들어가며
우리는 서버 가상화 기술을 사용하면서, 자연스럽게 메모리를 여러 가상 머신(VM)에 나누어주고 있다. 그런데 어떻게 이게 가능한 것일까? 분명 가상 머신의 게스트 OS 커널은 전체 메모리를 독점하고 있다고 생각할 것인데, 실제로는 그렇지 않기 때문이다.
이번 포스팅에서는 메모리 가상화 기술의 배경에는 어떤 기술들이 있고, x86 가상화에서 메모리 가상화 기술이 어떻게 동작하는지 알아볼 것이다.
이 글을 다 읽고 나면 하이퍼바이저가 메모리를 어떻게 관리하고, VM에 추상화시켜줄 수 있는지, 그리고 메모리 가상화의 오버헤드를 어떻게 최소화 할 수 있었는지 알게 될 것이다.
가상 메모리 (Virtual Memory)
메모리 가상화를 이야기하기에 앞서, 우리는 가상 메모리 기술을 이해해야만 한다.
왜냐하면 모든 현대 OS가 MMU를 기반으로 하는 가상 메모리 기술을 사용하고 있으며, 하이퍼바이저 또한 예외가 아니기 때문이다.
그리고 가상 메모리 기법은 하이퍼바이저가 VM에게 메모리를 할당해 주기 위한 메커니즘의 근간을 이루고 있다.
그래서 가상 메모리란 무엇일까? CS 교재에서 정의하는 가상 메모리의 정의는 다음과 같다.
메인 메모리의 물리적 크기 제한을 극복하기 위하여, 보다 저렴한 보조 기억장치의 공간을 대신 사용할 수 있게 하는 기법
가상 메모리 기술의 시작점이 값비싼 자기 코어 메모리 대신 보다 저렴한 자기 디스크를 사용하는 것이었기 때문에, 역사적 맥락에서 이 관점은 올바르다.
최초의 가상 메모리 구현체인 Atlas 시스템은 주 기억 장치와 보조 기억장치 사이에서 동작하는 페이징 메커니즘과 Page out 할 페이지를 식별하는 방법, 그 페이지를 사용자 개입 없이 자동으로 전송하는 방법 등을 구현하였다.[1]
하지만 현대 컴퓨터 시스템에서 페이징 기법은 보조 기억장치 활용보다 더 중요한 의미를 가지고 있다.
바로 '가상 메모리 주소'의 개념을 도입한 것이다.
가상 메모리 주소 (Virtual Memory Address)
어떠한 프로그램이 실행되려면 그 프로그램이 할당받을 메모리 공간이 필요하다. 해당 메모리 공간은 프로그램이 독점적으로 이용할 수 있어야 하며, 그 공간은 다른 프로그램이 할당받은 공간과 겹쳐서는(overlap) 안 된다.
그러나, 조금만 생각해봐도 이 가정에는 여러 문제가 엿보인다.
- 프로그램은 시작 전에 자신이 사용할 메모리를 사전에 할당받아야 한다.
전체 실행 시간에서 큰 메모리 공간을 사용하는 시간의 비중이 아주 낮더라도, 프로그램은 항상 사용할 메모리 공간을 모두 가지고 있어야 한다. - 메모리의 동적 할당이 불가능하다.
개발자는 프로그램을 작성할 때 이 프로그램이 사용할 메모리의 크기를 정확히 알고 있어야만 한다. - 메인 메모리의 크기가 변경될 때마다 그 위에서 동작할 프로그램을 재컴파일해야 한다.[2]
이 제약 사항들은 사용자의 수가 많지 않고, 리소스의 크기도 작았던 초기 메인프레임 시대에는 별 문제가 되지 않았다. 모든 개발자와 사용자들은 자신이 사용할 시스템의 세부 구현과 제약사항을 이해하고 있었으며, 정해진 프로그램을 연속적으로 실행하는 일괄 처리(Batch Processing) 방식이 주류를 이루었기 때문이기도 하다.
하지만 시스템의 규모가 커지고, 불특정 다수가 여러 프로그램을 임의의 시간에 로드하여 사용하게 되면서, 메인 메모리의 사용 효율을 높이고, 프로그램 주소를 추상화 할 수 있는 가상 메모리 기법이 주목을 받게 되었다.
이 관점에서 보았을 때, 가상 메모리 기술의 핵심은 바로 주소 공간(Address Space)의 추상화와 페이징(Paging)이다.
가상 메모리를 도입하는 것으로 개별 프로그램들은 자신이 메모리 공간을 전부 점유하고 있다고 생각하게 되었으며, 이 가상 메모리 주소(Virtual Address)와 물리 메모리 주소(Physical Address)를 매핑하고, 할당해 주기 위해 MMU(Memory Management Unit)와 페이징 기법이 사용되었다.
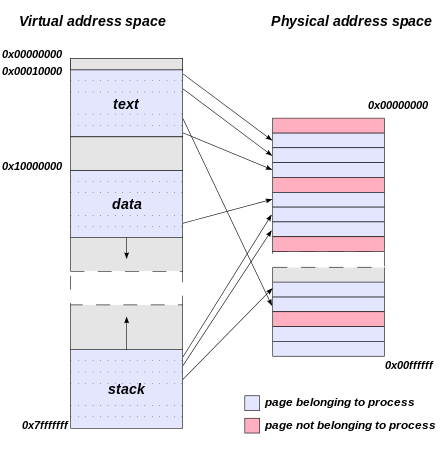
위 그림에서 보이듯이, 개별 프로세스는 전체 메모리 공간을 사용하며, 해당 메모리 공간은 페이지 단위로 물리 메모리에 매핑된다. x86에서 페이지 하나의 크기는 일반적으로 4KB이며, 경우에 따라 2MB와 1GB의 Hugepage를 사용할 수도 있다.
이렇게 페이지 단위로 메모리를 관리하게 되면서, 우리는 크게 두 가지의 이점을 얻게 되었다.
하나는 메모리 공간의 효율적인 사용이다. 요구 페이징(Demand Paging) 기법을 도입하는 것으로 이제 시스템은 특정 프로그램이 실행되는 그 순간에 필요한 메모리만을 할당하면 된다.
나머지 하나는 메모리 공간의 동적 할당이다. 이제 프로그래머는 특정 시점에 메모리 공간을 동적으로 추가 할당할 수 있게 되었다.
물론, 요청한 공간을 반드시 할당받을 수 있다고 보장받지는 못하지만.
메모리 주소 변환 (Address Translation)
가상 메모리의 개념과 페이징 기법에 대해 알아보았으니, 이제 그것이 실제로 어떻게 동작하는지 알아볼 차례이다.
프로세스의 가상 메모리 주소와 물리 메모리 주소 사이의 변환을 위해서는 MMU와 페이지 테이블이 사용된다.
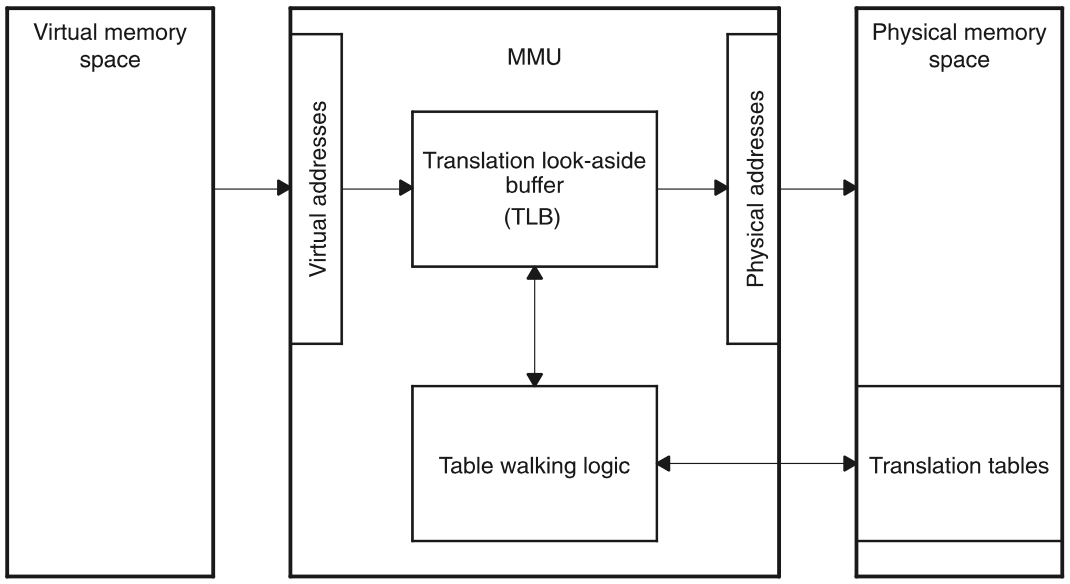
페이지 테이블은 메인 메모리에 저장되고, MMU는 페이지 테이블을 참조하여 Virtual Address - Physical Address 사이의 주소 변환을 실행한 뒤, 그 결과를 TLB(Table Lookaside Buffer)라는 캐시에 저장한다. 이는 지역성(locality) 원칙을 활용하여 주소 변환에 들어가는 오버헤드를 최소화하기 위함이다.
페이지 관리 및 주소 변환을 실행하는 MMU는 소프트웨어적으로 구현될 수도 있지만, 대부분의 현대 프로세서들은 이 일을 수행하는 전용 하드웨어를 내장하고 있다. x86에서 메모리 페이징 기법이 어떻게 동작하는지 좀 더 자세히 들어가 보자.
페이지 테이블 참조
현재, 대부분의 x86 기반 커널은 PML4 (Page-Map Level 4)를 사용한다. 이것은 개별 페이지를 참조하기 위해 총 4 단계의 계층 구조를 거친다는 의미이다. 이해를 돕기 위해 이미지를 하나 발췌하였다.[3]
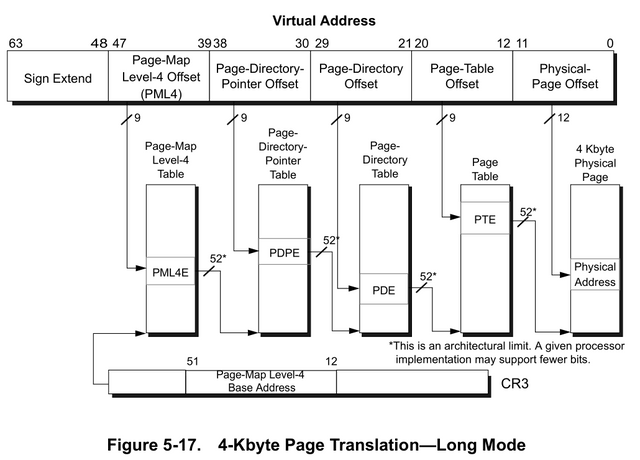
그런데 여기서 Sign Extend는 무엇일까?
x86의 64비트 모드에서 PML4로 동작하는 OS 커널은 메모리 참조를 위해 총 48비트를 사용한다. 이때 Bit 47이 0으로 설정되면 Bit 63-48이 0으로 설정되고, Bit 47이 1로 설정되면 Bit 63-48은 1로 설정된다. 이것을 Sign Extend라 부른다.
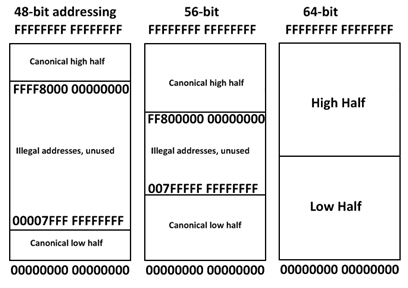
현대 OS는 Sign Extend를 커널 메모리 주소와 유저 메모리 주소를 구분하기 위해 사용한다. 만약 Bit 63-47이 1이라면, 그 주소는 커널 메모리 주소이다. 0이라면, 그 주소는 유저 메모리 주소이다. 이 개념을 High-memory, Low-memory라 부르기도 하니, 알아두면 좋을 것이다.
그리고 이 기법은 각 주소 공간의 최대 메모리 크기를 각각 128TiB로 제한한다. 이 때문에 64비트 x86 프로세서가 사용할 수 있는 최대 메모리 크기가 16EiB가 아닌, 256TiB인 것이기도 하다. 만약 더 큰 메모리 공간이 필요하다면 PML5 이상의 table walk가 필요할 것이다. (사실 Linux Kernel 5.5부터는 PML5가 기본값이다)
다시 본론으로 돌아가, 실제로 Page walking이 일어나는 방식에 대해 리눅스 커널을 참고하여 알아보자.
메모리 접근이 일어나면, 가장 먼저 CR3 레지스터를 참조하여 해당 프로세스의 페이지 테이블 엔트리에 접근한다. 이 때, CR3의 [63:52]는 0이며, [51:12]는 Page Global Directory (또는 PML4) 주소이다. 이 [51:12]의 40비트와 가상 주소의 [47:39]를 더하면 PUD(Page Upper Directory) Entry를 찾을 수 있고, 그 주소에 가상 주소의 [38:30]을 더하면 PMD(Page Middle Directory) Entry를 찾을 수 있고... 를 계속 반복하여 마지막 12비트(2^12Byte = 4KiB)가 실제 참조하고자 하는 데이터를 담고 있는 페이지에서의 오프셋이 된다.
이런 Page Walking 메커니즘의 특성 상, CR3 값은 프로세스간 전환(Context Switching)이 일어날 때마다 함께 바뀌어야 하며, CR3 값은 해당 프로세스의 컨텍스트에 포함된다.
Table Lookaside Buffer
PML4에서 개별 페이지를 참조하려면 총 4단계의 주소 변환과 각 단계마다 메모리 접근이 필요하다. 1회의 메인 메모리 접근은 약 100 cycle을 소비하기 때문에, 메모리 주소 변환에만 400 cycle이 낭비된다는 것을 의미한다. 만약 메모리 접근 시 매번 주소 변환을 수행해야 한다면 엄청난 CPU 사이클이 낭비될 것이다. 이 문제를 해결하기 위해 Table Lookaside Buffer (이하 TLB)가 도입되었다.
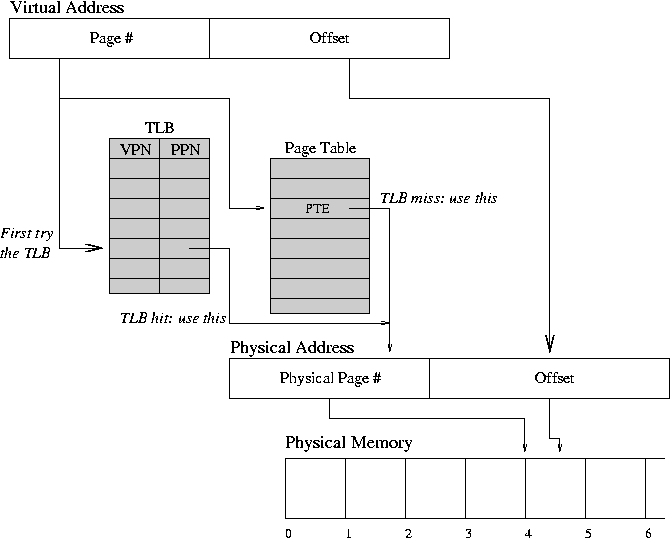
간단히 말해, 가상 메모리 주소의 [47:12]를 태그로 삼아, 주소 변환이 완료된 값(Physical Page Number)을 캐시에 저장하는 것으로 동일 페이지에 다시 접근할 때 주소 변환을 다시 수행할 필요가 없어졌다.
그런데 개별 프로세스마다 CR3가 달라야 한다면, 프로세스간 전환이 일어날 때 잘못된 주소 참조를 막기 위해 TLB 또한 비워져야 하지 않을까?
그래서 컴퓨터 공학자들은 ASID(Address Space Identifier, 인텔에서는 PCID라고 부른다)를 테이블에 추가하여, CR3가 바뀌더라도 TLB를 비울 필요가 없게 만들었다.
x86의 경우 PCID의 크기는 12비트이며, 운영체제는 최대 4096개의 프로세스를 TLB Flush 없이 유지할 수 있다.
메모리 가상화
가상 메모리와 페이징 기법 그리고 TLB를 이해했다면, 이제 메모리 가상화를 이해하기 위한 밑 준비가 끝난 것이다.
지금까지 이 시리즈의 포스팅을 모두 읽었다면, 다음에 따라올 질문 또한 예상이 될 것이다.
가상화 환경에서 이 기술들을 어떻게 구현할 수 있을까?
지금까지 이야기 해 온 기술들은 모두 OS의 커널이 직접 물리 메모리/CPU와 상호작용 한다는 전제를 가지고 있다. 하지만 서버 가상화 환경에서 하드웨어와 직접 상호작용 하는 것은 하이퍼바이저이고, 하이퍼바이저는 이 가상 메모리 구조와 페이지 테이블 Walking 메커니즘을 가상화하여 게스트 OS에게 보여줄 책임을 가진다.
어떻게 이게 가능한 것일까? 본론에 들어가기에 앞서, 하이퍼바이저가 추가된 메모리 참조 구조를 짚고 넘어가겠다.
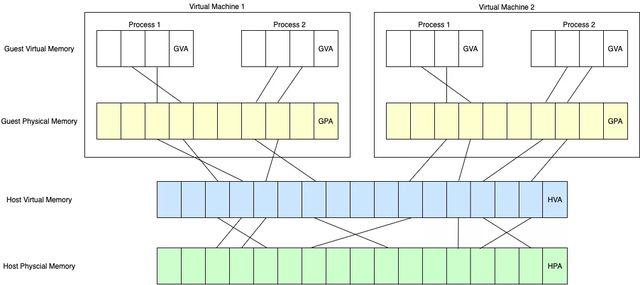
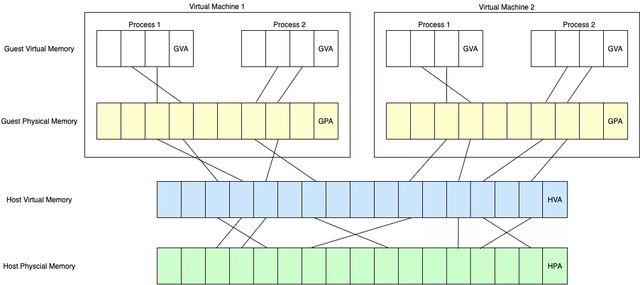
이제 메모리 참조 구조는 Host와 Guest를 구분한다.
Host Physical Address (HPA, 또는 Machine Address)가 실제 물리 메모리의 주소이고, Host Virtual Address(HVA)는 하이퍼바이저의 가상 메모리 주소이다. 가상 머신 내부의 메모리 주소는 Guest Physical Address(GPA), Guest Virtual Address(GVA)로 구분된다.
이 구조에서 기존의 CR3 참조만으로는 GVA를 HPA로 변환할 수 없다. CR3가 더 이상 물리 메모리 주소를 직접 참조할 수 없기 때문이다.
하이퍼바이저는 이 문제를 어떻게 타개했을까?
Shadow Page Table
초기 하이퍼바이저는 Shadow Page Table을 도입하는 것으로 이 문제를 해결하였다.
아이디어는 간단하다. CR3의 Page Global Directory를 실제 Page Table이 아닌, 하이퍼바이저가 관리하는 Shadow Page Table로 바꿔치는 것이다. 이렇게 하면 MMU가 Shadow Page Table을 walk하여 HPA를 가져오게 된다.
이 기법의 단점은 오버헤드가 크다는 것이다. 가장 먼저, 하이퍼바이저는 VM 내부에서 실행되는 프로세스마다 하나의 페이지 테이블을 유지해야 한다. 실행되는 VM과 프로세스가 늘어날수록 페이지 테이블을 저장하고 관리하는 오버헤드가 점점 더 커지는 것이다.
또한 하이퍼바이저는 게스트 OS가 바라보는 페이지 테이블 구조를 쉐도우 페이지 테이블과 항상 동기화 할 책임을 가진다. 이는 게스트 OS가 페이지 테이블 엔트리를 변경할 때마다, 하이퍼바이저가 해당 동작을 캐치하고 Shadow page table을 업데이트 해야 한다는 것을 의미한다. 이 동작은 페이지 테이블 엔트리에 쓰기 금지 보호를 걸어두는 것으로 구현할 수 있다.
만약 게스트 OS가 페이지 테이블 엔트리를 고치려고 하면, 액세스 위반 예외가 발생하고, VMM이 이것을 캐치한 다음 Shadow page table을 업데이트 하고 제어를 VM에 반환한다.
여기서 발생하는 오버헤드를 그나마 줄이기 위해 가상 TLB 방식이 제안되었다.
Shadow page table은 그대로 유지하되, table entry 업데이트는 게스트 OS가 자유롭게 수행할 수 있게 한다.
만약 페이지 테이블의 주소 매핑이 변경되면, TLB를 업데이트 하기 위한 특권 명령이 트리거되고 VMM은 그것을 캐치하여 Shadow page table을 동기화한다.
Intel EPT (Extended Page Table)
Shadow Page Table의 오버헤드를 근본적으로 제거하기 위해, 하드웨어 기반의 페이지 테이블이 등장하였다.
이것을 EPT(Extended Page Table)이라 하며, AMD에서는 NPT(Nested Page Table)이라 부른다.
기본 아이디어는 'VMM 대신 CPU가 Guest Walkthrough를 수행하게 하자' 이며, VM Exit와 컨텍스트 스위칭을 최소화 하는 것을 목표로 하였다.
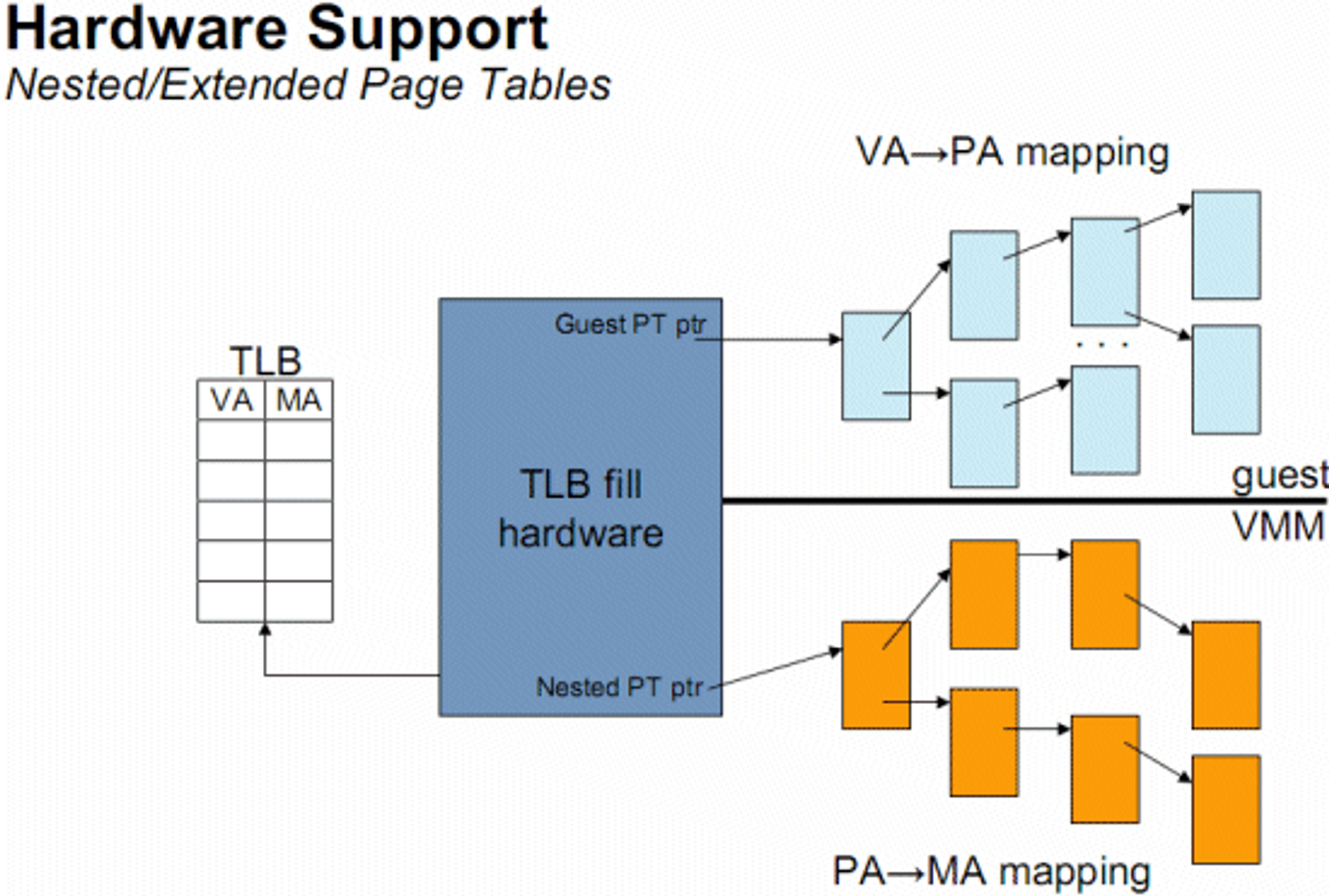
EPT를 활성화 하게 되면, 이제 모든 메모리 접근은 하이퍼바이저가 관리하는 EPT를 참조한다.
Page Walking의 매 단계마다 EPT를 참조하여 다음 엔트리의 주소를 알아내게 되나, 이 모든 작업을 하이퍼바이저가 아닌 MMU가 수행해 준다는 것이 다르다.
하이퍼바이저는 EPT 엔트리만 관리하면 되며, 더 이상 VM의 개별 프로세스마다 Shadow page table을 유지할 필요도 없어진다.
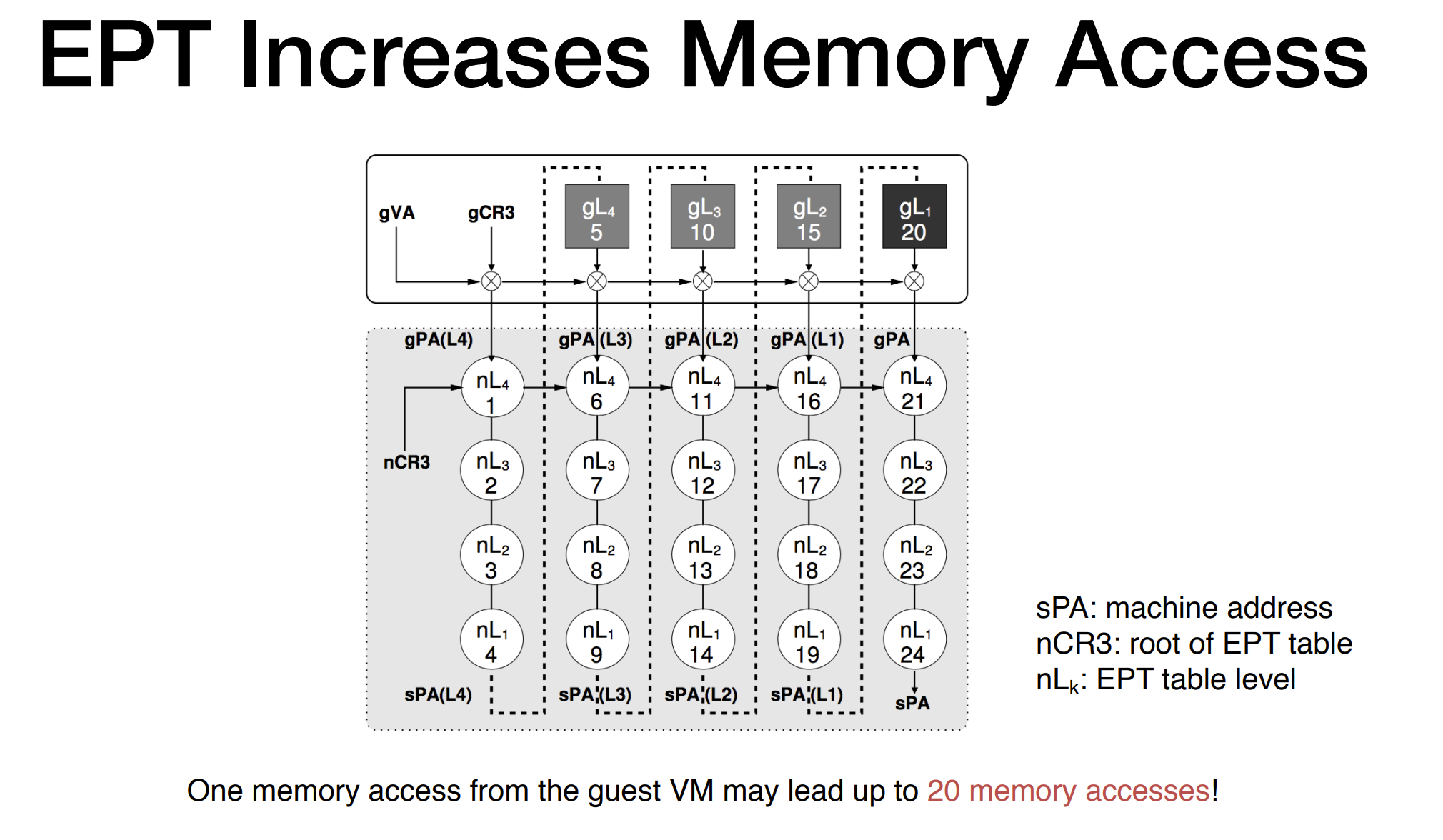
하지만 EPT가 장점만 가지고 있는 것은 아니다. TLB miss 시 4번의 메모리 접근이면 충분했던 비 가상화 환경과는 달리, EPT를 활성화하게 되면 한번의 메모리 접근에 최대 24회의 실제 메모리 접근이 필요할 수 있다.[4]
이것은 다시 말해 TLB Flush의 코스트가 훨씬 커진다는 것을 의미한다. EPT의 오버헤드를 최소화하려면, TLB Flush를 최소화해야 한다.
VPID (Virtual Process Identifier)
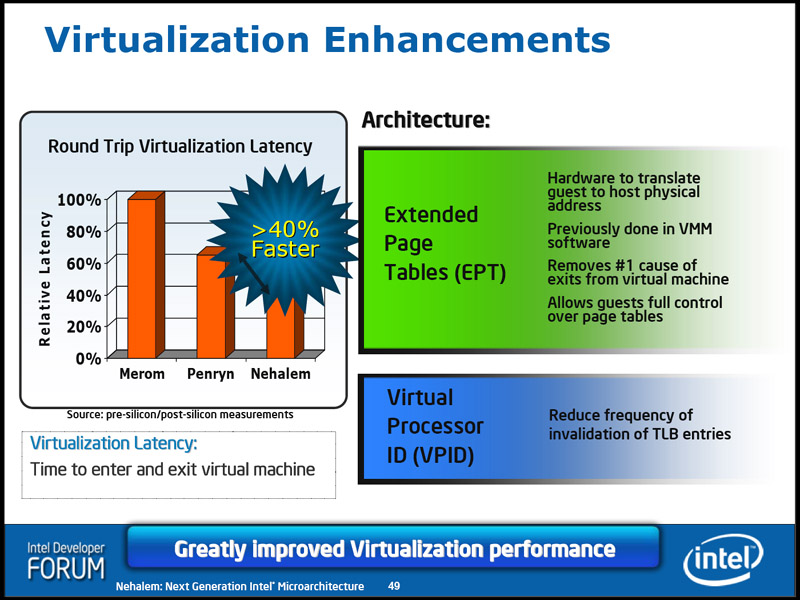
이 점 때문에 인텔은 네할렘 아키텍처에서 EPT와 함께 VPID를 추가하였다.
VPID는 TLB Entry에 추가되는 16비트 식별자로, 개별 가상 머신의 TLB 엔트리를 식별하기 위한 목적으로 동작한다. VMX가 활성화되지 않으면 VPID는 항상 0으로 설정되나, VMX 활성화 시 0번은 VMM이, 1-65535는 VM이 사용한다.
이렇게 VPID와 PCID를 조합하는 것으로, VMM은 VM 전환 시 TLB Flush 없이도 개별 프로세스의 TLB Entry의 일관성을 유지할 수 있게 되었다.
한편, VPID는 Shadow page table에도 적용할 수 있는데, Shadow page table에 VPID를 적용할 경우 성능 향상이 얼마나 되는지는 알려져 있지 않은 것으로 보인다. 만약 추가로 데이터를 확보한다면 업데이트 하도록 하겠다.
What's Next?
이것으로 서버 가상화에서의 메모리 가상화 기법에 대한 설명을 마친다. 다음 포스팅에서는 I/O 가상화를 다룰 것이다.
또한, 향후 ESXi에서의 PML5 지원과 2MB Hugepage에 대한 내용을 업데이트 할 예정이다.
레퍼런스
[1] https://ethw.org/Milestones:Atlas_Computer_and_the_Invention_of_Virtual_Memory,_1957-1962
[2] https://dl.acm.org/doi/abs/10.5555/1074100.1074903
[3] https://connormcgarr.github.io/paging/
[4] https://cseweb.ucsd.edu/~yiying/cse291j-winter20/reading/Virtualize-Memory.pdf

잘 보고 있습니다. 어떻게 이렇게 다양한 소스를 엮어서 글을 구성하셨는지 궁금할 따름입니다