
3. 고객의 전체모습을 파악해보기.
데이터를 통해 미래를 예측하는 방법은 다양하나, 적절히 가공해서 가시화하는 것만으로도 많은 정보를 얻을 수 있다.
머신러닝을 위한 데이터 가공을 통해 고객 행동을 분석해보자.
✔ 전제조건.
스포츠 센터에는 센터를 언제든 사용할 수 있는 종일회원, 낮에만 사용하는 주간회원, 밤에만 사용하는 야간회원으로 3종류가 있다.
또 일반적으로 입회비가 있으나, 비정기적으로 입회비 50% 할인이나 무료 이벤트를 통해 신규회원을 늘리고 있다. 탈퇴하려면 월말까지 신청 시 그 다음 달 말 반영된다.
취급할 데이터는 아래 4종류이다.
| 파일이름 | 개요 |
|---|---|
| use_log.csv | 센터 이용이력 데이터(2018.04~2019.03) |
| customer_master.csv | 2019년 3월 말 시점의 회원 데이터 |
| class_master.csv | 회원 구분 데이터(종일,주간,야간) |
| campaign_master.csv | 행사 구분 데이터(입회비 유무 등) |
1. 데이터 확인
import pandas as pd
uselog = pd.read_csv('use_log.csv')
print(len(uselog))
uselog.head()197428| log_id | customer_id | usedate | |
|---|---|---|---|
| 0 | L00000049012330 | AS009373 | 2018-04-01 |
| 1 | L00000049012331 | AS015315 | 2018-04-01 |
| 2 | L00000049012332 | AS040841 | 2018-04-01 |
| 3 | L00000049012333 | AS046594 | 2018-04-01 |
| 4 | L00000049012334 | AS073285 | 2018-04-01 |
▶uselog : 고객ID, 이용일을 포함한 간단한 데이터. 어떤 고객이 언제 센터를 이용하였는지 알 수 있다.
customer = pd.read_csv('customer_master.csv')
print(len(customer))
customer.head()4192| customer_id | name | class | gender | start_date | end_date | campaign_id | is_deleted | |
|---|---|---|---|---|---|---|---|---|
| 0 | OA832399 | XXXX | C01 | F | 2015-05-01 00:00:00 | NaN | CA1 | 0 |
| 1 | PL270116 | XXXXX | C01 | M | 2015-05-01 00:00:00 | NaN | CA1 | 0 |
| 2 | OA974876 | XXXXX | C01 | M | 2015-05-01 00:00:00 | NaN | CA1 | 0 |
| 3 | HD024127 | XXXXX | C01 | F | 2015-05-01 00:00:00 | NaN | CA1 | 0 |
| 4 | HD661448 | XXXXX | C03 | F | 2015-05-01 00:00:00 | NaN | CA1 | 0 |
▶customer : 고객ID, 이름, 회원 클래스, 성별, 등록일 정보가 있다. 이름은 마스킹되어 개인을 특정지을 수 없고, is_deleted는 2019년 3월 시점에 탈퇴한 유저를 시스템에서 빨리 찾기 위한 컬럼이다.
위의 데이터는 이미 탈퇴한 유저도 포함된다.
class_master = pd.read_csv('class_master.csv')
print(len(class_master))
class_master.head()3| class | class_name | price | |
|---|---|---|---|
| 0 | C01 | 0_종일 | 10500 |
| 1 | C02 | 1_주간 | 7500 |
| 2 | C03 | 2_야간 | 6000 |
campaign_master = pd.read_csv('campaign_master.csv')
print(len(campaign_master))
campaign_master.head()3| campaign_id | campaign_name | |
|---|---|---|
| 0 | CA1 | 2_일반 |
| 1 | CA2 | 0_입회비반액할인 |
| 2 | CA3 | 1_입회비무료 |
2. 고객 데이터를 가공하자
⏺고객 데이터인 customer와 이용 이력데이터인 uselog로 나눠서 우선 파악해보자.
우선 고객 데이터를 가공해보자.
customer를 기준으로 회원 구분/ 행사 구분 데이터를 조인한다.
customer_join = pd.merge(customer, class_master, on="class", how="left")
customer_join = pd.merge(customer_join, campaign_master, on="campaign_id", how="left")
customer_join.head()| customer_id | name | class | gender | start_date | end_date | campaign_id | is_deleted | class_name | price | campaign_name | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | OA832399 | XXXX | C01 | F | 2015-05-01 00:00:00 | NaN | CA1 | 0 | 0_종일 | 10500 | 2_일반 |
| 1 | PL270116 | XXXXX | C01 | M | 2015-05-01 00:00:00 | NaN | CA1 | 0 | 0_종일 | 10500 | 2_일반 |
| 2 | OA974876 | XXXXX | C01 | M | 2015-05-01 00:00:00 | NaN | CA1 | 0 | 0_종일 | 10500 | 2_일반 |
| 3 | HD024127 | XXXXX | C01 | F | 2015-05-01 00:00:00 | NaN | CA1 | 0 | 0_종일 | 10500 | 2_일반 |
| 4 | HD661448 | XXXXX | C03 | F | 2015-05-01 00:00:00 | NaN | CA1 | 0 | 2_야간 | 6000 | 2_일반 |
print(len(customer))
print(len(customer_join))4192
4192▶조인 이후에 데이터 갯수가 달라지지 않았는지 확인.
조인할 때 키가 없거나 잘못되면 자동으로 결측치가 포함된다. 조인 후에 결측치를 꼭 확인해주자.
customer_join.isnull().sum()customer_id 0
name 0
class 0
gender 0
start_date 0
end_date 2842
campaign_id 0
is_deleted 0
class_name 0
price 0
campaign_name 0
dtype: int64▶end_date 외에 결측치가 없으므로, class_name, price, campaign_name은 잘 들어갔다.
end_date에 결측이 있는 이유는 탈퇴하지 않은 회원은 탈퇴일이 없기 때문으로 예상할 수 있다.
3. 고객데이터를 집계 해보자
⏺어떤 회원과 어떤 캠페인이 많은지, 언제 입회/탈퇴가 많은지, 성별 비율, 탈퇴까지 남은 기간 등을 확인
customer_join.groupby("class_name").count()["customer_id"]class_name
0_종일 2045
1_주간 1019
2_야간 1128
Name: customer_id, dtype: int64▶회원 클래스는 종일 > 야간 > 주간 순으로 많으며, 종일반이 거의 절반을 차지하고 있다.
customer_join.groupby("campaign_name").count()["customer_id"]campaign_name
0_입회비반액할인 650
1_입회비무료 492
2_일반 3050
Name: customer_id, dtype: int64▶입회 캠페인을 통해 가입한 사람이 약 20%이다.
customer_join.groupby("gender").count()["customer_id"]gender
F 1983
M 2209
Name: customer_id, dtype: int64customer_join.groupby("is_deleted").count()["customer_id"]is_deleted
0 2842
1 1350
Name: customer_id, dtype: int64▶2019년 3월 기준으로 현재 가입된 회원은 2,842명, 탈퇴한 유저는 1,350명
2018.04 부터 2019.03 말까지 가입 인원을 집계해보자.
customer_join["start_date"] = pd.to_datetime(customer_join["start_date"])
customer_start = customer_join.loc[customer_join["start_date"]>pd.to_datetime("20180401")]
print(len(customer_start))13614. 최근 고객데이터를 집계
⏺고객 데이터에는 탈퇴한 고객도 포함되어 있기 때문에 가장 최근 2019.03월 데이터를 집계해서 현재 고객 전체 모습을 파악해보자.
customer_join["end_date"] = pd.to_datetime(customer_join["end_date"])
customer_newer = customer_join.loc[(customer_join["end_date"]>=pd.to_datetime("20190331"))|(customer_join["end_date"].isna())]
print(len(customer_newer))
customer_newer["end_date"].unique()2953
array([ 'NaT', '2019-03-31T00:00:00.000000000'],
dtype='datetime64[ns]')▶데이터는 총 2,953건이고, 유니크 값인 NaT는 datetime형의 결측치로, 여기서는 탈퇴하지 않은 고객을 뜻한다.
이 기간 대상 고객의 회원 구분, 캠페인, 성별 분포도 확인해보자.
customer_newer.groupby("class_name").count()["customer_id"]class_name
0_종일 1444
1_주간 696
2_야간 813
Name: customer_id, dtype: int64customer_newer.groupby("campaign_name").count()["customer_id"]campaign_name
0_입회비반액할인 311
1_입회비무료 242
2_일반 2400
Name: customer_id, dtype: int64customer_newer.groupby("gender").count()["customer_id"]gender
F 1400
M 1553
Name: customer_id, dtype: int64▶회원 구분이나 성별 구분에는 비율에 큰 차이가 없다. 이로 특정 회원 구분이나 성별이 탈퇴한 것은 아니라고 유추해볼 수 있다.
캠페인 구분에는 비율 상 약간의 차이가 있는데, 기존 전체 집계 데이터에서는 일반 입회 유저가 72%였으나, 최근 데이터에서는 비율이 81%이다.
5. 이용이력 데이터를 집계하자
⏺이용 이력 데이터는 고객 데이터와 달리, 이용 횟수의 변화나 정기적으로 이용하는지 등 시간적인 요소를 분석할 수 있다.
먼저, 월 이용 횟수에 평균값, 중앙값, 최대/최솟값 확인
#월/고객 이용 횟수 집계
uselog["usedate"] = pd.to_datetime(uselog["usedate"])
uselog["연월"] = uselog["usedate"].dt.strftime("%Y%m")
uselog_months = uselog.groupby(["연월","customer_id"],as_index=False).count()
uselog_months.rename(columns={"log_id":"count"}, inplace=True)
del uselog_months["usedate"]
uselog_months.head()| 연월 | customer_id | count | |
|---|---|---|---|
| 0 | 201804 | AS002855 | 4 |
| 1 | 201804 | AS009013 | 2 |
| 2 | 201804 | AS009373 | 3 |
| 3 | 201804 | AS015315 | 6 |
| 4 | 201804 | AS015739 | 7 |
#고객별 월 이용 횟수 집계
uselog_customer = uselog_months.groupby("customer_id").agg(["mean", "median", "max", "min" ])["count"]
uselog_customer = uselog_customer.reset_index(drop=False) #customer_id가 index로 들어있기 때문에 컬럼으로 변경해주기
uselog_customer.head()| customer_id | mean | median | max | min | |
|---|---|---|---|---|---|
| 0 | AS002855 | 4.500000 | 5.0 | 7 | 2 |
| 1 | AS008805 | 4.000000 | 4.0 | 8 | 1 |
| 2 | AS009013 | 2.000000 | 2.0 | 2 | 2 |
| 3 | AS009373 | 5.083333 | 5.0 | 7 | 3 |
| 4 | AS015233 | 7.545455 | 7.0 | 11 | 4 |
6. 이용이력 데이터로부터 정기이용 여부 플래그를 작성
⏺센터의 지속요소 중 하나로 정기적으로 센터를 이용하는 고객의 데이터가 중요하다.
정기적이라는 지표를 선정하는 기준은 다양하나, 여기서는 매주 같은 요일에 왔는지 유무로 판단해본다.
월/요일별 집계하고, 최댓값이 4 이상인 요일(매주 이용)이 하나라도 있으면 플래그를 1로 처리한다.
#고객별 월/요일 집계
uselog["weekday"] = uselog["usedate"].dt.weekday
#요일을 숫자로 변환 (0~6까지 숫자가 각 월~일요일에 해당)
uselog_weekday = uselog.groupby(["customer_id","연월","weekday"],
as_index=False).count()[["customer_id","연월", "weekday","log_id"]]
uselog_weekday.rename(columns={"log_id":"count"}, inplace=True)
uselog_weekday.head()| customer_id | 연월 | weekday | count | |
|---|---|---|---|---|
| 0 | AS002855 | 201804 | 5 | 4 |
| 1 | AS002855 | 201805 | 2 | 1 |
| 2 | AS002855 | 201805 | 5 | 4 |
| 3 | AS002855 | 201806 | 5 | 5 |
| 4 | AS002855 | 201807 | 1 | 1 |
▶AS002855고객의 경우 2018.04 토요일에 4번, 2018.05 토요일에도 4번, 2018.06 토요일에는 5번으로 매주 토요일 센터를 이용한다.
위를 활용해 횟수가 4,5회인 사람을 필터하면, 적어도 어떤 달의 특정 요일에는 매주 주기적으로 방문한 사람임을 확인할 수 있다.
❗ pd.where()함수
💡 pandas의 where함수 : df[''].where(조건문, 거짓 값에 대한 대체 값)의 형태로 사용한다.
예를들어 df['a'].where(df['a'] < 3, 10) 의 경우 a열 중 3보다 작은 값에는 그대로 a열의 값, 3이상인 값에 대해서는 10을 넣는다.
#고객별 최댓값을 계산하고, 4 이상인 경우 플래그를 지정
uselog_weekday = uselog_weekday.groupby("customer_id",as_index=False).max()[["customer_id", "count"]]
uselog_weekday["routine_flg"] = 0
uselog_weekday["routine_flg"] = uselog_weekday["routine_flg"].where(uselog_weekday["count"] < 4, 1)
uselog_weekday.head()| customer_id | count | routine_flg | |
|---|---|---|---|
| 0 | AS002855 | 5 | 1 |
| 1 | AS008805 | 4 | 1 |
| 2 | AS009013 | 2 | 0 |
| 3 | AS009373 | 5 | 1 |
| 4 | AS015233 | 5 | 1 |
7. 고객 데이터와 이용이력데이터를 결합
customer_join = pd.merge(customer_join, uselog_customer, on="customer_id", how="left")
customer_join = pd.merge(customer_join, uselog_weekday[["customer_id", "routine_flg"]], on="customer_id", how="left")
customer_join.head()| customer_id | name | class | gender | start_date | end_date | campaign_id | is_deleted | class_name | price | campaign_name | mean | median | max | min | routine_flg | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | OA832399 | XXXX | C01 | F | 2015-05-01 | NaT | CA1 | 0 | 0_종일 | 10500 | 2_일반 | 4.833333 | 5.0 | 8 | 2 | 1 |
| 1 | PL270116 | XXXXX | C01 | M | 2015-05-01 | NaT | CA1 | 0 | 0_종일 | 10500 | 2_일반 | 5.083333 | 5.0 | 7 | 3 | 1 |
| 2 | OA974876 | XXXXX | C01 | M | 2015-05-01 | NaT | CA1 | 0 | 0_종일 | 10500 | 2_일반 | 4.583333 | 5.0 | 6 | 3 | 1 |
| 3 | HD024127 | XXXXX | C01 | F | 2015-05-01 | NaT | CA1 | 0 | 0_종일 | 10500 | 2_일반 | 4.833333 | 4.5 | 7 | 2 | 1 |
| 4 | HD661448 | XXXXX | C03 | F | 2015-05-01 | NaT | CA1 | 0 | 2_야간 | 6000 | 2_일반 | 3.916667 | 4.0 | 6 | 1 | 1 |
customer_join.isnull().sum()customer_id 0
name 0
class 0
gender 0
start_date 0
end_date 2842
campaign_id 0
is_deleted 0
class_name 0
price 0
campaign_name 0
mean 0
median 0
max 0
min 0
routine_flg 0
dtype: int64▶기존 end_date의 결측치 갯수와 동일하므로, 결합에는 문제가 없다는 것을 확인.
8. 회원기간을 계산해보자.
⏺회원 기간은 start_date와 end_date의 차이이다. 다만 아직 탈퇴하지 않은 회원은 그 차이를 계산할 수 없다.
이 경우 2019
03.31로 값을 채워버리면 실제로 3월에 탈퇴하는 회원과 구분할 수 없으므로, 탈퇴하지 않은 회원은 임의로 2019.04.30일로 채워서 회원 기간을 계산해본다.
💡날짜 비교 함수 relativedelta를 사용해서 계산
from dateutil.relativedelta import relativedelta
customer_join["calc_date"] = customer_join["end_date"]
customer_join["calc_date"] = customer_join["calc_date"].fillna(pd.to_datetime("20190430"))
customer_join["membership_period"] = 0
for i in range(len(customer_join)):
delta = relativedelta(customer_join["calc_date"].iloc[i], customer_join["start_date"].iloc[i])
customer_join["membership_period"].iloc[i] = delta.years*12 + delta.months
customer_join.head()| customer_id | name | class | gender | start_date | end_date | campaign_id | is_deleted | class_name | price | campaign_name | mean | median | max | min | routine_flg | calc_date | membership_period | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | OA832399 | XXXX | C01 | F | 2015-05-01 | NaT | CA1 | 0 | 0_종일 | 10500 | 2_일반 | 4.833333 | 5.0 | 8 | 2 | 1 | 2019-04-30 | 47 |
| 1 | PL270116 | XXXXX | C01 | M | 2015-05-01 | NaT | CA1 | 0 | 0_종일 | 10500 | 2_일반 | 5.083333 | 5.0 | 7 | 3 | 1 | 2019-04-30 | 47 |
| 2 | OA974876 | XXXXX | C01 | M | 2015-05-01 | NaT | CA1 | 0 | 0_종일 | 10500 | 2_일반 | 4.583333 | 5.0 | 6 | 3 | 1 | 2019-04-30 | 47 |
| 3 | HD024127 | XXXXX | C01 | F | 2015-05-01 | NaT | CA1 | 0 | 0_종일 | 10500 | 2_일반 | 4.833333 | 4.5 | 7 | 2 | 1 | 2019-04-30 | 47 |
| 4 | HD661448 | XXXXX | C03 | F | 2015-05-01 | NaT | CA1 | 0 | 2_야간 | 6000 | 2_일반 | 3.916667 | 4.0 | 6 | 1 | 1 | 2019-04-30 | 47 |
9. 고객행동의 각종통계량을 파악해보자.
customer_join[["mean", "median", "max", "min"]].describe()| mean | median | max | min | |
|---|---|---|---|---|
| count | 4192.000000 | 4192.000000 | 4192.000000 | 4192.000000 |
| mean | 5.333127 | 5.250596 | 7.823950 | 3.041269 |
| std | 1.777533 | 1.874874 | 2.168959 | 1.951565 |
| min | 1.000000 | 1.000000 | 1.000000 | 1.000000 |
| 25% | 4.250000 | 4.000000 | 7.000000 | 2.000000 |
| 50% | 5.000000 | 5.000000 | 8.000000 | 3.000000 |
| 75% | 6.416667 | 6.500000 | 9.000000 | 4.000000 |
| max | 12.000000 | 12.000000 | 14.000000 | 12.000000 |
▶고객의 매월 평균 이용횟수는 약 5회 정도.
customer_join.groupby("routine_flg").count()["customer_id"]routine_flg
0 779
1 3413
Name: customer_id, dtype: int64정기적으로 이용하는 회원 횟수가 훨씬 많다.
#회원 기간별 분포
import matplotlib.pyplot as plt
%matplotlib inline
plt.hist(customer_join["membership_period"])(array([857., 774., 395., 368., 311., 331., 323., 237., 288., 308.]),
array([ 1. , 5.6, 10.2, 14.8, 19.4, 24. , 28.6, 33.2, 37.8, 42.4, 47. ]),
<BarContainer object of 10 artists>)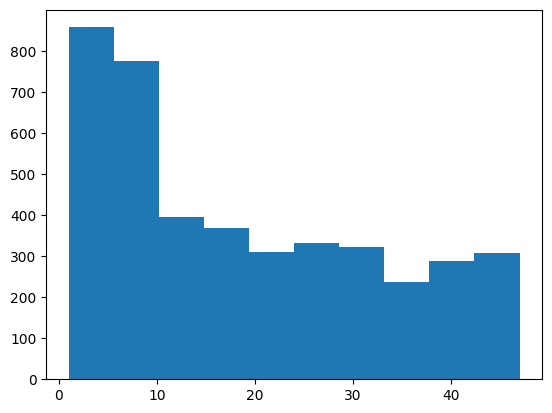
▶회원 기간이 10개월 이내인 고객이 많고, 그 이상의 고객 수는 대부분 일정하다. 비교적 짧은 기간 내에 고객이 빠져나가는 편이다.
10. 탈퇴회원과 지속회원의 차이를 파악하자
⏺스포츠 센터의 운영을 위해서는 단기적 고객의 탈퇴를 방지하는 방안을 모색하는 것이 중요해보인다.
지속 회원과 탈퇴 회원을 구분하여 각 특징을 파악해보자.
#탈퇴 고객
customer_end = customer_join.loc[customer_join["is_deleted"]==1]
customer_end.describe()| is_deleted | price | mean | median | max | min | routine_flg | membership_period | |
|---|---|---|---|---|---|---|---|---|
| count | 1350.0 | 1350.000000 | 1350.000000 | 1350.000000 | 1350.000000 | 1350.000000 | 1350.000000 | 1350.000000 |
| mean | 1.0 | 8595.555556 | 3.865474 | 3.621852 | 6.461481 | 1.821481 | 0.456296 | 8.026667 |
| std | 0.0 | 1949.163652 | 1.246385 | 1.270847 | 2.584021 | 0.976361 | 0.498271 | 5.033692 |
| min | 1.0 | 6000.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 0.000000 | 1.000000 |
| 25% | 1.0 | 6000.000000 | 3.000000 | 3.000000 | 4.000000 | 1.000000 | 0.000000 | 4.000000 |
| 50% | 1.0 | 7500.000000 | 4.000000 | 4.000000 | 7.000000 | 2.000000 | 0.000000 | 7.000000 |
| 75% | 1.0 | 10500.000000 | 4.666667 | 4.500000 | 8.000000 | 2.000000 | 1.000000 | 11.000000 |
| max | 1.0 | 10500.000000 | 9.000000 | 9.000000 | 13.000000 | 8.000000 | 1.000000 | 23.000000 |
#지속 고객
customer_stay = customer_join.loc[customer_join["is_deleted"]==0]
customer_stay.describe()| is_deleted | price | mean | median | max | min | routine_flg | membership_period | |
|---|---|---|---|---|---|---|---|---|
| count | 2842.0 | 2842.000000 | 2842.000000 | 2842.000000 | 2842.000000 | 2842.000000 | 2842.000000 | 2842.000000 |
| mean | 0.0 | 8542.927516 | 6.030288 | 6.024279 | 8.471147 | 3.620690 | 0.984166 | 23.970443 |
| std | 0.0 | 1977.189779 | 1.553587 | 1.599765 | 1.571048 | 2.030488 | 0.124855 | 13.746761 |
| min | 0.0 | 6000.000000 | 3.166667 | 3.000000 | 5.000000 | 1.000000 | 0.000000 | 1.000000 |
| 25% | 0.0 | 6000.000000 | 4.833333 | 5.000000 | 7.000000 | 2.000000 | 1.000000 | 12.000000 |
| 50% | 0.0 | 7500.000000 | 5.583333 | 5.500000 | 8.000000 | 3.000000 | 1.000000 | 24.000000 |
| 75% | 0.0 | 10500.000000 | 7.178030 | 7.000000 | 10.000000 | 5.000000 | 1.000000 | 35.000000 |
| max | 0.0 | 10500.000000 | 12.000000 | 12.000000 | 14.000000 | 12.000000 | 1.000000 | 47.000000 |
탈퇴 / 지속 회원의 차이
✅당연한 결과겠지만 탈퇴 회원의 이용 횟수 통계값이 모두 지속 회원에 비교해 작다. 특히 평균값, 중앙값은 1.5배 정도 차이남을 볼 수 있다.
반면 매월 최대 이용 횟수는 지속회원이 높긴 하지만 탈퇴 회원도 6.4 정도로 큰 차이가 나지는 않는다.
routine_flg를 보면 지속회원은 평균 0.98로 대부분의 회원이 정기적으로 방문하고 있지만, 탈퇴 회원의 평균은 0.45로 절반정도만 정기적으로 방문했다.
이렇게 행동 데이터를 풀어가면 탈퇴 회원과의 차이를 확인할 수 있고, 기간을 줄여서 확인해보거나 재적 기간 별로 더 상세히 보면 또 다른 특징을 발견할 수 있다.
