Wrap up Report
<기술적인 도전>
본인의 점수 및 순위
-
LB 점수 accuracy: 0.0000%, 136등(꼴등)
- 데이터 부족 (Train : 9,000 + Test : 1,000 = Total : 10,000)
- 부족한 데이터에 비해 많은 클래스 (Class : 42)
- 데이터 불균형
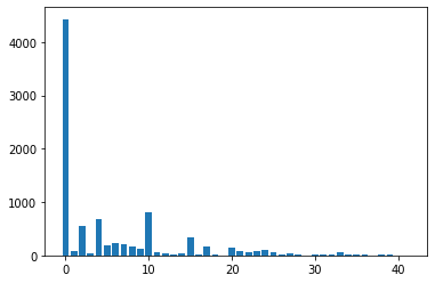
- 데이터 오류 (공식적으로 9개, 비공식은…)
- Test dataset에 없는 클래스가 존재 (3개로 추정)
- Private Leaderboard의 부재
- 베이스라인 코드만으로도 상위권(80% 대) 가능
- 세상에 완벽한 데이터가 없다는 것은 알고 있습니다.
- 하나씩 따로 보면 1~7 모두 극복해야 하고 극복할 수 있는 문제라고 생각합니다.
- 하지만 이렇게 많은 문제가 동시다발적으로 존재한다면, 이는 Competition과 데이터에 어느 정도 문제가 있다고 생각합니다.
- 그리고 데이터에 문제가 있다 보니, 성능 향상에 도움이 된다고 알려진 일반적인 방법들 또는 SOTA 논문에서 제시된 방법들을 사용해보더라도 성능에는 큰 영향을 미치지 못했습니다.
- 성능과는 별개로 시도해보고 도전해보는 것도 중요하다고 하지만, 시도와 도전을 통해서 Competition에서 가장 중요한 성능 향상을 하지 못한다면 의미가 많이 퇴색된다고 생각합니다.
- 따라서, 이번 Competition은 리더보드에 큰 의미가 없다고 판단되어 accuracy: 0.0000%로 제출하였습니다. (
물론, 그렇다고 논 것은 아닙니다.)
검증(Validation)전략
- Train : Vali= 4 : 1 (random_seed = 42)
- 1번의 Vali_acc와 Test_acc가 유사한 것을 확인
- Split 비율과 random_seed에 따라 성능 차이가 있는 것을 확인
- 2, 3번을 이유로 5-fold cross-validation을 따로 사용하지 않았습니다.
사용한 모델 아키텍처 및 하이퍼 파라미터
- Baseline Code : xlm-roberta-large
A. http://boostcamp.stages.ai/competitions/4/discussion/post/144
B. LB 점수 accuracy : 78 ~ 79%
C. output_dir='./results',
D. save_total_limit=3,
E. save_steps=100,
F. num_train_epochs=10,
G. learning_rate=1e-5,
H. per_device_train_batch_size=32,
I. per_device_eval_batch_size=32,
J. warmup_steps=300,
K. weight_decay=0.01,
L. logging_dir='./logs',
M. logging_steps=100,
N. evaluation_strategy='steps',
O. eval_steps = 100,
P. dataloader_num_workers=4,
Q. label_smoothing_factor=0.5
R. 해당 모델에 ensemble을 하면 accuracy : 80%이 가능합니다.
S.해당 결과로 이게 무슨 의미가 있는지 허탈함을 느꼈습니다.
앙상블 방법
- Hard Voting
- Soft Voting
시도했으나 잘 되지 않았던 것들
-
KoBERT 기반의 Classification
A. 계기 : transformers의 Trainer는 편리한 만큼 코드를 수정하기가 어렵다고 생각합니다. 그래서 가장 기본적인 형태로 구현하는 것이 여러 가지로 실험해볼 수 있다고 생각되어 KoBERT 기반의 Classification을 구현하였습니다.
B. 참고 자료 : https://colab.research.google.com/github/SKTBrain/KoBERT/blob/master/scripts/NSMC/naver_review_classifications_pytorch_kobert.ipynb
C. Code : http://boostcamp.stages.ai/competitions/4/discussion/post/144
D. 해당 Competition에서는 데이터가 부족하기 때문에, Pretrain한 모델이 더 적합했다고 생각합니다. (베이스라인 코드의 결과가 이를 뒷받침합니다.)
E. 그래서 처음부터 학습시키는 해당 모델은 한계가 있다고 생각했고 첫 주차에만 다뤄봤습니다.
F. 그래도 조금 더 개선할 여지는 있었다고 생각합니다.
i. KoBERT에서 xlm-roberta-large로 변경
ii. dataset['sentence'] = dataset['entity_01'] + ' [SEP] ' + dataset['entity_02'] + ' [SEP] ' + dataset['sentence']가 아니라 tokenizer로 dataset['entity_01'] + ' [SEP] ' + dataset['entity_02']와 dataset['sentence']를 각각 문장으로 봤어야 한다고 생각합니다.
Ex) tokenized_sentences = tokenizer(concat_entity, list(dataset['sentence']), return_tensors="pt", padding=True, truncation='only_second', max_length=100, add_special_tokens=True)
iii. i, ii를 했다면 충분히 베이스라인 코드는 따라잡았을 것이라고 생각합니다. -
KoBERT(+LSTM) 기반의 Classification
A. 1번의 KoBERT 기반의 Classification에서 LSTM Layer를 추가했으나 생각보다 성공적이지 않아서 아쉬웠습니다. -
CNN 기반의 Classification
A. 계기 : 이전에 NLP에 CNN 기반의 Classification을 구현해본 적이 있습니다. 당연히 성능은 높지 않을 것이라고 예상했으나, 실험 차원에서 해당 Competition에 적용해보았습니다.
B. 참고 자료 : https://ratsgo.github.io/natural%20language%20processing/2017/03/19/CNN/
C. 다음과 같이 임베딩을 해주었습니다. NLP에서 CNN을 사용할 때에는, 캐릭터 단위로 임베딩해주는 것이 좋다고 알고 있습니다.
D. 예전에 사용했던 코드로 손 쉽게 구현하기는 했지만, 예전 기술인 만큼 성능이 좋지 못했습니다.
E. 새삼스럽지만 BERT 이후 기술들의 힘을 느낄 수 있었습니다. -
그 외
A. Entity에 NER을 추가해보았으나, 생각보다 성공적이지 않아서 아쉬웠습니다.- 누구는 성능이 올랐다고 하고, 누구는 성능에 변화가 없다고 하니, 사람마다 케이스 바이 케이스가 있는 것 같습니다.
B. 외부 데이터를 추가해보았으나, 생각보다 성공적이지 않아서 아쉬웠습니다. - 과도한 일반화로 인해 실패했다고 생각합니다.
- 해당 Competition에서는 일반화보다는 train과 test dataset에 overfitting 되는 것이 중요했다고 생각합니다.
- 누구는 성능이 올랐다고 하고, 누구는 성능에 변화가 없다고 하니, 사람마다 케이스 바이 케이스가 있는 것 같습니다.
대회와 관계없이 시도한 것들
- 현재 부스트캠프에서 만난 팀원들과 함께 KBO 챗봇 프로젝트를 하고 있습니다.
- 위에서도 언급했지만, 해당 Competition을 진행하는 것 보다는 해당 프로젝트를 진행하는 것이 더 좋을 것 같다고 판단했습니다.
- 그래서 이번 Competition과 병행하면서 다음과 같은 일을 처리했습니다.
Competition에 열심히 참여하지는 않았지만 놀지 않았다는 것을 보여주고자...
-
KBO Record Crawler : https://github.com/baseballChatbot7/KBO-Record-Crawler
A. KBO 기록 크롤러를 구현 후, 데이터를 수집했습니다.
B. 해당 데이터는 KBO 챗봇에 사용될 예정입니다. -
KBOBERT : https://github.com/baseballChatbot7/KBOBERT
A. 실습에 사용했던 BERT 학습 코드를 사용하면, KBO 도메인에 특화된 BERT를 만들 수 있지 않을까 생각했습니다. (GPU도 자유롭게 사용할 수 있으니까요.)
B. 그래서 실습 코드를 받자마자, KBO 관련 뉴스 크롤러를 구현 후 약 46,000건의 뉴스를 수집했습니다.
C. 테스트 차원에서 해당 데이터를 가지고 BERT를 학습시켜본 결과(10에포크, 약 20시간 학습), 야구 도메인에 대한 [MASK]를 잘 예측하는 것을 확인할 수 있었습니다.
D. 최종적으로는 다른 팀원이 수집 중인 나무위키 야구 관련 문서를 합쳐서 BERT를 학습시킬 예정입니다. -
MRC : 현재 테스트 중
A. 저희가 만들고자 하는 챗봇은 MRC 기반입니다.
B. MRC를 제대로 만들 수 있을까 하는 걱정이 있었지만, MRC 실습 코드를 통해서 이러한 부담을 줄일 수 있었습니다.
C. 다음 STAGE 3에서 MRC를 제대로 구현해볼 생각이지만, 여의치 않다면 해당 코드로 MRC를 만들어보려고 합니다.
- 이번 STAGE의 가장 큰 재산은 마스터 님의 실습 코드와 직접 시도해본 결과들입니다. 이대로라면 목표로 하고 있는 네트워킹 데이까지 프로토타입 개발이 가능 할 것 같습니다…
<학습과정에서의 교훈>
학습과 관련하여 개인과 동료로서 얻은 교훈
- 이번 Competition에서는 리더보드 보다는 토론에 더 많은 집중을 했습니다.
- 많은 분들이 읽어 주시고, 좋아해 주시고, 사용해 주셔서 뿌듯했습니다.
- 다음 Competition에서도 리더보드에 집중하지 않을 것이라면, 토론에 집중할 생각입니다.
피어세션을 진행하며 좋았던 부분과 동료로부터 배운 부분
- 이번 피어세션을 통해서 팀원으로 함께하고 싶은 사람을 만날 수 있었고, 이를 계기로 STAGE 3의 팀원으로 이어져서 좋았습니다.
<마주한 한계와 도전숙제>
아쉬웠던 점들
- Competition의 완성도가 낮아 몰입하기 어려웠던 점이 많이 아쉬웠습니다.
- Competition과는 별개로 개인적으로 시도와 도전을 해볼 수 있지 않았을까…? 하는 아쉬움이 남습니다.
한계/교훈을 바탕으로 다음 스테이지에서 새롭게 시도해볼 것
- 위에서 언급한 프로젝트를 위해 다음 스테이지에서는 성능이 좋은 MRC 개발에 힘을 쏟을 계획입니다.
마무리
오늘보다 더 성장한 내일의 저를 기대하며, 다음 주에 뵙도록 하겠습니다.
읽어주셔서 감사합니다!
