Spring Batch란?
Spring Batch는 로깅/추적, 트랜잭션 관리, 작업 처리 통계, 작업 재시작, 건너뛰기, 리소스 관리 등 대용량 레코드 처리에 필수적인 기능을 제공한다. 또한 최적화 및 파티셔닝 기술을 통해 대용량 및 고성능 배치 작업을 가능하게 하는 고급 기술 서비스 및 기능을 제공한다.
Spring Batch에서 배치가 실패하여 작업을 재시작을 하게 된다면 처음부터가 아닌 실패한 지점부터 실행을 하게된다. 또한 중복 실행을 막기 위해 성공한 이력이 있는 Batch는 동일한 Parameter로 실행 시 Exception이 발생하게 된다.
Spring Batch는 Scheduler?
Spring Batch는 Batch Job을 관리하지만 Job을 구동하거나 실행시키는 기능은 지원하고 있지 않습니다. Spring에서 Batch Job을 실행시키기 위해서는 Quartz, Scheduler, Jenkins 등 전용 Scheduler를 사용해야 합니다.
Spring Batch의 용어
Job
Job은 배치처리 과정을 하나의 단위로 만들어 놓은 객체이다. 또한 배치처리 과정에 있어 전체 계층 최상단에 위치하고 있다.
Job Instance
JobInstance는 Job의 실행의 단위를 나타낸다. Job을 실행시키게 되면 하나의 JobInstance가 생성되게 된다. 예를 들어 1월 1일 실행 / 1월 2일 실행을 하게 됐을 때 각각의 JobInstance가 생성되며 1월 1일 실행한 JobInstance가 실패하여 다시 실행시키더라도 이 JobInstance는 1월 1일에 대한 데이터만 처리하게 된다.
Job Parameters
JobInstance는 Job의 실행 단위라면 JobInstance들을 구별하는 것은 바로 JobParameters 객체로 구분을 하게 된다. JobInstance 구별 외에도 개발자 JobInstance에 전달되는 매개변수의 역할도 하고 있다. 또한 JobParameters는 String, Double, Long, Date 4가지의 형식만을 지원한다.
Job Execution
JobExcution은 JobInstance에 대한 실행 시도에 대한 객체이다. 1월 1일에 실행한 JobInstance가 실패하여 재실행을 하여도 동일한 JobInstance를 실행시키지만 이 2번의 실행에 대한 JobExecution은 개별로 생기게 된다. JobExecution은 이러한 JobInstance 실행에 대한 상태, 시작시간, 종료시간, 생성시간 등의 정보를 담고있다.
Step
Step은 Job의 배치처리를 정의하고 순차적인 단계를 캡슐화한다. Job은 최소한 1개 이상의 Step을 가져야 하며, Job의 실제 일괄 처리를 제어하는 모든 정보가 들어있다.
Step Execution
StepExecution은 JobExecution과 동일하게 Step 실행 시도에 대한 객체를 나타낸다. 하지만 Job이 여러개의 Step으로 구성되어 있을 경우 이전 단계의 Step이 실패하게 되면 다음 단계가 실행되지 않음으로 실패 이후 StepExecution은 생성되지 않는다. StepExecution 또한 JobExecution과 동일하게 실제 시작이 될 때만 생성된다. StepExecution에는 JobExecution에 저장되는 정보 외에 read 수, write 수, commit 수, skip 수 등의 정보들도 저장이 된다.
Execution Context
ExecutionContext란 Job에서 데이터를 공유 할 수 있는 데이터 저장소이다. Spring Batch에서 제공하는 ExecutionContext는 JobExecutionContext, StepExecutionContext 2가지 종류가 있으나 이 두가지는 지정되는 범위가 다르다. JobExecutionContext의 경우 Commit 시점에 저장되는 반면 StepExecutionContext는 실행 사이에 저장이 되게 된다. ExecutionContext를 통해 Step간의 Data 공유가 가능하며 Job 실패 시 ExcutionContext를 통한 마지막 실행 값을 재구성할 수 있다.
Job Repository
JobRepository는 위에서 말한 모든 배치 처리 정보를 담고있는 매커니즘이다. Job이 실행되면 JobRepository에 JobExecution과 StepExecution을 생성하게 되며 JobRepository에서 Execution 정보들을 저장하고 조회하며 사용하게 된다.
Job Launcher
JobLauncher는 Job과 JobParameters를 사용하여 Job을 실행하는 객체이다.
Item Reader
ItemReader는 Step에서 Item을 읽어오는 인터페이스이다. ItemReader에 대한 다양한 인터페이스가 존재하며 다양한 방법으로 Item을 읽어 올 수 있다.
Item Writer
ItemWriter는 처리 된 Data를 Writer 할 때 사용한다. Writer는 처리 결과물에 따라 Insert가 될 수도, Update가 될수도, Queue를 사용한다면 Send가 될 수도 있다. Writer 또한 Read와 동일하게 다양한 인터페이스가 존재한다. Writer는 기본적으로 Item을 Chunk로 묶어 처리하고 있다.
Item Processor
Item Processor는 Reader에서 읽어온 Item을 데이터를 처리하는 역할을 하고 있다. Processor는 배치를 처리하는데 필수 요소는 아니며 Reader, Writer, Processor처리를 분산하여 각각의 역할을 명확하게 구분한다.
Chunk
Chunk란 데이터 덩어리로 작업 할 때 각 커밋 사이에 처리되는 row 수를 얘기한다.
Chunk 지향처리
Chunk 지향 처리란 한 번에 하나씩 데이터를 읽어 Chunk라는 덩어리를 만든 뒤, Chunk 단위로 트랜잭션을 다루는 것을 의미합니다.
Chunk 단위로 트랜잭션을 수행하기 때문에 실패할 경우엔 해당 Chunk 만큼만 롤백이 되고, 이전에 커밋된 트랜잭션 범위까지 반영이 된다.
Tasklet
Tasklet은 하나의 메서드로 구성 되어있는 간단한 인터페이스이다. 이 메서드는 실패를 알리기 위해 예외를 반환 하거나 throw할 때까지 execute를 반복적으로 호출하게 된다.
Spring Batch 예제 연습
Simple Job 생성
Batch Job 만들기 전에 SpringBatchTestApplication 클래스에 Spring Batch 기능 활성화 어노테이션인 @EnableBatchProcessing 어노테이션을 추가합니다.
설정완료 후 job 패키지를 생성하고, 하위에 SimpleJobConfiguration 클래스를 생성한다.
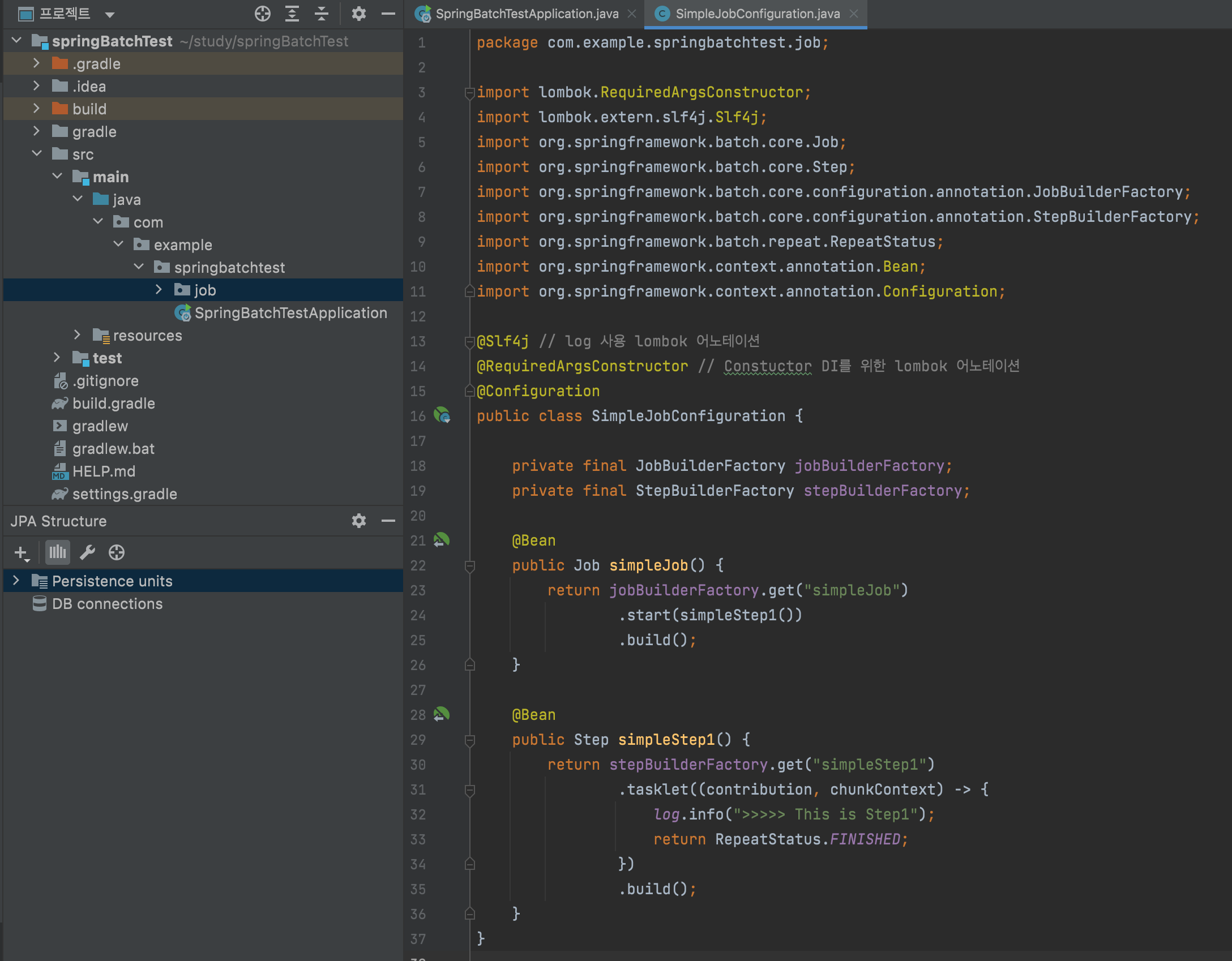
@Slf4j // log 사용 lombok 어노테이션
@RequiredArgsConstructor // Constuctor DI를 위한 lombok 어노테이션
@Configuration
public class SimpleJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
@Bean
public Job simpleJob() {
return jobBuilderFactory.get("simpleJob")
.start(simpleStep1())
.build();
}
@Bean
public Step simpleStep1() {
return stepBuilderFactory.get("simpleStep1")
.tasklet((contribution, chunkContext) -> {
log.info(">>>>> This is Step1");
return RepeatStatus.FINISHED;
})
.build();
}
}-
@Configuration- Spring Batch의 모든 Job은
@Configuration으로 등록해서 사용한다.
- Spring Batch의 모든 Job은
-
jobBuilderFactory.get("simpleJob")simpleJob이란 이름의 Batch Job을 생성한다.- job의 이름은 별도로 지정하지 않고 이렇게 Builder를 통해 지정한다.
-
stepBuilderFactory.get("simpleStep1")simpleStep1이란 이름의 Batch Step을 생성한다.jobBuilderFactory.get("simpleJon")와 마찬가지로 Builder를 통해 이름을 지정한다.
-
tasklet((contibution, chunkContext) -> {})- Step안에서 수행될 기능들을 명시한다.
- Tasklet은 Step안에서 단일로 수행될 커스텀한 기능들을 선언할 때 사용한다.
- 여기서는 Batch가 수행되면
log.info(">>>>> This is Step1")가 출력되도록 한다.
Batch Job을 생성하는 simpleJob은 simpleStep1을 품고있다.
Spring Batch에서 Job은 하나의 배치 작업 단위를 말한다. Job안에서는 이처럼 여러 Step이 존재하고, Step 안에는 Tasklet 혹은 Reader & Processor & Writer 묶음이 존재한다.
Step에서 Tasklet 하나와 Reader & Processor & Writer 한 묶음은 같은 레벨이다.
그래서 Reader & Processor가 끝나고 Tasklet으로 마무리 짓는 것과 같은 Step은 만들 수 없습니다.
main 메서드 실행
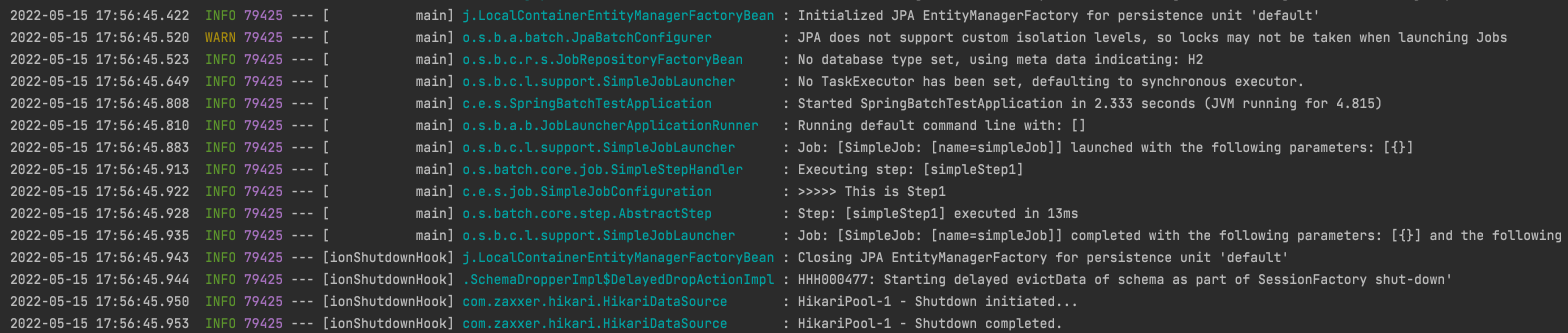
>>>>> This is Step1 로그가 잘나오는걸 확인할 수 있다.
Mysql 환경에서 Spring Batch 실행
Spring batch에서는 메타 데이터 테이블이 필요하다.
메타 데이터란 데이터를 설명하는 데이터라고 생각하면 된다.
Spring Batch의 메타 데이터는 다음과 같은 내용을 포함한다.
- 이전에 실행한 Job이 어떤 것들이 있는지
- 최근에 실패한 Batch Parameter가 어떤 것들이 있고, 성공한 Job은 어떤 것들이 있는지
- 다시 실행하면 어디서부터 시작해야 할지
- 어떤 Job에 Step들이 있었고, Step들 중 성공한 Step과 실패한 Step들은 어떤 것들이 있는지
메타 데이터 테이블이 있어야 Spring Batch가 정상 작동을 한다.
기본적으로 H2 DB를 사용할 경우 해당 테이블을 Spring Boot가 실행될 때 자동으로 생성해주지만 MySQL이나 Oracle과 같은 DB는 해당 테이블을 개발자가 직접 생성해야한다.
메타데이터 스키마는 Spring Batch에 존재하고, 이를 복사해서 그대로 Create 해주면 된다.
mysql 메타 데이터 테이블 생성 쿼리
-- Autogenerated: do not edit this file
CREATE TABLE BATCH_JOB_INSTANCE (
JOB_INSTANCE_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT ,
JOB_NAME VARCHAR(100) NOT NULL,
JOB_KEY VARCHAR(32) NOT NULL,
constraint JOB_INST_UN unique (JOB_NAME, JOB_KEY)
) ENGINE=InnoDB;
CREATE TABLE BATCH_JOB_EXECUTION (
JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT ,
JOB_INSTANCE_ID BIGINT NOT NULL,
CREATE_TIME DATETIME(6) NOT NULL,
START_TIME DATETIME(6) DEFAULT NULL ,
END_TIME DATETIME(6) DEFAULT NULL ,
STATUS VARCHAR(10) ,
EXIT_CODE VARCHAR(2500) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED DATETIME(6),
JOB_CONFIGURATION_LOCATION VARCHAR(2500) NULL,
constraint JOB_INST_EXEC_FK foreign key (JOB_INSTANCE_ID)
references BATCH_JOB_INSTANCE(JOB_INSTANCE_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_JOB_EXECUTION_PARAMS (
JOB_EXECUTION_ID BIGINT NOT NULL ,
TYPE_CD VARCHAR(6) NOT NULL ,
KEY_NAME VARCHAR(100) NOT NULL ,
STRING_VAL VARCHAR(250) ,
DATE_VAL DATETIME(6) DEFAULT NULL ,
LONG_VAL BIGINT ,
DOUBLE_VAL DOUBLE PRECISION ,
IDENTIFYING CHAR(1) NOT NULL ,
constraint JOB_EXEC_PARAMS_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_STEP_EXECUTION (
STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT NOT NULL,
STEP_NAME VARCHAR(100) NOT NULL,
JOB_EXECUTION_ID BIGINT NOT NULL,
START_TIME DATETIME(6) NOT NULL ,
END_TIME DATETIME(6) DEFAULT NULL ,
STATUS VARCHAR(10) ,
COMMIT_COUNT BIGINT ,
READ_COUNT BIGINT ,
FILTER_COUNT BIGINT ,
WRITE_COUNT BIGINT ,
READ_SKIP_COUNT BIGINT ,
WRITE_SKIP_COUNT BIGINT ,
PROCESS_SKIP_COUNT BIGINT ,
ROLLBACK_COUNT BIGINT ,
EXIT_CODE VARCHAR(2500) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED DATETIME(6),
constraint JOB_EXEC_STEP_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_STEP_EXECUTION_CONTEXT (
STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT TEXT ,
constraint STEP_EXEC_CTX_FK foreign key (STEP_EXECUTION_ID)
references BATCH_STEP_EXECUTION(STEP_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_JOB_EXECUTION_CONTEXT (
JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT TEXT ,
constraint JOB_EXEC_CTX_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_STEP_EXECUTION_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_STEP_EXECUTION_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_STEP_EXECUTION_SEQ);
CREATE TABLE BATCH_JOB_EXECUTION_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_JOB_EXECUTION_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_JOB_EXECUTION_SEQ);
CREATE TABLE BATCH_JOB_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_JOB_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_JOB_SEQ);다중 Step 구성하기
@Slf4j // log 사용 lombok 어노테이션
@RequiredArgsConstructor // Constuctor DI를 위한 lombok 어노테이션
@Configuration
public class SimpleJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
@Bean
public Job exampleJob() {
return jobBuilderFactory.get("exampleJob")
.start(startStep())
.next(nextStep())
.next(lastStep())
.build();
}
@Bean
public Step startStep() {
return stepBuilderFactory.get("simpleStep1")
.tasklet((contribution, chunkContext) -> {
log.info("Start Step!");
return RepeatStatus.FINISHED;
})
.build();
}
@Bean
public Step nextStep() {
return stepBuilderFactory.get("startStep")
.tasklet((contribution, chunkContext) -> {
log.info("Next Step!");
return RepeatStatus.FINISHED;
})
.build();
}
@Bean
public Step lastStep() {
return stepBuilderFactory.get("lastStep")
.tasklet((contribution, chunkContext) -> {
log.info("Last Step!");
return RepeatStatus.FINISHED;
})
.build();
}
}실행 결과
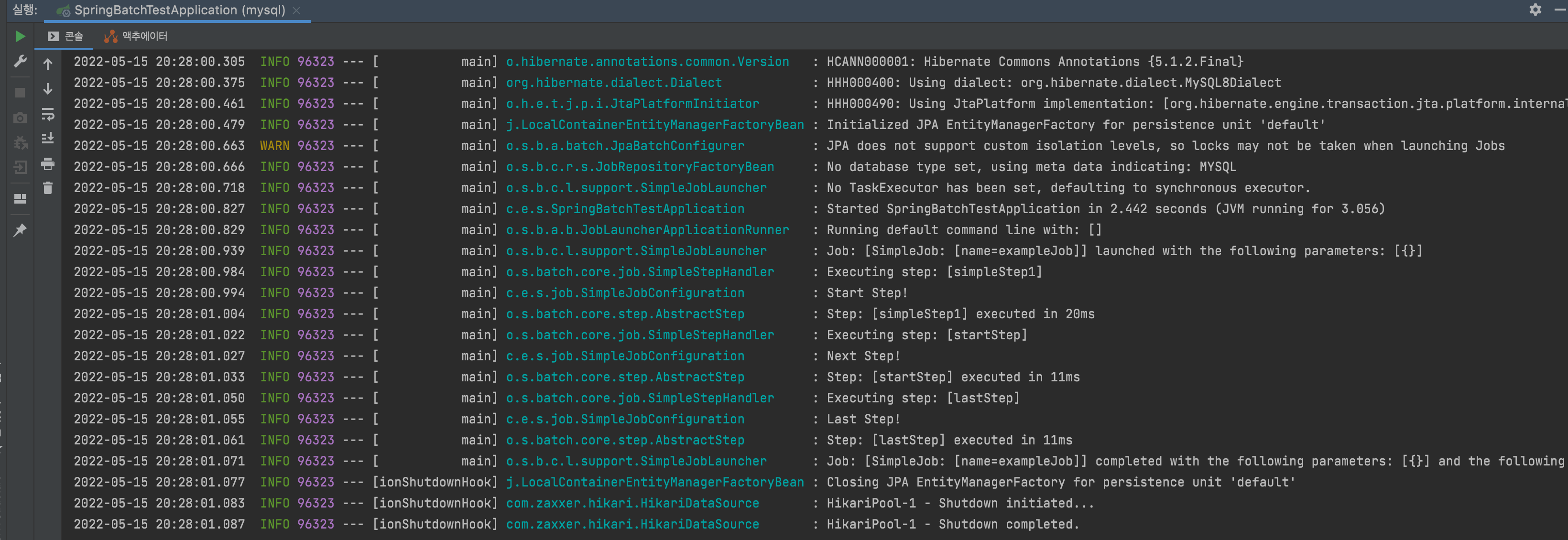
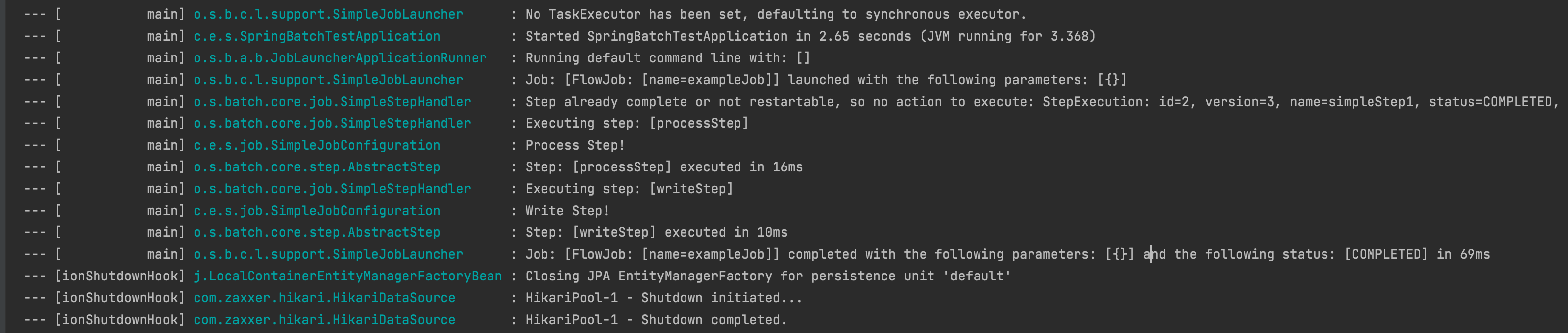
Flow를 통한 Step 구성
@Slf4j // log 사용 lombok 어노테이션
@RequiredArgsConstructor // Constuctor DI를 위한 lombok 어노테이션
@Configuration
public class SimpleJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
@Bean
public Job exampleJob() {
Job exampleJob = jobBuilderFactory.get("exampleJob")
.start(startStep())
.on("FAILED") // startStep의 ExitStatus가 FAILED일 경우
.to(failOverStep()) // failOverStep을 실행시킨다.
.on("*") // failOverStep의 결과와 상관없이
.to(writeStep()) // writeStep을 실행 시킨다.
.on("*") // writeStep의 결과와 상관없이
.end()
.from(startStep()) // startStep이 FAILED가 아니고
.on("COMPLETED") // COMPLETED일 경우
.to(processStep()) // process Step을 실행
.on("*") // process Step의 결과와 상관없이
.to(writeStep()) // write Step을 실행
.on("*") // write Step의 결과와 상관없이
.end() // flow를 종료
.from(startStep()) // startStep의 결과가 FAILED, COMPLETED가 아닌
.on("*") // 모든 경우
.to(writeStep()) // write Step을 실행
.on("*") // write Step의 결과와 상관없이
.end() // Flow를 종료
.end()
.build();
return exampleJob;
}
@Bean
public Step startStep() {
return stepBuilderFactory.get("simpleStep1")
.tasklet((contribution, chunkContext) -> {
log.info("Start Step!");
String result = "COMPLETED";
// String result = "FAIL";
// String result = "UNKNOWN";
// Flow에서 on은 RepeatStatus가 아닌 ExitStaus를 바라본다.
if(result.equals("COMPLETED")) contribution.setExitStatus(ExitStatus.COMPLETED);
else if(result.equals("FAIL")) contribution.setExitStatus(ExitStatus.FAILED);
else if(result.equals("UNKNOWN")) contribution.setExitStatus(ExitStatus.UNKNOWN);
return RepeatStatus.FINISHED;
})
.build();
}
@Bean
public Step failOverStep() {
return stepBuilderFactory.get("failOverStep")
.tasklet((contribution, chunkContext) -> {
log.info("FailOver Step!");
return RepeatStatus.FINISHED;
})
.build();
}
@Bean
public Step processStep() {
return stepBuilderFactory.get("processStep")
.tasklet((contribution, chunkContext) -> {
log.info("Process Step!");
return RepeatStatus.FINISHED;
})
.build();
}
@Bean
public Step writeStep() {
return stepBuilderFactory.get("writeStep")
.tasklet((contribution, chunkContext) -> {
log.info("Write Step!");
return RepeatStatus.FINISHED;
})
.build();
}실행 결과