
들어가며
현재 컴퓨팅 아키텍처의 발전을 이끄는 것은 데이터의 폭증이다. CPU와 스토리지, 그리고 네트워크의 속도 증가율은 감소한 반면, 데이터는 앞으로도 기하급수적으로 증가할 것으로 예상된다.
인텔을 위시한 마켓 플레이어들은 2010년대 초에 이러한 상황을 예측하고 대응에 들어갔다. 그렇게 등장한 것이 바로 데이터 중심 컴퓨팅(Data Centric Computing)이다.
데이터 중심 컴퓨팅이란, 기존의 애플리케이션 중심 컴퓨팅에서 벗어나 폭증하는 데이터를 '어떻게' 처리할 것인지에 초점을 맞추어 컴퓨팅 기술을 개발해야 한다는 생각이다. 이러한 아이디어는 특히 많은 비정형 데이터를 생산 및 소비하는 IoT/AI 워크로드에 적합한 접근 방식이었고, 기계 생산 데이터의 폭증에 따라서 자연스럽게 시장에 받아들여지게 된다.
특히 인텔은 Memory Centric Computing을 주창하며 Optane DCPM을 활용한 새로운 메모리 계층 구조를 제안했으나, 규모의 경제를 달성하지 못해 실패하였다.
한편, HPE는 정체된 무어의 법칙을 타파하기 위한 목적으로 Memory Centric Computing을 기치로 내건 'The Machine' 이니셔티브를 만들었으나, 2018년 이후로 추가적인 연구나 움직임은 나타나지 않았다. Memristor Architecture에 대한 근황(?)은 여기에서 확인할 수 있다.
이러한 새로운 시도들이 나타나고 좌절되는 가운데, 당면 과제를 이미 존재하는 클라우드를 통해 처리하고자 하는 움직임이 주류가 되었고, 곧 화두는 '데이터센터의 효율적인 활용'으로 넘어가게 된다.
이 시점에서 우리가 마주하게 된 질문은 다음과 같다.
- 데이터를 어떻게 처리할 것인가?
- 데이터를 어떻게 저장할 것인가?
- 데이터를 어떻게 전송할 것인가?
지금부터 각 질문에 대한 컴퓨팅 업계의 해답을 찾아볼 것이다.
CPU의 성능 향상
앞서, CPU의 성능 향상 속도가 데이터의 증가를 따라가지 못한다고 언급했었다.
이 언급을 뒷받침하기 위한 자료로 Karl Rupp의 '42 Years of Microprocessor Trend Data'를 발췌하겠다.
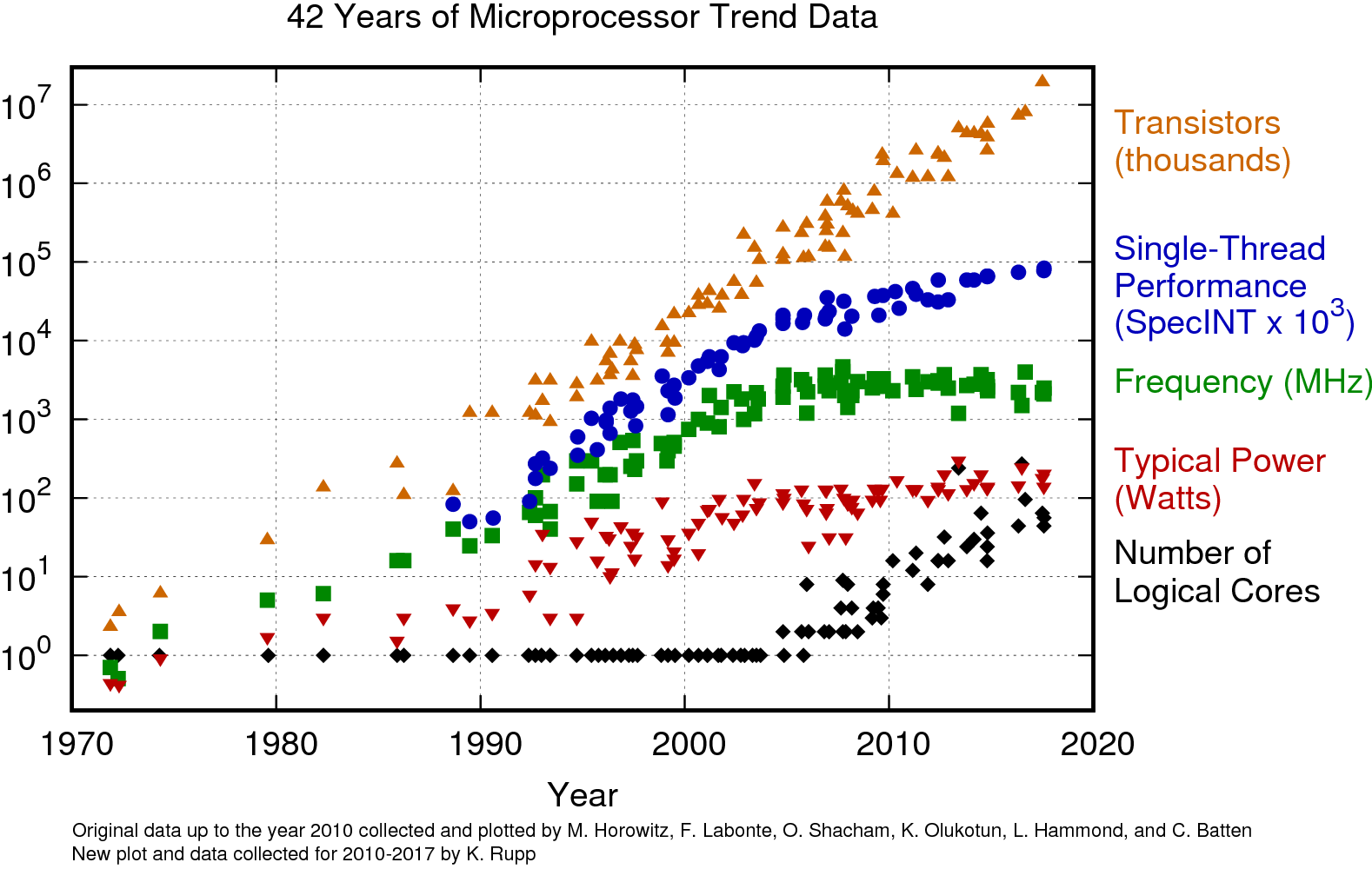
[그림 1. 42년간 마이크로프로세서의 발전 추세]
위 그래프를 보면 트랜지스터 수는 지속적으로 기하급수적인 증가를 보이고 있으나, 그 증가 추세는 2000년대부터 느려졌음을 알 수 있다. 싱글 쓰레드 성능은 2000년대 중반까지 기하급수적으로 증가하다 둔화되었고, 주파수 증가 추세 또한 마찬가지임을 알 수 있다.
반면, 코어 갯수는 2000년대 후반을 기점으로 기하급수적인 증가를 보인다. 즉, 2000년대 후반을 기점으로 하여 트랜지스터의 증가는 코어 갯수의 증가로 이어진 것임을 알 수 있다.
왜 이런 일들이 일어난 것일까? 왜 우리는 멀티코어 컴퓨팅으로 나아가야만 했던 것일까?
Dennard Scaling
Robert H. Dennard는 1974년에 발표된 논문에서 '모스팻의 다운사이징에 따른 성능 향상'을 이야기하였다. 간단히 정리하자면, 트랜지스터의 크기가 30% 감소할 때마다, 트랜지스터의 면적은 50% 감소하고, 트랜지스터가 소비하는 전력도 50% 감소하여, 동일한 공간에 2배의 트랜지스터를 넣으면서도 전력 소모는 동일하게 유지할 수 있다. 이 때 동작 속도는 40%가 증가한다는 가설이다. Dennard Scaling은 무어의 법칙을 실현하는데 있어 큰 영향을 끼쳤다.
실제로 Dennard Scaling은 상대적으로 긴 시간 동안 잘 동작했고, 그 동안 컴퓨팅 업계는 공짜 점심(Free Lunch)의 혜택을 누릴 수 있었다.
소프트웨어 관점에서 아무런 노력을 기울이지 않아도, 컴퓨터의 동작 속도는 Dennard Scaling에 따라서 저절로 증가하고, 세대가 지남에 따라 기하급수적인 성능 향상의 혜택을 볼 수 있었던 것이다.
하지만, 반도체 공정의 미세화 수준이 90nm에 이르자, 급격한 누설전류의 증가로 인해 Dennard Scaling은 붕괴한다.
이에 대하여 2004년에 멀티코어 프로그래밍의 필요성을 역설한 Herb Sutter의 글이 있다.
업계 전반적으로는 약 2005-2007년 사이에 Dennard Scaling이 완전히 붕괴했다는 인식이 존재한다. 더 이상 반도체 미세화에 따른 성능 향상이 공짜가 아니게 된 것이다.
폴락의 법칙 (Pollack's Rule)
폴락의 법칙은 인텔의 Fred Pollack의 이름을 따서 명명된 법칙으로, '마이크로 아키텍처의 발전으로 인한 성능 향상은 복잡성 증가의 제곱근에 비례한다'는 경험칙이다. 쉽게 풀어서 설명하자면, 두 배로 증가한 트랜지스터를 마이크로 아키텍처 개선에 투자하여, 복잡도를 두 배로 높이면 성능이 약 41% 향상된다는 내용을 담고 있다.
폴락의 법칙과 Dennard Scaling의 동작 속도 향상(세대당 40%)을 결합하면, 한 세대가 지날 때마다 약 두 배(97.4%)의 성능 향상을 달성할 수 있고, 이것은 곧 무어의 법칙을 지속적으로 실현할 수 있는 원동력이 되었다.
하지만, Dennard Scaling이 무너지면서 마이크로 아키텍처의 복잡성(=단일 코어의 복잡성)을 높게 가져가는 것으로는 무어의 법칙을 실현할 수 없게 되었을 뿐만 아니라, 기존의 방식을 유지하기에는 전력 효율성도 함께 발목을 잡게 된다.
동일한 수의 트랜지스터를 투입하여 더 높은 성능 향상을 가져올 수 있는 멀티코어로의 전환이 필요한 시점이 된 것이다.
이것이 바로 2005년, 테자스가 취소되고, 펜티엄 D가 시장에 등장하게 된 계기이다.
다크 실리콘 문제
Dennard Scaling의 붕괴는 반도체 업계에 새로운 도전을 가져왔다. 트랜지스터는 계속해서 작아지지만, 전력 소모가 그에 맞춰 줄어들지 않는다면, 트랜지스터의 수가 늘어날 때 개별 트랜지스터에 공급할 수 있는 전력의 양은 줄어들 수 밖에 없다. 이것이 바로 다크 실리콘 문제이다.
이 문제에 대응하기 위한 방법으로 크게 두 가지 접근법이 시도되었다. 하나는 개별 트랜지스터의 동작 전력을 줄이는 것이다. Dennard Scaling이 붕괴했더라도 추가적인 노력을 투입하여 동일한 효과를 가져올 수 있다면 무어의 법칙은 계속해서 유지될 수 있다. 이러한 노력의 결과물이 High-K - FinFet - GAA로 이어지는 트랜지스터 구조의 혁신이다.
다른 하나는 칩셋에서 '동시에 동작하는 영역'을 줄이는 것이다. 칩셋의 모든 영역에 만족할 만한 수준의 전력을 공급해 줄 수 없다면, 한 시점에 특정 영역만을 활성화하여 전력 요구 조건을 충족시키는 것이다. 이러한 어프로치는 싱글코어에서는 적용하기 어려운 방식이었으나, 멀티코어 시대가 도래하면서 본격적으로 발전하기 시작한다. 최초에는 개별 코어의 클럭을 제어할 수 있었으나, 현재는 Uncore 영역을 포함한 전체 패키지에 대한 전력 제어와, 100us tick의 전원 레벨 제어 기능이 구현되어 있다.
사실 다크 실리콘 문제는 데스크탑 컴퓨팅보다 모바일 컴퓨팅에서 먼저 두각을 드러내기 시작하였는데, 이는 모바일 장치의 전력 제한이 데스크탑에 비해 훨씬 심하기 때문이다. 이 문제에 대응하기 위해 ARM 진영은 선도적으로 빅-리틀 구조를 도입하였고, 전력 효율적인 스케줄링 기술을 발전시켰다.
열밀도 문제
사실 x86 업계에서 전력 소모량보다 더 큰 문제가 되었던 것이 바로 열밀도 문제이다. 트랜지스터의 전력 소모가 감소하지 않은 채로 밀도만 두배로 늘어난다면, 단위 면적당 발열량도 두배로 늘어나고 마는 것이다.
혹자는 방열판의 크기를 키우면 되지 않냐고 하지만, 실리콘이 직접 방열판과 맞닿아있는 것이 아닐 뿐더러, 다이와 히트 스프레더 그리고 방열판 사이의 열 전도 시간이 존재하기 때문에 무작정 방열판의 크기를 키우는 것이 정답은 아니다. 특히 서버 환경이 아닌 데스크탑 환경에서는 CFM을 높이기도 힘들고, 차가운 공기를 지속적으로 공급하는 것도 힘들기 때문에 더욱 큰 문제가 되었다.
이러한 문제를 핸들링하기 위해서 등장한 개념이 바로 TDP(Thermal Design Power, 열설계전력)이다.
컴퓨터 시스템의 냉각 성능을 미리 산정하고, 지속적인 냉각이 가능할 수준으로만 전체 전력 소모를 유지한다는 개념이 등장한 것이다.
이제 전체 코어는 항상 최대 속도로 동작하지 않으며, 열설계전력에 기반하여 단위 시간당 최대 속도로 동작할 수 있는 타임 슬롯을 갖는다. 워크로드의 종류가 다양하고, 모든 워크로드가 항상 최대 성능으로 동작하는 것은 아니기 때문에 시스템의 스루풋을 떨어뜨리지 않으면서도 전력을 보다 효율적으로 사용할 수 있는 기회를 갖게 된다. 인텔에서는 RAPL(Running Average Power Limit)을 통해 이것을 구현하는데, 이 글의 주제를 벗어나기 때문에 RAPL에 대한 자세한 내용을 여기서 다루지는 않겠다. 만약 관심이 있다면 위 링크를 참조하길 바란다.
정리
CPU의 성능 향상에 초점을 맞추어 위 내용을 정리하면 다음과 같은 그림이 나온다.
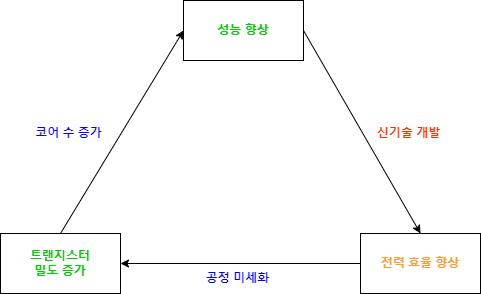
[그림 2. CPU의 성능 향상 도식]
반도체 공정이 미세화되면 트랜지스터의 밀도가 증가하고, 이것은 곧 코어 수의 증가로 이어져 성능이 향상된다.
하지만 Dennard Scaling의 붕괴 이후, 반도체 공정의 미세화가 곧 전력 효율의 향상으로 이어지지는 않기 때문에 추가적인 신기술 개발이 필요하며, 이러한 신기술 개발의 사이클이 반드시 공정 미세화 사이클과 일치하는 것은 아니게 되었다.
더 많은 코어가 더 많은 전력을 소모한다는 것은 곧 전성비가 나빠진다는 것이고, 폭증하는 데이터를 보다 '효율적으로' 처리할 방법이 필요하게 되었다.
GPGPU와 헤테로지니어스 컴퓨팅
무어의 법칙이 둔화되고, 전력 소모 관점에서의 제약이 커지자 컴퓨팅 업계는 다른 쪽으로 눈을 돌리기 시작한다.
바로 대규모 병렬 처리에 특화된 GPU를 활용하여 대용량 연산을 오프로딩하고, CPU는 GPU가 처리하지 못하는 워크로드를 처리하자는 것이다. 이제 헤테로지니어스 컴퓨팅이 대세로 떠오르기 시작한다.
GPGPU와 CUDA의 역사
사실 헤테로지니어스 컴퓨팅이라는 개념이 완전히 새로운 것은 아니다. 작게는 i487SX Math Co-Processor부터, 한 시대를 풍미한 SGI의 벡터 프로세싱 유닛까지, 특정 연산에 특화된 연산 장치가 범용 프로세서보다 더 높은 효율을 보인다는 것은 널리 알려져 있었고, 특히 그래픽 프로세싱과 슈퍼컴퓨팅 분야에서 널리 사용되어 왔다. 그럼에도 불구하고 GPGPU가 현재 각광을 받고 있는 것은 GPGPU만의 장점이 있기 때문이다, 이를 이해하기 위해 먼저 간단하게 GPGPU의 역사를 알아보겠다.
가장 먼저, 2000년대 초에 GPU의 잠재력을 알아본 몇몇 얼리 어답터들이 GPU의 프로그래머블 쉐이더를 exploit하여 병렬 처리 프로그램을 동작시키는 트릭을 제안한다.
이것은 곧 스탠포드의 BrookGPU 프로잭트로 이어졌고, 2006년 NVIDIA가 CUDA를 발표하면서 GPGPU의 시대를 열게 된다.
GPGPU의 가장 큰 특징은 '병렬 행렬 연산'에 최적화되었다는 것이다. GPU는 모니터에 표시되는 수많은 픽셀을 실시간으로 처리하기 위한 목적으로 개발되었고, 3D 연산을 위한 벡터 프로세싱에 최적화된 구조를 가지게 되었다.
그러나 우연찮게도 이러한 구조는 대규모 과학 연산을 비롯한 HPC 워크로드에 최적화되어 있었고, CUDA가 등장하자 자연스럽게 HPC 워크로드를 GPU를 활용해 병렬로 처리하려는 움직임들이 나타나기 시작한다.
그리고 엔비디아의 소프트웨어 생태계 지원에 힘입어, CUDA 에코시스템은 그야말로 대박을 친다. CUDA 프로그래밍만 배우면 누구나 개인용 슈퍼컴퓨터라고 할 만한 정도의 연산 성능을 활용할 수 있게 된 것이다. 물론 전통적인 슈퍼컴퓨터들 또한 GPU를 빠르게 받아들였고, 2018년 시점에는 TOP500에서 GPU로 인한 연산 성능의 증가가 과반을 넘어서게 된다.
여기에 더해, 2011년에 일어난 딥 러닝 기술과 NVIDIA CUDA의 결합은 놀라운 시너지 효과를 내면서 컴퓨팅 혁신을 이끌었다.
이것은 순전히 인공 신경망의 구조가 다차원 행렬 연산으로 표현되었기 때문에 가능했던 일인데, 역으로 GPU의 연산 성능 향상이 인공 신경망을 실제로 활용하기 위한 토대가 되었다고도 볼 수 있을 것이다.
결론적으로, 적어도 지금까지는 CPU+GPU 구조의 헤테로지니어스 컴퓨팅이 지난 10여년 간 컴퓨팅 파워의 증가를 이끌어 온 것으로 보인다.
그렇다면, 그 다음에는 무엇이 올 것인가?
FPGA의 대두
GPGPU는 몇 가지 한계점을 가지고 있다
- GPU의 가격이 비싸기 때문에 범용적으로 사용하기 어렵다
- GPU는 대규모 행렬 연산에 최적화되어 있다
- 전용 가속기에 비해 전력 효율성이 떨어진다
SmartNIC
컴퓨터 아키텍처에서 가장 먼저 다른 대안이 필요하게 되었던 영역은 바로 네트워킹이다.
x86 서버에서 네트워크 패킷 프로세싱은 그 특성 상 CPU로 처리되어 왔는데, 향후 800G 이상으로 확장되는 네트워크 대역폭 대비 CPU 성능 향상은 그에 미치지 못하기 때문이다.

[그림 3. CPU와 네트워크 대역폭 사이 성능 갭]
더 큰 문제점은, 이러한 네트워크 트래픽을 CPU로 처리하기 위해 필요한 CPU Cycle이 점점 더 많아지고 있다는 것이다. CPU는 단위 성능당 비용이 가장 비싼 컴포넌트인데, 그러한 CPU의 Cycle을 애플리케이션 대신 네트워크 트래픽 처리를 위해 사용한다는 것은 상당한 낭비로 여겨질 수 밖에 없다.
이제 CPU의 역할을 대신할 새로운 대안인 SmartNIC이 필요한 시기가 된 것이다.
SmartNIC은 프로그래밍 된 연산을 수행할 수 있는 FPGA 기반의 NIC으로, 본래 HFT(High Frequency Trading) 시스템에서 사용되었던 물건이다. Multi-hundred Gigabit 시대를 맞이하여 SmartNIC은 패킷 처리를 Line-rate로 수행할 수 있다는 특성을 살려 대용량 데이터 처리가 필요한 응용에 우선적으로 투입되고 있다. 대표적인 응용으로는 5G Core와 URLLC가 있으며, VMware도 NSX의 기능을 SmartNIC에 통합하는 작업을 진행하고 있다.
향후 고속 네트워크가 보급되면서 SmartNIC의 응용 범위도 계속 확장될 것으로 예상된다.
Computational Storage
그 다음으로 FPGA가 대두되고 있는 영역은 Computational Storage이다.
저장할 데이터가 늘어난다는 것은 곧 그 데이터를 처리하기 위해 필요한 대역폭도 증가한다는 것을 의미한다.
최근 들어 빠른 속도로 개발되고 있긴 하지만, PCI Express 표준은 7년간 3.0에 머물러 있었고, 4.0 이상으로 넘어오면서 신호 열화 문제와 간섭 문제가 심화되는 등, 한계에 가까워지고 있으며 이러한 문제를 해결하기 위해 적용된 Retimer 등의 솔루션은 전체 플랫폼의 비용 증가로 이어지고 있다.
Computational Storage를 활용하면 전체 데이터를 메모리로 전송하는 대신, 전처리를 거친 데이터를 메모리로 전송하는 등의 최적화를 통해 필요 대역폭을 줄일 수 있으며, 디스크 갯수 만큼의 병렬적인 확장이 가능하기 때문에 CPU의 연산을 보조하여 수평적으로 확장 가능한 추가 연산 성능을 얻을 수 있다. 이러한 장점은 특히 엣지 환경에서 두드러지는데, 엣지 환경에서는 강력한 컴퓨팅 파워를 활용하기가 어려울 뿐만 아니라 네트워크를 통한 트래픽 전송 비용 또한 비싸기 때문이다.
현재 NVMe Consortium에서 NVMe 기반 Computational Storage의 인터페이스를 표준화하기 위한 작업이 진행 중이며, 아마도 eBPF로 작성된 프로그램을 동적으로 로드하여 사용하는 방향으로 발전할 것으로 보인다.
다만, FPGA가 Computational Storage를 구현하기 위한 유일한 방법이 아님에 유의해야 한다. 자세한 내용은 조만간 다시 다룰 일이 있을 것으로 생각한다.
AI 가속기 (AI Accelerator)
한편, 인공 신경망 기반 AI의 확산은 새로운 유형의 칩을 탄생시켰다. AI 연산에 특화된 ASIC인 AI Accelerator가 바로 그것이다.
AI Accelerator는 2016년, Google의 TPU 기반으로 구동된 AlphaGo가 이세돌을 꺾으면서 본격적인 하이라이트를 받기 시작했으며, GPU보다 전력 효율적이면서 동일 칩 면적에서 보다 높은 성능을 낼 수 있다는 특성을 살려 AI 워크로드를 오프로딩하기 위한 목적으로 쓰이고 있다.
현재 대부분의 스마트폰 칩셋 제조사들이 자사의 AP에 AI 워크로드 가속을 위한 AI Accelerator를 내장하고 있으며, Tesla 또한 자율 주행 플랫폼을 위한 Dojo를 선보이는 등, 요 2년 새 가장 각광받은 반도체 유형이라고 말할 수 있을 것이다.
사용자 관점에서 AI Accelerator의 가장 큰 단점은 기존의 CUDA Ecosystem을 활용할 수 없다는 것이다. 향후 AI Accelerator에 시장 지배적인 플레이어가 나타나기 전까지는 AI 영역에서 NVIDIA의 독주가 계속될 가능성이 크다.
Post Heterogeneous Computing
여기까지 컴퓨팅 성능의 향상을 위해 업계가 걸어온 발자취를 살펴 보았다.
Dennard Scaling의 붕괴 이후, 컴퓨터 업계는 기하급수적으로 증가하는 데이터를 처리하기 위해 커다란 아키텍처의 변화를 겪었다.
가장 먼저, 멀티코어로의 전환이 있었으며 약 20년의 시간이 지난 끝에 거의 한계점에 도달한 것으로 보인다. 가장 큰 원인은 전력 소모의 증가이기 때문에, 데이터센터의 전력 수용량이 늘어나고, 냉각 시스템이 강화되는 등의 보완이 이루어지면 아직 몇 년은 더 지속될 수 있을 것이다.
하지만 암달의 법칙은 코어 갯수를 늘리는 것도 조만간 한계에 봉착할 것이라고 말하고 있다.
우리는 지금 그 다음의 아키텍처 변화를 목전에 두고 있다. FPGA가 점점 범용 워크로드의 영역으로 넘어오고 있으며, 특수목적용 반도체가 ASIC으로 찍혀서 나오는 일이 당연시되기 시작했다.
FPGA 업계도 이러한 흐름에 발맞추어 프로그래밍 편의성이 개선된 개발 플랫폼을 출시했으며, FPGA 프로그래밍의 진입 장벽이 점점 낮아지고 있다.
다만, FPGA는 생산 단가를 떨어뜨리기가 쉽지 않으며, 전파 지연 문제로 인해 동작 클럭 속도를 높이기가 어렵기 때문에 성능을 높이기 위해서는 병렬 처리 디자인이 사실상 강제된다는 특성을 가지고 있다.
앞으로 10년간은 FPGA와 ASIC이 서로의 영역을 침범하면서 발전해 나가는 구도가 나타날 것으로 예상한다. 만약 FPGA의 프로그래밍이 충분히 쉬워지고 애플리케이션에 잦은 변경이 필요하다면 FPGA가 최종 승자가 될 것이고, 제한된 영역의 애플리케이션이 오프로딩되고, ASIC 기반의 빌딩 블록을 조합하여 원하는 기능을 충분히 구현할 수 있게 된다면 ASIC이 최종 승자가 될 것이다.
그러나, 우리는 아직 하나의 질문을 남겨놓고 있다.
"헤테로지니어스 컴퓨팅 다음에는 어떤 변화가 올 것인가?"
앞으로의 10년은 헤테로지니어스 컴퓨팅의 발전을 누리는 동시에, 이 질문에 대한 답을 찾는 시간이 될 것이다.

무슨 말인지 완벽히 이해했습니다 … 🫠
다음 포스팅 마렵습니다.