
1. 다시 보니 반가운 SQL!

전직장에서 개발자분들이 오라클로 DB를 확인하시거나, 수정할 때 늘 SELETE 로 시작하는걸 보곤 했는데 그 쿼리를 오늘 딱! 배워서 무척 반가웠다. 그동안 어깨넘어서 보았던 것들이 이런 의미였다니.. 무슨 의미인지는 전혀 몰랐지만 거의 2년동안 어깨넘어 보던 것들이라 빨리 이해가 되었다.
거기에 어려운 node에 허우적대고 있다가 SQL하니까 머리가 싹~ 정리되고 업되는 기분이었다. 다음 수업에 다시 node 들어간다는데.. 두렵다...😥
2. DB
1) 정의
DataBase의 약자로, 다양한 카테고리의 정보를 저장할 수 있는 구조다. 여러 사람에 의해 공유되어 사용될 목적으로 통합해 관리되는 데이터의 집합이다.
즉, 데이터를 저장하는 구조/자료의 모음이다.
💡 파일 시스템 VS 데이터베이스
- 파일 시스템 : 데이터를 기록하고 여러 사람이 공유하여 사용 가능하다.
ex) Microsoft Excel 프로그램으로 데이터 관리
- 단점
- 데이터 중복이 생길 수 있다. -> 저장공간 낭비
- 데이터 공유에 있어 제한이 존재한다.
- 데이터가 불일치할 수 있다.
- 구현과 유지보수에 시간이 많이 소요된다.
위 같은 파일 시스템의 단점을 개선하기 위해 데이터베이스가 등장했다.
① 용어
-
데이터베이스 구조
- 열 (Column, Attribute, 속성)
- 행 (Record, Tuple, 튜플)
- 테이블 (Table, Relation)
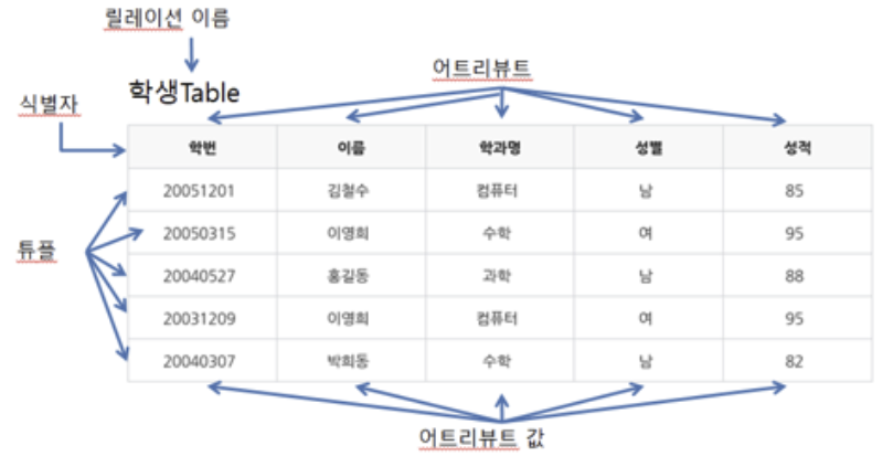
-
키 (Key) : 데이터베이스에서 튜플을 찾거나 순서대로 정렬할 때 구분하고 정렬의 기준이 되는 속성이다.
-
기본키 (PK, Primary Key) : 메인 키이며, RDBMS에서 테이블의 특정 튜플을 고유하게 식별하는 데 사용되는 키다.
기본키가 가능한 후보가 하나인 경우, 그 키 사용를 사용하며, 기본키가 가능한 속성이 여러 개라면, 테이블 특성 반영해 하나를 선택한다.- 기본키 선정시 고려사항
- 테이블 내 튜플을 식별할 수 있는 고유한 값을 가져야 한다.
- NULL값 / 중복값 불가
- 키 값의 변동이 일어나지 않아야 한다.
- 최대한 적은 수의 속성을 가진 것이어야 한다.
- 향후 키를 사용하는데 문제 발생 소지가 없어야 한다.
- 기본키는 테이블당 오직 하나의 필드에만 설정 가능하다.💡 NULL?
'값이 없음'을 나타내는 용어로 '아직 입력되지 않은 값', '알 수 없는 값'을 의미한다.
데이터베이스에서 값이 존재하지 않음을 나타낼 때 사용한다.
cf) 숫자 0, 공백 (아예 다른 개념이다.)
- 기본키 선정시 고려사항
-
외래키 (FK, Foreign Key) : RDBMS의 두 테이블 간의 관계를 정의하는 데 사용되는 키다. 외래키는 한 테이블의 필드(또는 필드 집합)이며, 이 필드는 다른 테이블의 기본 키(PK)를 참조한다.
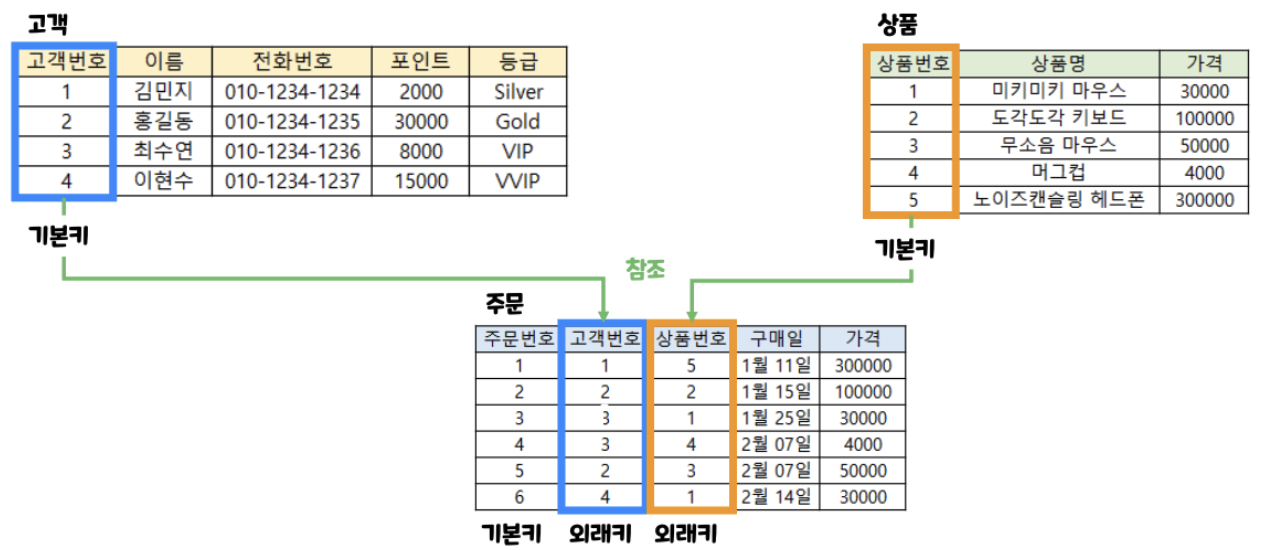
- 특징
- 참조하고(외래키) 참조되는(기본키) 양쪽 테이블 도메인은 서로 같아야 한다.
- 참조되는(기본키) 값이 변경되면 참조하는(외래키) 값도 변경된다.
- NULL 값과 중복 값 등이 허용된다.
- 자기 자신의 기본키를 참조하는 외래키도 가능하다. (아래 참고)
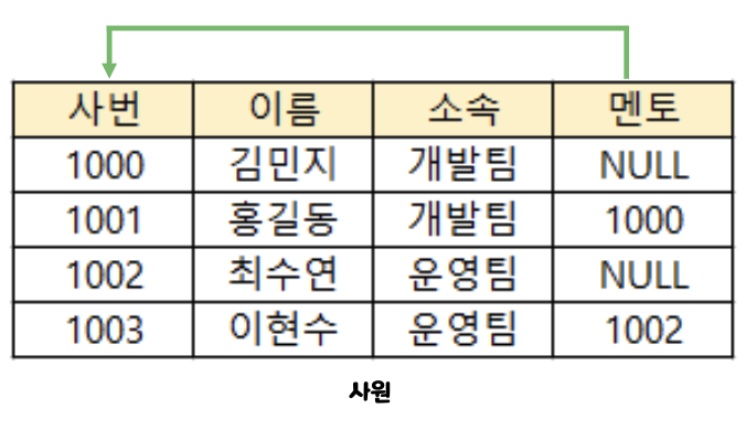
- 특징
-
2) 구축 단계
아래와 같은 단계를 거쳐 데이터베이스를 구축한다.

전체 데이터베이스 구성도는 아래와 같다. 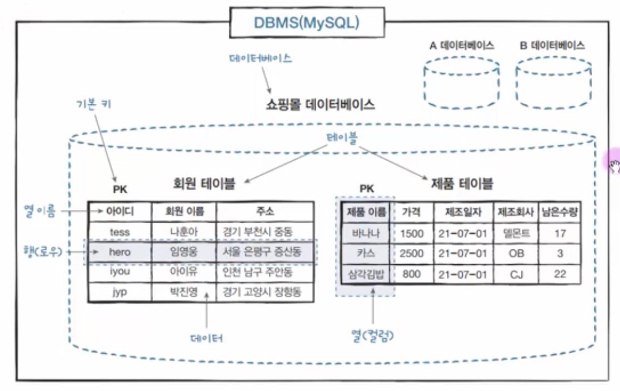
3) DBMS
DataBase Management System의 약자로, 데이터베이스에 접근/관리하기 위해 존재한다.
4) RDBMS
Relational DataBase Management System의 약자이다.
DBMS에 '관계(Relational)'가 추가된 것으로, 관계형 데이터베이스를 생성, 수정, 관리 및 쿼리할 수 있는 소프트웨어 시스템이다.
ex) Oracle, SQL Server, DB2, MySQL, PostgreSQL, SQLite 등
💡관계형?
이데이터가 테이블 형식으로 저장되며, 테이블 간의 관계를 통해 데이터를 구조화하고 조직화하는 방식을 의미한다.
3. MySQL
가장 널리 사용되고 있는 관계형 데이터베이스 관리 시스템 (RDBMS)이며, 오픈 소스이다.
윈도우, Mac, 리눅스 등 다양한 운영체제에서 사용 가능하다.
1) 설치
이 글을 쓰는 시점에서 MySQL 8.2.0 버전이 나와있었으나 나온 지 얼마안된 버전이라 불안정할 것을 예상하여 전 버전인 8.0.35 버전을 다운받았다.(mac 기준)
① 윈도우
설치 링크 : https://dev.mysql.com/downloads/installer/
② mac
윈도우는 설치 시 한번에 MySQL Workbench까지 받아진지만 mac은 MySQL Workbench를 따로 받아줘야한다.
- MySQL 설치 링크: https://dev.mysql.com/downloads/mysql/
- MySQL Workbench 설치 링크 : https://dev.mysql.com/downloads/workbench/
💡 MySQL Workbench?
데이터를 시각적으로 확인하기 편리하며, 콘솔 (git bash, cmd 등)에서도 동일한 작업 가능하다.
2) 실행
① window
# 1. MySQL 설치된 경로로 이동한다.
cd "c:\Program Files\MySQL\MySQL Server 8.0\bin"
# 2. 사용자명 root, 비밀번호를 입력해 MySQL에 접속한다.
mysql -u root -p # cmd, powershell에서 입력하는 경우
winpty mysql -u root -p # git bash에서 입력하는 경우
# 3. MySQL 종료 (다시 콘솔로 돌아가기)
quit # 또는 exit 를 입력해도 종료된다.② mac
# 1. MySQL 설치된 경로로 이동한다.
cd /usr/local/mysql/bin
# 2. 사용자명 root, 비밀번호를 입력해 MySQL에 접속한다.
.mysql -u root -p # mySQL에 접속된다.
# 3. MySQL 종료 (다시 콘솔로 돌아가기)
quit # 또는 exit 를 입력해도 종료된다.4. SQL
Structured Query Language의 약어로, 구조적 쿼리 언어다.
관계형 데이터베이스 관리 시스템 (RDBMS)에서 데이터를 정의, 조작 및 제어하기 위해 사용되는 표준 프로그래밍 언어이며, 실행 순서가 없는 비절차적인 언어다.
💡 DB 명명 규칙
1. 소문자로 작성하는 게 좋다.
2. 복합어구에는 _ (언더바)를 사용하는 게 좋다.
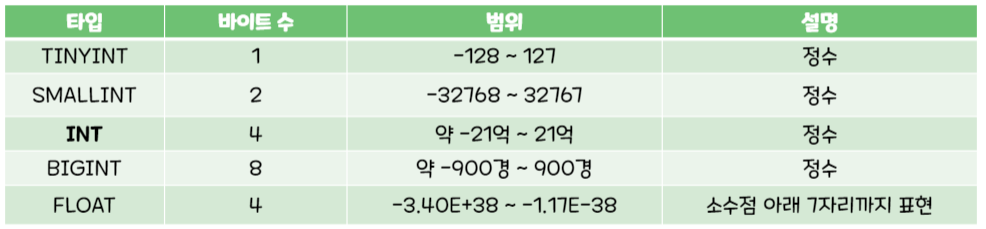
3. 데이터 타입을 이름으로 정하는 것은 피하는 게 좋다.💡 데이터 타입
MySQL에서 제공하는 데이터 타입은 매우 다양하다. 그 중에 자주 사용하는 형식은 아래와 같다.
- 숫자형
- 문자형
- 날짜형


SQL을 기능에 따라 분류하면 아래와 같이 3가지로 분류된다.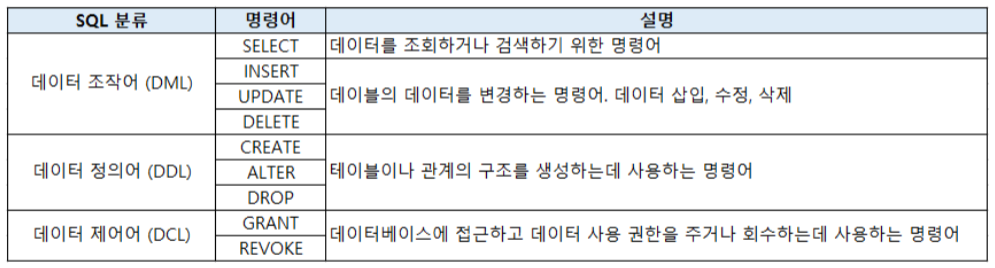 각각 자세히 알아보도록 하겠다.
각각 자세히 알아보도록 하겠다.
1) 데이터 정의어
= Data Definition Language(DDL)
① CREATE문
데이터베이스와 테이블을 생성한다.
- 데이터베이스 생성 + 한글 인코딩
CREATE DATABASE 데이터베이스명;
DEFAULT CHARACTER SET utf8mb4 DEFAULT COLLATE utf8mb4_unicode_ci;- 테이블 생성 : 테이블 이름, 열 이름, 데이터 형식, 기본키(pk), 외래키(fk) 정의한다.
-- 형식
CREATE TABLE 테이블명 (
속성이름1 데이터타입 PRIMARY KEY,
속성이름2 데이터타입,
[FOREIGN KEY 속성이름 REFERENCES 테이블이름(속성이름)]
);
-- 사용 예시
create table user(
id varchar(10) primary key not null,
password varchar(20) not null,
age int unsigned
);② ALTER문
생성된 테이블의 속성과 속성에 대한 제약 및 기본키, 외래키를 변경한다.
-- 형식
ALTER TABLE 테이블명 ADD 속성이름 데이터타입; -- 컬럼을 추가하는 명령어
ALTER TABLE 테이블명 DROP COLUMN 속성이름; -- 컬럼을 삭제하는 명령어
ALTER TABLE 테이블명 MODIFY 속성이름 데이터타입; -- 컬럼의 속성을 수정하는 명령어
-- 사용 예시
alter table user add gender enum('여자','남자');
alter table user drop column;
alter table user modify gender varchar(2) not null;③ DROP문
생성된 테이블 삭제한다. 테이블 구조와 데이터 모두 삭제하므로 주의가 필요하다.
-- 형식
DROP TABLE 테이블이름;
-- 사용 예시
drop table user;💡 DROP vs TRUNCATE
DROP TABLE 테이블이름;: 테이블을 삭제한다.TRUNCATE TABLE 테이블이름;: 테이블을 초기화한다.

2) 데이터 조작어
= Data Manipulation Language(DML), 데이터베이스의 내부 데이터를 관리하기 위한 언어다.
① INSERT문
테이블에 새로운 튜플을 추가한다.
-- 형식
INSERT INTO 테이블명 (필드1, 필드2, 필드3, ...) VALUES (값1, 값2, 값3, ...);
-- 필드를 명시하지 않는 경우 테이블의 모든 컬럼에 값을 순서대로 추가해야 함
INSERT INTO 테이블명 VALUES (값1, 값2, 값3, ...);
-- 사용 예시
insert into user (id, password) values ('jordy','1234');
insert into user values ('nardy', '1234', 31, '여자');② SELECT문
데이터를 검색하는 기본 문장으로, 질의어(query)라고도 한다. SQL문 중 가장 많이 사용되는 문법이다.
-- 형식
-- SELECT 속성이름 FROM 테이블이름 [WHERE 검색조건]
대괄호(`[]`) 안의 SQL예약어는 선택적으로 사용 가능하다.
-- 사용 예시
select * from user; -- *는 모든 값을 의미한다. 'user`라는 테이블의 모든 값을 조회한다. -
SQL 문 내부적 실행 순서
홍지수 고객의 주소를 찾기 위해SELECT addr FROM customer WHERE custname='홍지수'를 입력하면
아래와 같은 순서로 실행된다.
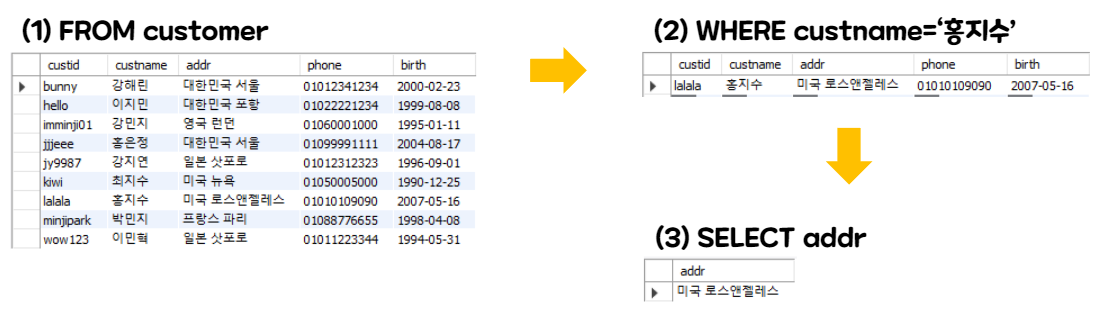
-
WHERE 조건
-
비교 연산자

-
부정 연산자

-
범위, 집합, 패턴, NULL

💡 와일드 문자?
특정 패턴에 일치하는 문자열을 찾을 때 사용한다.
-- 사용 예시 -- addr에 대한민국을 포함하고 있는 회원을 조회 select * from customer where addr like '%대한민국%'; -- custname 에 세글자 문자 중 마지막 글자가 수로 끝나는 회원을 조회 select * from customer where custname like '__수'; -- custname 에 마지막 글자가 수로 끝나는 회원을 조회 select * from customer where custname like '%수'; -- custname 에 마지막에서 두번째 글자가 해로 끝나는 회원을 조회 select * from customer where custname like '%해_'; -
복합 조건

-
-
ORDER BY : 결과가 출력되는 순서 조절하며, where 절과 함께 사용 가능하다. 단, where 절 뒤에 입력해야 한다.
- ASC : Ascending, 오름차순 (기본값)
- DESC : Descending, 내림차순
-- 사용 예시 -- custname 을 기준으로 오름차순 select * from customer order by custname ASC;
③ SELECT문 심화
- DISTINCT : 중복된 데이터를 제거한다.
-- 형식
SELECT [DISTINCT] 속성이름, ... FROM 테이블이름 [WHERE 검색조건] [ORDER BY 속성이름];
-- 사용 예시
select distinct addr from customer; - LIMIT : 출력 개수를 제한한다.
-- 형식
SELECT [DISTINCT] 속성이름, ...
FROM 테이블이름
[WHERE 검색조건]
[ORDER BY 속성이름]
[LIMIT 개수];
-- 사용 예시
select * from customer where addr like '%대한민국%' order by custname DESC limit 2;- 집계 함수
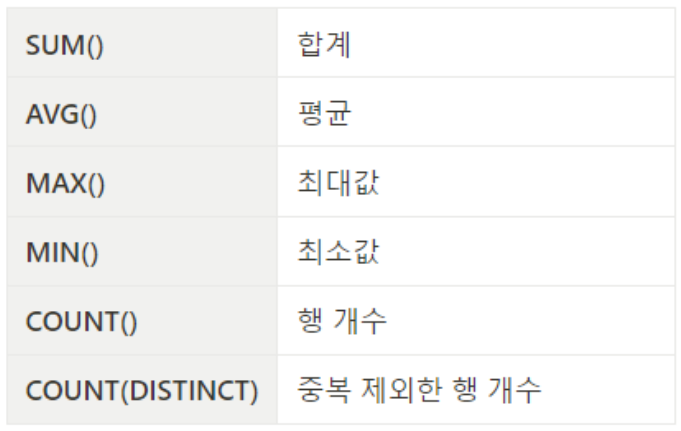
-- 사용 예시
-- orders 테이블에 존재하는 주문 개수
select count(*) as 'total_orders' from orders;
-- 사람별 주문 건수
-- select에서 group by를 쓸 때, group by뒤에 쓴 속성과 집계함수로 새로 만든 속성만 출력.
-- (다른 prodname 등등의 속성은 출력 X)
select custid, count(*) as 'count' from orders group by custid;
-- 사람별로 구매한 상품의 개수
select * from orders;
select custid, sum(amount) as 'total_amount' from orders group by custid;
-- 사람별로 결제한 금액
select custid, sum(amount*price) as 'total_price' from orders group by custid;
- GROUP BY : 속성이름끼리 그룹으로 묶는 역할이다.
- having : group by절의 결과를 나타내는 그룹을 제한한다.
-- 형식
SELECT [DISTINCT] 속성이름, ...
FROM 테이블이름
[WHERE 검색조건]
[GROUP BY 속성이름]
[HAVING 조건식]
[ORDER BY 속성이름]
[LIMIT 개수];
-- 사용 예시
-- 사람별로 구매한 상품의 개수 조회하는데, 구매한 상품의 개수가 5개 이상인 경우만 조회하고
-- 그중 custid != 'bunny'인 사람을 출력
select custid, sum(amount) as 'total_amount' from orders
where custid != 'bunny'
group by custid
having sum(amount) >= 5;④ UPDATE문
테이블에서 특정 속성 값을 수정한다. 반드시 프라이머리키를 기준으로 선택 후 update를 해야한다.
-- 형식
UPDATE 테이블명 SET 필드1 = 값1 WHERE 필드2 = 값2;
-- 사용 예시
update customer set custname = '강해란' where custid = 'bunny';⑤ DELETE문
테이블의 기존 튜플을 삭제한다. 반드시 프라이머리키를 기준으로 선택 후 delete를 해야한다.
지우려는 값이 외래값으로 설정되어 있으면 삭제가 안된다. → 외래값이 참조하고 있는 테이블에서 먼저 해당 값을 삭제 후 다시 외래값이 있는 테이블로 돌아와서 삭제해야 한다.
-- 형식
DELETE 테이블명 WHERE 필드1 = 값1;
-- 사용 예시
delete from orders where custid = 'wow123';3) JOIN
두 테이블을 묶어서 하나의 테이블을 만든다. 다른 두 테이블을 엮어야 원하는 형태가 나오기도 한다.
- Inner Join
-- 형식
SELECT [DISTINCT] 속성이름, ... FROM 테이블A INNER JOIN 테이블B ON 조인조건 WHERE 검색조건;
-- 사용 예시
-- customer, orders를 inner join -> 주문별로 배송지를 알고 싶을땐? 아래같이 입력
select customer.addr, orders.* from customer inner join orders on customer.custid = orders.custid;
-- customer 테이블의 custid와 order 테이블의 custid가 동일한 경우 그 값을 출력해줌.
select * from customer inner join orders on customer.custid = orders.custid;
-- 위 명령어에서 주문별로 배송지를 보기 위해 수정하면 아래같이 됨! // customer, order를 inner join처리한 것!
select customer.addr,orders.* from customer inner join orders on customer.custid = orders.custid;5. 마치며
전직장에서의 경험이 참 도움이 많이 되고 값지다는 걸 느낀다. 무슨 뜻인지 몰랐던 것들을 수업을 통해 알게되었을 때의 그 기분이란.. 짜릿햇..! 🤩
날이 갑자기 추워졌다가 다시 더워졌다가하면서 몸 컨디션이 확 떨어졌다. 아침에 일어나기도 힘들고.. 새벽에 공부하는게 집중이 잘 되긴하지만 컨디션을 위해 푹~ 자둬야겠다.
💻 본 글은 새싹X코딩온 풀스텍 웹 개발자 과정 수업과 수업자료를 참조하여 작성하였습니다.

나르디 화이팅!!!