지도학습
- 지도학습은 분류와 회귀로 나뉜다.
분류
- 미리 정의된 클래스 중 하나를 예측
- 이진분류 : 두 개의 클래스로 분류 ex) 예/아니오
- 다중분류 : 셋 이상(3개 이상)의 클래스 중 하나로 분류
-- ex) 붓꽃(Iris) 데이터에서 꽃을 "setosa", "versicolor", "virginica" 중 하나로 분류하는 문제
회귀
- 연속적인 숫자를 예측하는 것
- 출력 값에 연속성이 있다 --> 회귀 ex) 연소득 예측, 연속성 없으면 분류
과대적합
- 모델이 너무 훈련되서 패턴을 외워버린 상태
- 훈련 외의 새로운데이터에 대해 성능이 떨어짐
- 개선방법 : 모델단순화, 데이터추가, 정규화 등
과소적합
- 훈련 데이터조차 잘 예측하지 못하는 상태
- 모델이 너무 단순해서 패턴을 잘 잡지 못함
- 개선방법 : 모델복잡도증가, 더 많은 특성사용, 정규화 완화를 통한 더 복잡한 학습
원 - 핫 인코딩
-
문자(카테고리)형 변수가 있을 때
-- 예시: 성별(gender: 남, 여), 요일(day: 월, 화, 수, …), 지역(region: 서울, 부산, 대구, …) 등 -
머신러닝 알고리즘이 숫자형 입력만 받을 때
-- 대부분의 머신러닝 모델(특히 KNN, 로지스틱 회귀, SVM, 신경망 등)은 카테고리형 변수를 그대로 처리하지 못함
예시: '남', '여'를 0, 1로만 바꾸면 순서와 크기 의미가 생겨서 부적절할 수 있음. 대신, 각 범주마다 새로운 열을 만들어 0 또는 1로 표시 (예: 남=1, 여=0) -
순서가 없는 범주형 변수일 때
-- 예시: 색상(color: 빨강, 파랑, 초록)
-- 순서가 없는 값은 원-핫 인코딩이 적합 -
성별에 따른 overbuy ratio - Knn
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier # 1. 데이터 준비 (성별 포함) data = { 'age': [25, 34, 45, 23, 31, 52, 40, 29, 38, 49], 'family_size': [1, 2, 4, 1, 3, 5, 2, 1, 3, 4], 'monthly_purchase': [100, 250, 600, 130, 400, 800, 200, 120, 390, 700], 'gender': ['F', 'M', 'F', 'F', 'M', 'M', 'F', 'F', 'M', 'M'], 'overbuy': [0, 0, 1, 0, 1, 1, 0, 0, 1, 1] } df = pd.DataFrame(data) # 2. 범주형(성별) 원-핫 인코딩 df_encoded = pd.get_dummies(df, columns=['gender']) # 3. X, y 나누기 X = df_encoded.drop('overbuy', axis=1) y = df_encoded['overbuy'] # 4. 학습/테스트 분리 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 5. KNN 모델 학습 knn = KNeighborsClassifier(n_neighbors=3) knn.fit(X_train, y_train) # === 여기가 중요! === # 6. 새 데이터 입력 (예: 나이 28, 가족수 2, 월평균구매 350, 성별 'M') new_data = pd.DataFrame({ 'age': [28], 'family_size': [2], 'monthly_purchase': [350], 'gender_F': [0], # 'F'가 아니고 'gender_M': [1] # 'M'이므로 }) # 7. 예측 prediction = knn.predict(new_data) print("Overbuy 예측 결과:", "Overbuy" if prediction[0]==1 else "Not Overbuy")
-
전체적인 흐름
- 데이터를 준비하여 pandas에서 활용할 수 있게 변경
- 성별로 구분하려고 원-핫 인코딩 사용
- overbuy를 가지는 값과 안가지는 값으로 X,y를 나눔
- 학습/테스트 분리(train_test_split)
- knn 모델 객체 생성 후 학습
- new_data를 입력 후 예측
-
성별에 따른 overbuy ratio - 랜덤 포레스트
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier import matplotlib.pyplot as plt # 1. 데이터 준비 data = { 'age': [25, 34, 45, 23, 31, 52, 40, 29, 38, 49], 'family_size': [1, 2, 4, 1, 3, 5, 2, 1, 3, 4], 'monthly_purchase': [100, 250, 600, 130, 400, 800, 200, 120, 390, 700], 'gender': ['F', 'M', 'F', 'F', 'M', 'M', 'F', 'F', 'M', 'M'], 'overbuy': [0, 0, 1, 0, 1, 1, 0, 0, 1, 1] } df = pd.DataFrame(data) # 2. 성별 원-핫 인코딩 df_encoded = pd.get_dummies(df, columns=['gender']) # 3. X, y 분리 X = df_encoded.drop('overbuy', axis=1) y = df_encoded['overbuy'] # 4. train/test 분리 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 5. 랜덤포레스트 모델 생성 및 학습 rf = RandomForestClassifier(n_estimators=100, random_state=42) rf.fit(X_train, y_train) # 6. 예측 및 정확도 y_pred = rf.predict(X_test) accuracy = (y_pred == y_test).mean() print(f"테스트 세트 정확도: {accuracy:.2f}") # 7. 새로운 데이터 예측 (예: 28세, 가족2, 월350, 남자) new_data = pd.DataFrame({ 'age': [28], 'family_size': [2], 'monthly_purchase': [350], 'gender_F': [0], 'gender_M': [1] }) proba = rf.predict_proba(new_data)[0] print(f"Not Overbuy 확률: {proba[0]:.2f}, Overbuy 확률: {proba[1]:.2f}") # 8. 예측 확률 시각화 plt.bar(['Not Overbuy', 'Overbuy'], proba, color=['skyblue', 'tomato']) plt.title('Prediction Probability') plt.ylabel('Probability') plt.ylim(0, 1) for i, v in enumerate(proba): plt.text(i, v + 0.02, f'{v:.2f}', ha='center', fontsize=12) plt.show()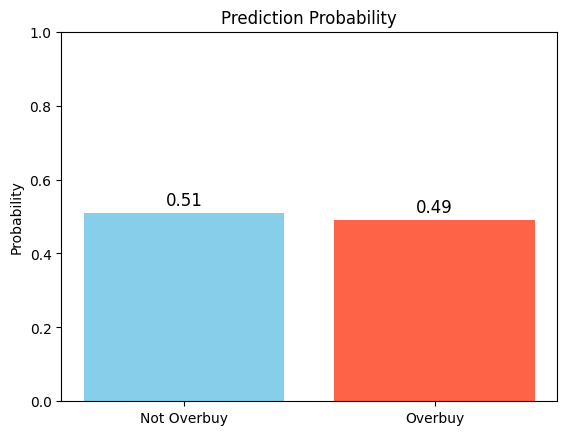
머신러닝에 대해서 감을 전혀 못잡겠다. 어떤 순서로 흘러가는지도 모르겠고 그냥 냅다 책만 따라하고 있는 느낌이다. 이렇게해서 내 실력이 늘까?? 난 진짜 아니라고 생각한다. 맨땅에 헤딩을 해도 어떤 땅인지는 알고 헤딩해야한다. 효율적으로 공부하는 방법을 찾아야겠다. 내일부터는 코랩 -> 주피터랩으로 변경하고 기초 캐글문제를 직접 부딪히며 풀면서 공부를 진행하려한다. 제발 게으르게 행동하지말고 하자.
