
분산 파일 시스템
- 네트워크 기반으로 연결된 여러 머신의 스토리지를 관리하는 파일 시스템
- 하나의 머신에서 장애가 발생하더라도 데이터가 유실되지 않도록 분산
GFS (Google File System)
- 2003년 Google이 직면한 증가하는 데이터 처리 요구사항을 충족하기 위해 특별히 제작되었으며, 논문으로 소개되었고 이는 HDFS의 모태가 되었다.
- GFS 클러스터는 단일 GFS Master Server와 여러 개의 GFS Chunk Server로 구성되며, 여러 Client에서 액세스 할 수 있다.
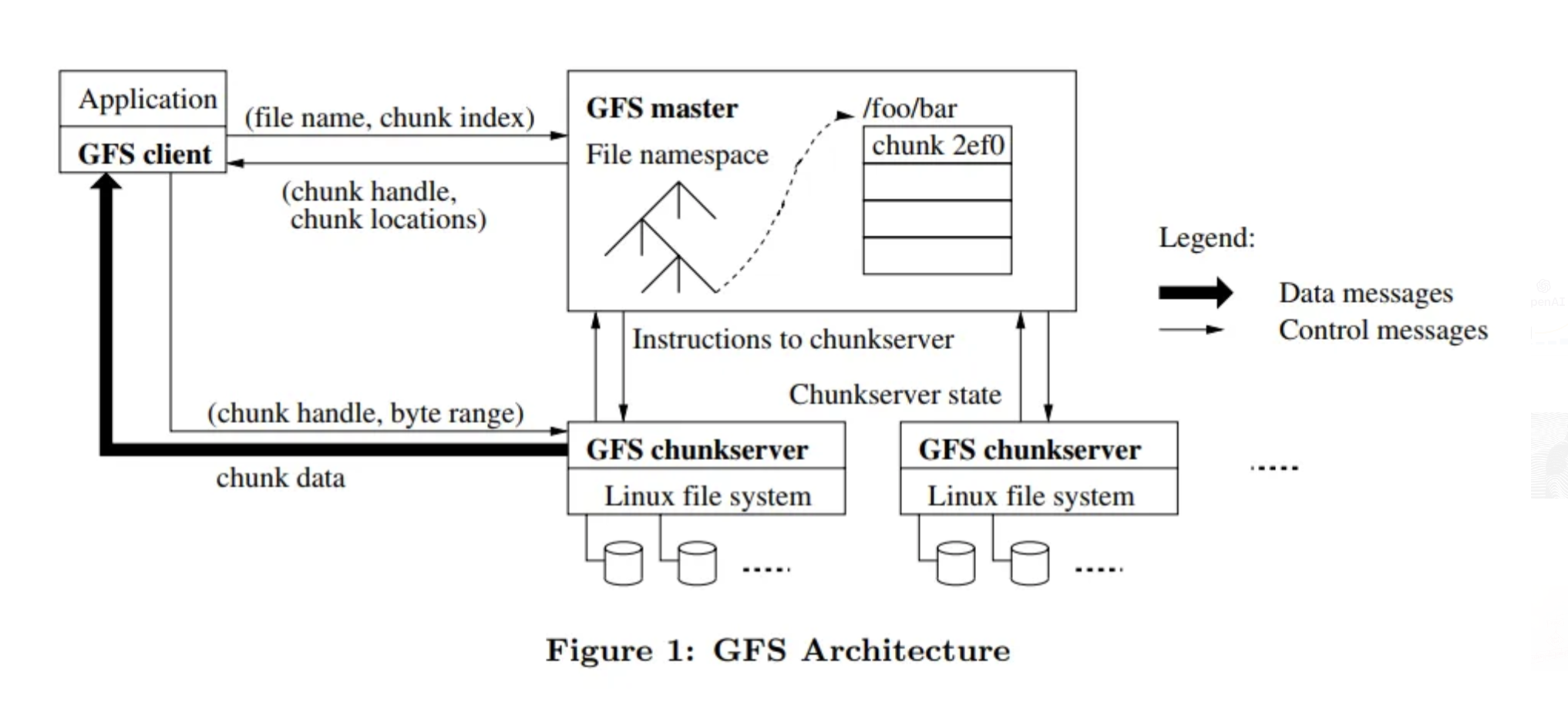
- GFS Master Server는 File의 네임 스페이스, 엑세스 제어 정보, 파일이서 Chunk로의 매핑 및 Chunk의 현재 위치를 포함하는 모든 파일 시스템 메타 데이터를 유지한다.
- GFS의 파일은 Chunk Server에서 로컬 디스크에 Linux 파일로 Chunk를 저장하고, Chunk를 핸들링하기 위해 바이트 범위로 지정된 청크 데이터를 읽거나 쓸 수 있다.
- 각 Chunk는 기본 복제본 수 3개로 여러 Chunk Server에 복제되기 때문에 하드웨어 오류가 발생할 경우에도 데이터 손실을 방지할 수 있다.
- GFS는 모든 시스템의 Master Server(Node)가 겪는 가장 일반적인 문제인 병목 현상을 피해 단일 지점 실패로 이어지지 않기 위해서, 읽기 및 쓰기에 대한 마스터의 개입을 최소화하고 대신 클라이언트는 마스터에게 어떤 Chunk Server에 해당 작업을 수행하기 위해 어떤 Chunk Server에 접속해야 하는 지 요청 후 Chunk Server와 직접 상호작용한다.
HDFS (Hadoop Distributed File System)
- HDFS는 GFS를 모델로 만들어진 오픈소스로 기존의 대용량 파일시스템과 다르게 저사양 서버를 하나로 묶어서 하나의 스토리지처럼 사용할 수 있게 되었다.
- HDFS는 클라이언트의 요청을 빠른 시간 안에서 처리하는 것 보다 동일한 시간 내에 더 많은 데이터를 처리하는 것을 목표로 하기 때문에 인터넷 뱅킹이나 인터넷 쇼핑몰과 같은 서비스에서 HDFS를 사용하는 것은 적합하지 않다.
- HDFS는 하나의 파일이 GB 또는 TB 그 이상의 크기로 저장할 수 있도록 설계되어 있다.
- HDFS는 한 번 저장한 데이터는 더 이상 수정할 수 없고, 읽기만 가능하도록 데이터 무결성을 유지한다.
- HDFS는 데이터의 수정은 불가능하지만 파일 이동, 삭제, 복사 할 수 있는 인터페이스를 제공하며, 한 번 기록된 데이터의 수정이 불가능한 부분은 Hadoop 2.0부터 저장된 파일에 Append 할 수 있는 기능이 추가되었다.
Block Structure File System
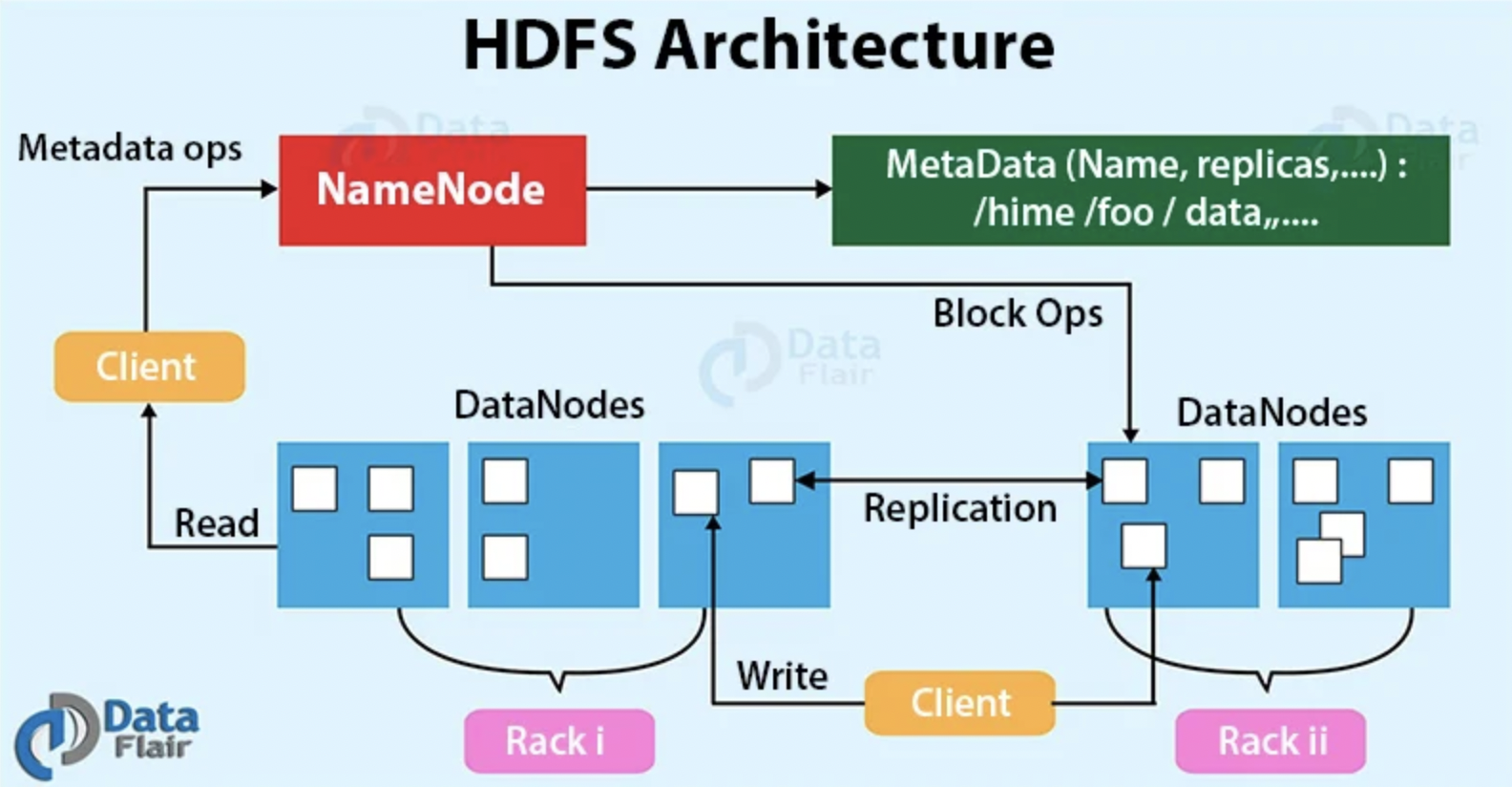
HDFS Block
- HDFS에 저장되는 파일은 특정 크기의 블록으로 나뉘어서 분산된 서버에 저장할 수 있다.
- Hadoop 1.0 버전에서는 기본 블록 사이즈가 64MB, Hadoop 2.0 버전에서는 기본 블록 사이즈가 128MB이다.
- 파일 하나의 크기가 실제 하나의 물리 디스크 사이즈보다 커질 수 있다.
- 실제 파일 크기가 블록 사이즈보다 적은 경우 파일 크기 만큼만 디스크를 사용한다.
HDFS Block 사이즈가 큰 이유 (1) - 탐색 비용 최소화
- HDFS는 데이터를 전송하는데 더 많은 시간을 할애할 수 있도록 디스크 내에 데이터의 위치를 찾는 시간과 원하는 데이터의 위치에 도달하는 전반적인 데이터 탐색 비용을 최소화하기 위해 설계되었다.
- 일반적인 디스크 블록에 비해 블록 사이즈가 큰 용량을 사용하면서 블록의 시작점을 탐색하는 비용을 최소화 할 수 있다.
HDFS Block 사이즈가 큰 이유 (2) - 네임노드의 메타데이터 크기 감소
- HDFS의 NameNode는 블록의 위치, 파일 명, 디렉토리 구조와 같은 메타데이터 정보를 메모리에 저장하고 관리하는데, 파일 하나 당 블록 단위로 나누어서 저장할 수 있는 블록 사이즈가 클수록 NameNode에 저장되는 메타데이터의 용량이 감소하게 된다.
NameNode & Secondary NameNode
NameNode
- NameNode는 파일 시스템을 유지하기 위해서 FsImage(File system Image)와 EditLog인 메타데이터를 관리한다.
- FsImage는 네임스페이스를 포함한 데이터의 모든 정보를 담고있다.
- EditLog는 DataNode에서 발생한 데이터의 변환 내역을 담고 있다.
- NameNode는 DataNode에서 전송된 하트비트(Heartbeat)를 통해 DataNode의 상태 정보와 DataNode에 저장되어 있는 블록의 목록을 주기적으로 전송하면서 모니터링한다.
Secondary NameNode
- NameNode의 Standby 역할이 아니다.
- Secondary NameNode는 NameNode의 FsImage와 EditLog를 주기적으로 병합하고 Checkpoint로서의 역할과 FsImage와 EditLog를 백업하는 일을 수행한다.
Checkpoint란 NameNode가 시작하게 되면 FsImage를 로딩한 후, 변경 사항을 적용하기 위해 EditLog를 반영하여 병합하는 작업을 의미한다. FsImage는 생성되면 변경되지 않으며, HDFS가 실행되면서 발생하는 모든 변경사항은 EditLog에 반영된다.
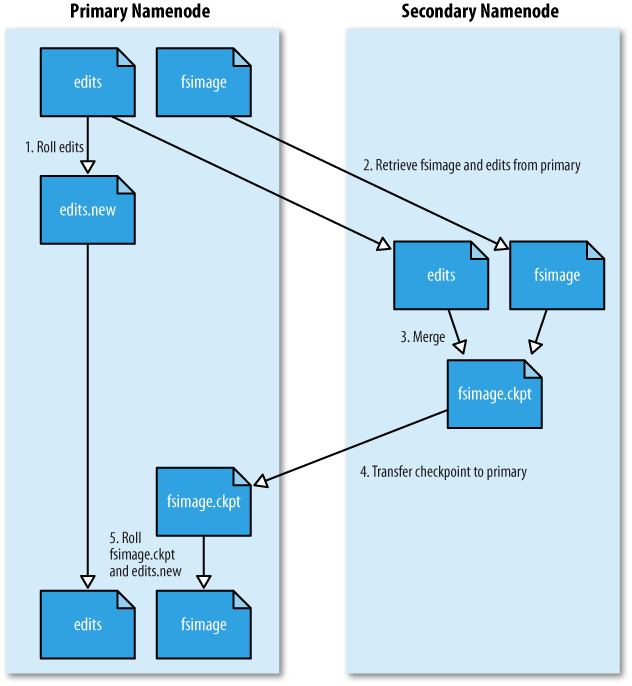
- Checkpoint 과정을 통해서 EditLog가 커짐에 따라서 발생할 수 있는 디스크 용량의 문제를 방지하고, NameNode가 재구동하는 시간을 좀 더 빠르게 할 수 있다.
DataNode
- 실제 파일을 로컬 파일 시스템에 HDFS 데이터를 저장한다.
- 하트비트를 통해 데이터 노드의 동작 여부를 NameNode에 주기적으로 전달한다.
- 저장하고 있는 블록의 목록을 주기적으로 NameNode에 보고한다.
HDFS 읽기 연산 과정
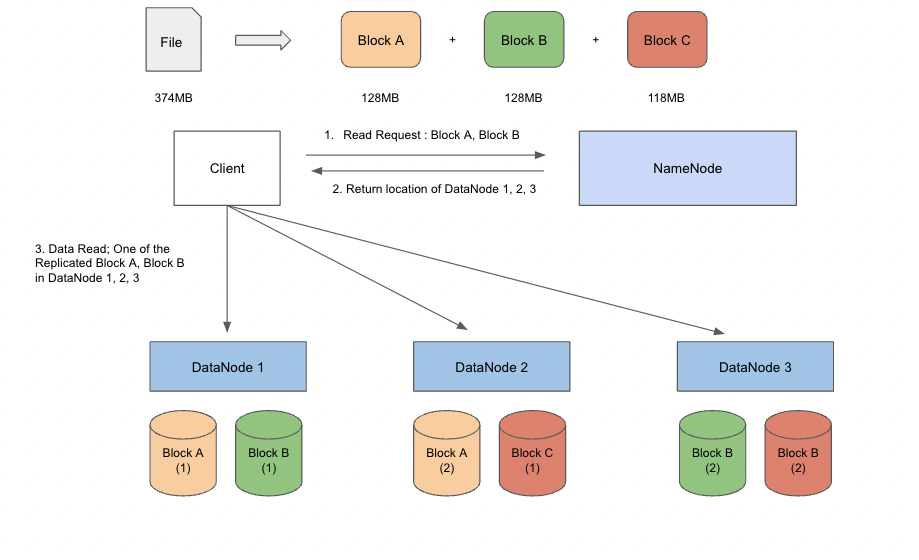
Replication Factor가 2(Default: 3)로 Block A, B, C 데이터가 각각 1개의 복사본을 가지면서 2개씩 총 6개의 블럭 데이터가 생성되고 이를 총 3개의 DataNode에 저장함으로서 특정 서버의 디스크에서 문제가 발생하더라도 복제된 블록을 이용하여 데이터 조회에 문제가 발생하지 않도록한다.
- 클라이언트가 NameNode에게 File의 Block A와 Block B의 내용을 읽기 위한 요청을 보냄
- NameNode는 클라이언트에게 Block A와 Block B의 블록 데이터가 위치한 DataNode의 위치를 전송
- 클라이언트는 NameNode에서 받은 Block A와 Block B의 블록 데이터가 위치한 DataNode의 위치 정보를 기반으로 데이터 읽기
Hadoop 2.x Architecture의 HA와 HDFS Federation 지원
HDFS HA(High Availabiliby, 고가용성) 지원
Hadoop 1.x Architecture에서 NameNode는 단일 실패 지점으로, NameNode가 다운되면 이후 Hadoop 클러스터 자체에 접근할 수 없다.
- 위와 같은 Hadoop 1.x Architecture의 문제를 해결하기 위해서 Hadoop 2.x Architecture에서는 한 번에 2개의 NameNode를 지원하면서, Active NameNode와 Standby NameNode를 사용했다.
- Active NameNode는 클러스터에서 클라이언트와의 작업을 처리한다.
- Standby NameNode는 Hadoop 1.x의 Secondary NameNode와 동일한 방식으로 FsImage와 EditLog를 사용하여 Checkpoint로 NameNode의 메타데이터를 관리한다.
- Hadoop 1.x Architecture에서의 Secondary NameNode와 다르게 Hadoop 2.x Architecture에서 Standby NameNode는 Active NameNode가 다운되면 이를 인계받아 클라이언트와의 작업을 처리한다.
Hadoop 1.x Architecture에서 NameNode는 파일 블록들의 정보를 관리하기 위해 네임스페이스를 사용하여 전체 클러스터에서 단일 네임스페이스만 관리할 수 있었다. 따라서, NameNode가 다운되면 전체 클러스터에 접근할 수 없었기 때문에 부분적인 데이터 가용성이 불가능했다.
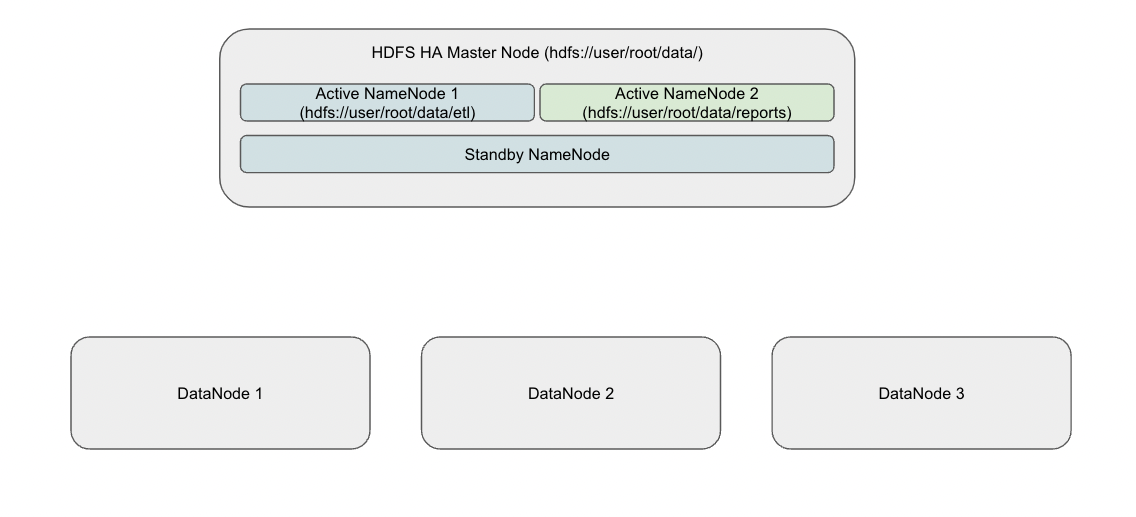
- 위와 같은 Hadoop 1.x Architecture의 문제를 해결하기 위해서 Hadoop 2.x Architecture에서는 여러 개의 NameNode를 사용하여 여러 개의 네임스페이스를 관리할 수 있다.
- HDFS 클러스터에서 상위 디렉토리를 사용할 수 있지만, 하위에 존재하는 서로 다른 디렉토리가 한 번에 여러 Active NameNode에 의해서 관리될 수 있었다.
Reference
