대량의 데이터를 가지고 무한 스크롤을 구현 시 고려해야 할 점
대량의 데이터를 가지고 무한 스크롤을 구현할 때 가장 중요하게 고려해야 할 점은 성능과 로딩 속도 있다. 한 번에 로드 되는 아이템의 개수를 적절할게 조절하여 디바이스 및 네트워크 부하의 증가를 막고, 다음 페이지의 데이터를 미리 로딩하여 사용자가 페이지를 끝까지 스크롤 했을 때 즉시 데이터가 표시될 수 있도록 해야 한다. 또한 로드 된 아이템들이 메모리에 계속 쌓이지 않도록 스크롤 위치에 따라 로드 된 데이터 중 일부를 해제하여 메모리 사용량을 최적화할 필요도 있다.
이 외에도 스크롤을 내리는 동안 사용자가 원활하게 데이터를 탐색할 수 있도록 부드러운 스크롤링과 함께 스크롤이 진행되고 있다는 시각적인 피드백을 제공하고, 데이터가 로딩중인지, 마지막 페이지인지 등을 나타내는 UI요소를 제공하여 사용자 경험을 개선할 수 있다.
프로세스의 생명주기
1. 프로그램과 프로세스
- 프로그램이 저장되어 있는 곳: 보조 기억장치
- 프로그램이 로딩되는 곳: 주 기억장치
- 프로그램이 실행되는 주체: 프로세스
- 작업을 처리하는 주체: 쓰레드
2. 프로세스 상태변화
- 스케쥴링 알고리즘에 따라 프로세스들은 상태변화가 일어나며 준비/수행 상태일 때 CPU를 사용하게 된다.
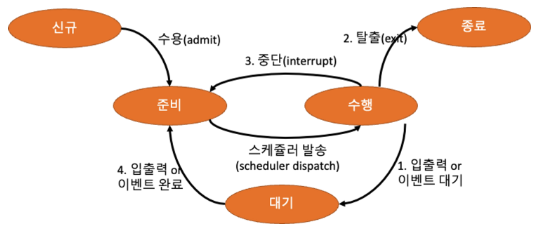
3. 프로세스 생명주기
-
신규(New)
- 프로세스가 막 메인 메모리에 올라온 상태
- 아직 실행하는 것은 불가능
- 수용 동작을 거쳐야 준비 단계로 넘어 감
-
준비(Ready)
- 변수 초기화 등 기초 준비 작업을 모두 끝내고 실행을 할 수 있는 상태
- 스케쥴러를 통해 발송 되어야 수행 상태가 됨
- 신규 프로세스 수용 / 대기 프로세스의 입출력 및 이벤트가 완료 / 수행 프로세스 중단(: 선점 스케쥴링에 의해 OS가 프로세스의 상태를 중단 상태로 강제로 변환하여 CPU를 회수)과 같은 케이스를 통해 준비 상태가 된다.
-
수행(Running)
- CPU가 실제로 프로세스를 수행하고 있는 상태
- 선점 스케쥴링에 의해 중단되면 준비 상태
- 입출력 및 이벤트가 필요하면 대기 상태
- 수행이 완료되면 종료 상태
- 준비 프로세스가 스케쥴러를 통해 발송될 때 수행 상태가 됨
-
대기(Wating)
- 프로세스 도중에 I/O 작업이 필요하여 I/O 작업을 수행하는 상태
- 이때 CPU는 I/O를 기다리며 다른 프로세스를 수행
- 대기 상태가 끝나면 프로세스는 다시 준비 상태가 되고, 잠시후 다시 수행 상태가 됨
-
종료(Terminated)
- 최종적으로 프로세스가 종료된 상태
- 사용하던 메모리 영역이 해제
