데이터셋 종류
훈련 데이터셋(Training Dataset): 모델의 학습에 사용되는 데이터셋이다.
테스트 데이터셋(Test Dataset): 모델의 일반화 성능을 평가하기 위해 사용되는 독립적인 데이터셋이다.
검증 데이터셋(Validation Dataset): 일부 경우에는 모델의 하이퍼파라미터를 조정하고 모델의 성능을 향상시키기 위해 검증 데이터셋을 사용한다.
과적합이란?
과적합(Overfitting)은 머신 러닝에서 모델이 훈련 데이터에 지나치게 적합되어, 새로운 입력 데이터에 대한 일반화 성능이 저하되는 현상을 의미한다.
그래프로 과적합 확인
# 그래프 확인을 위한 긴 학습
history = model.fit(X_train, y_train, epochs=2000, batch_size=500,
validation_split=0.25)
# history에 저장된 학습 결과를 확인
hist_df = pd.DataFrame(history.history)
hist_df
# y_vloss에 테스트셋의 오차 저장
y_vloss = hist_df['val_loss']
# y_loss에 학습셋의 오차 저장
y_loss = hist_df['loss']
# x 값을 지정하고 테스트셋의 오차를 빨간색으로, 학습셋의 오차를 파란색으로 표시합니다.
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, "o", c="red", markersize=2, label='Testset_loss')
plt.plot(x_len, y_loss, "o", c="blue", markersize=2, label='Trainset_loss')
plt.legend(loc='upper right')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()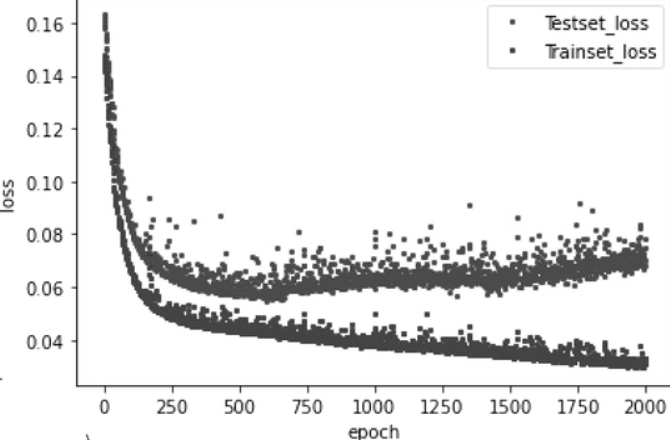
과적합 방지
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
# 학습이 언제 자동 중단될지 설정합니다.
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=20)
# 최적화 모델이 저장될 폴더와 모델 이름을 정합니다.
modelpath = "./data/model/Ch14-4-bestmodel.hdf5"
# 최적화 모델을 업데이트하고 저장합니다.
checkpointer = ModelCheckpoint(filepath=modelpath, monitor='val_loss',
verbose=0, save_best_only=True)
# 모델을 실행합니다.
history = model.fit(X_train, y_train, epochs=2000, batch_size=500, validation_split=0.25, verbose=1, callbacks=[early_stopping_callback, checkpointer])
프론트 공부하는 중..