
데이터 분석의 4단계
1) 데이터 불러오기
import pandas as pd
commercial = pd.read_csv('./data/commercial.csv')2) 데이터 살펴보기
commercial.tail(5)
list(commercial) #칼럼 살펴보기3) 데이터 가공하기
commercial[['시', '구', '상세주소']] = commercial['도로명주소'].str.split(' ', n=2, expand=True) #도로명 잘라 정리하기
seoul_data = commercial[commercial['시']=='서울특별시'] #필요한 데이터만 남기기groupdata = seoul_chicken_data.groupby('구')
group_by_category = groupdata['상권업종소분류명']
chicken_count_gu = group_by_category.count()
sorted_chicken_count_gu = chicken_count_gu.sort_values(ascending=False)
sorted_chicken_count_gu4) 데이터 시각화
- 어울리는 그래프 찾기
[1] 바 그래프: 각 항목들의 수치와 순위를 볼 때
[2] 라인 그래프: 이전 항목들 혹은 흐름에 따라 데이터의 관계를 볼 때
[3] 파이 차트: 비율을 볼 때
[4] 히트맵: 두 개 축의 수치를 한 눈에 볼 때
[5] 지도: 지리 정보를 한 눈에 볼 때
#지도에 표현하기 & 필요한 라이브러리
import matplotlib.pyplot as plt
import folium #folium 설치하기 conda install -c conda-forge folium
import json
# https://raw.githubusercontent.com/southkorea/seoul-maps/master/kostat/2013/json/seoul_municipalities_geo_simple.json
seoul_state_geo = './data/seoul_geo.json'
geo_data = json.load(open(seoul_state_geo, encoding='utf-8'))
map = folium.Map(location=[37.5502, 126.982], zoom_start=10)
folium.Choropleth(geo_data=geo_data,
data=chicken_count_gu,
columns=[chicken_count_gu.index, chicken_count_gu],
fill_color='PuRd',
key_on='feature.properties.name').add_to(map)
map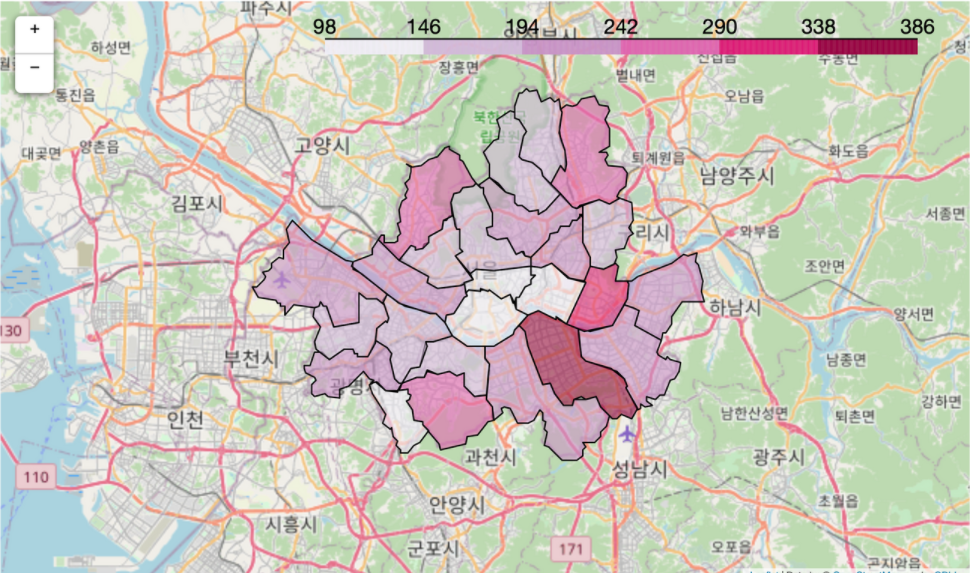

심리학적 데이터를 활용한 탐구를 즐기는 사람