Wrap up Report
<기술적인 도전>
본인의 점수 및 순위
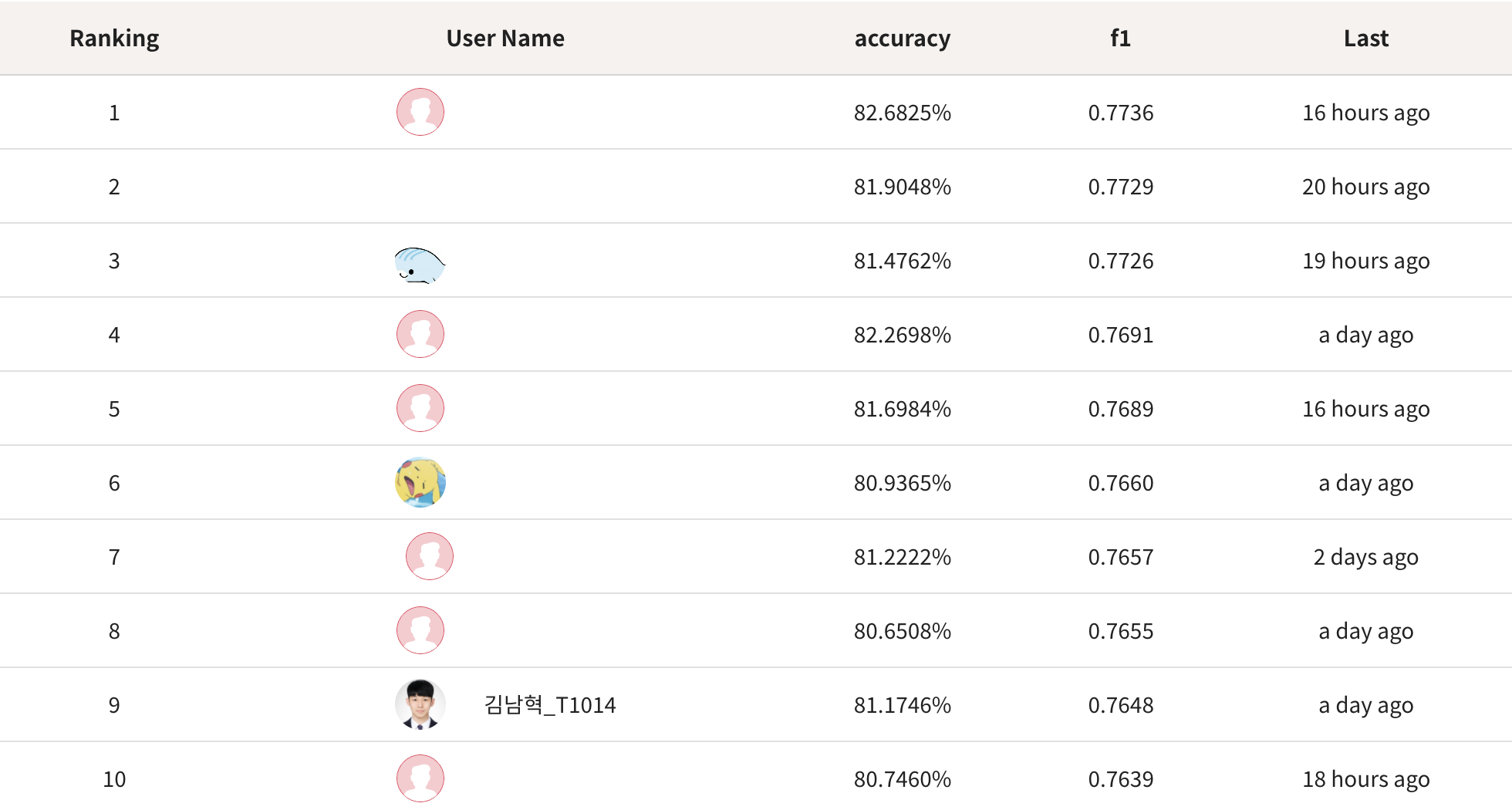
- LB 점수 accuracy: 81.1746%, f1: 0.7648, 9등
검증(Validation)전략
- 제공된 dataset에 age filtering(>= 58) 이후 10-fold cross-validation을 적용했습니다.
- 그리고 train dataset에 pseudo labeling 된 eval dataset을 추가했습니다.
사용한 모델 아키텍처 및 하이퍼 파라미터
- 아키텍쳐: ResNet34
A. LB 점수 accuracy : 81.5238%, f1 : 0.7669%
B. transforms.CenterCrop(384)
C. transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
D. batch_size=4
E. LabelSmoothingLoss()
F. optim.SGD(model_ft.parameters(), lr=0.0001, momentum=0.9)
G. lr_scheduler.StepLR(optimizer_ft, step_size=10, gamma=0.9)
H. num_epochs=15
I. 해당 competition에서는 model보다는 data 자체가 중요했다고 생각합니다.
J. 따라서, 최소한의 성능이 보장되는 model만 구현하고 data에 집중했습니다.
앙상블 방법
- Hard Voting
- Soft Voting
시도했으나 잘 되지 않았던 것들
- 해당 dataset에서는 Data Augmentation 했던 것이 생각보다 성공적이지 않아서 아쉬웠습니다.
A. data가 워낙 깔끔했기 때문에 이러한 결과가 나온 것으로 생각됩니다.
B. 따라서, CenterCrop과 Normalize 정도만 사용했습니다. - 개인적으로 시도했을 때, 3X2X3-class classifier multi model로 했던 것이 생각보다 성공적이지 않아서 아쉬웠습니다.
A. 한두 번의 시도로 너무 성급하게 포기한 것 같아 아쉽습니다.
B. 결과론적으로 학습 시간에 이점이 있었던 18-class classifier single model이 해당 competition에는 적합했던 것 같습니다. - FocalLoss와 F1Loss가 생각보다 성공적이지 않아서 아쉬웠습니다.
- 외부 데이터 추가
A. Flickr-Faces-HQ (FFHQ), Correctly Masked Face Dataset (CMFD), Incorrectly Masked Face Dataset (IMFD) 그리고 All-Age-Faces-Dataset을 추가했습니다.
B. 과도한 일반화로 인해 실패했다고 생각됩니다.
C. 해당 competition에서는 일반화보다는 train과 eval dataset에 overfitting 되는 것이 중요했다고 생각합니다. - 이미지 분류 문제가 아니라, 이미지 매칭 문제로 해결하고자 했습니다.
A. eval dataset에는 1,800명이 있고 한 사람당 7장의 사진을 가지고 있습니다.
B. 그리고 마스크를 착용한 사람의 나이를 정확하게 분류하지 못하는 것이 성능 저하의 원인이라고 생각했습니다.
C. 따라서 동일한 사람의 사진을 7장 매칭 후, 미착용 사진으로 성별과 나이를 분류하고 이를 바탕으로 나머지 6장의 사진을 분류한다면 성능이 오를 것으로 생각했습니다.
D. 물론, 일반적인 방법은 아니며, eval dataset의 허점을 이용하고자 한 것입니다.
E. 이미지 매칭을 위해서 단순 유사도, ImageHash, deepface 등 다양한 방법들을 사용했습니다.
F. 그 결과, 유사한 데이터가 많아 동일한 사람의 사진을 7장 매칭하는 것은 불가능에 가깝다고 생각했습니다.
G. 이미지 매칭에서 생기는 성능 저하나 이미지 분류에서 생기는 성능 저하가 큰 차이가 없을 것으로 생각되어, 이후에는 이미지 분류에 집중했습니다.
<학습과정에서의 교훈>
학습과 관련하여 개인과 동료로서 얻은 교훈
- U Stage에서 같은 조였던 서일님에게 많은 도움을 받았습니다.
A. 본인이 가지고 있는 정보를 아낌없이 공유해주었습니다. (위에서 언급한 외부 데이터도 공유해주셨습니다.)
B. Competition의 특성상 핵심이 되는 정보는 공유하지 않았는데, 서일님에게는 모두 공유를 했고 추가로 조언도 받을 수 있었습니다.
C. 모든 사람과는 아니더라도, 마음이 맞는 사람들과 정보를 공유하는 것도 괜찮은 것 같다고 생각했습니다. - 예전에 pseudo labeling을 좋은 방법이라고 생각하지는 않았는데, 이번 대회를 통해서 Semi-Supervised Learning인 pseudo labeling의 힘을 깨달을 수 있었습니다.
피어세션을 진행하며 좋았던 부분과 동료로부터 배운 부분
- 대회 초반, 다른 사람들의 다양한 시도와 결과를 참고할 수 있어서 좋았습니다.
- 랜덤으로 진행된 피어세션 덕분에, 커뮤니케이션의 중요성을 느낄 수 있었습니다.
<마주한 한계와 도전숙제>
아쉬웠던 점들
- 성능이 좋았던 단 하나의 모델에만 집중하여 아쉬웠습니다.
A. 하나의 모델로만 진행하다 보니, 유사한 모델과 결과만 생성되어 앙상블에서 큰 효과를 보지 못했습니다.
B. 그리고 pseudo labeling으로 특정 성능에 수렴했을 때, 벗어날 방법이 없었습니다.
한계/교훈을 바탕으로 다음 스테이지에서 새롭게 시도해볼 것
- 다음 스테이지는 한국어 언어 모델 학습 및 다중 과제 튜닝 (KLUE) 입니다. 어떤 task로 competition을 하는지 모르기 때문에, 어떤 시도를 해볼지 아직 잘 모르겠습니다. 만약 pretrain된 언어 모델을 사용한다면, 적어도 2개 이상의 언어 모델을 가지고 competition을 진행해볼 계획입니다.
마무리
오늘보다 더 성장한 내일의 저를 기대하며, 다음 주에 뵙도록 하겠습니다.
읽어주셔서 감사합니다!

PLUS ULTRA