강의 복습 내용
[Day 39]
(8강) 양자화
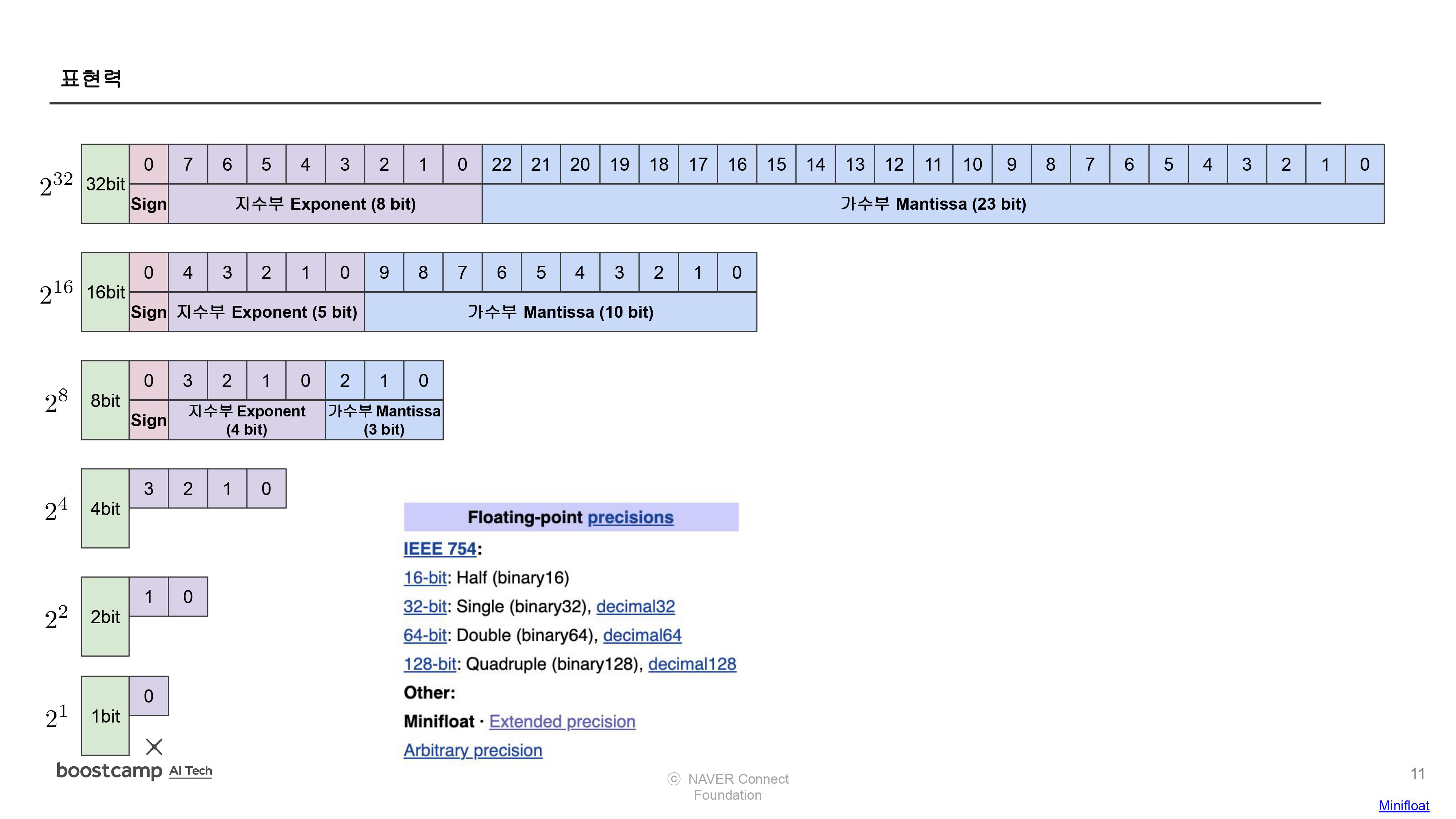
- Quantization
- Reduction in the model size.
- Reduction in memory bandwidth requirements.
- On-device int8 computations are faster compared to float32 (with FLU)
- Quantization is primarily a technique to speed up inference (only the forward pass is supported for quantized operators).
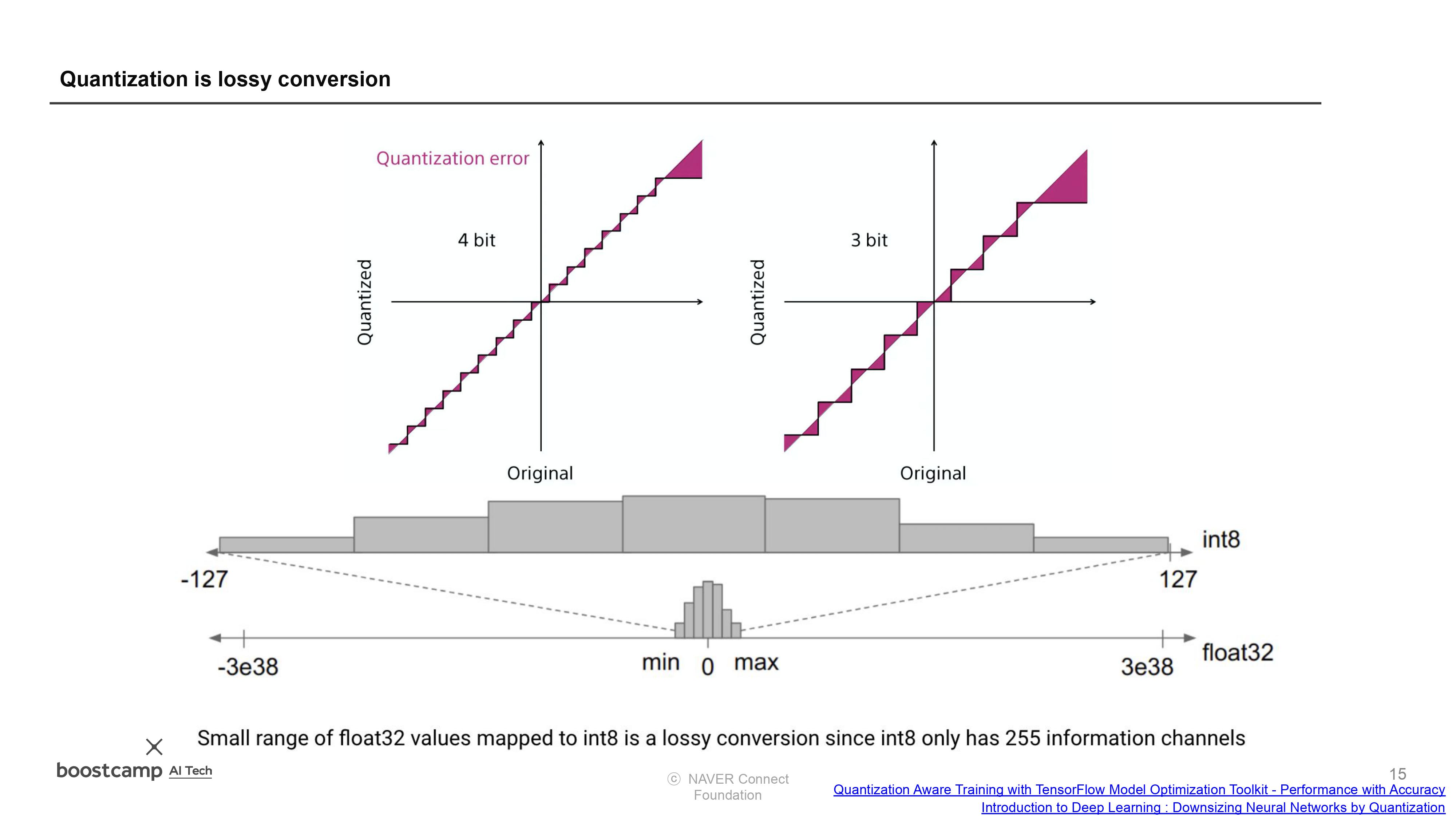
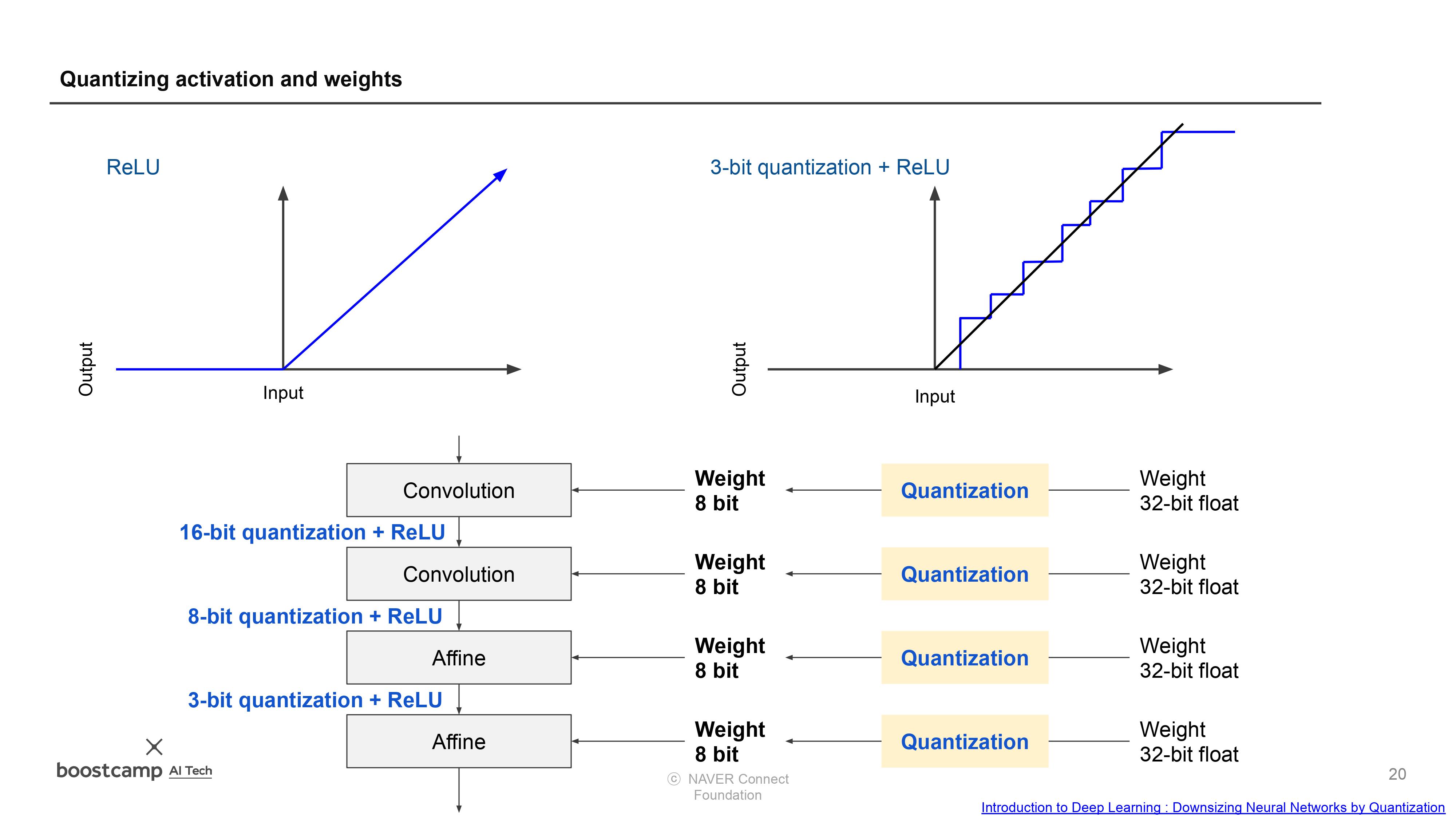

- Quantization의 종류
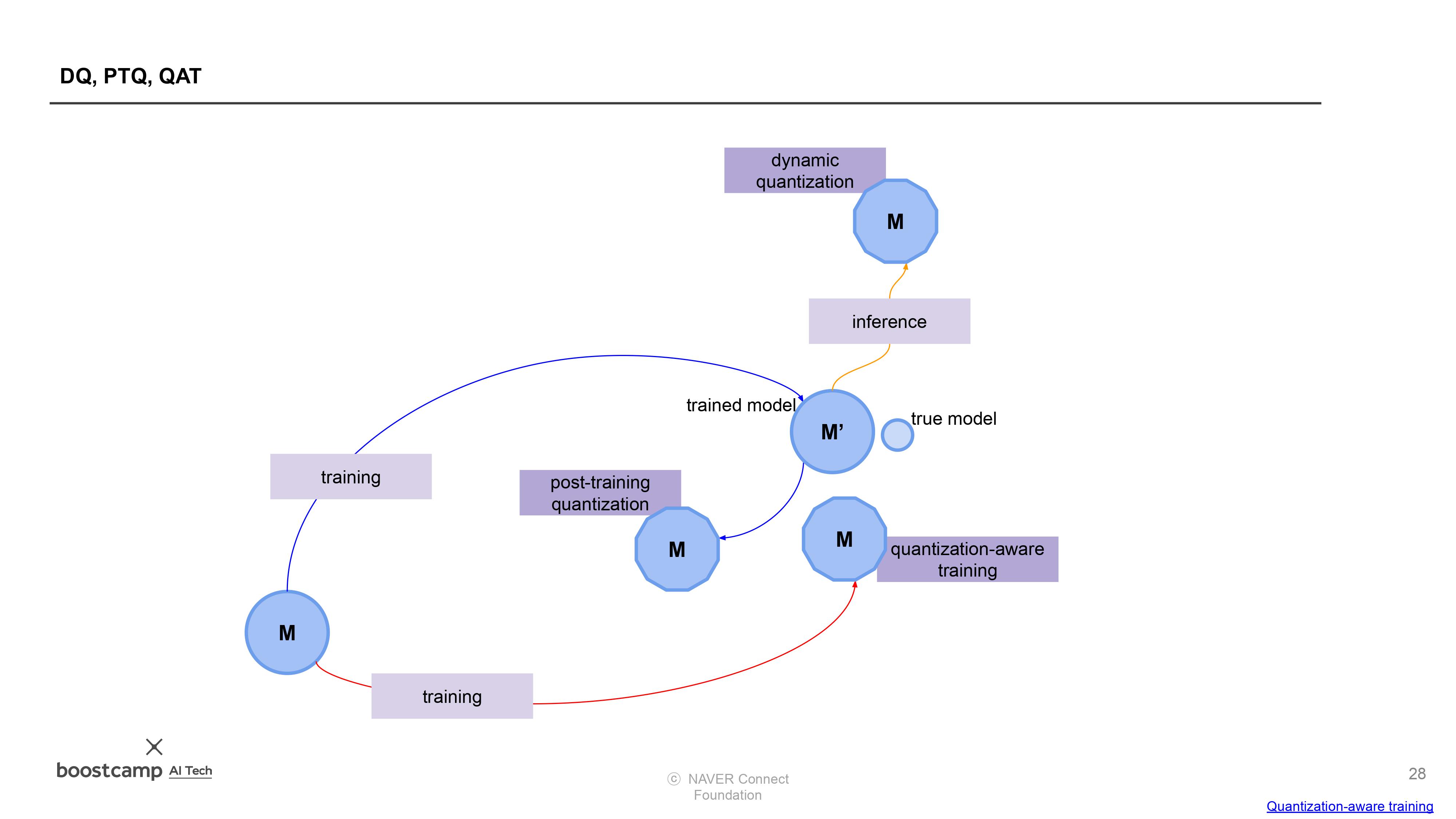
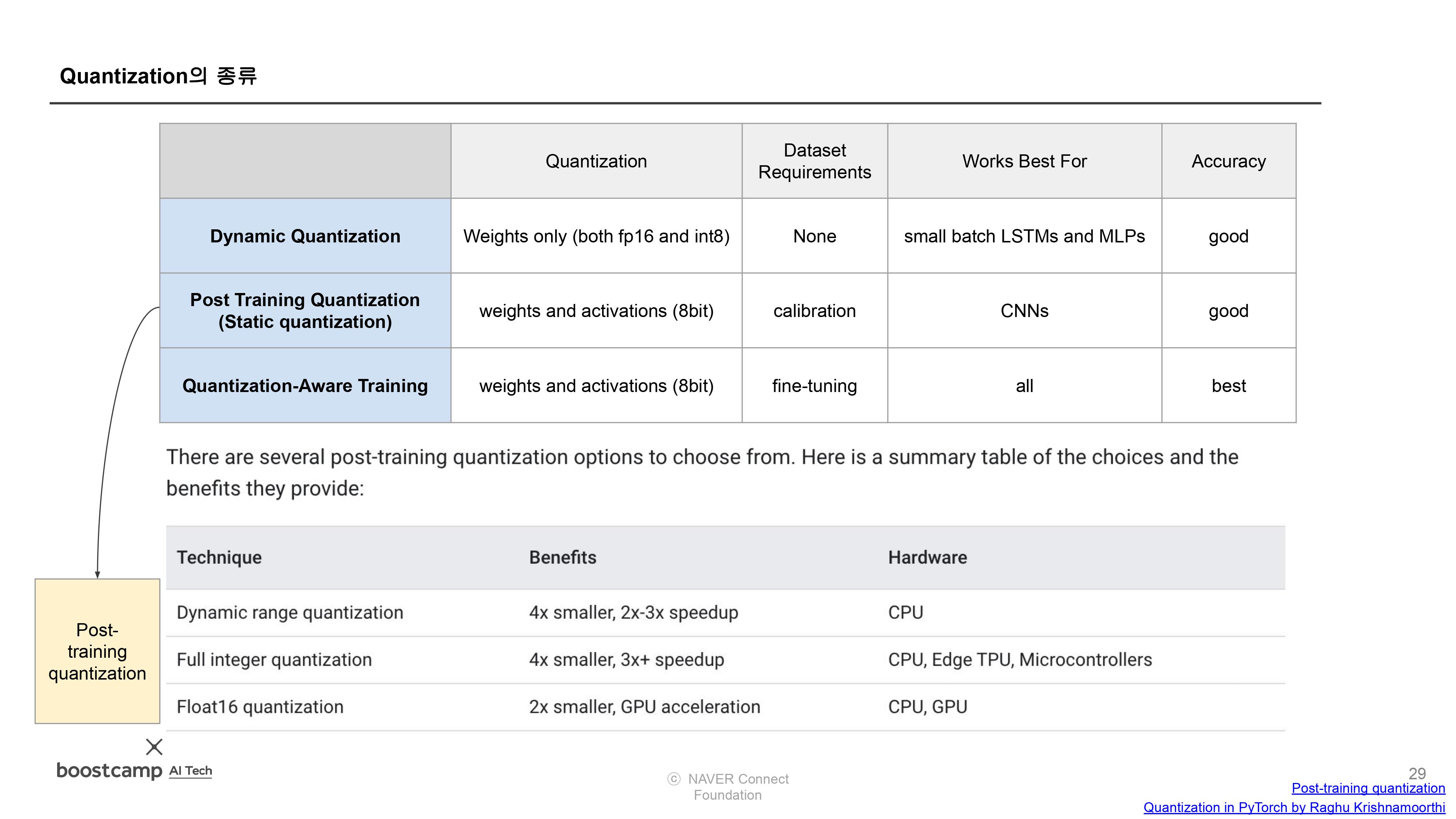
- Dynamic quantization (weights quantized with activations read/stored in floating point and quantized for compute.)
- This is the simplest to apply form of quantization where the weights are quantized ahead of time but the activations are dynamically quantized during inference. This is used for situations where the model execution time is dominated by loading weights from memory rather than computing the matrix multiplications. This is true for for LSTM and Transformer type models with small batch size.
- Static quantization (weights quantized, activations quantized, calibration required post training)
- Static quantization quantizes the weights and activations of the model. It fuses activations into preceding layers where possible. It requires calibration with a representative dataset to determine optimal quantization parameters for activations. Post Training Quantization is typically used when both memory bandwidth and compute savings are important with CNNs being a typical use case. Static quantization is also known as Post Training Quantization or PTQ.
- Quantization aware training (weights quantized, activations quantized, quantization numerics modeled during training)
- Quantization Aware Training models the effects of quantization during training allowing for higher accuracy compared to other quantization methods. During training, all calculations are done in floating point, with fake_quant modules modeling the effects of quantization by clamping and rounding to simulate the effects of INT8. After model conversion, weights and activations are quantized, and activations are fused into the preceding layer where possible. It is commonly used with CNNs and yields a higher accuracy compared to static quantization. Quantization Aware Training is also known as QAT.
- Dynamic quantization (weights quantized with activations read/stored in floating point and quantized for compute.)
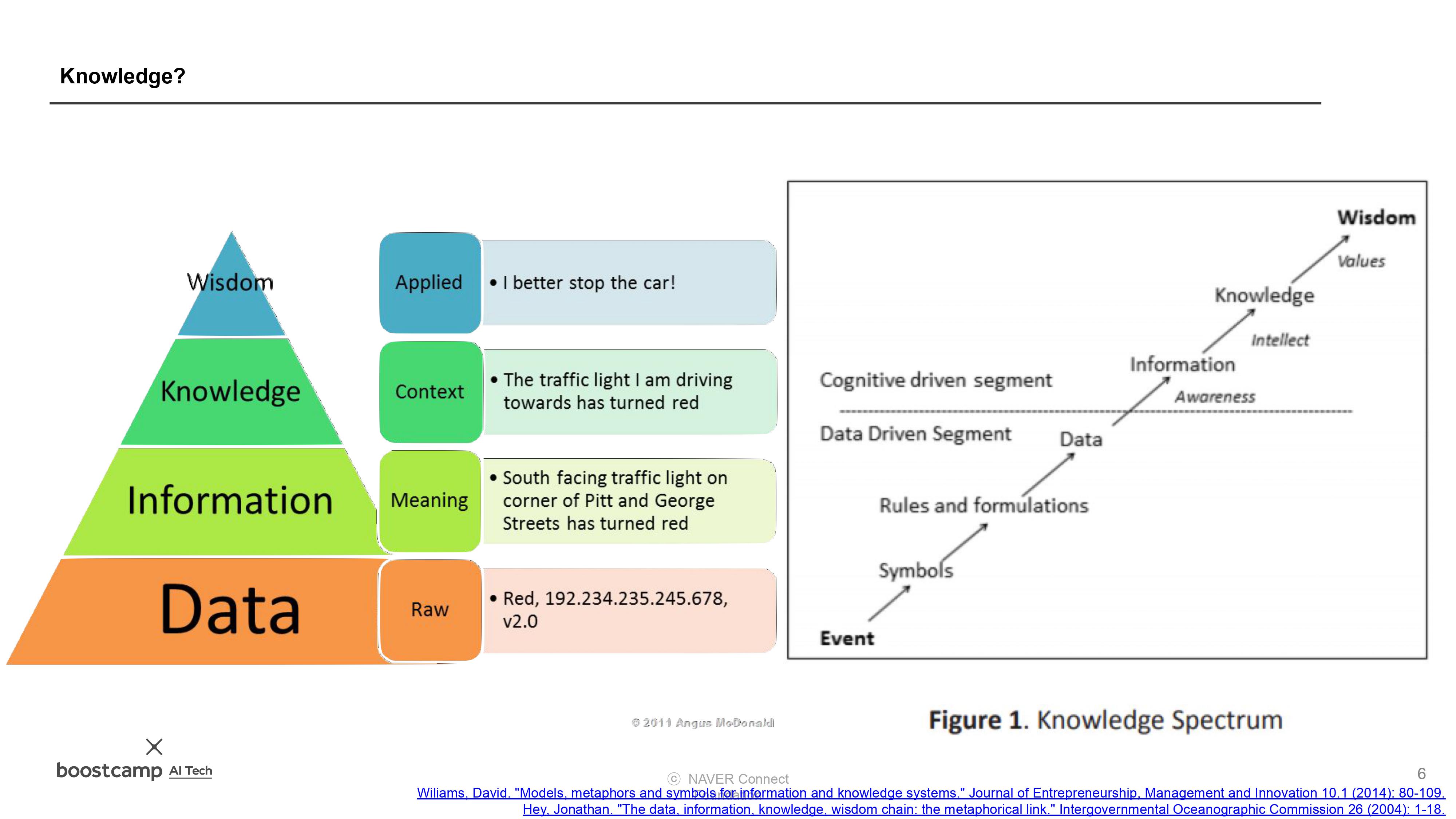
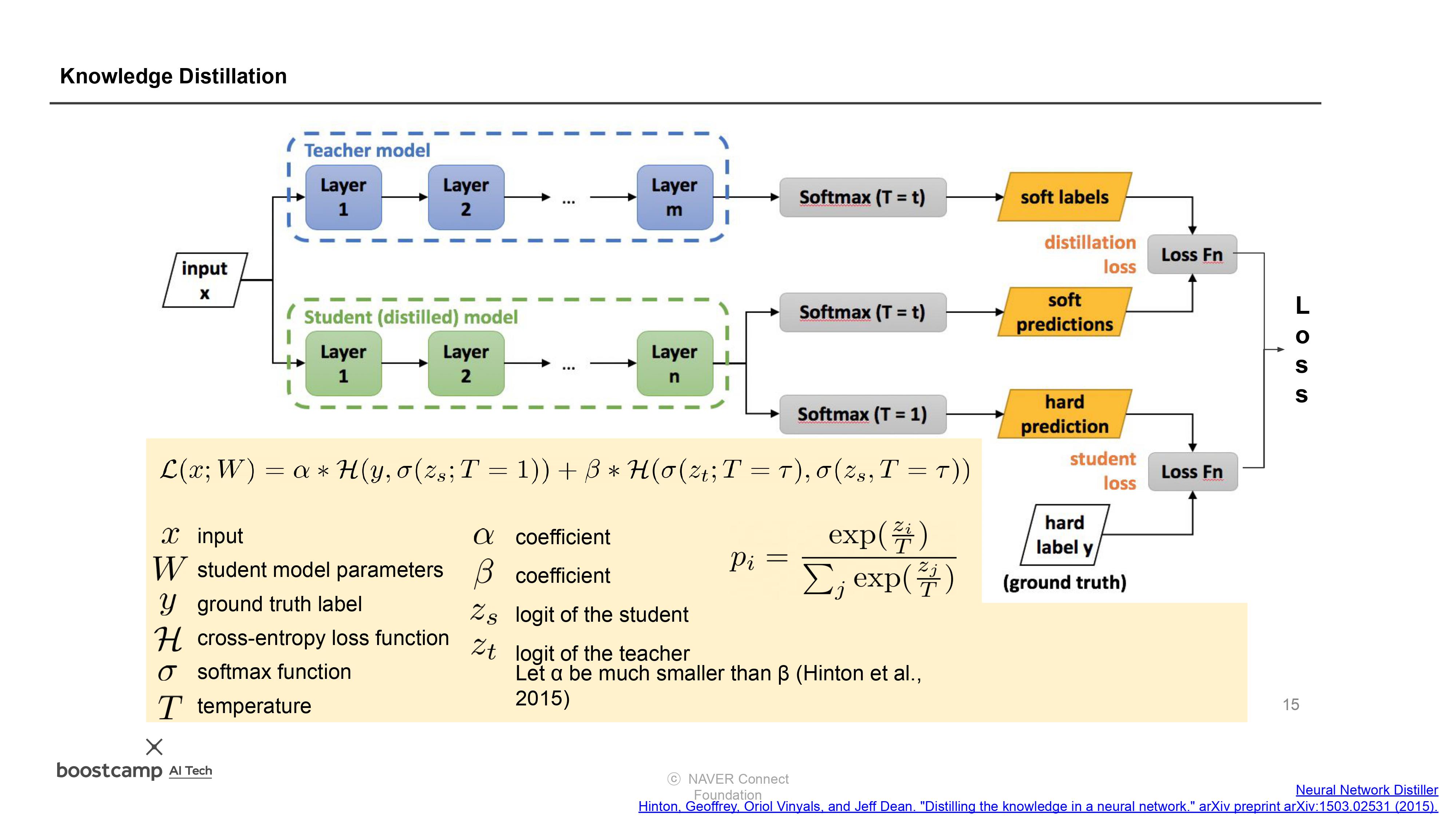
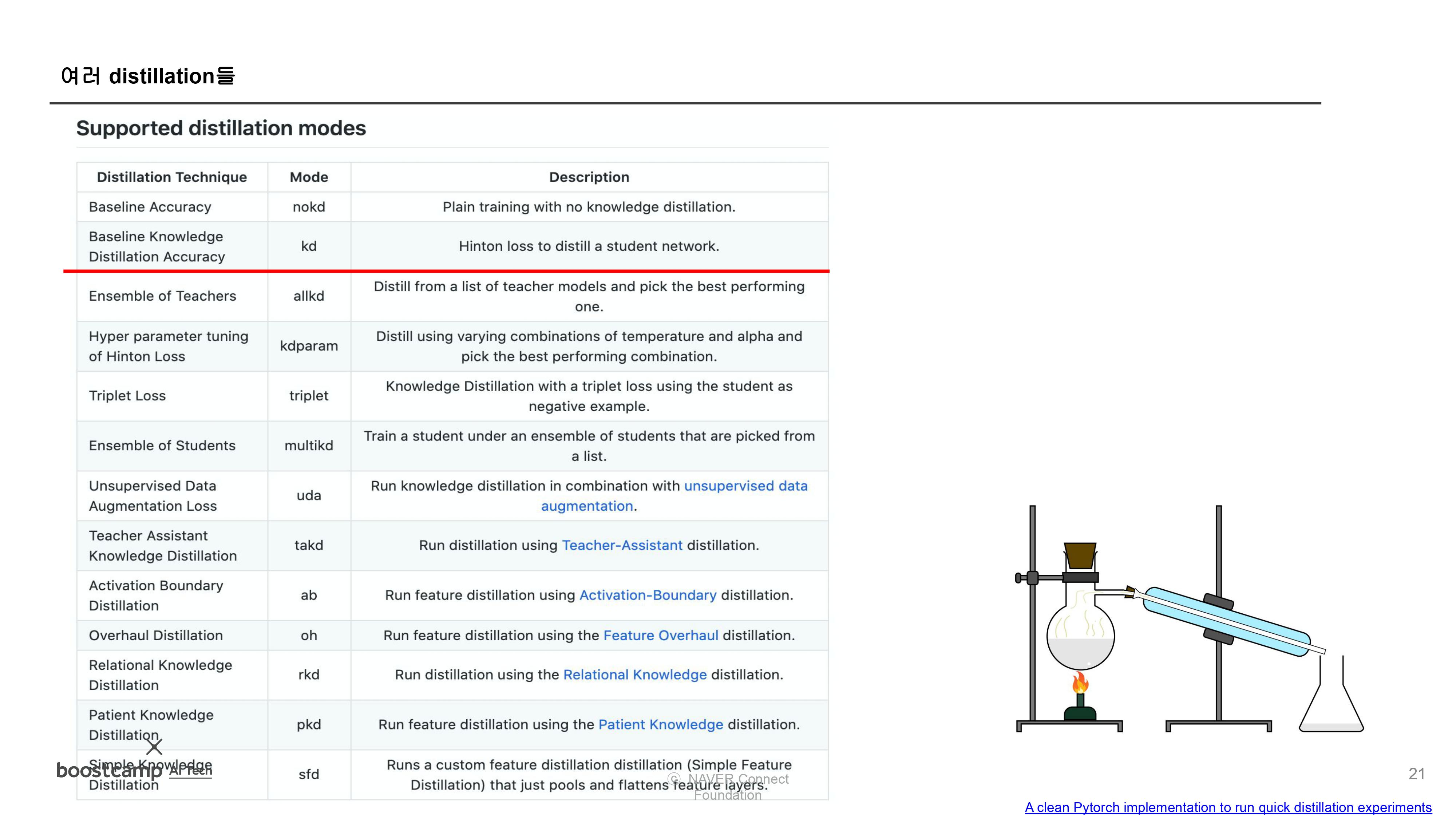
(9강) 지식 증류


Further Question
(8강) 양자화
1) 이 에러를 보정하려면 어떻게 하면 좋을까?
- decimal.Decimal, math.fsum(), round(), float.as_integer_ratio(), math.is_close() 함수 혹은 다른 방법을 통해서 실수를 방지할 수 있다.
2) Dynamic quantization을 하는 이유는 무엇일까?
- 동적 양자화 기능은 부동소수점 모델의 가중치를 정적인 int8 또는 float16 타입의 양자화된 모델로 변환하기 위해서 이다.
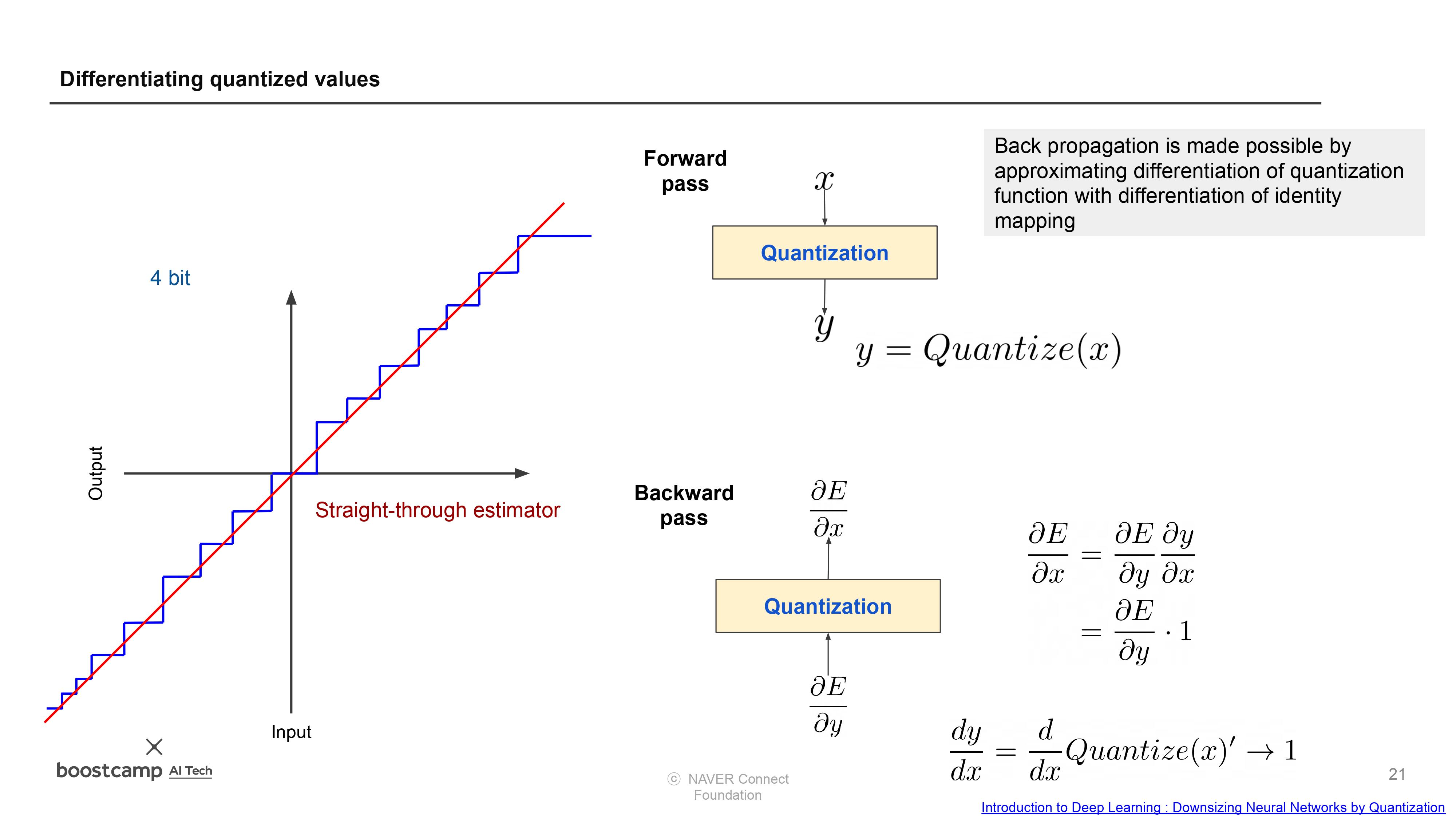
3) 이 히스토그램은 어떤 의미가 있을지 적어보자
- 양자화를 통해서 간단하게 표현된다는 것을 시각적으로 확인할 수 있다.
(9강) 지식 증류
1) Asterisk(*)의 용도는?
- Unpacking
2) zero-mean assumption이 참이 아닐 때 Knowledge distillation은 어떤 쓸모가 있을까?
- Teacher와 Student가 같아지도록 학습할 수 없기 때문에, 쓸모없을 것이다.
3) 하나의 Loss에서 KL과 CE를 섞어쓴 이유는?
- 더 안정적으로 optimization을 하기 위해서 하나의 Loss에서 KL과 CE를 섞어 사용했다.
피어 세션 정리
강의 리뷰 및 Q&A
- (8강) 양자화
- (9강) 지식 증류
과제 진행 상황 정리 & 과제 결과물에 대한 정리
[과제#3/3] 지식증류방법을 활용한 학습
Kd Loss 정의하기

총평
지난주에 배웠던 Knowledge distillation을 모델 경량화를 위한 방법으로 사용한다는 것이 너무 신기했습니다.
이를 보면서 GAN과 유사하게 학습하는 모델 경량화 방법 같다고 생각했습니다.
그것 이외에도 오늘 강의와 Further Question에서 배울 거리, 생각할 거리가 많아 만족스러웠습니다.
오늘보다 더 성장한 내일의 저를 기대하며, 내일 뵙도록 하겠습니다.
읽어주셔서 감사합니다!

PLUS ULTRA