레드와인과 화이트와인을 구분한 pca


-
주성분 분산이 높은 순서대로 시각화
-
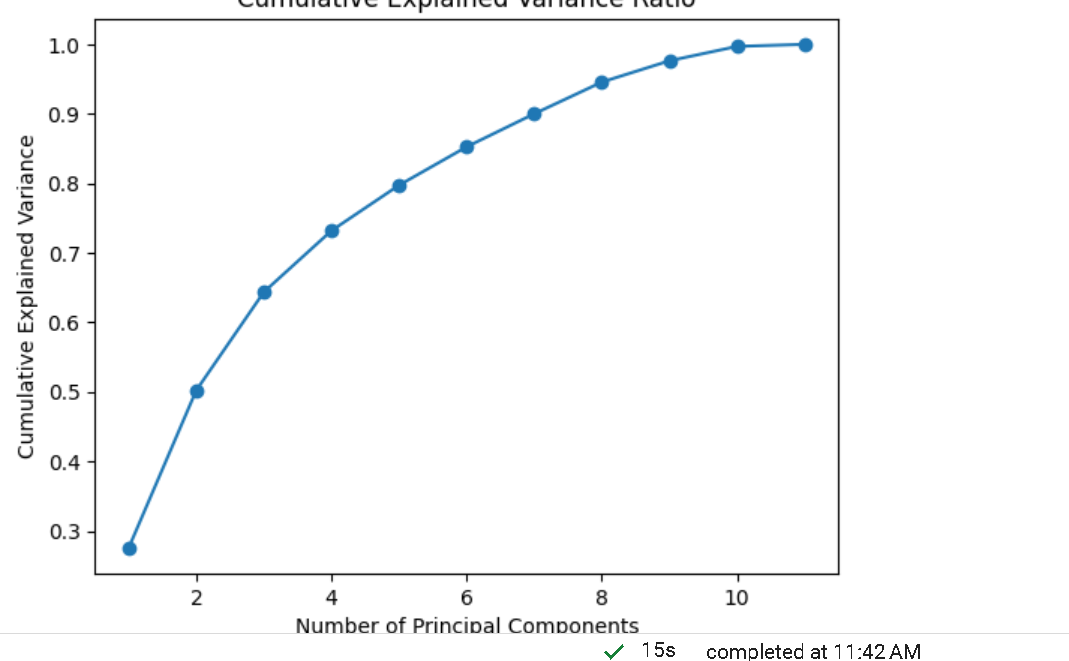
해당 그래프는 주성분의 개수에 따른 누적 설명된 분산
-
해당 그래프는 (누적 설명 분산 그래프) 분석을 위해 유지할 주성분의 수를 결정하는 데 도움

이런 식으로도 표현 가능
레드와인과 화이트와인을 구분한 k-means 엘보우 기법


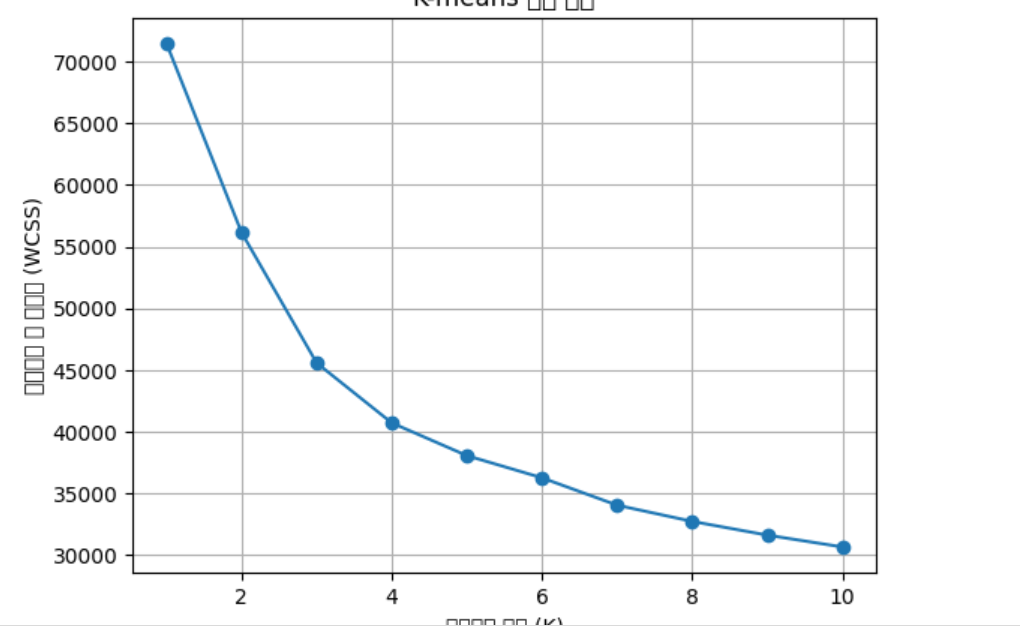
(한국어라 잘렸다)
-
엘보: 데이터셋에 대해 다양한 k값에 대한 k-means 클러스터링 수행
-
k값에 대해 각 포인트에서 할당된 중심까지 제곱 거리의 합 계산, SSE(Sum of Squared Errors)의 감소율이 급격히 변하는 지점을 찾음
그래프 해석 -
첫 번째 그래프는 엘보우 방법 도표
-
k(클러스터 수)의 다양한 값에 대한 SSE(제곱 오류의 합)을 보임
-
SSE가 더 느린 속도로 감소하기 시작하는 지점은, 최적의 클러스터 수
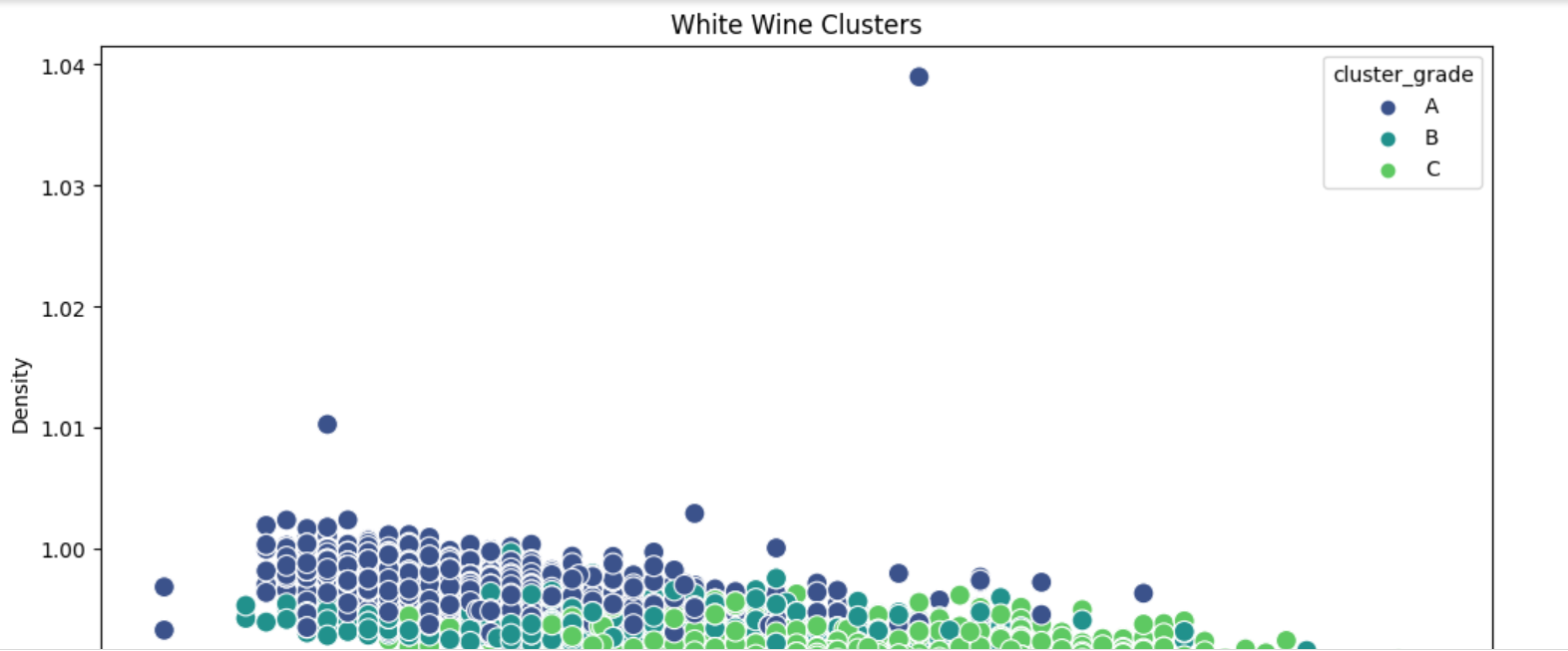
레드와인과 화이트와인을 구분한 k-means grade_mapping 하기




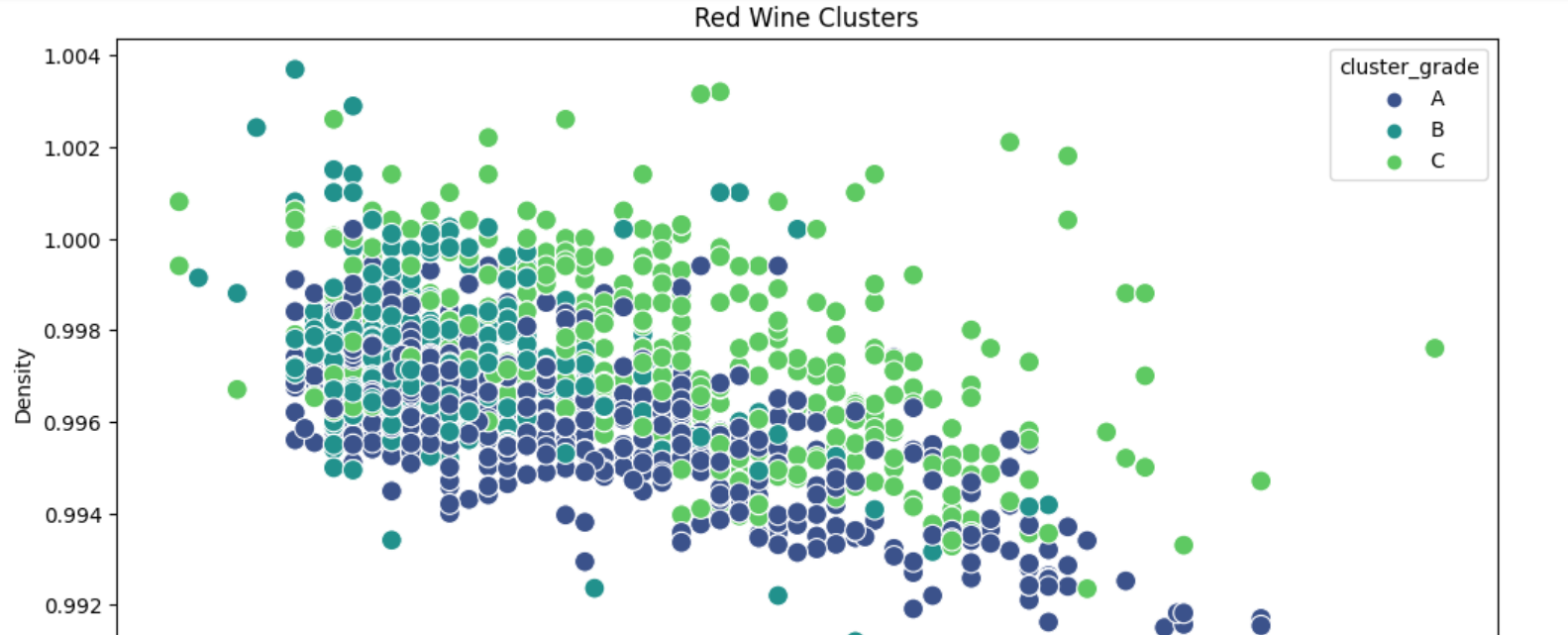
레드와인과 화이트와인을 구분한 DBSCAN 기법


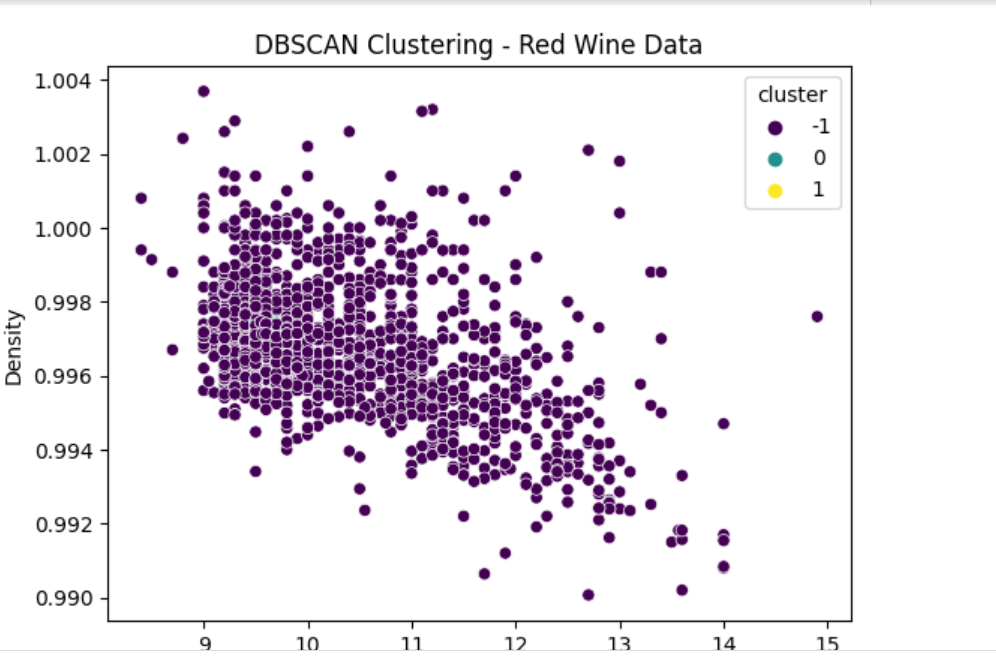
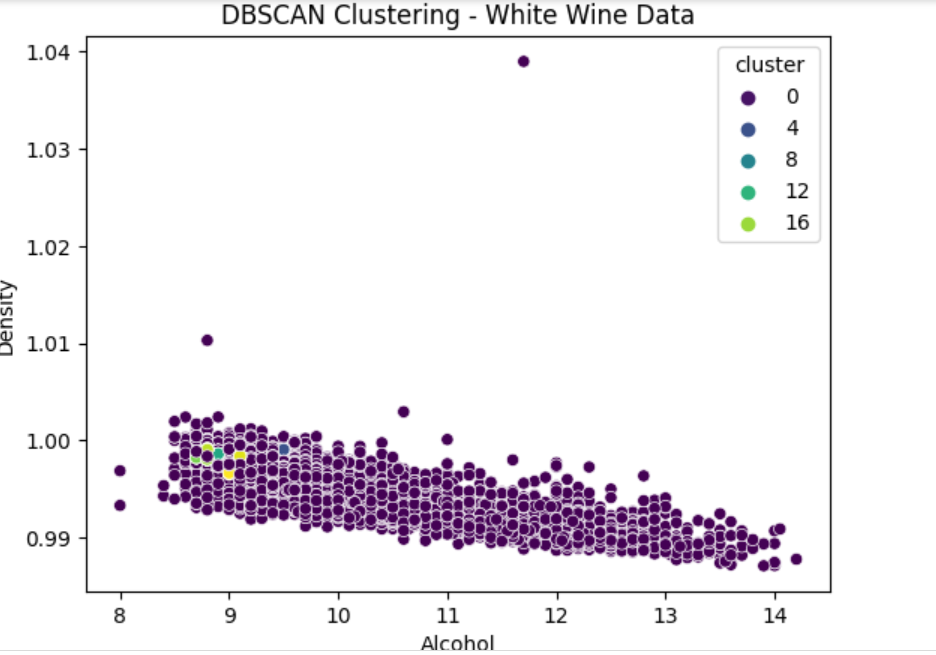
-
DBSCAN 클러스터의 산점도
-
임의의 모양의 클러스터를 찾고 노이즈 지점을 이상값으로 처리
-
왼쪽-> 오른쪽 알콜 함유량 증가 (x축), 아래->위 밀도 감소(y축)
-
각 클러스터 색으로 분류
전체 기법 정리
-
pca: 산점도는 주성본을 기준으로 데이터가 얼마나 잘 분리되는지 시각화
-
k-means: 데이터를 별개의 그룹으로 분할하는데 유용, 엘보우 방법(최적의 군집 수 식별)
-
dbscan: 임의의 모양의 클러스터를 찾고, 이상값 식별(밀도기반 방법)

안녕하세요. 일로 인해 잠시 쉽니다 :)