🧐과제 진행에 대한 회고
지금 껏 강의를 통해 강사님이 알려주신 코드 그대로 받아적으며 수동적 학습을 하다 보니 배웠던 내용들을 스스로 활용할 기회가 많이 없었는데,
확실히 이런 과정을 직접 하다 보니 잊어버렸던 개념들도 다시 돌아보며 지난 강의들의 개념이 점점 잡히는 게 느껴졌다.
중간 중간 알 수 없는 에러들까지 구글링으로 찾으며 생각보다 시간이 많이 소요되었지만..이런 과정들 또한 비전공자인 나에게 조금 더 익숙해지고 발전해가는 데에 큰 도움이 되리라 믿는다.
아직은 강의노트를 보지 않으면 진행이 되지않다 보니 다시 한번 수업 내용의 반복❗복습❗이 정말 중요함을 다시금 느낀다.✨
EDA1 프로젝트 과제- 스타벅스 이디야 매장 데이터 분석
- 문제 1 : 서울시의 스타벅스 매장의 이름과 주소, 구 이름을 pandas data frame으로 정리
- 문제 2 : 서울시의 이디야 커피 매장의 이름과 주소, 구 이름을 pandas data frame으로 정리
- 문제 3 : 이디야 커피 매장이 스타벅스 커피 매장 근처에 있는지를 분석
▶️문제 1. 서울시의 스타벅스 매장의 이름과 주소, 구 이름을 pandas data frame으로 정리
from selenium import webdriver
from bs4 import BeautifulSoup
import numpy as np
import pandas as pd
import re
import time
import json
import requests
import folium
import matplotlib.pyplot as plt
import urllib
import platform
import seaborn as sns
from matplotlib import font_manager, rc
from urllib.request import urlopen
from tqdm import tqdm
from selenium.webdriver.common.by import By
plt.rcParams["axes.unicode_minus"] = False
rc("font", family= "Malgun Gothic")
%matplotlib inline- 스타벅스 페이지에서 데이터 가져오기
starbucksUrl = "https://www.starbucks.co.kr/store/store_map.do"
driver = webdriver.Chrome("../driver/chromedriver.exe")
driver.get(starbucksUrl)
#지역선택
localSearch = '//*[@id="container"]/div/form/fieldset/div/section/article[1]/article/header[2]/h3/a'
driver.find_element(By.XPATH,localSearch).click()
# 서울
# driver.find_element(By.XPATH,'//*[@id="container"]/div/form/fieldset/div/section/article[1]/article/article[2]/div[1]/div[1]')
driver.find_element(By.XPATH,'//*[@id="container"]/div/form/fieldset/div/section/article[1]/article/header[2]/h3/a').click()
driver.find_element(By.XPATH,'//*[@id="container"]/div/form/fieldset/div/section/article[1]/article/article[2]/div[1]/div[2]/ul/li[1]/a').click()
time.sleep(0.5)
driver.find_element(By.XPATH,'//*[@id="mCSB_2_container"]/ul/li[1]/a').click()req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
contents = soup.select('#mCSB_3_container > ul > li')--> 593
#출력 확인
print(contents[0].get('data-lat'))
print(contents[0].get('data-long'))
print(contents[0].get('data-name'))
print(contents[0].select_one('p.result_details').text)37.501087
127.043069
역삼아레나빌딩
서울특별시 강남구 언주로 425 (역삼동)1522-3232
# 전체 데이터 출력
lat = []
lng = []
shop = []
address = []
for items in tqdm(contents):
lat.append(items.get('data-lat'))
lng.append(items.get('data-long'))
shop.append(items.get('data-name'))
address.append(items.select_one('p.result_details').text)
#구별 구분
gu = [add.split()[1] for add in address]
# 확인
print(len(lat), len(shop), len(gu))
df_starbucks = pd.DataFrame({
'매장' : shop,
'구' : gu,
'주소' : address,
'위도' : lat,
'경도' : lng,
})
df_starbucks.head()
df_starbucks["브랜드"]='스타벅스'
df_starbucks.info()
df_starbucks.to_csv("../data/EDA.starbucks_data.csv", sep=",", encoding = 'utf-8')▶️문제 2 : 서울시의 이디야 커피 매장의 이름과 주소, 구 이름을 pandas data frame으로 정리
- 이디야 페이지에서 데이터 가져오기
ediyaUrl = "https://www.ediya.com/contents/find_store.html"
driver = webdriver.Chrome("../driver/chromedriver.exe")
driver.get(ediyaUrl)
driver.find_element(By.XPATH,'//*[@id="contentWrap"]/div[3]/div/div[1]/ul/li[2]/a').click()
search_add = driver.find_element(By.XPATH,'//*[@id="keyword"]')
search_add.send_keys('서울 강남구')
search = driver.find_element(By.XPATH,'//*[@id="keyword_div"]/form/button').click()
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
shops = soup.select('#placesList > li > a > dl')
print(len(shops))
print(shops[0].select_one('dt').text)--> 44
-->강남YMCA점
# 구 리스트
gu_list = ['서울 강남구', '서울 강북구' ,'서울 강서구', '서울 관악구' ,'서울 광진구', '서울 금천구', '서울 노원구', '서울 도봉구',
'서울 동작구', '서울 마포구','서울 서대문구', '서울 서초구' ,'서울 성북구' ,'서울 송파구', '서울 양천구' ,'서울 영등포구',
'서울 은평구', '서울 종로구' ,'서울 중구', '서울 강동구' ,'서울 구로구' ,'서울 동대문구', '서울 성동구', '서울 용산구',
'서울 중랑구']
search_add = driver.find_element(By.ID,'keyword')
search = driver.find_element(By.XPATH,'//*[@id="keyword_div"]/form/button')
shop = []
gu = []
address = []
for gu_name in tqdm(gu_list):
search_add.clear()
search_add.send_keys(gu_name)
time.sleep(0.3)
search.click()
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
shops = soup.select('#placesList > li > a > dl')
for items in shops:
shop.append(items.select_one('dt').text)
address.append(items.select_one('dd').text)
gu.append(address[-1].split()[1])
print(len(shop))df_ediya = pd.DataFrame({
'매장' : shop,
'구' : gu,
'주소' : address,
})
df_ediya.tail()
df_ediya["브랜드"]='이디야'- 위도/ 경도 값 추가
import googlemaps
gmaps_key = 'AIzaSyCB3zeKUulnVUj_yDjKqaqoqVsF0MGvx_o'
gmaps = googlemaps.Client(key=gmaps_key)
gmaps.geocode("이디야 이태원역점", language='ko')
#위도/경도 불러와지는지 확인
tmp = gmaps.geocode("이디야 이태원역점", language='ko')
print(tmp[0].get("geometry")["location"]["lat"])
print(tmp[0].get("geometry")["location"]["lng"])37.534542
126.994596
# 위도/경도 값 불러와서 추가
lat = []
lng = []
for idx, rows in tqdm(df_ediya.iterrows()):
shop_name = '이디야' + rows.get('매장')
gmap = gmaps.geocode(shop_name, language='')
if len(gmap) != 0:
lat.append(gmap[0].get("geometry")["location"]["lat"])
lng.append(gmap[0].get("geometry")["location"]["lng"])
else:
lat.append(np.nan)
lng.append(np.nan)
len(lat)-->717
# 이디야 데이터프레임에 위도/경도 값 추가
df_ediya['위도'] = lat
df_ediya['경도'] = lng
df_ediya.info()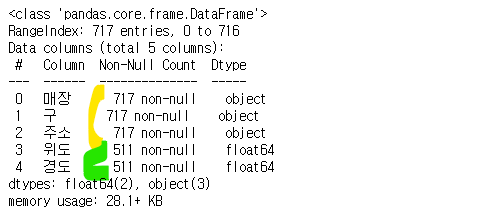
# nan값 있는 인덱스는 삭제해주기
delete = df_ediya[df_ediya['위도'].isnull()].index
df_ediya.drop(delete, axis=0, inplace=True)
df_ediya.info()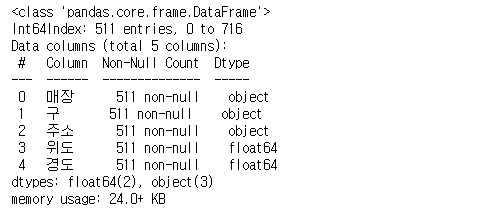
- 저장
df_ediya.to_csv("../data/EDA.ediya_data.csv", sep=",", encoding = 'utf-8')▶️문제 3 : 이디야 커피 매장이 스타벅스 커피 매장 근처에 있는지를 분석
- 정리된 데이터로 데이터 분석하기
#스타벅스 데이터 읽어오기
starbucks = pd.read_csv(
"../data/EDA.starbucks_data.csv",
sep=",",
encoding = 'utf-8',
index_col = 0
)
# 이디야 데이터 읽어오기
ediya = pd.read_csv(
"../data/EDA.ediya_data.csv",
sep=",",
encoding = 'utf-8',
index_col = 0
)- 구별 매장 수 비교
#스타벅스 구별 매장 수
# pivot table 사용
pivot_starbucks = starbucks.pivot_table(index='구', values='매장', aggfunc=len)
pivot_starbucks['브랜드'] = '스타벅스'
pivot_starbucks.head()
# 이디야 구별 매장 수
# pivot table
pivot_ediya = ediya.pivot_table(index='구', values='매장', aggfunc=len)
pivot_ediya['브랜드'] = '이디야'
pivot_ediya.head()
# 스타벅스 구별 매장 수 상위 10개 지역
pivot_starbucks.sort_values(by='매장', ascending=False).head(10)
# 이디야 구별 매장 수 상위 10개 지역
pivot_ediya.sort_values(by='매장', ascending=False).head(10)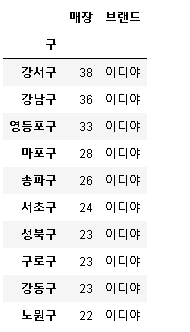
강남구에 월등히 많은 수를 보유한 스타벅스에 비해 이디야는 구별 매장 수 차이가 크지 않고 각각 상위 10개 구의 차이도 조금 있음을 확인.
totalData = pd.concat([df_starbucks,df_ediya], axis=0)
totalData.reset_index(drop=True, inplace=True)
totalData.tail()
totalData["값"]=1
totalData.to_csv("../data/EDA.totalData.csv", sep=",", encoding='utf-8')
totalCnt = totalData.pivot_table(index="구", columns="브랜드", values='값', aggfunc=np.sum)
totalCnt.head()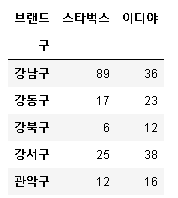
- plot그래프로 시각화 하여 차이 확인
totalCnt.plot.bar(rot=2, figsize=(15,8), color=['blue', 'red'])
plt.xticks(rotation="vertical")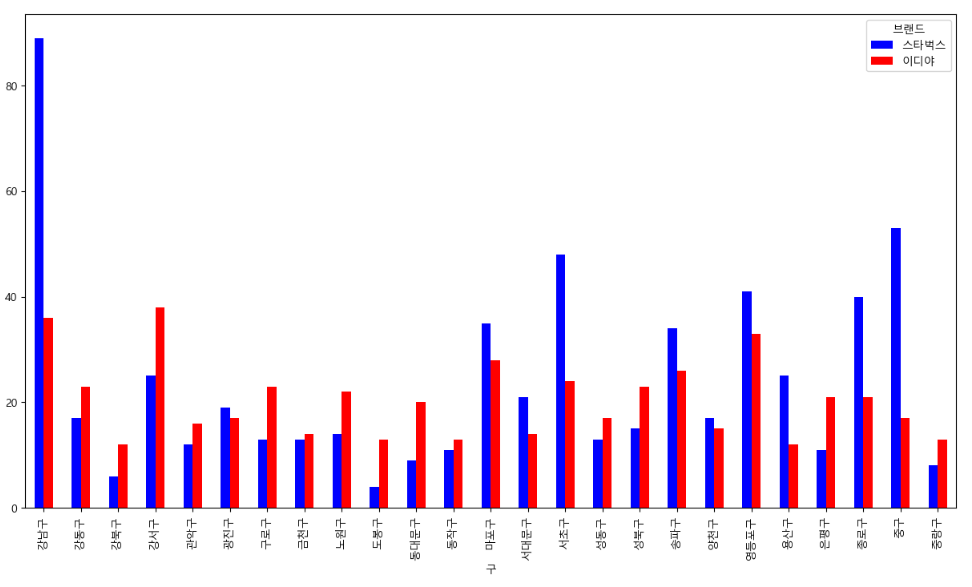
스타벅스는 [강남구, 마포구, 서초구, 중구 ]등 유동인구가 많은 지역에 특히 밀집되어 있는 반면, 이디야 매장은 비교적 지역 별 큰 편차 없이 고르게 분포되어 있음을 알 수 있다.
totalCnt["위도"] = np.nan
totalCnt["경도"] = np.nan
for idx, rows in totalCnt.iterrows():
tmp = gmaps.geocode(idx, language='ko')
if tmp:
lat= tmp[0].get("geometry")["location"]["lat"]
lng= tmp[0].get("geometry")["location"]["lng"]
totalCnt.loc[idx,"위도"]=lat
totalCnt.loc[idx,"경도"]=lng
else:
print(idx)
totalCnt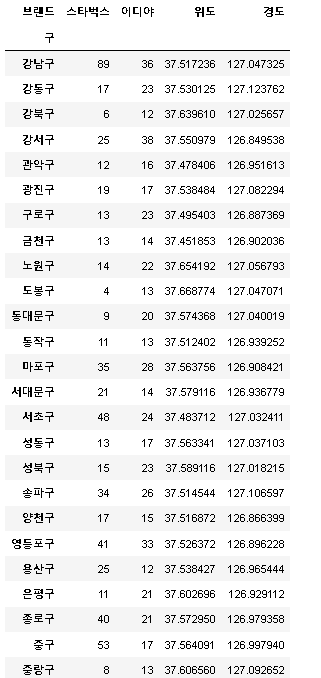
- 지도에 표시해서 확인해보기
seoul = [37.517692, 126.989912]
resultMap = folium.Map(
location=seoul,
zoom_start=11,
tiles="OpenStreetMap"
)
for idx, rows in totalCnt.iterrows():
#스타벅스 --> 파란 원
folium.Circle(
location=[rows["위도"], rows["경도"]],
radius = rows["스타벅스"]* 50,
fill = True,
color = 'blue',
popup = idx,
tooltip = idx
).add_to(resultMap)
#이디야--> 붉은 원
folium.Circle(
location=[rows["위도"], rows["경도"]],
radius = rows["이디야"]* 50,
fill = True,
color = 'red',
popup = idx,
tooltip = idx
).add_to(resultMap)
resultMap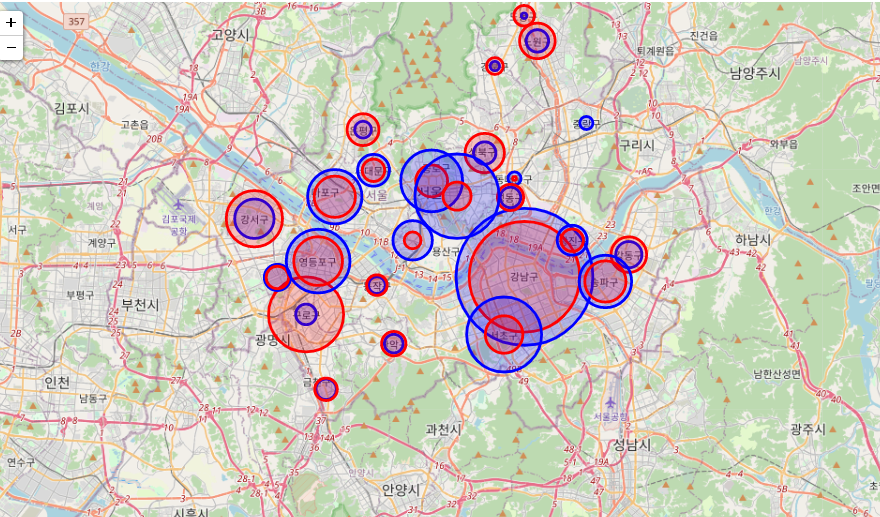
스타벅스는 유동 인구 많은 한강 주변 (강남, 마포, 서초 등) 중심으로 원의 크기가 크지만 외곽으로 갈 수록 원의 크기가 급격히 작아짐
이디야는 그에 비해 고루 분호되어 있는 편이다.
<결론>
'스타벅스 커피 매장이 위치하는 곳에 이디야가 전략적으로 따라 매장을 낸다' 라는 의견에 대해 두 브랜드의 구 별 위치 및 매장 빈도수를 확인한 결과, 크게 상관관계가 있어 보이지는 않는다.
서울 중심과 외곽지역 분포 수가 현저히 차이나는 스타벅스에 비해 이디야 커피는 특정 지역이 아닌 서울 지역 전체에 전반적으로 고른 분포를 보이고 있으므로, 결과적으로 두 브랜드 간 해당 의견은 타당하지 않다고 본다.

데이터분석 스터디노트🧐✍️