[논문리뷰] Stuffed Mamba: State Collapse and State capacity of RNN-Based Long-Context Modeling
SSM
목록 보기
8/8
(arXiv:2410) STUFFED MAMBA: STATE COLLAPSE AND STATE CAPACITY OF RNN-BASED LONG-CONTEXT MODELING
Purpose of the paper

- Mamba의 long context retrieval performance가 보고된 바와 달리 학습 시의 길이보다 긴 길이에서 망가지는 것이 여러 리서치에서 발견되었다. 해당 논문은 이 이유를 state collapse로 보고, 어떠한 상황에서 state collapse가 발생하는지/어떻게 해결할 수 있을지/state capacity와 collapse간의 관계는 무엇인지에 대해서 고찰한다.
- 저자들은 state collapse가 몇몇 exploding out-of-distribution channel 때문에 발생한다고 주장한다. 기존 연구에서는 delta를 통해 state collapse를 해결하고 length generalization을 하려는 시도가 있었으나, 단순히 delta를 작게 만드는 것은 정보 손실로 이어지게 된다. 따라서, 저자들은 다른 방식으로 이 문제를 해결하려 한다.
State Collapse inspection
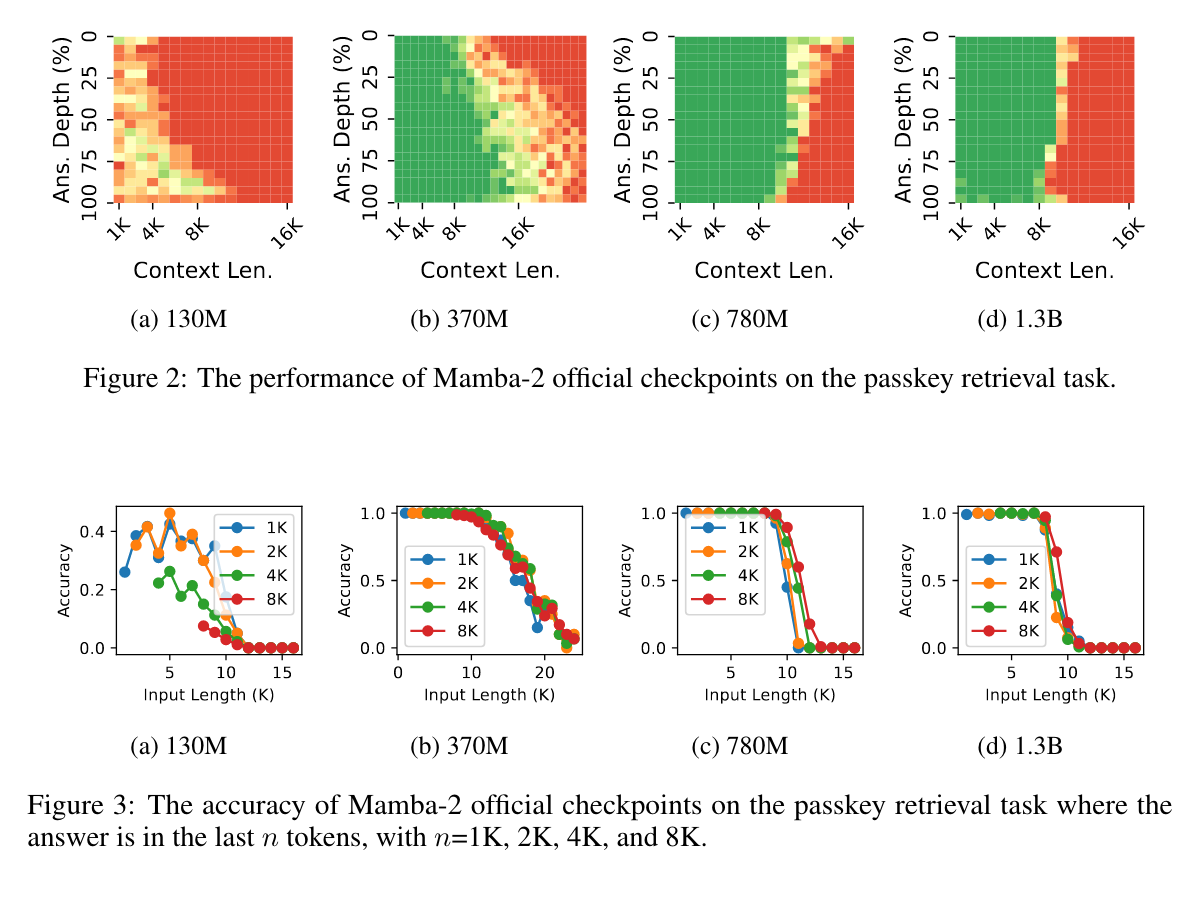
- passkey retrieval task에서 원래 Mamba2의 체크포인트 값을 가지고 수행한 결과를 보면 일정 threshold를 넘어서면 급격히 실패하는 것을 확인할 수 있다. 저자들은 이것이 mamba2의 구조 상 stable exponential memory decay가 발생하게 되면 일어나서는 안되는 문제라고 지적하며, 만약 last k token에 retrieval 대상이 있을 경우를 따로 분석한다.
- 이러한 예상치 못한 문제는 train length 보다 더 긴 문장을 볼 때 딱 train length까지만 보고 나머지는 버리는게 오히려 낫다는 얘기가 된다.
- Recurrent structure에서 state dim은 변하지 않으므로, state collapse에서 급격한 값의 변화는 state 의 값이 변해서 발생하는 일이다. 따라서 저자들은 mamba-2-370M에서 mean, variance를 확인하여 context length를 벗어날 때의 상황을 확인하고자 하였다.
- 그들은 SC가 프롬프트에 독립적으로 발생한다고 주장한다. 즉, pretraining corpus에서의 문장을 넣든, 아무거나 집어넣든 똑같이 발생한다는 것이다.

- 좀 더 깊이 살펴보고자, delta, B, x에 대해 각 헤드마다 평균과 분산을 리포트해본 결과, delta와 B에 비해 x가 더 stable하며, B가 delta보다 더 먼저 explode하는 것을 확인할 수 있었다.
- 이에 대한 추가적인 ablation은 future work로 미뤘다.
- 개인적인 의견으로는 구조 상 B가 exp, log 계산도 안하니까 conv만 하다보면 먼저 exp 하게 될 것 같음
- 보다 상위 레벨에서 SC가 overparameterization으로 인해 발생한다고 주장한다. 즉, state capacity가 train length에 비해 현저히 클 때, 언어모델은 ‘잊는 법’을 배우지 않고서도 좋은 성능을 보이게 된다. 따라서, train length보다 긴 길이, state capacity보다 긴 길이의 input이 들어왔을 때 어떻게 잊고 무엇을 기억해야하는지 알지 못한다는 것이다. 즉 overfitting과도 연관이 되는 것이다.
How to mitigate State collapse?
- Forget more and remember less : increasing amount of state decay
- Delta를 줄이는 것이 아니라 각각 B, alpha를 조정하여서 각각 state decay & amount of information inserted를 조정하고자 하였다.
- State normalization : 각 state에 대해 update후에 정규화를 진행하여 hidden state가 일정 threshold 이하로 유지되도록 한다.
- 병렬 학습이 불가능 (각 update마다 적용하므로)
- Sliding window by state difference : h_t를 가중합으로 쓸 수 있음 → 커널을 hidden state간의 difference로 해서 학습을 진행하였다.
- 공통적으로 state의 explosion을 막기 위한 방식이라고 볼 수 있다.
- 학습을 더 긴 context에 대해 진행 - data engineering을 통해 진짜 4k 이상인 데이터에 대해서만 학습하고 initial state를 직전 state값으로 유지했다.. backprop이 흘러가지 않되 이전 정보는 가지고 가도록하는 것이다.
State capacity
- 앞서 살펴본 바에 의하면 SC는 state capacity보다 작은 정보량만을 가지고 있을 때 발생한다. 그렇다면 실제로 capacity와의 관계를 확인하고자 실험을 진행했다.
- 여러 모델 사이즈의 mamba2 에 대해 확인한 결과, state size S와 Train length T_train 간의 관계는 T_train = 5.172*S - 4.469 로 나타났다고 한다.
Mitigated Result

- 제시된 학습방법으로 train 한 결과이다.
- LongMamba(제시된 방식)이 일반화능력을 3배 가량 증가시켰으나 짧은 시퀀스에서 여전히 perplexity가 크게 나타났다. 또한 제시된 다양한 방법들이 모두 64k이상으로 일반화하는데 성공하였으나 state normalization은 헤드 간의 비율을 고려하여 학습하지 못했기에 오히려 성능이 망가지는 것으로 보인다.

M.S Student @ KAIST GSAI