✔ RDBMS
- 관계형(Relational) 데이터베이스 시스템
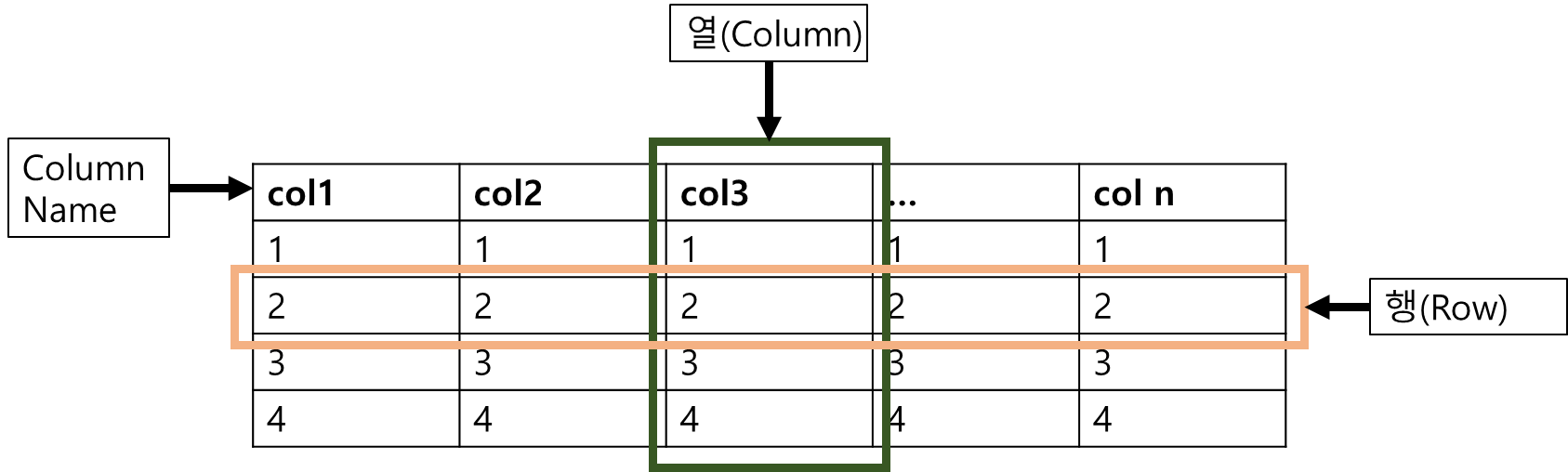
- 테이블 기반의 DBMS
- 데이터를 테이블 단위로 관리.
- 하나의 테이블은 여러 개의 컬럼(Column)으로 구성
- 중복 데이터 최소화.
- 같은 데이터가 여러 컬럼 또는 테이블에 존재할 경우, 데이터 수정시 문제가 발생할 가능성이 높아짐. (정규화)
- 여러 테이블에 분산되어 있는 데이터를 검색시 테이블 간의 관계(join)을 이용하여 필요한 데이터 검색.
- RDBMS 저장 구조 : Table
✔ SQL(Structured Query Language)
- Database에 있는 정보를 사용할 수 있도록 지원하는 언어.
- 모든 DBMS에서 사용 가능
- 대소문자 구분 X(단, 데이터의 대소문자는 구분.)
- 명령어 : DCL(제어), DDL(정의), DML(조작)
- DCL(Data Control Language) : GRANT, REVOKE
- DDL(Data Definition Language) : CREATE, ALTER, DROP, RENAME
- DML(Data Manipulation Language) : INSERT, UPDATE, DELETE, SELECT
- COMMIT, ROLLBACK : DML 명령문 수행한 변경 관리.
1. DDL(Data Definition Language)
- 데이터 정의어
- 데이터베이스 객체(table, view, index, ...) 구조 정의
- 테이블 생성, 컬럼 추가, 타입 변경, 제약조건 지정, 수정 등.
| SQL문 | 설명 |
|---|
| create | 데이터베이스 객체 생성 |
| drop | 데이터베이스 객체 삭제 |
| alter | 기존에 존재하는 데이터베이스 객체 수정 |
◾ 데이터베이스 생성.
create database 데이터베이스명 [default character set 값 collate 값];
- Character set : 문자가 컴퓨터에 저장될 때 어떤 코드로 저장될지 규칙의 집합.
- collate : 특정 문자 셋에 의해 데이터베이스에 저장된 값들을 비교, 검색, 정렬 등의 작업을 위해 문자들을 서로 비교할 때 사용하는 규칙들의 집합.
◾ 데이터베이스 변경.
alter database 데이터베이스명 [default character set 값 collate 값]
◾ 데이터베이스 삭제
- 데이터베이스 삭제 :
drop database 데이터베이스명;
- 데이터베이스 사용 :
use 데이터베이스명;
◾ table 생성.
- 데이터 타입
- 문자형 데이터
- CHAR(M) : 고정 길이 M 문자열. 1~255.
- VARCHAR(M) : 가변 길이 M 문자열. 1~65535.
- TEXT(M) : 최대 65535bytes.
- 숫자형 데이터
- INT(M) : (signed)-2147483648~2147483647, (unsigned)0~4294967295
- DOUBLE, FLOAT, REAL 등
- 날짜형 데이터
- DATE : YYYY-MM-DD
- DATETIME : YYYY-MM-DD HH:MM:SS
- TIMESTAMP(M) : 1970-01-01~2038-01-19 03:14:07까지 지원. (1970-01-01 00:00:00을 1초 단위로 표기.)
- 이진 데이터
- 테이블 생성
- optional attributes
- NOT NULL
- DEFAULT value
- UNSIGNED
- AUTO INCREMENT
- PRIMARY KEY
- 제약 조건 : 컬럼에 저장될 데이터의 조건 설정.
- constraint로 지정하거나 ALTER로 설정.
create table 테이블명(
column_name1 Type [option],
column_name2 Type [option],
... ,
column_nameN Type [option],
[constaint 제약 조건]
);
- 스키마 : 데이터베이스의 테이블에 저장될 데이터의 구조와 형식 정의.
2. DML(Data Manipulation Language)
- 데이터 조작어
- Data 조작 가능
- 테이블의 레코드를 CRUD(Create, Retrieve, Update, Delete)
| SQL문 | 설명 |
|---|
| insert(c) | 데이터베이스 객체에 데이터 입력. |
| select(r) | 데이터베이스 객체에서 데이터 조회. |
| update(u) | 데이터베이스 객체에 데이터 수정. |
| delete(d) | 데이터베이스 객체에 데이터 삭제. |
◾ INSERT
insert into 테이블명 VALUES (col_val1, col_val2, ..., col_valN);insert into 테이블명 (col_name1, col_name2, ...col_nameN) VALUES (col_val1, col_val2, ..., col_valN);- 생략 가능한 Field
- NULL이 허용된 컬럼.
- DEFAULT가 설정된 컬럼.
- AUTO INCREMENT가 설정된 컬럼.
◾ UPDATE
update 테이블명 SET col_name=col_val1, [...] WHERE 조건- WHERE 조건을 만족하는 레코드 값 변경
- WHERE을 생략하면 모든 데이터 변경.
◾ DELETE
delete from 테이블명 wehre 조건- WHERE을 생략하면 모든 데이터 삭제.
◾ SELECT
select * | {[all|distinct] column | expression[alias], ...} from 테이블명 [wrere ... order by...];
- ALL : 선택된 모든 행 반환. (default)
- DISTINCT : 선택된 행 중 중복 제거.
- column : from 절에 나열된 테이블에서 지정된 열 선택.
- expression : 표현식 값으로 인식되는 하나 이상의 값, 연산자 및 SQL 함수의 조합을 의미.
- alias : 별칭
- order by : 정렬 (default : asc)
3. DCL(Data Control Language)
- 데이터 제어어
- DB, Table 접근 권한이나 CRUD 권한 정의.
- 특정 사용자에게 테이블의 검색 권한 부여/금지 등.
| SQL문 | 설명 |
|---|
| grant | 데이터베이스 객체 권한 부여. |
| revoke | 데이터베이스 객체 권한 취소. |
4. TCL(Transaction Control Language)
- 트랜잭션 제어어
- transaction : 데이터베이스 논리적 연산 단위.
| SQL문 | 설명 |
|---|
| commit | 실행한 Query 최정적으로 적용. |
| rollback | 실행한 Query를 마지막 commit 전으로 취소시켜 데이터 복구. |
5. MySQL 내장 함수
◾ 숫자
- ABS() : 절대값
- CEILING() : 값보다 큰 정수 중 가장 작은 수
- FLOOR() : 값보다 작은 정수 중 가장 큰 수
- ROUND() : 숫자를 자릿수 기준으로 반올림.
- TRUNCATE() : 숫자를 자릿수 기준으로 버림.
- POW(), POWER() : X의 Y승
- MOD() : 분자를 분모로 나눈 나머지
- GREATEST() : 가장 큰 수.
- LEAST() : 가장 작은 수.
◾ 문자
- ASCII() : 문자의 아스키 코드 값.
- CONCAT(문자열1, 문자열2, ...) : 문자열 결합.
- INSERT(문자열, 시작위치, 길이, 새로운 문자열) : 시작 위치부터 길이만큼 새로운 문자열로 대치.
- REPLACE(문자열, 기존 문자열, 바뀔 문자열) : 기존 문자열을 바뀔 문자열로 대치.
- INSTR(문자열, 찾는 문자열) : 찾는 문자열의 위치 값.
- MID(문자열, 시작위치, 개수) : 문자열 중 시작위치부터 개수만큼 리턴.
- SUBSTRING(문자열, 시작위치, 개수) : 문자열 중 시작위치부터 개수만큼 리턴.
- LTRIM(), RTRIM(), TRIM() : 왼쪽, 오른쪽, 양쪽 공백 제거.
- LCASE(), LOWER() : 소문자로 변경.
- UCASE(), UPPER() : 대문자로 변경.
- LEFT(문자열, 개수) : 문자열 중 왼쪽에서 개수만큼 추출.
- RIGHT(문자열, 개수) : 문자열 중 오른쪽에서 개수만큼 추출.
- REVERSE(문자열) : 문자열 반대로 나열.
◾ 날짜
- NOW(), SYSDATE(), CURRENT_TIMMESTAMP() : 현재 날짜와 시간.
- CURDATE(), CURRENT_DATE : 현재 날짜.
- CURTIME(), CUREENT_TIME() : 현재 시간.
- DATE_ADD(날짜, 인터벌, 기준값) : 날짜에서 기준 값 만큼 더한다.
- DATE_SUB(날짜, 인터벌, 기준값) : 날짜에서 기준 값 만큼 뺀다.
- YEAR(날짜) : 연도.
- MONTH(날짜) : 월.
- MONTHNAME(날짜) : 월 (영어)
- DAYNAME(날짜) : 요일 (영어)
- DAYOFMONTH(날짜) : 월별 일자.
- DAYOFWEEK(날짜) : 주별 일자[일(1), ... 토(7)]
- WEEKDAY(날짜) : 주별 일자[일(0), ..., 토(6)]
- WEEK(날짜) : 일년중 몇 번째 주인지
- FROM_DAYS(날수) : 00년 00월 00일부터 날 수만큼 경과한 날의 날짜 리턴.
- TO_DAYS(날짜) : 00년 00월 00일부터 날짜까지의 일자 수 리턴.
- DATE_FORMAT(날짜, '형식') : 날짜를 형식에 맞게 반환.
◾ 논리
- IF(논리식, 값1, 값2) : 참일 경우 값1, 거짓이면 값2 반환.
- IFNULL(값1, 값2) : 값1이 NULL이면 값2로 대치. NULL이 아니면 값1 반환.
- NULLIF(값1, 값2) : 값1 = 값2 TRUE이면 NULL 그렇지 않으면 값1 리턴.
◾ 그룹
- COUNT() : 레코드의 수.
- SUM() : 레코드 값의 합계.
- AVG() : 레코드 값의 평균.
- MAX() : 레코드 값 중 최대값.
- MIN() : 레코드 값 중 최소값.
6. Aggregation Function
- 집계(그룹, 집합) 함수는 하나 이상의 행을 그룹으로 묶어 연산하여 총합, 평균 등의 결과 반환
sum : 그룹의 누적 합계.avg : 그룹의 평균.count : 그룹의 null 제외 총 개수.
- 중복 제거를 하고 싶다면 distinct 키워드 사용.
max : 그룹의 최대값.min : 그룹의 최소값
7. GROUP BY
- group by
- SELECT 문에서 GROUP BY절을 사용하여 쿼리된 테이블의 행을 그룹으로 묶음.
집계 함수를 각 그룹에 대해 단일 결과 행으로 반환.- GROUP BY 절을 생략하면 집계 함수는 모든 행에 적용.
- SELECT 절의 모든 요소는 GROUP BY절의 표현식, 집계 함수를 포함하는 표현식 또는 상수만 가능.
- having
- group by한 결과에 조건을 추가할 경우 사용.
- aggregate 조건은 where절이 아닌 having에 사용.
SELECT 실행 순서
SELECT columns : 5FROM table_name : 1WHERE conditions : 2GROUP BY grouping column : 3HAVING grouping conditions : 4ORDER BY col [ASC|DESC] : 6
8. SET(집합 연산자)
- 모든 집합 연산자는 동일한 우선 순위.
- select 절에 있는 column의 개수와 type이 일치해야한다.
- SET : MySQL은 UNION만 지원.
- UNION(합집합) : 두 쿼리에서 선택된 모든 행 반환(중복은 한 번만 포함)
- UNION ALL(합집합) : 두 쿼리에서 선택된 모든 행 반환(모든 중복 포함)
- INTERSECT(교집합) : 두 쿼리에서 선택된 모든 중복 행 반환.
- MINUS(차집합) : 첫 번째 쿼리에서 선택한 행 반환(중복행 제거)
9. Transaction
- 트랜잭션 : 데이터베이스의 상태를 변화시키는 일종의 작업 단위.
- 트랜잭션 도구
- START TRANSACTION : COMMIT, ROLLBACK이 나올 때까지 실행되는 모든 SQL.
- COMMIT : 모든 코드 실행.
- ROLLBACK : START TRANSACTION 실행 전 상태로 되돌림.
