Beautiful Soup for web data
BeautifulSoup
- HTML : 웹 페이지를 구성하는 마크업 언어
- html 태그 : 웹 페이지 표현
- head 태그 : 눈에 보이지 않지만 문서에 필요한 헤더 정보 보관
- body 태그 : 눈에 보이는 정보 보관
- Beautiful Soup 테스트를 위해 html 작성- Beautiful Soup : 태그로 이루어진 문서를 해석하는 기능을 가진 모듈
html.parser: Beautiful Soup의 html을 읽는 엔진 중 하나(lxml도 많이 사용)- html.parser, lxml, lxml-xml, xml, html5lib 등
prettify(): html을 태그 기준으로 들여쓰기를 통해 정리해주는 기능- 모듈 설치 : pip install beautifulsoup4 | conda install -c beautifulsoup4
- 공식 문서 : https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.html
page = open("../data/03. Zerobase.html", "r").read()
soup = BeautifulSoup(page, "html.parser")
print(soup.prettify())
- 태그 키워드 활용 :원하는 태그를 키워드로 선택할 수 있다. 처음 만나는 태그만을 선택한다.
- head 키워드 : head 태그를 선택
- body 키워드 : body 태그를 선택
- p 키워드 : p 태그를 선택
# head 태그 확인
soup.head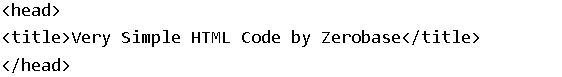
# p 태그 확인
# 처음 발견한 p 태그만 출력
# find()
soup.p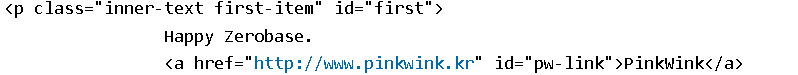
- find, find_all
- 원하는 태그를 찾을 수 있다.
- 클래스, 아이디를 이용할 수 있다.
- find_all : 다중 확인 시
- 파이썬 예약어 - class, id, def, list, str, int, tuple..
soup.find("p")
# find_all() : 여러개 확인 시 사용
soup.find("p", class_="inner-text second-item")
# 원하는 내용만 출력
soup.find("p", {"class":"outer-text first-item"}).text.strip()
# 다중 조건
soup.find("p", {"class": "inner-text first-item", "id":"first"})
# find_all() : 여러개의 태그 반환
# list형태로 반환
# soup.find("p")는 하나만 출력
soup.find_all("p")
# 특정태그 확인
soup.find_all(class_="outer-text")
soup.find_all(id="pw-link")[0].text'PinkWink'
soup.find_all("p", class_="inner-text second-item")
# p 태그 리스트에서 텍스트 속성만 출력
print(soup.find_all("p")[0].text)
print(soup.find_all("p")[1].string)
print(soup.find_all("p")[1].get_text())
- 텍스트 키워드 : 태그에 포함된 텍스트 반환
text 키워드: 태그에 포함된 텍스트를 반환string 키워드: 태그에 포함된 텍스트를 반환(단, 단일 태그인 경우에만 동작)get_text(): 태그에 포함된 텍스트를 반환- 텍스트가 여러 개 있다면 태그를 기준으로 개행되어 반환
'구분자': 태그 사이의 구분자 설정strip 옵션: 데이터의 양끝 공백 제거 설정(True / False)
stripped_strings 키워드: for을 사용하여 리스트, 튜플 등의 형태로 반환할 수 있다.
# p 태그 리스트에서 텍스트 속성만 출력
for each_tag in soup.find_all("p"):
print("=" * 50)
print(each_tag.text)
- 외부로 연결되는 링크의 주소 알아내기
find("a")로 링크 태그를 찾는다.태그[속성],태그.get(속성): 해당 태그의 속성 값 반환
# a 태그에서 href 속성값에 있는 값 추출
links = soup.find_all("a")
links
for each in links:
href = each.get("href")
text = each.get_text()
print(text + "=>" + href)
크롬 개발자 도구
- 크롬 개발자 도구를 활용해 찾고자 하는 데이터의 태그, 클래스, 아이디 등 정보 확인
- urllib의 request 모듈 : 웹주소에 접근하기 위해 사용하는 모듈
- urlopen() : url로 웹 페이지를 요청하는 함수
- status 키워드 : http 상태 코드로 200일 경우 정상적으로 정보를 받았다는 의미

beautifulsoup 예제 1-1 - 네이버 금융
# import
from urllib.request import urlopen
from bs4 import BeautifulSoup
url = "https://finance.naver.com/marketindex/"
page = urlopen(url)
soup = BeautifulSoup(page, "html.parser")
print(soup.prettify())- 크롬 도구로 환율의 값이 담긴 태그와 클래스가 span, value임을 확인
.status 키워드: http 상태 코드로 200일 경우 정상적으로 정보를 받았다는 의미
# 환율 정보
soup.find_all("span","value"), len(soup.find_all("span","value"))
# soup.find_all("span", class_="value"), len(soup.find_all("span","value")) 와 동일
# soup.find_all("span", {"class":"value"}), len(soup.find_all("span","value")) 와 동일 (딕셔너리 타입)- !pip install requests
- find, find_all
- select, selece_one
- find, select_one : 단일 선택
import requests
from bs4 import BeautifulSoup
from urllib import response
url = "https://finance.naver.com/marketindex/"
response = requests.get(url)
soup = BeautifulSoup(response.text,"html.parser")
print(soup.prettify())데이터 추출
- soup.findall("li", class = 'on') : 태그와 클래스는 중복이 가능하므로 원하지 않는 데이터도 추출될 수 있다.
- class : .클래스 (>) 태그 - 클래스 소속 중 해당 태그 선택
- id : #아이디 (>) 태그 - 아이디 소속 중 해당 태그 선택
- tag : 태그 - 태그 선택
- (>) : 해당 클래스, 아이디의 바로 하위를 의미(>가 없다면 깊이 우선 탐색을 하게 된다.)
- 아이디 : exchangeList 하위의 li 태그 추출
exchangeList = soup.select("#exchangeList > li") #id태그 : #, class태그: '.'
len(exchangeList), exchangeList#title
title = exchangeList[0].select_one(".h_lst").text
#exchange
exchange = exchangeList[0].select_one(".value").text
#change
change = exchangeList[0].select_one(".change").text
#updown
updown = exchangeList[0].select_one("div.head_info > .blind").text
#link
title, exchange, change, updown--> ('미국 USD', '1,432.50', ' 1.50', '하락')
baseUrl = "https://finance.naver.com"
baseUrl + exchangeList[0].select_one("a").get("href")--> 'https://finance.naver.com/marketindex/exchangeDetail.naver?marketindexCd=FX_USDKRW'
# 환전 고시 환율 추출
# 4개 데이터 수집
import pandas as pd
exchange_datas = []
baseUrl = "https://finance.naver.com"
for item in exchangeList:
data = {
"title": item.select_one(".h_lst").text,
"exchange":item.select_one(".value").text,
"change":item.select_one(".change").text,
"updown": item.select_one("div.head_info > .blind").text,
"link":baseUrl + item.select_one("a").get("href")
}
exchange_datas.append(data)
df = pd.DataFrame(exchange_datas)
df
df.to_excel("./naverfinance.xlsx", encoding="utf-8")BeautifulSoup 예제 2 - 위키백과 문서 정보 가져오기
- 위키 백과 --> 여명의 눈동자 링크
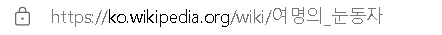
보이는 링크와 다르게 복사됨 --> UTF-8로 인코딩되어야 하기 때문이다.
'https://ko.wikipedia.org/wiki/%EC%97%AC%EB%AA%85%EC%9D%98_%EB%88%88%EB%8F%99%EC%9E%90'
from urllib.request import urlopen, Request
import urllib
import pandas as pd
from bs4 import BeautifulSoup
html = "https://ko.wikipedia.org/wiki/{search_words}"
req = Request(html.format(search_words=urllib.parse.quote("여명의_눈동자"))) #글자를 URL로 인코딩
response = urlopen(req)
# response.status --> 200출력 확인
response
soup = BeautifulSoup(response, "html.parser")
print(soup.prettify)
# 주요 인물 부분의 태그 확인
# ul임을 확인
n = 0
# 주인공 나오는 줄 확인
for each in soup.find_all("ul"):
print("=>"+str(n)+"==============")
print(each.get_text())
n += 131 번째 ul이 원하는 정보를 가지고 있음을 확인(인덱스는 0부터 시작)
# replace 함수를 이용해 필요없는 부분 제거
soup.find_all("ul")[31].text.strip().replace("\xa0", "").replace("\n","")--> '채시라: 윤여옥 역 (아역: 김민정)박상원: 장하림(하리모토 나츠오) 역 (아역: 김태진)최재성: 최대치(사카이) 역 (아역: 장덕수)'

데이터분석 스터디노트🧐✍️