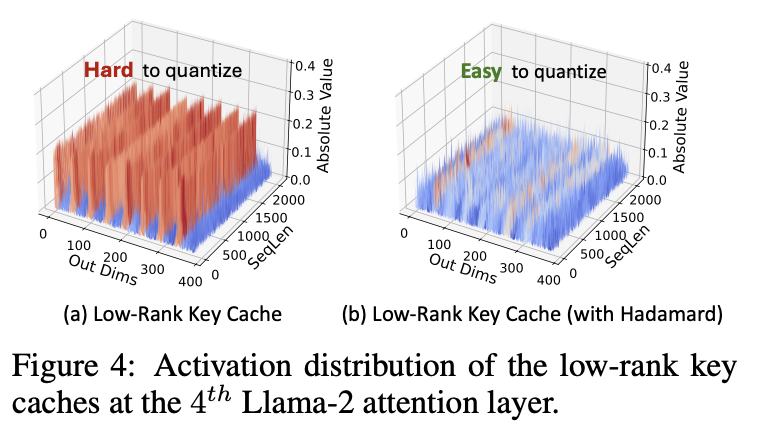
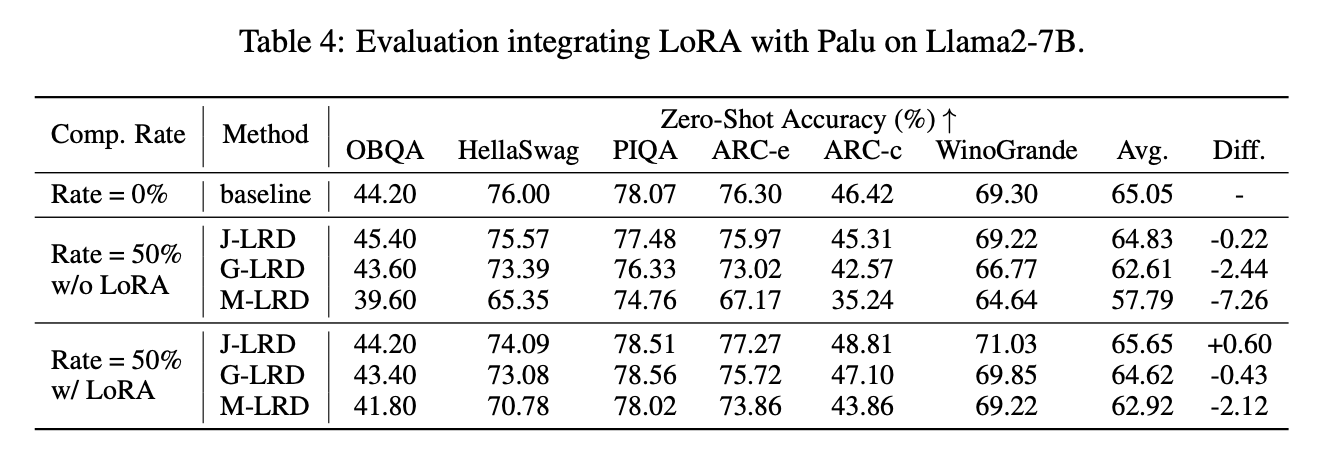
- Palu의 성능을 보다 최적화하고자 quantization을 추가한다. 이 때 low-rank compressed latent 가 outlier를 꽤 많이 가진다는 것을 확인할 수 있
었다.
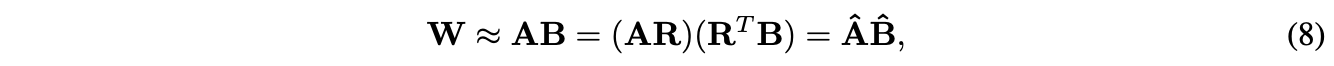
- SVD로 인해 추가적으로 발생한 outlier들이 발생하는데, 이를 해결하기 위해 Walsh-Hadamard transform을 추가적으로 적용하여 quantization accuracy를 향상시키고자 하였다. Calibration stage에 이미 whitening을 적용하여 추가적인 computation overhead는 없다.
 .
.
Experiments
Main Result (Decomposition Granularity)
Quantization Integration
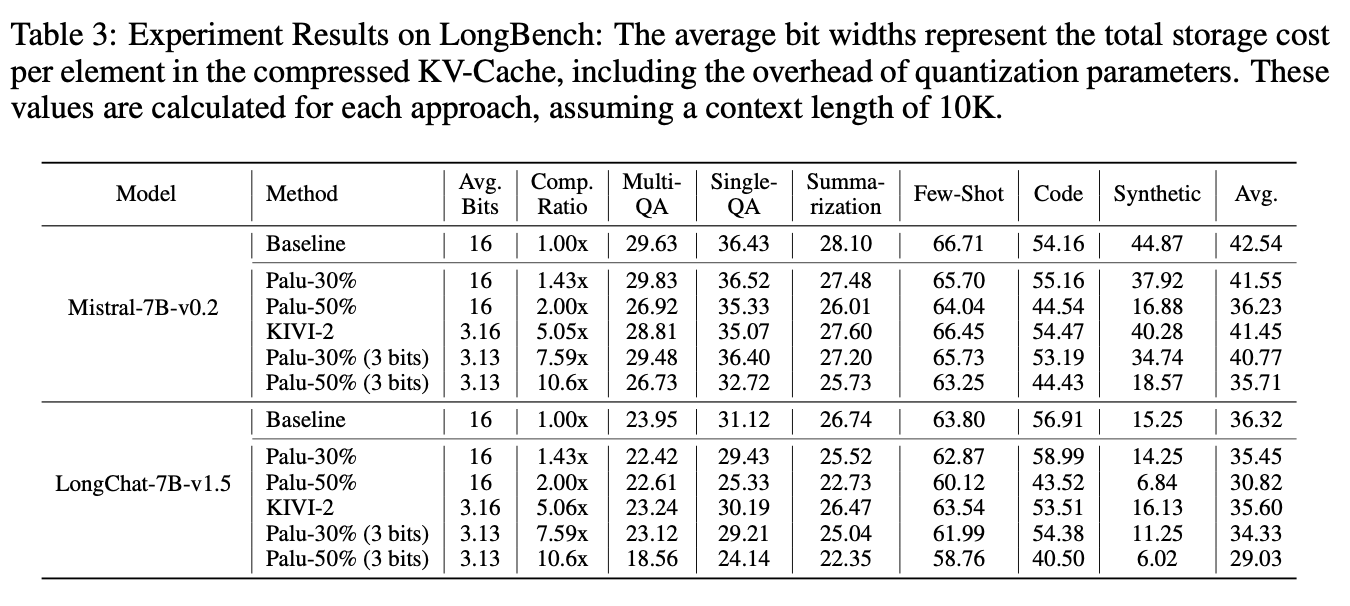
Long Context dataset
Latency Evaluation
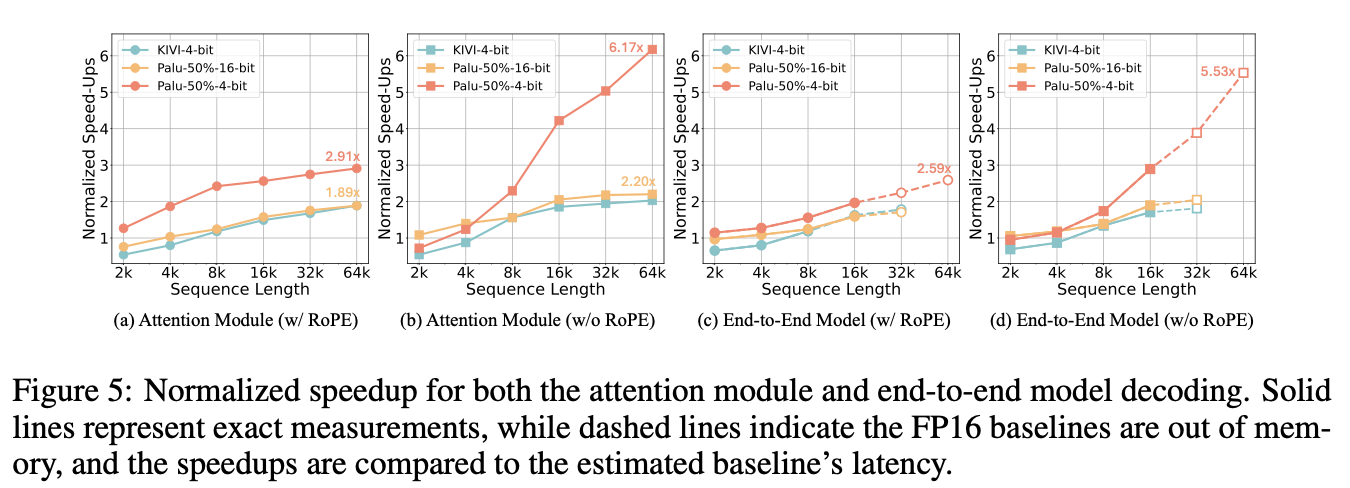
- Palu는 short sequence에서는 그리 속도 향상이 크지 않거나 없었지만, sequence 길이가 길어질수록 속도 향상이 크게 일어나는 것을 확인할 수 있었다.
- Attention module 자체에서 64K 길이에 1.89배, quantization 적용 시 2.91배까지도 향상되었고, non-RoPE에 대해서는 2.20, 6.18배까지도 성능 향상이 되었다.
- End-to-end speed up도 1.71배, 2.05배 speed up이 있었으며 quantization 추가 시 각각 2.59배, 5.53배 향상이 있었다.
- 커스텀 커널도 속도 향상이 일어나는 것을 확인할 수 있었다.
Appendix
Quantization
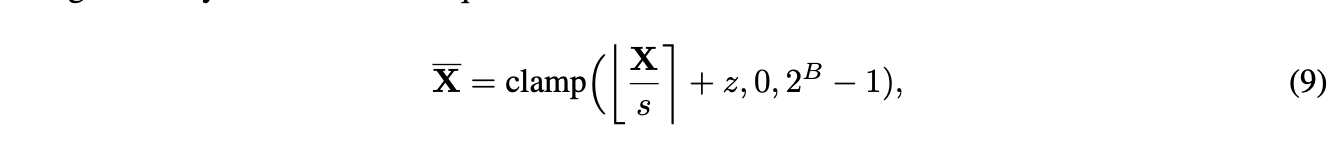
Memory Usage
- Palu는 weight decompose 시 추가적으로 linear layer가 필요하므로, 사실상 전체 메모리 관리 측면에서는 메모리가 증가할 수 있다. 예를 들어, 30%로 압축한다고 했을 때 weight는 40% 증가하게 된다. 이 때, m=n이라고 하면 약 1.4배의 weight증가가 발생하는 것이다. 그러나, optimal한 group compression으로 진행하게 된다면, m=8n, 즉 그룹이 8개일 때 weight 비율은 0.7875로 감소하며, 오히려 memory saving이 가능해짐을 알 수 있다.
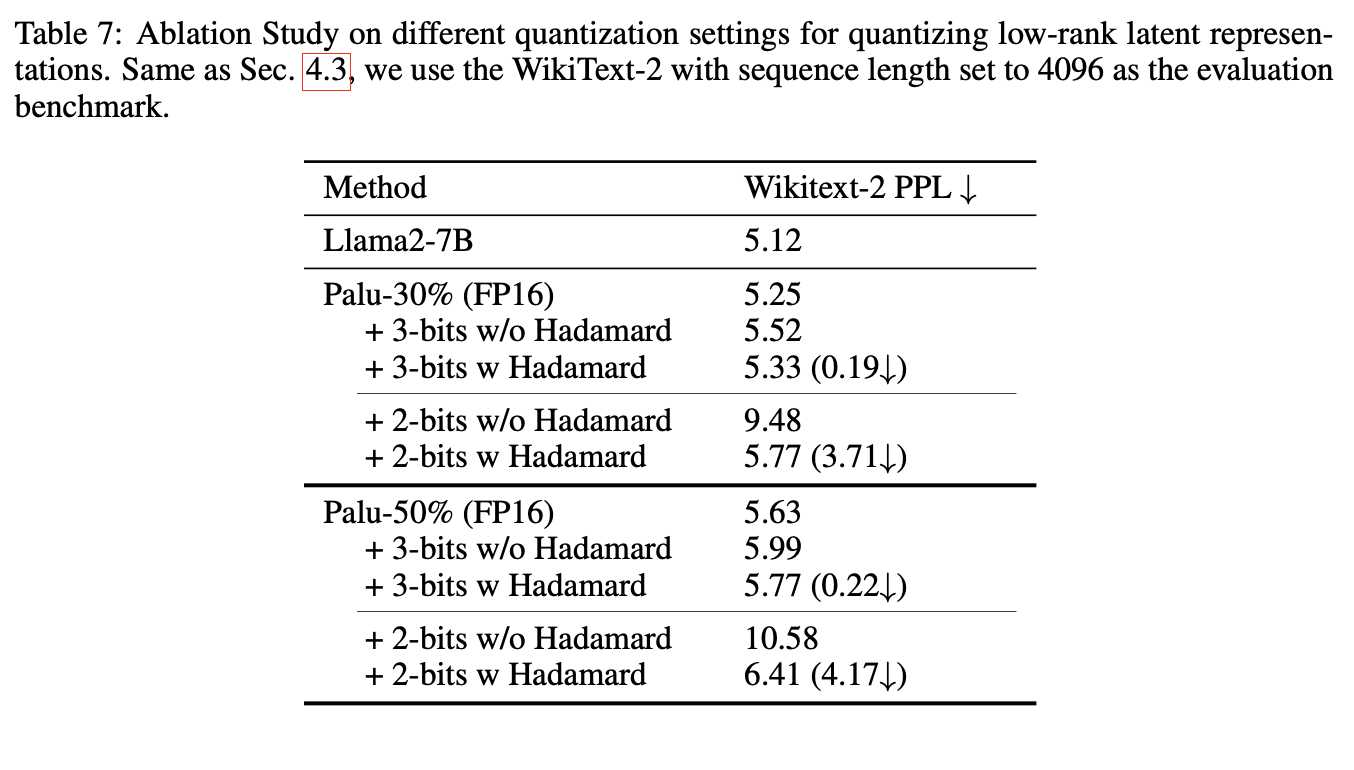
LoRA integration
- 아래 수식을 적용하여 Palu에 LoRA도 적용할 수 있다.
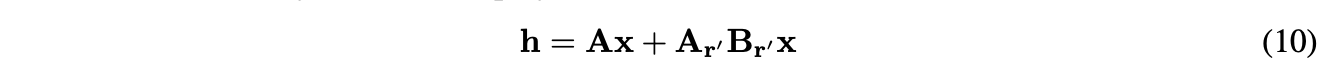
- 실험 결과는 아래와 같다.
Ablation
Runtime Analysis
- 직접 runtime에 SVD를 할 경우와 runtime 비교
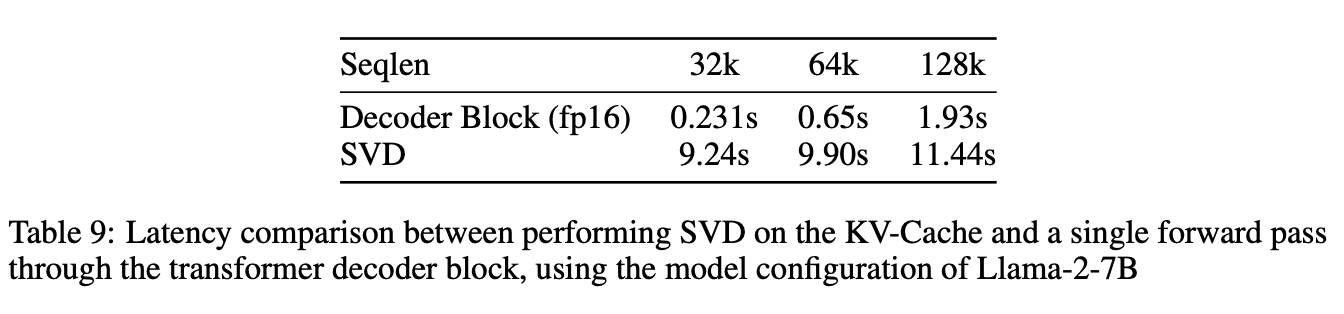
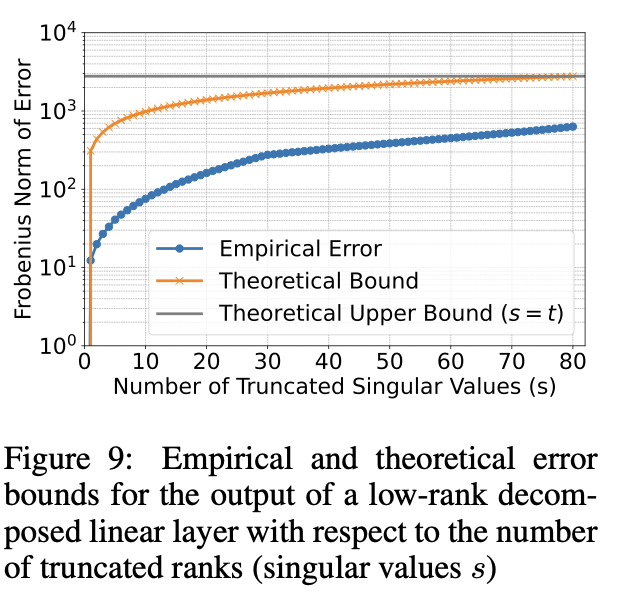
SVD Error Bound
- 이론적으로 SVD ratio일 때의 bound를 보이고 실제 결과랑 비교
Compute and Memory footprint analysis

