크기가 너무 큰 문제는 계산, 메모리 효율적으로 풀어야한다. 현실적인 implementation을 위한 변형들에 대해 알아보자.
Inexact Newton method
Symmetric n×n linear system을 풀기 위한 Newton step pkN를 생각해보자.
∇2fkpkN=−∇fk(7.1)
이 section에서는 계산 효율적으로 pkN를 approximation 하는 방법에 대해 알아본다. 이는 위의 식을 CG 또는 Lanczos method (Hessian의 negative curvature를 다루기 위한 변형 버전)을 통해 푸는 것을 기반으로 한다. Line search, trust-region을 모두 다룰 것이다.
Local convergence of inexact Newton methods
(7.1)을 푸는 대부분의 iterative solver는 residual에 근거해서 종료를 결정한다. (Exact Newton step pkN의 경우 residual은 0일 것이다.)
rk=∇2fkpk+∇fk(7.2)
여기서 pk는 inexact Netwon step이다. 일반적으로, CG iteration은
∥rk∥≤ηk∥∇fk∥(7.3)
일때 종료하며, 여기서 sequence {ηk} (모든 k에 대해 0<ηk<1)을 forcing sequence라고 부른다. Forcing sequence의 선택이 어떻게 inexact Newton method의 convergence 속도에 영향을 미치는지 살펴보자.
Theorem 7.1
∇2f(x∗)가 PD인 minimizer x∗의 neighborhood에서 ∇2f(x)가 존재하며 continuous 하다고 가정하자. pk가 (7.3)을 만족시키고, 어떤 상수 η∈[0,1)에 대해 ηk≤η를 가정할 때, iteration xk+1=xk+pk을 생각해보자. 그러면, 만약 시작점 x0이 x∗에 충분히 가깝다면, sequence {xk}는 x∗로 수렴하며, η<η^<1인 임의의 상수 η^에 대해 다음을 만족한다.
∥∇2f(x∗)(xk+1−x∗)∥≤η^∥∇2f(x∗)(xk−x∗)∥
Hessian matrix ∇2f가 x∗에서 PD이고 x∗의 주위에서 continuous하므로, 모든 충분히 x∗에 가까운 xk에 대해 ∥(∇2fk)−1∥≤L을 만족시키는 양의 상수 L이 존재한다 (nonsingular matrix A에 대해서 I=A−1A이므로 ∥A−1∥≥(∥A∥)−1이므로). 따라서 우리는 (7.2)로부터 inexact Newton step이 다음을 만족한다는 것을 알 수 있다.
xk가 x∗에 충분히 가까울 때, o(1) term은 (1−η)/2로 bounded 된다.
∥∇fk+1∥≤(ηk+(1−η)/2)∥∇fk∥≤21+η∥∇fk∥(7.7)
따라서 gradient의 norm은 매 iteration마다 (1+η)/2 만큼 줄어들게 된다.
Theorem 7.1을 증명하기 위해, smoothness assumption 하에
∇fk=∇2f(x∗)(xk−x∗)+o(∥xk−x∗∥)
임을 주목하자. 따라서 xk가 x∗에 가까우면 ∇fk는 scaled error ∇2f(x∗)(xk−x∗)와 상대적으로 작은 perturbation 만큼밖에 차이나지 않는다. 이 결과를 (7.7)에 집어넣으면 Theorem 7.1이 증명된다.
(7.6)에 의해
∥∇fk∥∥∇fk+1∥≤ηk+o(1)
만약에 limk→∞ηk=0이 되도록 forcing sequence를 선택하면,
k→∞lim∥∇fk∥∥∇fk+1∥=0
즉, gradient norm이 0으로 Q-superlinearly converge한다. {xk}가 x∗로 superlinearly converge함도 이에 뒤따른다.
Rates of convergence
Q-superlinear convergence가 무슨 말인지 몰라서 appendix를 참조한다. Q는 quotient를 의미한다고 하고, 연속된 error의 비율을 이용하기 때문에 붙었다고 한다.
(Q-linear)
충분히 큰 모든 k에 대해, 다음을 만족시키는 상수 r∈(0,1)이 존재한다.
∥xk−x∗∥∥xk+1−x∗∥≤r
(Q-superlinear)
k→∞lim∥xk−>x∗∥∥xk+1−x∗∥=0
(General 하게)
Order of convergence q와 rate of convergence μ에 대해
k→∞lim∥xk−>x∗∥q∥xk+1−x∗∥=μ
q=1이면 linear convergence (여기서 μ∈(0,1)이면 Q-linear), q=2이면 quadratic convergence이다.
Hessian ∇2f(x)가 x∗의 주위에서 Lipschitz continuous 하다고 가정하면 quadratic convergence도 얻을 수 있다. 이 경우, (7.5)는
∇fk+1=rk+O(∥∇fk∥2)
가 될 수 있고, ηk=O(∥∇fk∥)로 forcing sequence를 고르면
∥∇fk+1∥=O(∥∇fk∥2)
가 되기 때문에, gradient norm이 0으로 Q-quadratic하게 converge한다 (so does xk to x∗)
Theorem 7.2
Theorem 7.1의 조건들이 만족하고, inexact Newton method로 생성된 {xk}가 x∗로 converge 한다 가정하자. 그렇다면, 만약 ηk→0일 경우 rate of convergence는 superlinear 한다. 추가로, ∇2f(x)가 x∗ 주위에서 Lipschitz continuous하고, ηk=O(∥∇fk∥)이면, convergence는 quadratic하다.
Line search Newton-CG method
Truncated Newton method라고도 한다. Newton equation (7.1)에 CG를 적용해서 search direction을 계산한다. 그리고 (7.3)의 termination test를 만족하는가 본다. 그런데 CG는 positive definite system을 풀려고 나왔는데, ∇2fk는 xk가 solution에 가깝지 않을 경우 negative eignevalue를 가질 수도 있다. 따라서 negative curvature를 가지는 direction이 생성되면 CG를 바로 종료한다. 이렇게 함으로써 pk가 descent direction이 되게 된다. 또한, 가능할 경우 항상 step length αk=1로 함으로써, pure Newton method의 빠른 convergence rate이 보장된다.
즉, Line search Newton-CG는 search direction pk를 계산하기위해 CG를 내부 iteration으로 사용하는 알고리즘이다. (7.1)을 다음과 같이 바꿔쓰고,
Bkp=−∇fk(7.9)
Search direction을 dj, CG가 생성하는 sequence를 zj라고 하자. Bk가 PD면, {zj}는 (7.9)의 Newton step pkN로 converge한다. 각 iteration마다 요구되는 정확도를 나타내는 tolerance ϵk를 정한다. Forcing sequence는 superlinear convergence rate을 얻기 위해 ηk=min(0.5,∥∇fk∥)로 정할 수 있고, 다른 선택지도 있다.
Line search Newton-CG에서의 CG part와 그냥 CG의 큰 차이는 1) 여기선 시작점 z0=0이 사용됨, 2) inexact solution에서 CG가 끝나도록 하는 tolerance ϵk의 사용, 3) pk가 descent direction이 되도록 보장해주는 negative curvature test djTBkdj≤0의 사용이다. 만약에 첫 inner iteration j=0에서 negative curvature가 감지되면, 출력되는 direction pk=−∇fk는 descent direction이면서 nonpositive curvature를 갖는다.
내부 CG iteration에 preconditiong을 도입할 수도 있다.
Line search Newton-CG는 큰 문제에 적합하지만 Hessian ∇2fk가 singular에 가까울 때, direction이 너무 길고 좋지 않아, line search에 필요한 계산이 많아지고 objective function의 reduction도 작다. 해결책으로 Newton step을 normalize 하거나 negative curvature test에 threshold를 도입하는 것을 생각해볼 수 있는데 구체적인 방법을 정하기 어렵다. 저자들 의견엔 그냥 이런 경우에는 밑에서 다룰 trust-region Newton-CG를 사용하는게 낫다고 말한다.
Line search Newton-CG에서는 Hessian Bk를 explicit하게 알 필요 없이 Hessian-vector product인 ∇2fkd만 계산할 수 있으면 되는데, Chapter 8에서 배우겠지만 Hessian을 저장하지 않고 계산하는 방식이 있다. 이를 Hessian-free Newton method라고 부른다.
Trust-region Newton-CG method
알고리즘을 만든 사람의 이름을 따서 CG-Steihaug 라고도 부른다. Trust-region subproblem을 풀 때 CG의 변형을 사용한다.
p∈Rnminmk(p)=fk+(∇fk)Tp+21pTBkp subject to ∥p∥≤Δk
dj는 변형된 CG iteration의 search direction이고, zj는 변형된 CG가 생성하는 sequence이다.
Loop안의 첫 if문은 현재의 search direction에 대한 negative curvature test이다. 두번째 if문은 trust-region bound를 위반했을 때 loop을 멈추는 역할이다. 두 경우 모두 현재의 search direction과 trust-region boundary의 intersection을 통해 step pk를 얻는다.
Tolerance ϵk의 선택이 trust-region Newton-CG의 비용을 적게 유지하는데 중요하다. Well-behaved solution x∗의 주위에서는 trust-region bound가 무시될 수 있을 것이고, trust-region Newton-CG는 Theorem 7.1과 7.2에서 다룬 inexact Newton method로 이해될 수 있을 것이다. 이런 경우 Line search Newton-CG와 비슷하게 ϵk를 고르면 빠른 convergence를 얻을 수 있다.
Pure CG와 CG-Steihaug에 사용된 CG의 주요 차이점은 후자는 1) trust region bound를 위반할 때, 2) direction이 ∇2fk에 대해 negative curvature를 갖는 direction일 때, 3) ϵk로 정의되는 convergence tolerance를 만족할 때 iteration을 종료한다는 것이다.
z0=0으로 initialize 하는게 중요한 부분이다. ∥∇fk∥2≥ϵk라면, Algorithm 7.2는 mk(pk)≤mk(pkC)인 점 pk에서 종료한다. 즉, model function에 대한 reduction이 Cauchy point로 얻어지는 것보다 같거나 크다는 것이다. 이를 보이기 위해 여러 경우들을 생각해보자. 먼저, 만약 d0TBkd0=(∇fk)TBk∇fk≤0이면, negative curvature test가 만족되어 Cauchy point p=−Δk(∇fk)/∥∇fk∥을 반환한다. 이외의 경우, Algorithm 7.2는 z1을 다음과 같이 정의한다.
만약 ∥z1∥<Δk라면 z1은 정확히 Cauchy point이다. Algorithm 7.2의 이어지는 step들은 최종 pk가 mk(pk)≤mk(z1)을 만족하도록 만든다. 만약 ∥z1∥≥Δk면 Cauchy point를 반환한다. 모든 경우에 최소 Cauchy point 만큼은 model mk를 감소시키기 때문에 Algorithm 7.2는 globally convergent하다.
또 중요한 성질 중 하나는 zj의 norm이 매 iteration마다 zj−1의 norm보다 커진다는 것이다. 이는 z0=0으로 initialize한 결과이다. mk를 넘어서 탐색해봤자 의미가 없기 때문에 boundary에 도착하면 iteration을 종료한다는 것을 함의한다.
Theorem 7.3
Algorithm 7.2에 의해 생성되는 vector의 sequence {zj}는 다음을 만족한다.
0=∥z0∥2<⋯<∥zj∥2<∥zj+1∥2<⋯<∥pk∥2≤Δk
증명
먼저 Algorithm 7.2에 의해 생성되는 vector들의 sequence가 j≥0에 대해 zjTrj=0이고 j≥1에 대해 zjTdj>0임을 만족함을 보이자. zj+1은 zj에 대해 recursive 하게 계산되지만, 다음과 같이 풀어 쓸 수 있다.
zj=z0+i=0∑j−1αidi=i=0∑j−1αidi
양변에 r_j를 곱하고 Theorem 5.2의 내용을 적용하면 (간략히 설명하면 CG에서는 각 iteration마다 이전 direction vector들과는 orthogonal한 새 direction에 대해 minimize 하기 때문에 residual과 지난 direction vector의 내적은 0이라는 내용)
zjTrj=i=0∑j−1αidiTrj=0
귀납적으로 zjTdj>0임을 보이자. 먼저
z1Td1=(α0d0)T(−r1+β1d0)=α0β1d0Td0>0
임을 알 수 있다. 이제 zjTdj>0이 참이면 zj+1Tdj+1>0도 참임을 보이면 된다.
이제 Theorem을 증명하기 위한 준비가 끝났다. 만약 Algorithm 7.2가 djTBkdj≤0 또는 ∥zj+1∥2≥Δk에 의해 종료한다면, pk는 가능한 최대 길이인 ∥pk∥2=Δk를 만족하도록 골라질 것이다. 다른 경우들에 대해서는 ∥zj∥2<∥zj+1∥2임을 보여야한다.
Theorem에 따라 zj들은 z1으로부터 pk로 이어지는 path를 interpolate한다고 볼 수 있다는 걸 알았다. Bk=∇2fk가 PD일 때, 이 path는 dogleg method와 비교해볼 수 있다. 두 method 모두 −∇fk에서 시작해서 trust-region boundary condition이 위반되지 않는 범위에서 차근차근 pkN로 향한다. Bk=∇2fk가 PD일 때, Algorithm 7.2는 optimal 보다 적어도 절반 이상 좋은 model mk의 reduction을 가져온다.
Preconditioning the trust-region Newton-CG method
우리는 preconditioning이 CG를 가속시켜준다는 것을 알고있다. Preconditioning 하는 상황에 대해, Theorem 7.3을 일반화시켜 zj가 weighted norm ∥D⋅∥ 에 대해 monotonically 증가한다고 할 수 있다. 우선 trust-region subproblem을 weighted norm에 대해 다시 적으면,
p∈Rnminmk(p)=fk+(∇fk)Tp+21pTBkp subject to ∥Dp∥≤Δk(7.13)
여기서 p^=Dp로 정의하면,
g^k=D−TB^k=D−T(∇2fk)D−1
가 되고 (7.13)을 새로 정의한 variable로 적으면
p^∈Rnminfk+g^kTp^+21p^kTB^kp^ subject to ∥p^∥≤Δ
이므로 기존의 trust-region subproblem과 똑같은 형태이다. 따라서 Algorithm 7.2를 수정하는 일 없이 바로 적용 가능하다.
Preconditioner은 여러가지 선택지가 있는데, 그 중 incomplete Cholesky factorization에 대해 얘기해보자. PD인 matrix B에 대해 다음을 만족하는 lower triangular matrix L을 구한다.
B=LLT−R
이 때 L에 제약조건이 붙는다. 예를 들면, B의 lower triangular part와 같은 sparsity 구조를 가져야 한다던지, B보다 nonzero element의 수가 적어야 한다던지. R은 approximate factorization의 inexactness이다. Hessian ∇2fk가 indefinite한 경우에는 문제가 좀 복잡해진다. 다음 알고리즘은 trust-region Newton-CG의 preconditioner를 정의하기 위해 incomplete Cholesky와 modified Cholesky를 합쳤다.
Cholesky 분해 후에는 D=LT로 preconditioning 하면 된다.
Trust-region Newton-Lanczos method
Algorithm 7.2의 한계는 negative curvature를 갖는 어느 direction도 모두 허용해서, model에 대한 reduction이 적은 것까지 채택한다는 것이다. 예를 들어,
pminm(p)=10−3p1−10−4p12−p22 subject to ∥p∥≤1
문제를 생각해보자. p=0일 때 steepest descent direction은 (−10−3,0)T이고 negative curvature를 가진다. Algorithm 7.2는 이 direction과 trust-region boundary와 경계를 채택하면 model m에 대한 reduction은 약 10−3이다. 다음 step도 비슷하게 이어질 것이다.
챕터 4에서 Hessian ∇2fk가 negative eigenvaules를 가질 때, search direction이 ∇2fk의 가장 작은 eigenvalue에 해당하는 eigenvector 쪽 성분을 크게 가질 것이라는 것을 보았다. (Theorem 4.1의 1번과 그에 대한 분석 Iterative solution of the subproblem 참조, 내가 이해하기로는 p(λ)=−(B+λI)−1g 인데, negative eigenvalue가 존재하면 B+λI가 PD여야 한다는 조건에 의해 λ가 양의 값을 가져야한다. 이 때, B+λI=Q(Λ+λI)QT로 분해하면 p(λ)=−∑j=1nλj+λqjTgqj 이니, 가장 작은 eigenvalue를 가지는 eigenvector 성분이 분모 값이 작아지므로 두드러질 것이다.) 이 성질을 이용하여 algorithm이 minimizer가 아닌 stationary point에서 빠르게 벗어나도록 만들 수 있다. 여기서 앞에 괄호 안에 적힌 내용을 적용할 수 있다는 것이다.
다른 방법은 Bkp=−∇fk를 풀 때 CG 대신 Lanczos method를 이용하는 것이다. Lanczos method는 indefinite system에 적용 가능한 CG의 일반화 된 버전이라고 생각하면 되고, negative curvature information을 모으며 CG를 계속 진행할 수 있게 해준다.
j step 후, Lanczos method는 n×j matrix Qj를 만드는데, Qj의 column들은 서로 orthogonal하며 Lanczos method에 의해 생성되는 Krylov subspace를 span한다. Qj는 QjTBQj=Tj (여기서 Tj는 tridiagonal 행렬) 가 되는 성질을 가지고 있다. Tridiagonal하다는 점을 이용해서 basis Qj의 range 안에서 trust-region subproblem의 approximate solution을 찾을 수 있다. e1=(1,0,0,…,0)T일 때, 그렇게 함으로써 다음의 문제를 풀고
w∈Rjminfk+e1TQj(∇fk)e1Tw+21wTTjw subject to ∥w∥≤Δk
trust-region subproblem의 approximate solution은 pk=Qjw로 정의한다. Tj가 tridiagonal이므로 위 problem은 Tj+λI를 factoring하고 챕터 4의 Iterative solution of the subproblem의 방법처럼 풀면 된다.
Limited-memory quasi-Newton methods
큰 문제의 Hessian matrix가 계산 비용이 너무 크거나 sparse 하지 않을 때 사용한다. Hessian의 n×n approximation을 모두 저장하는 대신, n 길이를 갖는 vector들을 몇개 저장한다. 그럼에도 불구하고 꽤 괜찮은 (linear 이지만) rate of convergence를 보여준다. 여기서는 L-BFGS를 주로 다룰것이다. L-BFGS의 메인 아이디어는 Heesian approximation에 최근 수 iteration에서 얻은 curvature 정보만 사용하는 것이다.
Limited-memory BFGS
먼저 BFGS를 표현하는 수식들로부터 시작하자. 각 BFGS의 step은
xk+1=xk−αkHk∇fk
여기서 αk는 step length이고 Hk는 approximated inverse Hessian이며
Hk를 모두 저장하는 대신 m개(일반적으로 3~20개)의 {si,yi} vector pair 만을 저장하자 (이제 정확히는 modified 버전 Hk를 저장하는 것이다). 이를 이용해서 Hk대신 Hk∇fk를 바로 계산한다. 각 step마다 새 vector pair를 저장하고 제일 오래된 것은 버린다.
이제 update 과정을 조금 더 자세히 살펴보자. k번째 iteration에서 먼저 initial Hessian approximation Hk0를 고른다 (BFGS와 다르게 각 iteration마다 initial approximation이 달라도 된다). BFGS의 Hk+1 구하는 식을 반복한다고 보면,
Hk0q 계산을 빼면 총 4mn 번의 곱셈 연산이 필요하다. 만약 Hk0가 diagonal이면 n 번의 추가적인 곱셈 연산이 필요하다. 계산 복잡도가 낮을 뿐만 아니라 initial matrix Hk0가 나머지 계산과 분리되어 있어 각 iteration마다 자유롭게 고를 수 있다는 장점도 있다. 효과적인 방법 중 하나는 Hk0=γkI로 잡는 것이라고 한다. 이 때,
γk=yk−1Tyk−1sk−1Tyk−1
γk는 가장 최근 search direction에 대한 true Hessian matrix의 size를 추정하는 scaling factor이다. 이 방법을 사용하면 search direction pk가 잘 scaled 되게 보장해주고 대부분의 iteration에서 step length αk=1이 선택되도록 만든다.
Iteration이 m 번 이상 진행되어서 계산에 필요한 vector pair들이 쌓이기 전에는 BFGS와 동일하게 작동한다 (initial Hessian이 똑같이 선택되고, L-BFGS에서 Hk0=H0을 선택하는 경우).
L-BFGS의 가장 큰 단점은 ill-conditioned problem (특히 eigenvalue가 넓게 퍼져 있는 문제)에서 수렴이 느리다는 것이다.
Relationship with conjugate gradient methods
Limited-memory method는 nonlinear conjugate gradient method를 개선하고자 하는 시도해서 진화했고, 초기 구현은 quasi-Newton method 보다는 CG에 닮았다. 이 두 class 간의 관계가 memoryless BFGS iteration의 근간이 된다.
Nonlinear CG의 하나인 Hestenes-Stiefeil로부터 시작하자. Search direction은
이 식은 quasi-Newton과 닮았지만 matrix H^k+1이 symmetric, PD가 아니다. H^k+1TH^k+1로 symmetric화 할 수 있지만 secant equation은 만족하지 못하고, singular하다. Symmetric하고 PD이고 secant equation을 만족시키는 iteration matrix는
이는 L-BFGS update 식이 Hk=I일 때 적용된 것과 동일하다. 항상 이전 Hessian approximation이 identity matrix로 reset된다는 의미에서 위 식으로 업데이트 되는 알고리즘들을 “memoryless” BFGS 라고 할 수 있다.
Memoryless BFGS에 exact line search를 고려하면 CG와의 관계가 더 잘 드러난다. 식을 써보면,
pk+1=−Hk+1∇fk+1=−∇fk+1+ykTpk∇fk+1Tykpk
Hestenes-Stiefel과 완전히 동일하다. 여기서 모든 k에 대해 ∇fk+1Tpk=0이라 가정하면 Hestenes-Stiefel에서 Polak-Ribiere가 된다.
General limited-memory updating
Quasi-Newton matrix를 compact (또는 outer product) form으로 나타냄으로써 모든 quasi-Newton update formula와 inverse에 대해 효율적인 implementation을 유도할 수 있다. 여기서는 correction pair를 연속적으로 update하는 경우만 다룬다 (반대되는 방식으로는 storage가 가득차면 모두 버리고 새로 프로세스를 시작하는 것이 있다. 실험 결과 효율이 떨어진다 한다.).
Compact representation of BFGS updating
Theorem 7.4
B0이 symmetric, PD라고 하고, k vector pair {si,yi}i=0k−1이 siTyi>0을 만족한다 가정하자. Bk가 B0에 k번 BFGS update를 적용하여 얻어진다고 하자. 그러면,
(Lk)i,j={si−1Tyj−1 if i>j0otherwiseDk=diag[s0Ty0,…,sk−1Tyk−1]
은 k×k matrix이다.
siTyi>0,i=0,1,…,k−1 조건이 (7.24)의 가운데 matrix가 nonsingular하도록 보장해준다. L-BFGS처럼 최대 m개의 최신 correction pair {si,yi}를 갖고 오래된 pair는 버린다. Bk0=δkI (여기서 δk=1/γk)로 선택하면 첫 m iteration 동안의 Theorem 7.4의 식을 바로 사용할 수 있다.
k>m 번째 iteration에서는 {si,yi}의 변하는 성질을 반영하기 위해, n×m matrix Sk와 Yk를 다음과 같이 정의하고
(Lk)i,j={sk−m−1+iTyk−m−1+j if i>j0otherwiseDk=diag[sk−mTyk−m,…,sk−1Tyk−1]
은 m×m matrix이다. xk+1이 생성되고 나면 Sk에서 sk−m을 지우고 sk를 추가해서 Sk+1를 얻는다 (Yk+1, Lk+1, Dk+1도 비슷하게 얻음).
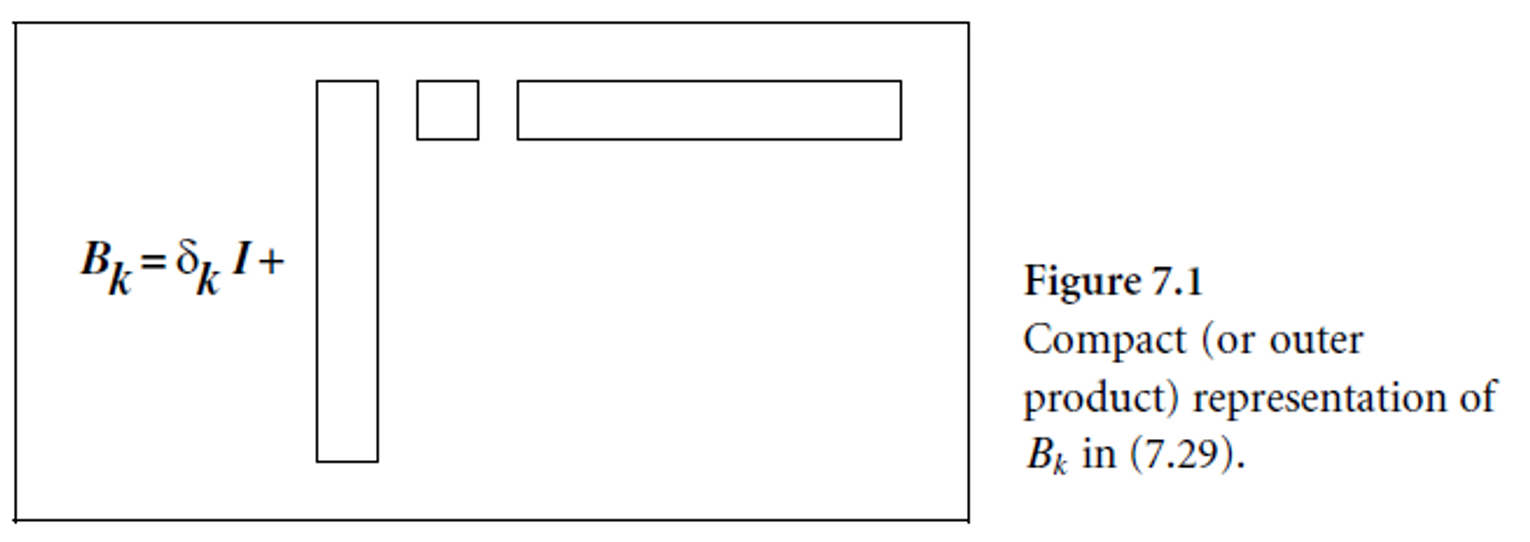
(7.29) 식의 가운데 matrix의 dimension이 2m으로 작기 때문에 factorization의 계산 비용이 무시할만하다. 위 그림에서 볼 수 있듯이 correction을 길고 narrwo한 matrix들의 outer product로 볼 수 있다.
Bk의 limited-memory update는 2mn+O(m3) operation이 필요하고 matrix-vector 곱 Bkv는 (4m+1)n+O(m2) 곱셈연산이 필요하다. m이 작을 때는 Bk를 바로 다루는 것이 경제적이다.
Bk의 approximation이 trust-region method나, 특히 bound-constrained, general-constrained optimization에서 사용될 수 있다. L-BFGS-B은 bound constraint이 있는 큰 nonlinear optimization을 풀기 위해 compact limited-memory approximation을 활용한다. 이 경우, constraint gradients에 의해 정의된 subspace에 대한 Bk의 projection이 반복적으로 계산되어야 한다.
물론, compact representation을 inverse Hessain approximation에 적용할 수도 있다. 또, SR1에 적용될 수도 있는데, 표기를 Theorem 7.4에서 빌려오면
Limited-memory SR1로 바꾸는 것도 limited-memory BFGS랑 같은 방식으로 할수 있다.
Unrolling the update
Limited-memory update를 더 간단하게 구현할 수는 없을까? Limited-memory BFGS update는 compact representation에 기반한 방법보다 꽤 비싸다는 것을 보자. Direct BFGS를 다시 써보면
Bk+1=Bk−akakT+bkbkT
여기서,
ak=(skTBksk)1/2Bkskbk=(ykTsk)1/2yk
Basic matrix Bk0에 대해
Bk=Bk0+i=k−m∑k−1[bibiT−aiaiT]
Vector pair {ai,bi}는 {si,yi}로부터 복원될 수 있는데,
위 과정을 살펴보면, 각 iteration k마다 ai는 vector pair {sk−m,yk−m}에 종속적이라 모두 재계산되어야 하는 반면, bi의 경우는 bk−1과 bjTsk−1만 재계산하면 된다. 이 사실을 고려해 계산을 수정하면 여전히 대략 23m2n 연산이 limited-memory matrix를 결정하기 위해 필요한데 compact form은 2mn multiplication만을 필요로한다.
Sparse quasi-Newton updates
Quasi-Newton approximation Bk가 true Hessian과 같은 (또는 비슷한) sparsity pattern을 갖도록 하는 방법에 대해서 알아보자. 이렇게 함으로써 필요한 storage는 줄이고, 정확도는 오히려 향상될 수 있다.
우리가 어느 점에서 Hessian의 어느 component가 nonzero인지 안다고 가정하자. 즉, 우리는 다음의 set의 내용을 안다.
Ω={(i,j)∣[∇2f(x)]ij=0 for some x in the domain of f}
또, 현재의 Hessian approximation Bk의 exact Hessian의 nonzero structure을 반영한다고 가정하자. 즉, (i,j)∈/Ω에 대해 (Bk)ij=0이다. Bk를 Bk+1로 업데이트 하면서 1) secant condition이 만족하고, 2) 같은 sparsity pattern을 가지고, 3) Bk와 최대한 가까운 Bk+1를 찾고 싶다. 이를 최적화 문제로 표현하면,
Bmin∥B−Bk∥F2=(i,j)∈Ω∑[Bij−(Bk)ij]2subject to Bsk=yk,B=BT,Bij=0 for (i,j)∈/Ω
이 최적화 문제의 solution Bk+1은 sparsity pattern이 Ω인 n×n linear system을 풀어서 얻을 수 있다. Bk+1을 얻고나면 이를 trust-region method에 이용해서 xk+1을 얻을 수 있다. 참고로 Bk+1은 PD가 아닐 수 있다. 그런데 사실 이런 방식은 scale invariance하지 못하고 실제 해보면 성능이 떨어진다는 단점이 있다.
다른 방법으로 secant equation을 relax해서 마지막 step에 strictly 만족하도록 하기보다는 최근 몇 step에 approximately 만족하도록 하는 것이다. Sk, Yk를 limited-memory BFGS 때처럼 최근 m개에 대해 저장한 것으로 정의하면,
Bmin∥BSk−Yk∥F2subject to B=BT,Bij=0 for (i,j)∈/Ω
이 convex optimization은 solution이 있지만 계산하기 쉽지 않다. 또 생성된 Hessian approximation이 singular하거나 poorly condition 되어있을 수 있다. 앞에 방식보단 낫지만 큰 문제에서는 성능이 썩 좋지는 않다.
Algorithms for partially separable functions
Separable하다는 것은 함수가 더 간단한 독립적으로 최적화 될 수 잇는 함수들의 합으로 분해될 수 있다는 것을 말한다. 예를들어,
f(x)=f1(x1,x3)+f2(x2,x4,x6)+f3(x5)
변수가 겹치지 않음을 주목하자. 일반적으로 더 낮은 차원의 최적화를 여러번 하는게 높은 차원 최적화 한번 하는것 보다 경제적이다.
일반적으로 큰 objective function f:Rn→R은 separable하지 않은데, 그래도 element function이라는 것의 sum으로 적을 수 있다. 각 element function은 많은 수의 linearly independent direction으로 움직였을 때 영향받지 않는다는 성질이 있다. 이런 성질을 만족할 때 f가 partially separble하다고 말한다. Hessian ∇2f가 sparse한 모든 함수는 partially separable하다. Partially separable하면 어떻게 도움되는지 살펴보자.
가장 간단한 형태의 partial separability는 objective function이 다음과 같이 쓰여질 수 있을 때다.
f(x)=i=1∑nefi(x)
여기서 fi는 각각 몇개의 x에만 의존한다. 그러면,
∇f(x)=i=1∑ne∇fi(x)∇2f(x)=i=1∑ne∇2fi(x)
이런 경우에 전체 Hessian ∇2f(x)를 approximate하는 것보다 효율적인 방법이 있을까? Quasi-Newton approximation이 이런 구조를 잘 활용한다면 가능하다. 다음의 objective function을 예를 들어 설명하자.
Matrix U1을 compactifying matrix라고 부르는데, 위 두 matrix를 비교해보면 알 수 있듯이 derivative 정보를 작은 dimension에 저장할 수 있게 해준다.
그래서 핵심 아이디어는 quasi-Newton approximation ∇2f1을 저장하는 대신에 ∇2ϕ1의 2×2 quasi-Newton approximation B[1]을 저장해두자는 것이다. B[1]을 업데이트 하기 위해 x에서 x+로 가는 step 후 다음 정보를 저장한다.
s[1]=x[1]+−x[1]y[1]=∇ϕ1(x[1]+)−∇ϕ1(x[1])
그리고 B[1]+를 얻기 위해 BFGS나 SR1을 사용한다. 그러면
B[1]≈∇2ϕ1(U1x)=∇2ϕ1(x[1])
이고, ∇2f1을 얻기 위해서는
∇2f1(x)≈U1TB[1]U1
로 transformation해서 얻을 수 있다. 이를 각 element function에 대해 적용하면